







Diffusion Transformers (DiT) 原理总结
简短描述:
Diffusion Transformers (DiT) 是一种基于Transformer架构的扩散模型,旨在替代传统的U-Net结构,解决其计算冗余、参数效率低和长程依赖建模不足的问题。
DiT通过将VAE输出的潜在特征分块并展平成序列,结合ViT的标准架构来处理这些序列,从而提升了生成质量和计算效率。此外,DiT引入了自适应条件注入机制,通过改进的adaLN-Zero块有效融合时间步和类别信息,使得模型能更好地处理不同条件下的生成任务。
实验结果表明,DiT在图像生成任务中展现了强大的性能,尤其在ImageNet数据集上刷新了SOTA指标。
详细描述:
DiT(扩散变换器)是基于Transformer架构的扩散模型,它由UC Berkeley和纽约大学的谢赛宁团队提出,作为对传统基于U-Net的扩散模型的一种创新性替代方案。DiT在图像生成领域展现了强大的性能,尤其是在ImageNet任务上刷新了SOTA(state-of-the-art,最先进)指标,标志着生成模型架构的统一化和发展。其核心创新点如下:
1. U-Net局限性
- 计算冗余:U-Net的跳跃连接和跨分辨率操作较为低效。
- 参数效率低:U-Net需要在每个分辨率阶段使用独立的卷积核,导致参数量随深度增加。
- 长程依赖建模不足:注意力层仅在高分辨率层(如SD v1.5的8x8层)使用,未能有效捕捉全局信息。
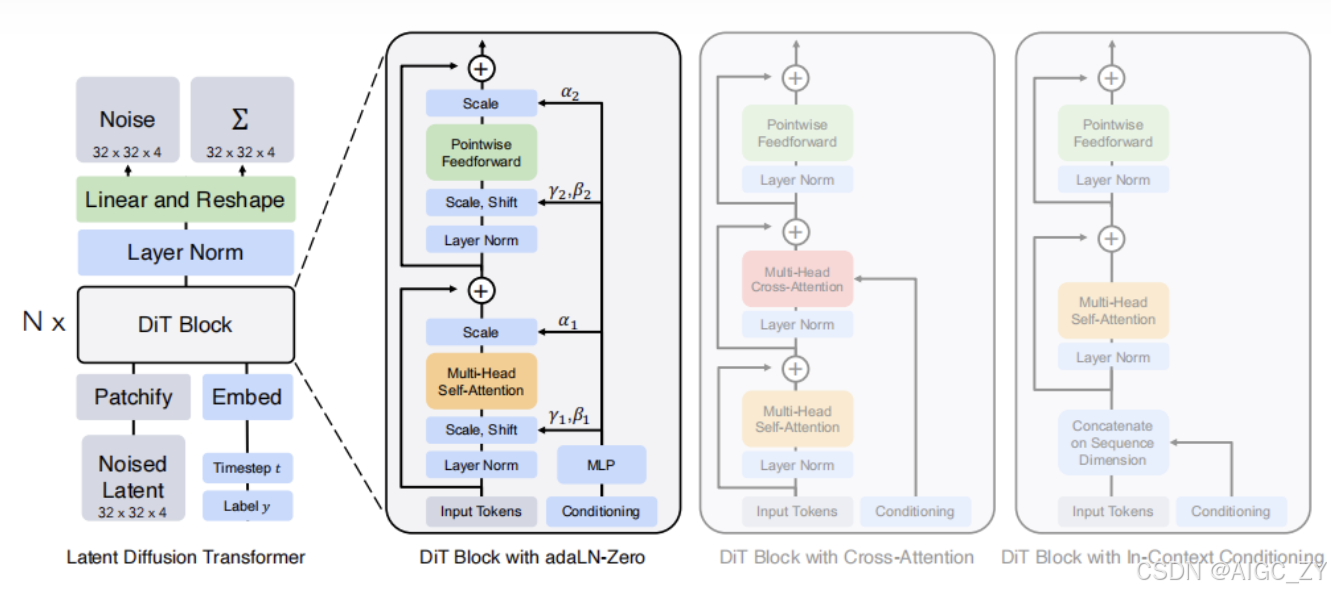
2. DiT架构创新
- 潜在空间分块(Patchify):将VAE编码的潜在空间特征 Latent 表示分割成小块 patches,并展平成序列,类似ViT(Vision Transformer)的做法。这种方式可以控制计算复杂度,通过调整patch大小来优化性能。
输入:VAE编码的潜在空间特征(尺寸H×W×C,如32×32×4)。
分块:按p×p大小切分,生成N =[ (H×W)/p] ²个块。
投影:线性映射至高维空间(维度d), 得到DiT输入的Latent特征维度
是 N x d。
- Transformer主干:DiT采用标准的ViT架构处理这些序列,完全替代了U-Net中的卷积操作。多头注意力 + MLP
3. 条件注入机制
- 自适应条件注入:通过改进的adaLN-Zero块,将时间步(timestep)和类别标签等条件信息与输入特征融合。该过程通过调整归一化参数,使得模型能够更好地处理不同条件下的生成任务。
4. DiT设计中的关键块
-
上下文条件(Context Cond):将时间步
t和类别标签c作为额外的tokens,并与输入特征拼接,提升了模型的表达能力,同时计算开销较低。 -
交叉注意力(Cross-Attn):将额外的条件信息(如时间步和类别标签)视为一个单独的序列,加入额外的多头交叉注意力机制,增加了一些计算负担,但提升了生成质量。
-
自适应层归一化(adaLN):用自适应归一化替代标准归一化层,从
t和c的嵌入向量中回归出维度缩放参数 γ \gamma γ 和 移位参数 β \beta β
最小化计算复杂度并优化训练。 -
adaLN-Zero:进一步优化了自适应归一化机制,进一步在任何残差连接前增加一个维度缩放参数 α \alpha α, 并将这些参数初始化为零,优化了块的初始化。提高了模型稳定性。
5. 实验设计与效果
- DiT在多个模型规模和patch大小的配置下进行实验,结果表明,增大模型规模和减小patch大小能显著提升扩散模型的生成性能。
- 在ImageNet数据集上的实验中,DiT-XL/2模型在256x256和512x512分辨率下,分别取得了2.27和3.04的FID(Fréchet Inception Distance)得分,超越了所有现有的扩散模型。
6. 总结
- DiT展示了基于Transformer架构的扩散模型在图像生成中的巨大潜力,特别是在生成质量和计算效率方面相比传统的U-Net架构有显著提升。
- 尽管初期的创新没有引起广泛关注,但随着Sora视频生成模型等应用的出现,DiT在生成模型领域的影响力逐渐上升。
参考资料:
【AIGC图像实践篇 10】DiT 原理及实践
Diffusion Transformer模型结构解析(DiT、SD3、Flux)
扩散模型解读 (一):DiT 详细解读

















 2682
2682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









