







文章:《DeepLoco:Dynamic Locomotion Skills Using Hierarchical Deep Reinforcement Learning》
1、INTRODUCTION
提出了两级控制器DeeoLoco:低级控制器(low-level controller,LLC)和高级控制器(high-level controller,HLC)。
低级控制器在小的时间尺度上以保持平衡为主要目标,高级控制器在大的时间尺度上有更高层次的目标,比如路径规划。
两级控制器都使用actor-critic网络。
2、RELATEDWORK
系统结构如下:
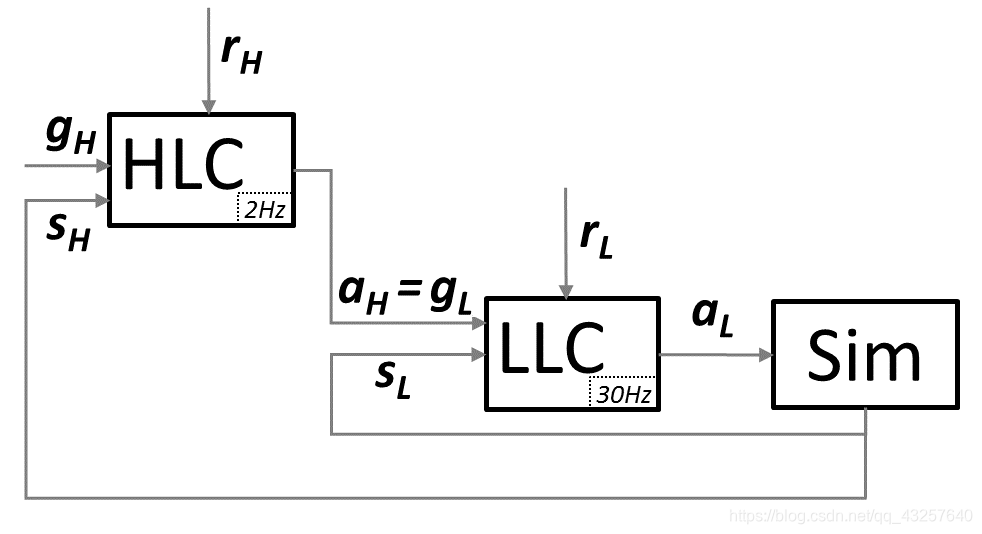
频率设定:系统仿真3khz,低级控制器30hz,高级控制器2hz。
g:goal, r:reward, s:state, a:action。
aH=gL,表示高级控制器的输出为低级控制器的目标。这里aH由一系列足迹组成。aL直接输入到模拟器里,估计就是最基础的关节角度之类的了。
3、POLICY REPRESENTATION AND LEARNING
actor
普通的actor网络。输入g,s,输出a的均值,再通过高斯分布的抽样得到a
π
(
s
,
g
,
a
)
=
p
(
a
∣
s
,
g
)
=
G
(
μ
(
s
,
g
)
,
θ
)
\pi(s,g,a) = p(a|s,g) = G(\mu(s,g),\theta)
π(s,g,a)=p(a∣s,g)=G(μ(s,g),θ)
a
=
μ
(
s
,
g
)
+
λ
N
,
N
∼
G
(
0
,
θ
)
a=\mu(s,g)+\lambda N,\quad N\sim G(0,\theta)
a=μ(s,g)+λN,N∼G(0,θ)
这里协方差矩阵
θ
=
d
i
a
g
(
σ
i
)
\theta=diag({\sigma_i})
θ=diag(σi)是固定参数。
σ
i
\sqrt{\sigma_i}
σi取a变化范围的10%比较合适。考虑到噪声N有可能会使训练失败,加入服从概率为
ϵ
\epsilon
ϵ的伯努利分布的参数
λ
∈
[
0
,
1
]
\lambda \in[0,1]
λ∈[0,1]。
value
普通的value网络。不赘述。
update
更新时仅使用 λ = 1 \lambda=1 λ=1的数据。使用PolicyGradient。不赘述。
4、LOW-LEVEL CONTROLLER
Reference Motion
为了让LLC学得更快更好,引入了参考动作。参考动作由和LLC差不多的state组成。为了采集参考动作,分别从走路和转弯的过程截取7秒,再从7秒里采集step。一个step始于支撑脚的脚后跟着地,止于摆动脚的脚后跟着地。为了统一,将每个step线性归一化到0.5s。
LLC
LLC state: 关节的位置,旋转角度,线速度,角速度,脚是否触地,标志阶段的变量
ϕ
\phi
ϕ。
LLC goal:接下来两步的期望位置坐标(x,y)(为什么是两步而不是更多步请参考原文),身体期望角度。
LLC action:关节位置。
LLC reward:综合了关节位置与参考动作关节位置的距离和实际脚步位置与期望脚步位置的距离。
Bilinear Phase Transform
LLC state中的阶段变量
ϕ
\phi
ϕ在每个step内会以一定的速率增加。比如一个step持续1s,假设
0
≤
ϕ
≤
2
0\le\phi\le2
0≤ϕ≤2,则
ϕ
=
2
t
\phi=2t
ϕ=2t。
问题是一个变量不足以明显地体现阶段的差别,因为还有上百个变量一同作为actor网络的输入,
ϕ
\phi
ϕ在网络中的作用就微乎其微了。
提出了一种解决办法:
令
Φ
=
(
Φ
0
,
Φ
1
,
Φ
2
,
Φ
3
)
Φ
i
∈
{
0
,
1
}
\Phi =(\Phi_0,\Phi_1,\Phi_2,\Phi_3)\quad \Phi_i \in \{0,1\}
Φ=(Φ0,Φ1,Φ2,Φ3)Φi∈{0,1} 且
Φ
i
=
1
\Phi_i = 1
Φi=1时0.25i<
ϕ
\phi
ϕ<0.25(i+1)。在将actor网络输入变成下面这样

