







大家好,我是苍何。
离谱,以前我看不上外包,现在外包看不上我!
这是不少读者给反馈的消息,华为 OD 打开了外包新世界的大门,什么薪资,什么年终奖,什么转正,该有的通通给你满足。
除了那不值一提的「外包」字眼,其他都值得一提。
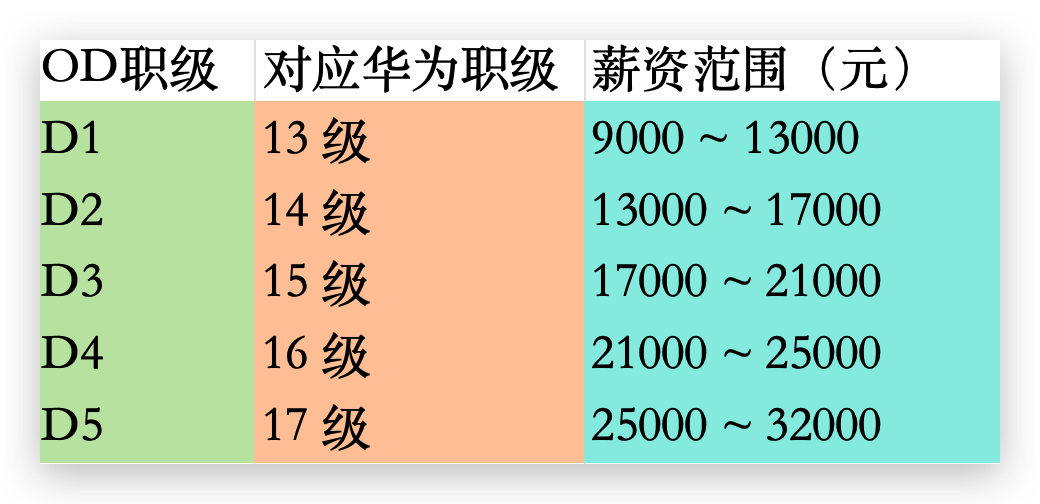
- D1对应华为的13级,薪资中位数在9k-13k之间。
- D2对应华为的14级,薪资中位数在13k-17k之间。
- D3对应华为的15级,薪资中位数在17k-21k之间。
- D4对应华为的16级,薪资中位数在21k-25k之间。
- D5对应华为的17级,薪资中位数在25k-32k之间
华为 OD 薪资除了基本的 base 薪资,还有绩效工资和年终奖。
除此之外,OD 也是有加班费的,加班工资为平时工资的两倍,但每个月的最后一个星期六默认需要加班,若不参加需要额外请假。
带薪年假、夜宵、班车、加班打车报销等福利等福利也和正式员工一样。
那很多人就问,这样说和华为正式编有啥区别啊?
区别还是有的,首先 OD 从性质上就是个外包,薪资普遍低于同等级别的正式员工。
例如,以14级为例,正式员工的基本工资通常在20k以上,而OD员工的薪资则在13k-17k之间
此外,OD员工的绩效奖金可能比正式员工少一些,OD 年终奖的范围在 2~4 个月。
为什么少些?OD 不是跟华为签订的劳动合同,而是其他公司,比如外企德科这样的人力公司,华为还得给人家企业钱呢,所以到你手里自然而然变少。
很多人关心 OD 的转正机会,硬性条件比如你要绩效A 吧,你得至少干满一年吧,你还得被华为高度认可才行。
有没有机会,机会还是有的,那得靠自己的努力和运气在了。
不过,从综合来看,OD 比一些中小厂薪资好少不少了,如果没有更好的选择,OD 或许可以解决燃眉之急吧。
对此,你怎么看,「新式外包」你心动了吗?欢迎评论区讨论。
…
回归主题。
今天来一道华为 OD 考过的面试算法题,给枯燥的牛马生活加加油😂。
题目描述
平台:LeetCode
题号:219
题目名称:存在重复元素 II
给你一个整数数组 nums 和一个整数 k,判断数组中是否存在两个 不同的索引 i 和 j,满足 nums[i] == nums[j] 且 abs(i - j) <= k。如果存在,返回 true;否则,返回 false。
示例 1:
输入:
nums = [1,2,3,1], k = 3
输出:
true
示例 2:
输入:
nums = [1,0,1,1], k = 1
输出:
true
示例 3:
输入:
nums = [1,2,3,1,2,3], k = 2
输出:
false
提示:
- 1 <= nums. length <= 10^5
- -10^9 <= nums[i] <= 10^9
- 0 <= k <= 10^5
解题思路
这道题目要求在数组中查找满足一定条件的两个元素。具体来说,元素值相同且索引差值不超过 k。
我们可以使用哈希表(字典)来记录每个元素上次出现的索引。遍历数组时,对于当前元素 nums[i]:
- 如果该元素已经存在于哈希表中,并且满足当前索引
i与之前出现的索引差值不超过k,则返回true。 - 如果条件不满足,更新哈希表,将该元素的索引更新为当前索引。
如果遍历结束后没有找到符合条件的元素对,则返回 false。
复杂度分析:
- 时间复杂度:O (n),其中
n是数组的长度。我们遍历一次数组,每次操作哈希表的时间复杂度为均摊 O (1)。 - 空间复杂度:O (n),哈希表在最坏情况下需要存储
n个元素。
代码实现
Java 代码:
import java.util.HashMap;
public class Solution {
public boolean containsNearbyDuplicate(int[] nums, int k) {
// 创建一个哈希表存储数字和对应的索引
HashMap<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
// 检查当前数字是否在哈希表中,且索引差值是否不超过 k
if (map.containsKey(nums[i]) && i - map.get(nums[i]) <= k) {
return true;
}
// 更新哈希表中的当前数字的索引
map.put(nums[i], i);
}
return false;
}
}
C++ 代码:
#include <unordered_map>
#include <vector>
using namespace std;
class Solution {
public:
bool containsNearbyDuplicate(vector<int>& nums, int k) {
// 创建一个哈希表存储数字及其索引
unordered_map<int, int> map;
for (int i = 0; i < nums.size(); i++) {
// 如果当前数字存在且满足索引差值不超过 k
if (map.find(nums[i]) != map.end() && i - map[nums[i]] <= k) {
return true;
}
// 更新哈希表
map[nums[i]] = i;
}
return false;
}
};
Python 代码:
def contains_nearby_duplicate(nums, k):
# 创建一个哈希表存储数字和索引
num_map = {}
for i, num in enumerate(nums):
# 如果当前数字存在于哈希表且索引差值不超过 k
if num in num_map and i - num_map[num] <= k:
return True
# 更新哈希表
num_map[num] = i
return False
# 示例调用
nums = [1, 2, 3, 1]
k = 3
print(contains_nearby_duplicate(nums, k)) # 输出: True
ending

你好呀,我是苍何。是一个每天都在给自家仙人掌讲哲学的执着青年,我活在世上,无非想要明白些道理,遇见些有趣的事。倘能如我所愿,我的一生就算成功。共勉 💪
点击关注下方账号,你将感受到一个朋克的灵魂,且每篇文章都有惊喜。
更多更全更热门的「笔试/面试」相关资料可访问排版精美的 合集新基地 🎉🎉


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











