







2.2.2 NVGRE 技术
介绍完了 VXLAN, 再来讨论 NVGRE。 NVGRE 是 Network Virtualization using Generic Routing Encapsulation 的缩写,是将以太网报文封装在 GRE 内的一种隧道转发模式,最初由 Microsoft 提出, 并联合了 Intel、 HP、 DELL 等公司,向 IETF 提出。其实与 VXLAN 相比,它 除了将 MAC 封装在 GRE 内(与 VXLAN 将 MAC 封装在 UDP 内不同)外,其他功能几乎完 全相同。 比如, NVGRE 定义了一个类似 VNI 的 TNI(Tenant Network Identifier), 长度同样是 24 比特, 同样可以扩展到 16777216(2 的 24 次方)个网段(NVGRE 里面叫做租户)。
硬说两者有什么区别的话,就是 VXLAN 新的 UDP 头部中包含了对原始二层帧头的哈 希结果,容易实现基于等价多路径的负载均衡,而 GRE 的头部实现负载均衡要困难些— 很多网络设备不支持用 GRE 的 Key 来做负载均衡的哈希计算。
VXLAN 和 NVGRE 技术有惊人的相似之处,或许两者都无法最终成为行业标准,只 能在围绕着 Cisco、 VMware、 Microsoft 的战略联盟(Ecosystem)内部进行标准化。
2.2.3 STT 技术
再来讨论另一种隧道技术 STT(Stateless Transport Tunneling, 无状态传输隧道),它是 Nicira 的私有协议。 STT 利用 MAC over IP 的机制, 与 VXLAN、 NVGRE 类似,把二层的 帧封装在一个 IP 报文之上。 STT 协议很聪明地在 STT 头部前面增加了一个 TCP 头部,把 自己伪装成一个 TCP 包。 但和 TCP 协议不同的是,这只是一个伪装的 TCP 包,利用了 TCP 的数据封装形式,但改造了 TCP 的传输机制—数据传输不遵循 TCP 状态机,而是全新 定义的无状态机制,将 TCP 各字段的意义重新定义,无需三次握手建立 TCP 连接,也没 有用到 TCP 那些拥塞控制、丢包重传机制,因此 STT 被 Nicira 称为无状态 TCP。 STT 技 术除了用于隧道封装,还可以用于欺骗网卡—数据中心内部的 TCP 报文往往非常大,在 发出去之前经常需要分片, 但分片以前往往需要 CPU 处理, 从而影响 CPU 性能,因此现在绝 大多数服务器网卡支持报文分片,不由 CPU 来处理,也就减轻了 CPU 的负担。然而通过网卡 进行分片只能针对 TCP 报文,通过 VXLAN 或者 NVGRE 协议封装的原始 TCP 报文到达网卡 后,网卡认为它们不是 TCP 报文,就无法分片了,这就还是需要 CPU 来进行分片工作, 也就 增加了 CPU 负担,降低了服务器性能(最新推出的一些网卡声称可以对 VXLAN 进行分片, 但其技术上不成熟)。