








0.Abusurt
0.1逐句翻译
Feature extraction is crucial for human activity recognition (HAR) using body-worn movement sensors.
特征提取是利用佩戴式运动传感器进行人体活动识别的关键。
Recently, learned representations have been used successfully, offering promising alternatives to manually engineered features.
最近,已经成功地使用了学习表示,为手工设计的特性提供了有希望的替代方案。(大约就是使用深度学习的方法进行特征提取)
Our work focuses on effective use of small amounts of labeled data and the opportunistic exploitation of unlabeled data that are straightforward to collect in mobile and ubiquitous computing scenarios.
我们的工作重点是有效利用少量标记数据,以及利用在移动和无处不在的计算场景中可以直接收集的未标记数据。
We hypothesize and demonstrate that explicitly considering the temporality of sensor data at representation level plays an important role for effective HAR in challenging scenarios.
我们假设并证明,明确考虑传感器数据在表示水平上的时效性,对于具有挑战性的场景中有效的HAR具有重要作用。
We introduce the Contrastive Predictive Coding (CPC) framework to human activity recognition, which captures the long-term temporal structure of sensor data streams.
我们将对比预测编码(CPC)框架引入到人类活动识别中,以捕获传感器数据流的长期时间结构。
Through a range of experimental evaluations on real-life recognition
tasks, we demonstrate its effectiveness for improved HAR.
通过对现实生活中识别能力的一系列实验评估我们证明了它对改进HAR的有效性。(大约就是通过实验说明了CPC是可以在HAR当中使用的)
CPC-based pre-training is self-supervised, and the resulting learned representations can be integrated into standard activity chains.
基于cpc的前训练是自我监督的,由此产生的学习表征可以集成到标准的活动链中。
It leads to significantly improved recognition performance when only small amounts of labeled training data are available, thereby demonstrating the practical value of our approach.
当只有少量的标记训练数据时,它可以显著提高识别性能,从而证明了我们的方法的实用价值。(就是本文不是简单的使用无监督,还在其中加入了一部分有标签的数据,准确的讲,不就是个半监督吗)
0.2总结
文章的最大贡献就是在HAR当中引入了对比学习这种表示学习的思想,在这种思想的加持下可以进行大量无标签数据的训练。
这里并不是一个严格的无监督,他是一个半监督的状态
1.INTRODUCTION
1.1逐句翻译
第一段(惯性传感器的分布广泛以及应用广泛)
Body-worn movement sensors, such as accelerometers or full-fledged inertial measurement units (IMU), have been extensively utilized for a wide range of applications in mobile and ubiquitous computing, including but not limited to novel interaction paradigms [67, 82, 84], gesture recognition [83], eating detection [2, 7, 73, 87], and health and well-being assessments in general [24, 54, 76].
穿戴式运动传感器,如加速度计或成熟的惯性测量单元(IMU),已被广泛应用于移动和普适计算的广泛应用,包括但不限于新型交互范式[67,82,84]、手势识别[83]、进食检测[2,7,73,87]、以及一般的健康和幸福评估[24,54,76]。
(大约就是说目前IMU应用的还挺多的,内涵一句应用场景广泛)
They are widely utilized on commodity smartphones, and smartwatches such as Fitbit and the Apple Watch.
它们被广泛应用于普通智能手机,以及Fitbit和Apple Watch等智能手表。
(就是说应用设备广泛)
The ubiquitous nature of these devices makes them highly suitable for real-time capturing and analysis of activities as they are being performed.
这些设备无处不在的特性使它们非常适合实时捕捉和分析正在执行的活动。
第二段()
The workflow for human activity recognition (HAR), i.e., the all encompassing paradigm for aforementioned applications, essentially involves the recording of movement data after which signal processing and machine learning techniques are applied to automatically recognize the activities.
人类活动识别(human activity recognition, HAR)的工作流程,即上述应用的包涵一切的范例,本质上涉及到记录运动数据,然后应用信号处理和机器学习技术来自动识别活动。
(介绍HAR)
This type of workflow is typically supervised in nature, i.e., it requires the labeling of what activities have been performed and when after the data collection is complete [8].
