






本项目基于开源项目
WeClone
PyWxDump
本项目基于blog
(小白0基础) 微调deepseek-8b模型参数详解以及全流程——训练篇
(小白0基础) 租用AutoDL服务器进行deepseek-8b模型微调全流程(Xshell,XFTP) —— 准备篇
阅前必读:本项目主要用于熟悉微调的各种流程,并不以简单为首要目标,如果需要快速达成克隆目标,请阅读开源项目:
完成项目需要准备
- Xshell,Xftp
- 任意服务器(或者有独显的本地)
- 电脑登录微信
1.clone 仓库,准备微信数据
利用conda快速新建一个虚拟环境,在终端进入环境,pip安装pywxdump包
先新建一个文件夹,在该文件夹下右键一个“在终端中打开”
conda activate clonemyself(自定义名字)
pip install -U pywxdump
安装好之后输入,观察是否有输出
wxdump -h
有输出,直接输入,进入图像化界面
wxdump ui
进入后点击自动解密已登录微信
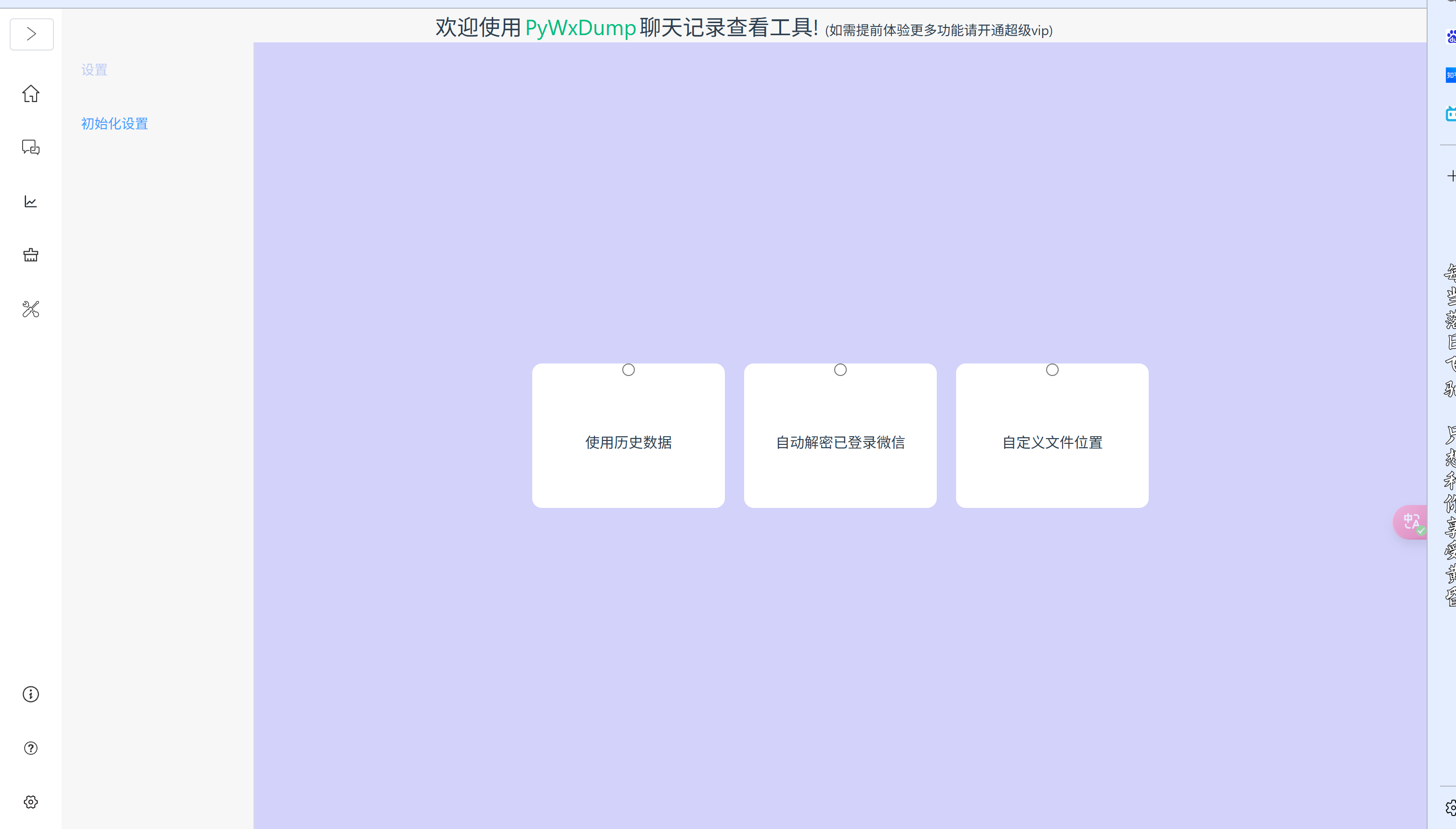
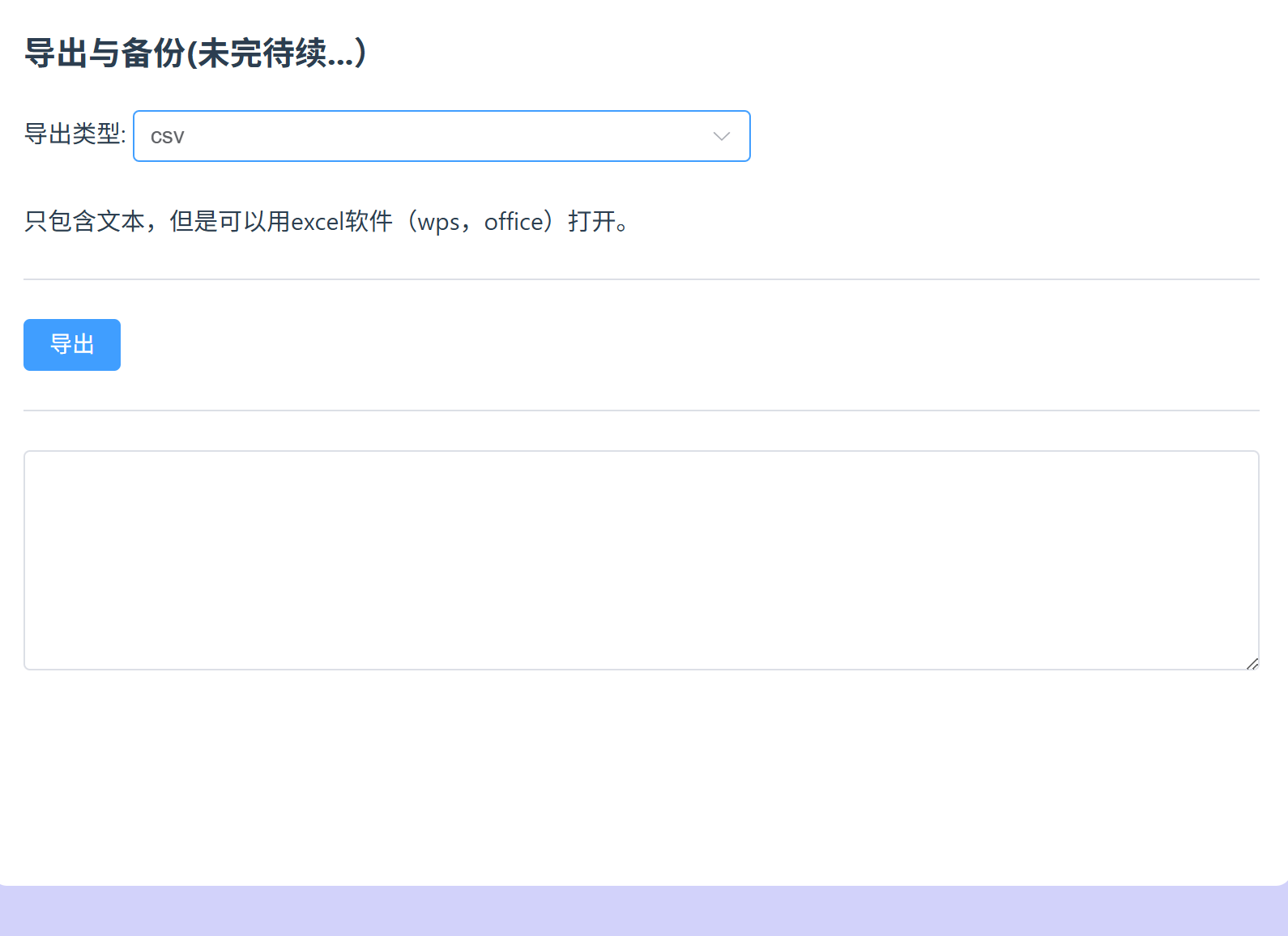
点击左边的聊天,点击导出备份

选择则csv文件导出
这里多选几个自己聊天聊的多的记录
进入目录 ,导出的文件在.\wxdump_work\export\wxid_ipqm2wst5hrf22\csv下
2.创建训练集
我们借助开源项目的其中一个功能
首先进入我们刚刚创建的那个环境下,进入刚刚新建的文件夹中
git clone https://github.com/xming521/WeClone.git
把上面的csv文件夹放入WeClone\data文件夹下,进入WeClone\make_dataset文件夹下,运行./make_dataset/qa_generator.py这个文件
这里可能需要准备一些环境,pip install 缺失的包名就可以了(注意在正确的环境下)
完成后终端输出一个目录,打开后发现csv文件总结为一个json文件,这个就是我们的训练集
3.训练
训练方式介绍两种
如果希望快速得到训练过程的,请参考开源项目WeClone
记下来将讲解deepseekr1的模型训练,首先参照*(小白0基础) 租用AutoDL服务器进行deepseek-8b模型微调全流程(Xshell,XFTP) —— 准备篇*
直到准备数据集为止
我们进入Xshell,将我们的文件拖入./root/autodl-tmp的自建文件夹中,在AutoDL中打开jupyter,运行以下文件,具体参数需要参考
(小白0基础) 微调deepseek-8b模型参数详解以及全流程——训练篇
注意需要处理以下几个问题:
- 由于我们的训练集没有cot部分,所以删除了cot方面的推导
- question部分填写想问的问题
- 模型放的位置需要更改,代码中已经标出
!pip install unsloth
# Also get the latest nightly Unsloth!
!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 #这里指的是处理上下文最大的长度