而 STT 的头部是 TCP 格式,这样网卡就会认为它是 TCP,从而对大包 进行分片。 但实际上它不是 TCP,也无需三次握手, 因此提高了 CPU 的效率。 STT 技术在 Nicira 被 VMware 收购前只能用于 Nicira NVP 平台之上,被收购后主要用在部署了多 Hypervisor 的 NSX 网络虚拟化环境,即 NSX-MH 架构中。
2.2.4 三种 Overlay 技术的对比和应用场景
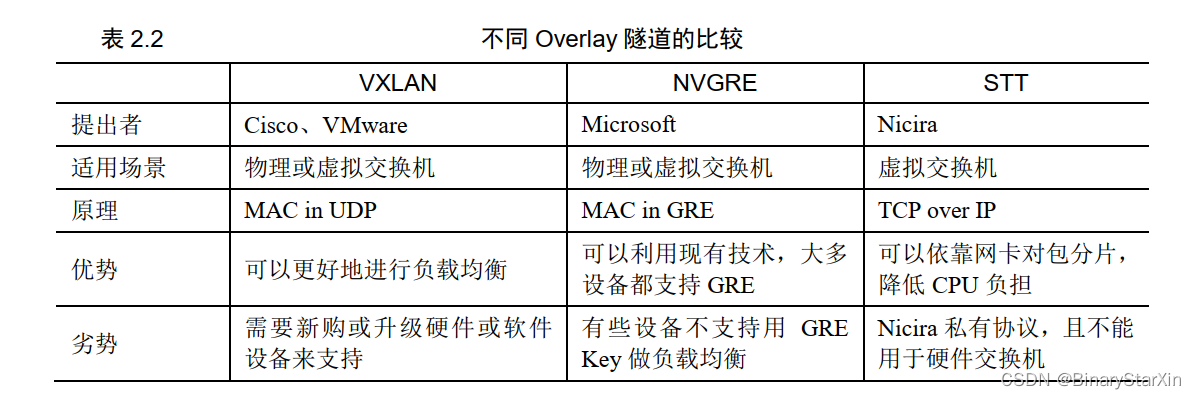
介绍完三种 Overlay 隧道技术,我们将其做一个对比,如表 2.2 所示。
VMware 的 NSX-V 网络虚拟化解决方案在 Overlay 层使用 VXLAN 技术,为虚拟网络 提供服务—利用 VMware 的 NSX 环境中支持 VXLAN 的分布式逻辑交换机对数据包进行 封装和解封装,从而实现网络虚拟化,而其中间的物理网络变得就不重要了。 VXLAN 甚 至可以在多数据中心之间进行扩展,因为无论数据中心之间的运营商链路、路由协议多么 复杂,只要打通了隧道,就可以看作一个简单的二层链路。
VMware NSX 利用这个技术, 在三层网络之实现了大二层扩展和多租户环境。 其他物理硬件厂商近几年新推出的交换机,大多都支持 VXLAN,可以由连接服务器 的 ToR 交换机对 VXLAN 流量进行封装和解封装。 当然这种解决方案不是基于主机的 Overlay,也没有实现控制平面和转发平面的分离。 而 STT 作为先前的 Nicira 私有协议,在其被 VMware 收购后,主要运用在 NSX-MH 网络 虚拟化架构中,是 NSX-MH 中的默认隧道协议。这是因为 STT 有其绝佳的优势—可以减轻 服务器 CPU 的负担。当然 NSX-MH 同样也支持 GRE 和 VXLAN。 而 NVGRE 目前已广泛用于以 Microsoft Hyper-V 搭建的虚拟化环境中,但主要应用在 Azure 公有云,而没有在企业级的虚拟化环境中广泛部署。 它与 VMware 的 Overlay 方案非常类 似—在 Hyper-V 的 Hypervisor 之上给数据包打上 Tag(标签),封装进 GRE 隧道,到达目的 Hypervisor 时解封装。 未来 Overlay 技术究竟走向何方,这就要看几大 IT 巨头如何斗法了。这些巨头们身边 都有战略合作伙伴,都打造了一个属于自己的生态圈。
2.2.5 下一代 Overlay 技术—Geneve