这种类型的工作流在本质上通常是受监督的,例如,它需要在行为完成之后标记哪些活动已经被执行并且记录执行的时间[8]。
(就是你在采集完成之后得知道什么时间你在做什么,并将这个东西标记在你采集的传感器数据上)
Streams of sensor data are segmented into individual analysis frames using a sliding window approach, and forwarded as input into feature extractors.
使用滑动窗口方法将传感器数据流分割成独立的分析帧,并将其作为输入输入特征提取器。
(这里应该是指的是传统方法)
The resulting representations are then categorized by a machine learning based classification backend into the activities under study (or the NULL class).
结果表示然后被一个基于机器学习的分类后端分类为正在研究的活动
第三段(数据集大小是关键)
The availability of large-scale annotated datasets has resulted in astonishing improvements in performance due to the application of deep learning to computer vision [34, 42], speech recognition [3, 26] and natural language tasks [18, 52].
由于深度学习在计算机视觉[34,42]、语音识别[3,26]和自然语言任务[18,52]的应用,大规模标注数据集的可用性导致了惊人的性能改善。
(就是大规模的数据集在等等方面都可以有效地改善识别的效果)
While end-to-end training has also been applied to activity recognition from wearable sensors [27, 29, 59], the depth and complexity is limited by a lack of such large-scale, diverse labeled data.
虽然端到端训练也已应用于可穿戴传感器的活动识别[27,29,59],但由于缺乏这种大规模、多样化的标记数据,其深度和复杂性受到限制。
(使用传感器数据的工作也有不少,但是大多受制于标记数据集的大小问题)
However, due to the ubiquity of sensors (e.g., in phones and commercially available wearables such as watches etc.) the data recording itself is typically straightforward, which is in contrast to obtaining their annotations, thereby resulting in potentially large quantities of unlabeled data.
然而,由于传感器(例如,在手机和商业可用的可穿戴设备,如手表等)的无处不在,数据记录本身通常是直接的,这与获取它们的注释不同,从而导致潜在的大量未标记数据。
(虽然标记得不多,但是没有标记的很多)
Thus, in our work we look for approaches that can make economic use of the limited labeled data and exploit unlabeled data as effectively as possible.
因此,在我们的工作中,我们寻找的方法可以经济地利用有限的标记数据,并尽可能有效地利用未标记数据。
第四段(传统深度学习当中有长尾问题,所以本文想要使用无监督的特征提取替代传统的特征工程)
Previous works such as [31, 63, 69] have demonstrated how unlabeled data can be utilized to learn useful representations for wide ranging tasks, including identifying kitchen activities [11], activity tracking in car manufacturing [71], classifying every day activities such as walking or running [4, 10, 51, 66], and medical scenarios involving identifying freeze of gait in patients suffering from Parkinson’s disease [57].
之前的研究,如[31,63,69],已经证明了如何利用未标记数据来学习广泛任务的有用表示,包括识别厨房活动[11],汽车制造中的活动跟踪[71],对日常活动(如步行或跑步)进行分类[4,10,51,66],以及识别帕金森病[57]患者步态冻结的医疗方案。
In many such applications, the presence of complex and often sparsely occurring movement patterns coupled with limited annotation makes it especially hard for deriving effective recognition systems.
在许多这样的应用程序中,复杂且经常稀疏出现的移动模式的存在,加上有限的注释,使得获得有效的识别系统变得特别困难。
(在实际的行为识别过程中,我们可能遇见那些复杂的很少出现的行为,这些行为可能根本也没有标签标注他们。所以我们在训练模型的是很很难获得好的效果)
The promising results delivered in these works without the use of labels have resulted in a general direction of integrating unsupervised learning as-is into conventional activity recognition chains (ARC) [8] in the feature extraction step.