虽然维数变成原来的四倍,但阶段间输入高度不相关且稀疏。
Training
在episode开始初始化机器人的位置。每个episode持续200s,若摔倒则提前结束。每个step的gL由前一个gL‘加上高斯噪声产生。每个step有新的参考动作产生。
Style Modification
在reward加入一些先验知识使机器人学到的动作更鲁棒和流畅。比如降低膝盖弯曲程度等。
可以先训练一个没有先验知识的普通actor网络,之后派生出有不同先验知识的fine-tune过的网络。将所有网络的输出线性加权得到最终的action。实验表明这样做效果不错。
5、HIGH-LEVEL CONTROLLER
HLC
HLC state:既包含机器人传感器的信息也包含外界环境信息,可以表示为
s
H
=
(
C
,
T
)
s_H=(C,T)
sH=(C,T),其中C与
s
L
s_L
sL大部分重合除了是否触地变量和阶段变量。T表示机器人周围11m*11m(前10m,后1m)的地形信息。
HLC action: 等同于 LLC goal。
Network
HLC网络结构如下:
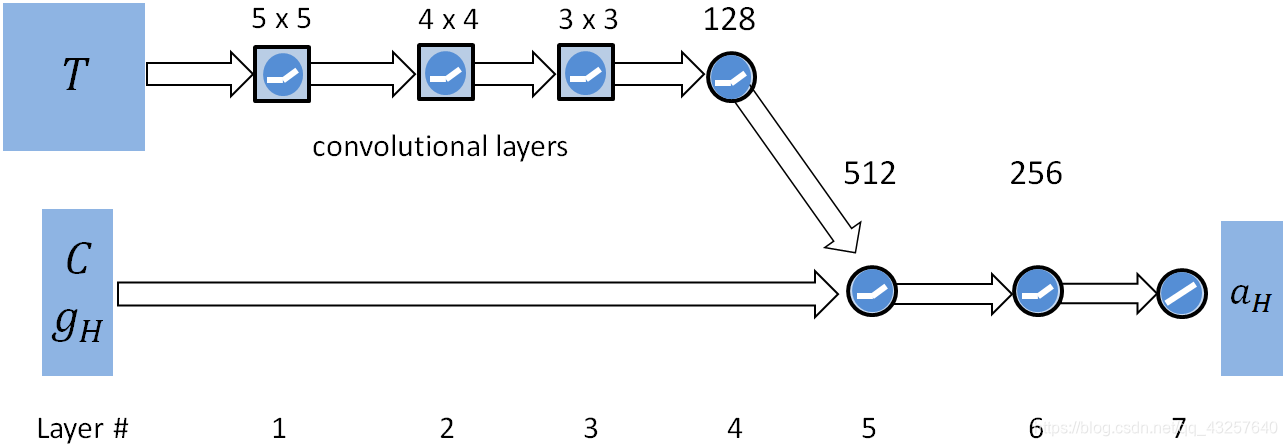
T被单独的卷积网络降维成512维的特征向量才输入actor网络
Training
每个epsiode开始前机器人处于默认位置。epsiode持续200s,若摔倒则提前终止。每个step前HLC的actor输出一个aH交给LLC执行。
注意HLC和LLC分开训练。
Tasks
任务决定了HLC goal和reward。goal 可以看成是具体任务对state的补充。
6、CONCLUSION
基本的分级学习思路和基本的算法。有很多小技巧可以借鉴。

















 1280
1280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