最后来介绍另一种未来会出现的 Overlay 技术。诚然, Overlay 解决了一些问题,但其封装头格式固定,不利于修改和扩展—毕竟一些特殊应用的数据包需要在封装过程中添 加一些额外的信息。比如在端口镜像的报文附加逻辑交换机目的端口信息,用于目的端口 不能在隧道终点被可视化的情况;比如在报文附加逻辑交换机源端口信息或应用及服务的 上下文,以指导隧道终端的转发决策或服务策略实施;比如标识 Traceflow 报文,用于抓包 或整网健康状况的可视化。因此, VMware、 Microsoft、 Red Hat、 Intel 几家公司正在联合研 发 Geneve(Generic Network Virtualization Encapsulation)协议来解决这些问题。它的报文格 式其实也使用了 UDP 进行封装,也有 24 比特的网段级别,但是它在报文中增加了一个可选 字段(Option),允许虚拟化应用实现扩展。 Geneve 设想的报文如图 2.8 所示。

在将来, Geneve 协议会非常适用于服务链的场景。例如, NSX 可以创建一个服务的逻辑连
接(如图 2.9 所示,它可以为 VPN 服务、防火墙服务、第三方服务之间的关系创建成一个逻辑
关系),而这些逻辑链的节点之间需要传递元数据。有了 Geneve 协议, 头部可以进行变更和扩
展后,就可以指示报文的下一个链节点, 并将报文分类(Classification) 的结果传递到一个服务。

Geneve 协议不仅支持将 IPv4 封装在 UDP 里,还支持 IPv6。该研发项目已提交 IETF。 或许在不久的将来,我们就可以看到这种技术被标准化,并广泛用于数据中心内部。
2.3 各厂商的网络虚拟化解决方案
介绍完几种 Overlay 技术之后,我们就需要对比一下几大厂商基于 Overlay 技术的网络 虚拟化解决方案了。各家厂商的解决方案各有千秋,各有利弊。在这里介绍它们的网络虚 拟化解决方案,目的是让读者对整个行业的趋势有一个了解,也让读者了解 VMware NSX 网络虚拟化解决方案在行业中所处的地位。
2.3.1 Cisco ACI 解决方案
Cisco ACI 是 Cisco 公司提出的 SDN 和网络虚拟化解决方案,它的主要组件有应用策 略基础设施控制器(APIC)和 ACI 交换矩阵, 其逻辑架构如图 2.10 所示。
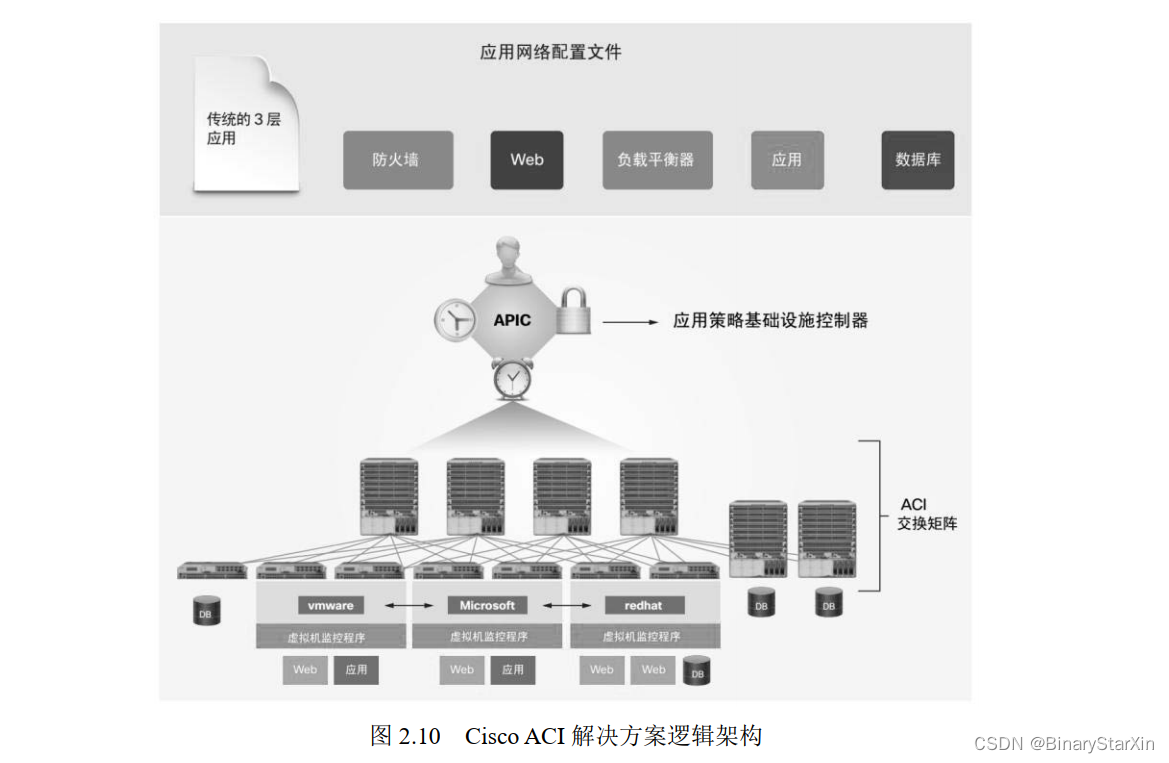
1. Cisco 应用策略基础设施控制器(APIC) APIC 是 Cisco ACI 解决方案的主要组件。它是 Cisco ACI 解决方案中实现交换矩阵、 策略实施、健康状态监控、自动化和进行中央管理的统一平面。目前, APIC 一般是以软件 形式安装在 Cisco UCS 服务器中,一般建议购买 3 台以上从而实现集群和冗余。 Cisco APIC 负责的任务包括交换矩阵激活、交换机固件维护、网络策略配置和实例化。 Cisco APIC 完全与数据转发无关,对数据平面只有分发指令功能。这意味着即使与 APIC 的通信中断,交换矩阵也仍然可以转发流量。 Cisco APIC 通过提供 CLI 和 GUI 来管理交换矩阵。APIC 还提供开放的 API,使得 APIC 可以管理其他厂家的设备。