这些工作在不使用标签的情况下取得了很有前景的结果,这导致了在特征提取步骤中将无监督学习按现状集成到传统活动识别链(ARC)[8]中的一个总体方向。
(就是说用无监督的方式取代传统的特征提取方法)
In this work, we follow this general direction of utilizing (potentially large amounts of) unlabeled data for effective representation learning and subsequently construct activity recognizers from the representations learned.
在这项工作中,我们遵循这一总体方向,即利用(可能是大量的)未标记数据进行有效的表征学习,并随后从学到的表征构建活动识别器。
第五段(本文提出的内容考虑了时间序列的特点)
Recent work towards such unsupervised pre-training has gone beyond the early introduction using Restricted Boltzmann Machines (RBMs) [63], involving (variants of) autoencoders [31, 74], and self-supervision [32, 69].
最近对这种无监督的预训练的研究已经超越了早期使用受限玻尔兹曼机器(Restricted Boltzmann Machines, RBMs)[63]的引入,涉及(各种)自动编码器[31,74]和自我监督[32,69]。
While they result in effective representations, most of these approaches do not specifically target a characteristic inherent to body-worn sensor data – temporality.
虽然它们能有效地表示,但大多数方法并没有专门针对穿戴式传感器数据固有的特性——时间性。
Wearable sensor data resemble time-series and we hypothesize
that incorporating temporal characteristics directly at the representation learning level results in more discriminative features and more effective modeling, thereby leading to better recognition accuracy for HAR scenarios with limited availability of labeled training data – as they are typical for mobile and ubiquitous computing scenarios.
可穿戴传感器数据类似于时间序列,我们假设在表示学习水平上直接结合时间特征会产生更有区别的特征和更有效的建模,从而导致在有限的标记训练数据可用性下对HAR场景更好的识别精度——因为它们是典型的移动和无处不在的计算场景。
(因为在这里,我们不标记某种特定的分类,所以可以适应大场景下的多种行为的变化。)
第六段()
Previous work on masked reconstruction [32] has attempted to address temporality at feature level in a self-supervised learning scenario by regressing to the zeroed sensor data at randomly chosen timesteps.
之前关于掩码重构[32]的工作试图通过在随机的节点上归零传感器数据,并使用自动监督的方式进行特征提取,来最终达到消除暂时性的目标。
(我觉得你随机对序列的一部分进行置0达到的效果就是我们在训练的过程中,让序列的每个部分的贡献都差不多,达到一个均衡的目的,也就不会使得暂时性对实验结果造成很大的影响)
This incorporates local temporal characteristics into a pretext task that forces the recognition network to predict missing values based on immediate past and future data.
这将局部时间特征整合到借口任务中,迫使识别网络根据最近的过去和未来数据预测缺失值。(这样)
It was shown that the resulting sensor data representations are beneficial for modeling activities, which provides evidence for our aforementioned hypothesis of temporality at feature level playing a key role for effective modeling in HAR under challenging constraints.
结果表明,所得到的传感器数据表示有利于建模活动,这为我们前面提到的特征水平上的时间性假设提供了证据,该假设对于具有挑战性的约束条件下HAR的有效建模起到了关键作用。
1.2总结
- 1.惯性传感器分布广泛应用广泛
- 2.HAR传统都是通过滑动窗口将数据分成一段一段的,送入到下游的特征分析器当中,大约就是陈述了一个传统机器学习的方法
- 3.这里说明了一个矛盾:
想要提升精度就需要大量的数据集,但是标记的行为识别数据集并不多见。
但是实际上我们生活当中有很多传感器数据,但是我们并没有将其很好的利用起来。
为了解决这个矛盾本文就尝试使用对比学习这种无监督的方式来解决这个矛盾。
2 RELATED WORK ON REPRESENTATIONS OF SENSOR DATA IN HUMAN ACTIVITY RECOGNITION
3 SELF-SUPERVISED PRE-TRAINING WITH CONTRASTIVE PREDICTIVE CODING
3.0
3.0.1逐句翻译
第一段(介绍本文提出的模型的主要结构)
In this paper, we introduce the Contrastive Predictive Coding (CPC) framework to human activity recognition from wearables.