dtype = None #这里指的是处理数据类型的精度
load_in_4bit = True # 这里是进行4bit的量化减少内存损耗
!pip install wandb
import wandb
wandb.login(key="e98ba3844d27f8ef8720dbe8db30ed8a8cf4c5b8")
run = wandb.init(
project='my fint-tune on deepseek r1 8b',
job_type="training",
anonymous="allow"
)
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "/root/autodl-tmp/DeepSeek-R1-Distill-Llama-8B", # 这里改成你本地模型,以我的为例,我已经huggingface上的模型文件下载到本地。
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
这一个微信中日常聊天的场景,假设你是一个拥有真实感情的人,请用日常用语和用户聊天
### Question:
{}
### Response:
<think>{}"""
question = "自定义问题"
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda") # return_tensors="pt"返回 PyTorch 张量格式。
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask, #掩码自注意力机制
max_new_tokens=1200, #限制最长文本
use_cache=True, # 启用 Key-Value 缓存,避免重复计算历史 token 的注意力(显著加速自回归生成)。
)
response = tokenizer.batch_decode(outputs) #将生成的 token IDs 解码为文本。
print(response[0].split("### Response:")[1]) # 按照### Response: 分隔
model = FastLanguageModel.get_peft_model(
model,
r=16, # LoRA秩:控制低秩矩阵的维度(16x16)
target_modules=[
"q_proj",# q_proj, k_proj, v_proj:注意力层的 Query/Key/Value 投影矩阵
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj", # FFN(前馈网络)层的门控、升维、降维矩阵。
],
lora_alpha=16, #缩放因子,控制 LoRA 权重对原始权重的缩放强度(ΔW = α/r × A×B)
lora_dropout=0, #无dorpout
bias="none", #无偏置
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407, # 随机种子(确保实验可复现)