2. Cisco ACI 交换矩阵 Cisco 在推出 ACI 解决方案的同时, 还推出了 Cisco Nexus 9000 系列交换机。Nexus 9500 为机箱式的核心交换机(骨干节点交换机), Nexus 9300 为 2U 或 3U 高度的非机箱式汇聚/ 接入交换机(枝叶节点交换机)。 Cisco Nexus 9000 系列交换机可以部署在 ACI 环境下,也 可以独立部署。如果是独立部署,以后也可以升级到 ACI 环境,但需要其软件和板卡支持 ACI 才行。这些 Nexus 9000 系列交换机实现了 ACI 环境下的底层物理网络,在这套物理网 络之上,可以非常便捷地通过 VXLAN 实现虚拟网络。 除了物理交换机外, ACI 解决方案还可以在虚拟化环境中安装 Cisco AVS( Cisco Application Virtual Switch),作为虚拟交换机。
Cisco在Nexus 9000交换机中混用了商用芯片和自主研发的芯片—商用芯片处理普通流 量,而自主研发的芯片处理 ACI 流量, 即 SDN 和网络虚拟化中的流量。 APIC 控制器直接将 指令发布给 Nexus 9000 中的自主研发芯片,再由芯片分布式地处理数据流量。换言之, ACI 环境中真正的控制平面是 Nexus 9000 交换机中的自主研发芯片。这样设计的好处是,数据控 制和转发都与软件无关,而是听命于芯片,消除了软件控制可能带来的瓶颈。因此 Cisco 的 ACI 解决方案与 SDN 反其道而行之,其实是一种 HDN(H 为 Hardware)。
对于传统 SDN 集中了网络复杂性的问题, Cisco ACI 解决方案中引入了一个完全与 IP 地址无关的策略模型。这个模型是一种基于承诺理论的面向对象的导向模型。承诺理论基 于可扩展的智能对象控制,而不是那种管理系统中自上而下的传统命令式的模型。在这个 管理系统中, 控制平面必须知晓底层对象的配置命令及其当前状态。相反,承诺理论依赖 于底层对象处理, 由控制平面自身引发的配置状态变化作为“理想的状态变化”,然后对象 作出响应,将异常或故障传递回控制平面。这种方法减少了控制平面的负担和复杂性,并 可以实现更大规模的扩展。这套模型通过允许底层对象使用其他底层对象和较低级别对象 的请求状态变化的方法来进行进一步扩展。
2.3.2 在 Microsoft Hyper-V 中实现网络虚拟化
Microsoft 也提供了基于 Hyper-V 虚拟化平台的网络虚拟化产品,由于它不像 NSX、 ACI 那样有完整的解决方案,因此目前还没有被正式命名,一般被称为 HNV(Hyper-V Network Virtualization),它以 Windows Server 2012 中的网络附加组件形式加载在 Hyper-V 的虚拟化平台之上。