本文将对比预测编码(CPC)框架引入到可穿戴设备的人体活动识别中。
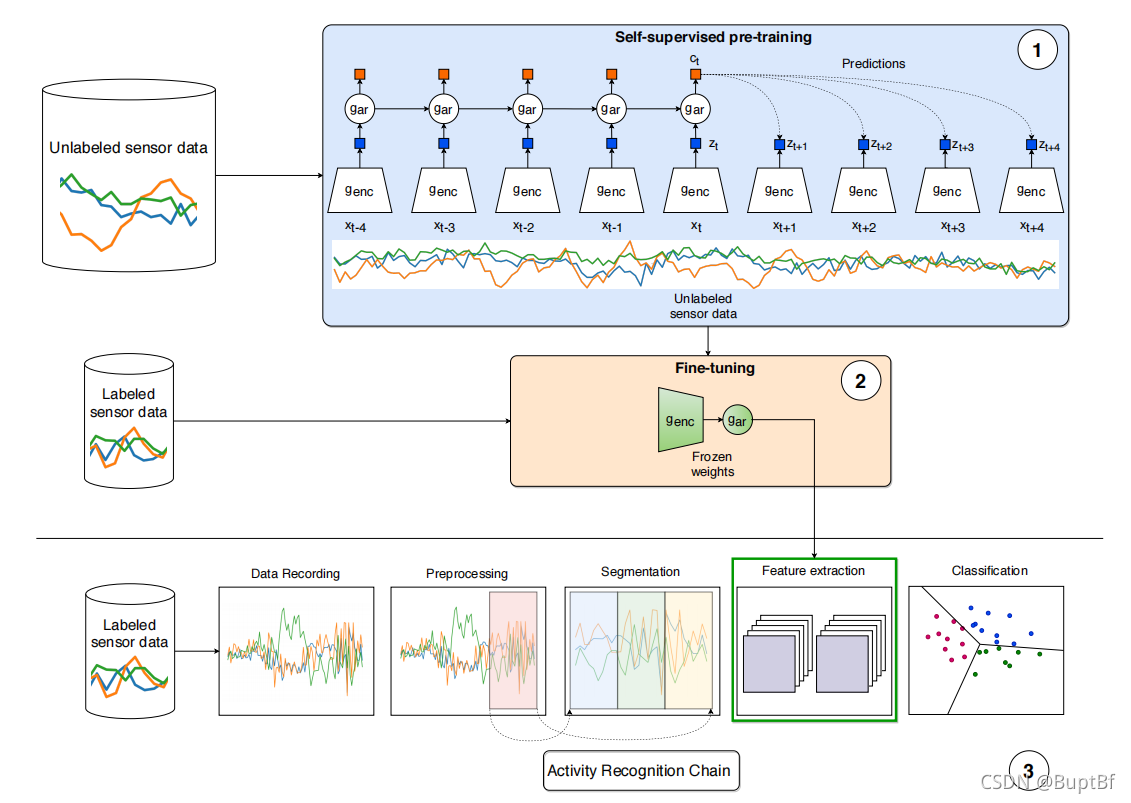
Fig. 1 outlines the overall workflow, which includes:
(i) pre-training (part 1 in Fig. 1), where unlabeled data are utilized to obtain useful representations (i.e., learn encoder weights) via the pretext task; and,
预先训练(图1中的第一部分),其中未标记数据通过藉由借口任务来获得有用的表示(即,学习编码器权值)
(大约就是使用借口任务让表示学习的权重得到学习)
(ii) fine-tuning, which involves performing activity recognition on the learned representations using a classifier (part 2 in Fig. 1).
微调,这涉及使用分类器对已学习的表示进行活动识别(图1中的第2部分)。
During pre-training, the sliding window approach is applied to large quantities of unlabeled data to segment it into overlapping windows.
They are utilized as input for self-supervised pre-training, which learns useful unsupervised representations.