use_rslora=False,
loftq_config=None, # 一种结合 量化与 LoRA 的技术,可进一步压缩模型。
)
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
这一个微信中日常聊天的场景,假设你是一个拥有真实感情的人,请用日常用语和用户聊天
### Question:
{}
### Response:
<think>
{}
</think>
{}"""
## 主要是对训练集的数据进行格式化
def formatting_prompts_func(examples):
inputs = examples["instruction"]
cots = [""] * len(inputs)
outputs = examples["output"]
texts = []
for input, cot, output in zip(inputs, cots, outputs): #利用zip方法
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN # template:一个包含 {} 占位符的字符串模板。
texts.append(text)
return {
"text": texts,
}
from datasets import load_dataset
dataset = load_dataset("/root/autodl-tmp/clonemyself",split="train")#这里填写放模型的地点
dataset = dataset.map(formatting_prompts_func, batched = True,)
dataset["text"][0]
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2, # 数据预处理时的并行进程数(加快数据加载
args=TrainingArguments(
per_device_train_batch_size=2, # 每个 GPU 的批大小
gradient_accumulation_steps=4, # 梯度累积步数
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5, #学习率步数
max_steps=80,#步长或者完整训练一次num_train_epochs=1
learning_rate=2e-4, # 初始学习率
fp16=not is_bfloat16_supported(), # 启用 float16 混合精度训练
bf16=is_bfloat16_supported(),
logging_steps=10, # 日志步长
optim="adamw_8bit", # 使用 8-bit AdamW 优化器
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs", # 模型和日志的输出目录
),
)
trainer_stats = trainer.train()
wandb.finish()