Microsoft HNV 的研发代码是通过 Scratch 编写的,且只支持 Hyper-V 一款 Hypervisor, 没有进行公开化。 也就是说,这种网络虚拟化平台只能部署在纯 Hyper-V 环境。部署 HNV 所需的最低 Hyper-V 版本为 3.0,它在 Windows Server 2012(包括 R2)操作系统中以角色 的方式提供给 Hyper-V,作为服务模块加载。在 HNV 中,使用的是 NVGRE 协议实现 Overlay (之前已阐述)。为了将流量从物理环境迁移到虚拟环境,或者将虚拟网段迁移到其他虚拟网段, 需要部署 Windows Server 2012 R2 Inbox Gateway 或者第三方网关设备。
Microsoft 使用 Hyper-V可扩展交换 API 对 HNV 进行了扩展,我们可以使用 PowerShell cmdlets 对 API 进行再编程, 最终实现网络虚拟化的自动化部署,进而实现整个数据中心的自动化。 HNV 可以通过以下两种方式进行部署: System Center Virtual Mmachine Manager (SCVMM) 和 HNV PowerShell cmdlets。 SCVMM 其实也是在后台使用 HNV PowerShell cmdlets,在 Hyper-V 平台上配置 HNV 组件,有一个统一的图形化界面。 在管理上, SCVMM 提供了跨越部署 Hyper-V 的物理服务器之间的 HNV 配置管理。 同时, SCVMM 是一款服务器虚拟化与网络虚拟化一体化的管理工具。
但是,由于 Microsoft 的网络虚拟化平台并没有基于 SDN 的理论基础实现,且只能支持 Hyper-V 平台,很多高级的网络功能也是缺失的,因此它不能算完整的网络虚拟化解决方案。 当然,当 Hyper-V 结合其 System Center 产品的时候,还是能达到较高的用户使用体验— System Center 可以为数据中心从基础架构到上层应用的绝大部分角色提供统一、便捷的管理。
2.3.3 Juniper Contrail 解决方案
2012 年初, Cisco、 Google、 Juniper 和 Aruba 公司的几名前高管创立了 Contrail 公司, 专注于 SDN 解决方案。 12 月,这家公司以 1.76 亿美元被 Juniper 公司收购,其产品和解决 方案融入 Juniper, Contrail 也成为 Juniper 的 SDN 和网络虚拟化解决方案的代名词。