在训练前,将滑动窗口方法应用于大量未标记数据,将其分割成重叠窗口。它们被用作自我监督前训练的输入,学习有用的无监督表征。
(大约就是在无监督学习的过程中,也使用滑动窗口这个方法,来学习这些表征)
Once the pre-training is complete, weights from both 𝑔𝑒𝑛𝑐 and 𝑔𝑎𝑟 are frozen and used for feature extraction (part 2 in Fig. 1).
一旦预训练完成,则冻结𝑔𝑒𝑛𝑐和𝑔𝑎𝑟的权重,用于特征提取(图1中的第2部分)。
This corresponds to the feature extraction step in the ARC (part 3 in Fig. 1).
这对应于ARC中的特征提取步骤(图1中的第3部分)。
第二段(怎么验证学习的有效性)
The frozen learned weights are utilized with the backend classifier network (see Sec. 3.2), a three-layer multilayer perceptron (MLP), in order to classify windows of labeled data into activities.
后台分类器网络(一个三层多层感知器,MLP)利用冻结的学习权值,将标记数据的窗口分类为行为。
This corresponds to the classification step in the ARC. The learned weights from CPC are frozen and only the classifier is optimized on (potentially smaller amounts of) labeled datasets.
这与ARC中的分类步骤相对应。从CPC学到的权值被冻结,只有分类器在(可能数量更少)标记的数据集上进行优化。
The resulting performance directly indicates the quality of the learned representations.
结果的性能直接表明了学习表示的质量。
第三段(介绍接下里的内容)
In what follows, we first detail our Contrastive Predictive Coding framework as it is applied to HAR, and then describe the backend classifier network used to evaluate the unsupervised representations.
在接下来的内容中,我们首先详细介绍对比预测编码框架在HAR中的应用,然后描述后端分类器网络用于评估无监督表示。
3.0.2总结
本文提出的内容的主要组成就是:
- 1.使用CPC从无标签数据当中来学习特征提取
- 2.使用有标签数据进行微调
- 3.前两个部分被称为预训练,之后使用提取的特征取代传统的行为识别的特征提取阶段。
之后使用三层全连接,来预测最终的行为识别结果,达到一个与测试表征学习质量的目标
总结就是使用了非常传统的对比学习思路。
3.1
4. HUMAN ACTIVITY RECOGNITION BASED ON CONTRASTIVE PREDICTIVE CODING基于对比预测编码的人体活动识别
4.0
4.0.1逐句翻译
第一段(总结上一段的内容:介绍模型设计,引出本文的实验)
In the previous section we have introduced our representation learning framework for movement data based on contrastive predictive coding.
在上一节中,我们介绍了基于对比预测编码的运动数据表示学习框架。
This pre-training step is integrated into an overarching human activity recognition framework, that is based on the standard Activity Recognition Chain (ARC) [8].
这个训练前的步骤被集成到一个全面的人类活动识别框架中,该框架基于标准的活动识别链(ARC)[8]。
(这里作者还在说他这个东西可以嵌入到常规的行为识别链当中)
Addressing our general goal of deriving effective HAR systems from limited amounts of annotated training data, as it is a regular challenge in mobile and ubiquitous computing settings, we conducted extensive experimental evaluations to explore the overall effectiveness of our proposed representation learning approach.
我们的总体目标是从有限数量的标注训练数据中获得有效的HAR系统,因为这是移动和普适计算环境中的一个常规挑战,我们进行了广泛的实验评估,以探索我们提出的表示学习方法的整体有效性。
(在此强调目标是使用广泛分布的传感器设备采集的数据进行行为识别。)
第二段(开始介绍本段的描述内容)
In what follows we provide a detailed explanation of our experimental evaluation, which includes descriptions of:
下面我们将对我们的实验评估进行详细的解释,包括以下内容的描述:
i) Application scenarios that our work focuses on;
我们工作重点关注的应用场景;
ii) Implementation details;
实现细节
iii) Evaluation metrics used for quantitative evaluation; and
用于定量评价的评价指标;和
iv) Overall experimental procedure. Results of our experiments and discussion thereof are presented in Sec. 5.