save_path = "/root/autodl-tmp/DeepSeek-WX" # 自定义保存路径
# 保存模型和分词器
model.save_pretrained(save_path)
tokenizer.save_pretrained(save_path)
我们进入wandb网站,可以看到自己训练的参数
4. 验证
保存好模型之后,我们就可以执行验证
我们重新新建一个jupyter文件用于验证
from unsloth import FastLanguageModel
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
save_path = "/root/autodl-tmp/DeepSeek-WX"
base_model_path = "/root/autodl-tmp/DeepSeek-R1-Distill-Llama-8B"
## 加载基础模型
base_model = AutoModelForCausalLM.from_pretrained(
base_model_path,
load_in_4bit=True,
device_map="auto",
)
model = PeftModel.from_pretrained(base_model, save_path) # 适配器
tokenizer = AutoTokenizer.from_pretrained(base_model_path) # 分词器
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
这一个微信中日常聊天的场景,假设你是一个拥有真实感情的人,请用日常用语和用户聊天
### Question:
{}
### Response:
<think>{}"""
question = "今天天气真好啊,你吃饭了吗,你吃了啥"
FastLanguageModel.for_inference(model) # 应用unsloth优化(可选)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda") # return_tensors="pt"返回 PyTorch 张量格式。
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask, #掩码自注意力机制
max_new_tokens=200, #限制最长文本
use_cache=True, # 启用 Key-Value 缓存,避免重复计算历史 token 的注意力(显著加速自回归生成)。
)
response = tokenizer.batch_decode(outputs) #将生成的 token IDs 解码为文本。
print(response[0].split("### Response:")[1]) # 按照### Response: 分隔
等待片刻即可输出微调之后的对话
注意事项
训练集不存在推理部分,所以在模型微调的时候添加了空字符串作为微调参数。

















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