Juniper 认为,当今数据中心逐渐采用基于 OpenFlow 的 SDN 控制器来对物理交换机进 行编程,以实现自动化。然而,这种方法具有与基于 VLAN 的多租户虚拟化方法相似的缺 陷,即存在可扩展性、成本和可管理性的缺陷。 OpenFlow 是基于流表转发的,数据中心内 存在数以千计的虚拟机,更有数百种数据流,因此在现今的低成本物理交换硬件中进行流 编程是一项艰巨的任务和挑战,或是仅能通过支持流管理的昂贵交换设备加以缓解。此外, 这种方法会降低管理基础结构的能力,因为租户/应用程序的状态编程在底层硬件之中,一 个租户/应用程序的问题会影响到其他租户/应用程序。
Juniper 认为它们的 Contrail 解决方案通过 Overlay 提供高级网络特性,从而解决了这 些自动化、成本、扩展性和可管理性的问题。所有网络特性(包括交换、路由、安全和负 载均衡)都可从物理硬件基础结构转移到 Hyperisor 中实现, 并有统一的管理系统。它在支 持系统扩展的同时, 还降低了物理交换基础结构的成本,因为交换硬件不贮存虚拟机或租 户/应用程序的状态,仅负责在服务器之间转发流量。此外, Contrail 系统还解决了敏捷性 问题,因为它提供了全部必要的自动化功能,支持配置虚拟化网络、联网服务。
Contrail 是一种横向扩展的网络堆栈,支持创建虚拟网络,同时无缝集成现有物理路由 器和交换机。它能支持跨公共云、私有云和混合云编排网络,同时提供有助自动化、可视 化和诊断的高级分析功能。图 2.11 是 Contrail 解决方案的架构。可以看到, Contrail 可以控 制物理网络,还可以通过 XMPP 协议管理虚拟化环境中的逻辑网络, 它支持的网络功能包括交换、路由、负载均衡、安全、 VPN、网关服务和高可用性,此外,它还提供面向虚拟网络和物理网络的可视化和诊断功能,以及用于配置、操作和分析的 REST API,并能够无缝集成到云编排系统(例如 CloudStack 或 OpenStack)或服务提供商运营和业务支持系统(OSS/BSS)。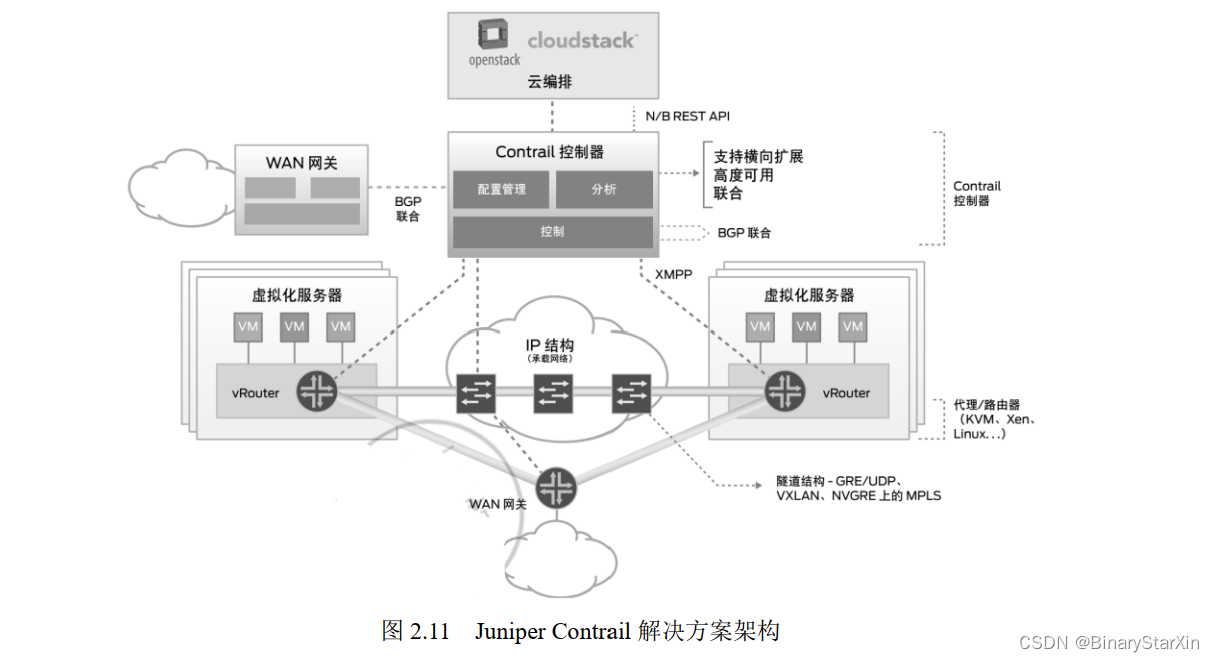
Juniper 的 Contrail 解决方案在 Overlay 层面其实并不是通过 VXLAN 或 NVGRE 协议来 搭建的,它的架构比较复杂。首先,它通过再编程,在 KVM 或 Xen 虚拟机上生成一个 vRouter (Vitural Router,虚拟路由器),值得注意的是, vRouter 不是虚拟交换机,而是虚拟路由器。 Contrail 控制器是通过 XMPP 协议控制 vRouter,使得加载 vRouter 的 KVM 或 Xen 主机之 间实现了基于 MPLS 技术的互连。而 Contrail 控制器在物理网络层面使用 BGP 协议来互连 和扩展物理网络。
















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