整个实验过程。我们的实验结果和讨论将在第5节中给出。
4.0.2总结
这一部分大约就是一个承上启下的作用
4.1 Application Scenarios
4.3 Performance Metric
The test set mean F1-score is utilized as the primary metric to evaluate performance.
测试集的平均f1分数被用来作为评估性能的主要指标。
The datasets used in this study show substantial class imbalance and thus experiments require evaluation metrics that are less affected negatively by such biased class distributions [64].
本研究使用的数据集显示了严重的分类与分类之间的不平衡,因此实验需要的评价指标受这种偏置的阶级分布的负面影响较小[64]
The mean F1-score is given by:
f1的平均分是:
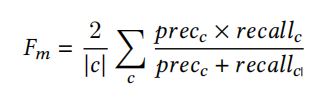
where |𝑐| corresponds to the number of classes
其中|𝑐|对应类的数量
while 𝑝𝑟𝑒𝑐𝑐 and 𝑟𝑒𝑐𝑎𝑙𝑙𝑐 are the precision and recall for each class.
precc和recallc是对应每个分类的precision and recall
(带几个数据进去可以知道这个东西确实有效,但是不知道为啥有效,具体为啥应该得去看文章:Evaluation: from precision, recall and F-measure to ROC)
5 RESULTS AND DISCUSSION结果与讨论
5.1 Activity Recognition
第一段(介绍实验开展方式)
We perform CPC-based self-supervised pre-training and integrate the learned weights as a feature extractor in the activity recognition chain.
我们进行基于cpc的自我监督预训练,并将学习到的权值作为特征提取器集成到活动识别链中。
In order to evaluate these learned representations, we compute their performance on the classifier network (Sec. 3.2).
为了评估这些习得的表示,我们计算它们在分类器网络上的性能(第3.2节)。
The performance obtained by CPC is contrasted primarily against previous unsupervised approaches including multi-task self supervised learning [69], convolutional autoencoders [31], and masked reconstruction [32].
CPC获得的性能主要与之前的无监督方法进行了对比,包括多任务自监督学习[69]、卷积自编码器[31]和掩码重构[32]。
For reference, we also compare the performance relative to the supervised baseline–DeepConvLSTM [59]– and a network with the same architecture as CPC, albeit trained end-to-end from scratch.
作为参考,我们还比较了相对于有监督的基线DeepConvLSTM[59]和具有与CPC相同架构的网络的性能,尽管是从头到尾训练的。
Once the model was pre-trained using CPC, the learned weights (from both 𝑔𝑒𝑛𝑐 and 𝑔𝑎𝑟) were frozen and used with the classifier network. Labeled data was utilized to train the classifier network using cross entropy loss and the test set mean F1-score was detailed in Tab. 2.
一旦使用CPC对模型进行预训练,学习到的权值(来自𝑔𝑒𝑛𝑐和𝑔𝑎𝑟)将被冻结并与分类器网络一起使用。利用标记数据利用交叉熵损失训练分类器网络,测试集f1均值得分详见表2。
第二段()
We first compare the performance of the CPC-based pre-training to state-of-the-art unsupervised learning approaches.
我们首先比较了基于cpc的前训练和最先进的无监督学习方法的表现。
We note that all unsupervised learning approaches are evaluated on the same classifier network (Sec.3.2), which is optimized during model training for activity recognition.
我们注意到,所有的无监督学习方法都在同一个分类器网络上进行评估(章节3.2),该网络在活动识别的模型训练中进行了优化。
On Mobiact, Motionsense and USC-HAD, CPC-based pre-training outperforms allstate-of-the-art unsupervised approaches.
For UCI-HAR, the performance
is comparable to masked reconstruction. This clearly demonstrates the effectiveness of the pre-training thereby
fulfilling one of the goals of the paper – which is to develop effective unsupervised pre-training approaches. It also
validates our hypothesis that explicitly incorporating temporality at the representation level itself is beneficial
towards learning useful representations.


















 1501
1501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











