









https://blog.csdn.net/qq_37314249/article/details/103605076
https://zhuanlan.zhihu.com/p/94085500
4、对点集的深度学习
4.1 欧式空间点集的特点
1、无序性
2、点与点之间的关联
3、旋转不变性
4.2 pointnet 框架

模型有3个关健模块:
1、max pooling层作为一个对称函数去中和所有点的信息,
2、一个局部和全局信息融合的框架结构,
3、两个联合对齐网络实现输入点云与点特征的对齐。
1、symmetry function for unordered input
有三种方法实现模型对输入点云的无序性的适应:
1、将点进行排序。
高维空间事实上是不存在点扰动稳定的排序,如果存在则要求高维空间到一维映射时保持空间接近度,一般很难实现。所以排序不能解决这个问题。
2、用RNN网络对所有点的全排列进行训练
RNN是将点集看成一个顺序信号,希望用随机排序训练RNN,保证输入顺序对输出没有影响。但是在“OrderMatters”里表明点的顺序问题仍然存在。这种方法对较短的序列有较好的鲁棒性,但是对成千的序列输入很难。
3、用一个对称函数去融合所有点的特征。对称函数例如+和*。
本文利用的这种思想,用max pooling作为一个对称函数。
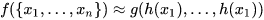
其中h(x)为MLP多层感知机,g为单变量函数与max pooling的组合,用在了下方,保证提取的全局特征不随点的顺序变换而改变。

2、局部和全局信息的结合
前几个节的输出是一个向量[f1,f2,…fk],这是对应输入序列的全部特征。我们可以利用这些全局特征训练一个svm或mlp实现分类。但是在分割任务里需要结合局部特征和全局特征。具体方法是将每个点的64个特征和1024个全局特征串联得到一个1088的特征。注意这里没有用到每个点周围的特征。

3 旋转对齐网络
我们希望,点云经过几何变换后,最终的语义标签是不变的。所以在提取特征前,要将点云旋转到一个标准的空间。
本文使用一个T-Net的小网络计算一个3*3的仿射变换矩阵,这个网络也是提取特征,最大池化,全连接。通过这个矩阵与原始点云相乘得到新的点云。同时将这个网络用在特征空间上,保证特征的不变性。特征空间为64x64的,所以添加softmax中增加了正则化项。
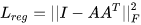

(整个网络的个人理解)
1、 输入n×3的数据,首先利用输入数据和T-Net训练3×3的矩阵,并用在输入点云上实现坐标变换,将输入点云旋转到一个相对稳定的空间。
2、 然后利用共享多层感知机训练得到n×64的特征。这一步的多层感知机有两层,第一层是364的,将每个点的3个特征变换到64,然后在利用6464的进行计算。共享的意思是所有n个点用的是一个多层感知机,也就是他们的权重是相同的。那么最终的n×64中,每个n的64个特征只是利用他自身的3个特征计算出来的。
3、 再次利用T-Net计算6464的变换矩阵,希望特征也具有不变性。并加入了正则化,得到每个点的特征
4、 然后再次利用共享多层感知机(64,128,1024)得到n×1024的特征。这里的每个n的1024个特征依然是利用对应输入n的3个特征计算得到的。然后利用max pool 将n×1024压缩到11024 。到这可以看出,输入点的顺序对这1024特征是不影响的。
对于分类问题,利用一个多层感知机(512,256,k)就能得到k个分数,判断这些点云是那个类。
对于分割问题,需要对每个点分类,所以将每个点的64个点特征和全局1024个特征进行拼接,得到n×1088个特征。然后利用shared mlp(512,256,128)得到n×128的点特征。然后再次利用shared mlp(128,m)得到n×m的分数矩阵,实现点的分割。
4.3 理论证明
证明了两个定理:
1、PointNet的网络结构能够拟合任意的连续集合函数
2、(a)说明对于任何输入数据集,都存在一个关键集和一个最大集,使得对和之间的任何集合,其网络输出都和一样。下图表示任何落在关键集和最大集中的点集都会得到同样的特征。定理2(b)说明了关键集的数据多少由maxpooling操作输出数据的维度K给出上界(框架图中为1024)。换个角度来讲,PointNet能够总结出表示某类物体形状的关键点,基于这些关键点PointNet能够判别物体的类别。这样的能力决定了PointNet对噪声和数据缺失的鲁棒性
















 1236
1236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









