









原来很早就有人用 Diffusion 做分割了~
论文: Diffusion Transformer U-Net for Medical Image Segmentation
0、摘要
扩散模型在各种生成任务中展现了其强大的能力。然而,在医学图像分割中应用扩散模型时,仍需克服几个障碍:(1)扩散过程中条件化所需的语义特征与噪声嵌入不能很好地对齐;(2)扩散模型中使用的U-Net主干对反向扩散过程中准确像素级分割所必需的上下文信息不敏感。(第一条不太理解~)。
为了克服这些局限性,本文提出了一个交叉注意力模块来增强来自源图像的条件,并提出了一个基于 Transformer 的 U-Net,具有多尺寸窗口,用于提取不同尺度的上下文信息。
在 Kvasir-Seg、CVC Clinic DB、ISIC 2017、ISIC 2018 和 Refuge 5个不同成像模态的基准数据集上进行评估,Diffusion Transformer U-Net 实现了出色的泛化能力,并在这些数据集上具有 SOTA 结果。
1、引言
1.1、不同网络架构的固有局限
(1)CNN 能够提取局部特征,但不能直接提取全局特征;
(2)ViT 使用固定窗口,限制了其提取精确像素级分割所需的精细上下文细节的能力;
(3)DDPM 从源图像中提取的语义嵌入与扩散过程中的噪声嵌入未能有效对齐,从而导致条件化效果不佳,进而影响了模型的整体性能表现。;
(4)基于 DDPM 的方法中的 UNe t主干在反向扩散(去噪)过程中对各种尺度的上下文信息不敏感,这在CNN和ViT中也有观察到。;
1.2、本文贡献
(1)提出一种具有前向和反向过程的条件扩散模型来训练分割网络。在去噪过程中,通过一个新的交叉注意力模块,将噪声图像的特征嵌入与源图像(条件)的特征嵌入对齐。然后,通过分割网络将其去噪为源图像的分割掩码;
(2)设计了一种基于 Transformer 的多尺寸窗口的 U-Net,命名为 MT U-Net,用于提取像素级和全局上下文特征,以实现良好的分割性能;
(3)由扩散模型训练的 MT U-Net 在各种成像模式上具有出色的泛化能力,在 5 个基准数据集上均具有 SOTA 结果;
2、方法
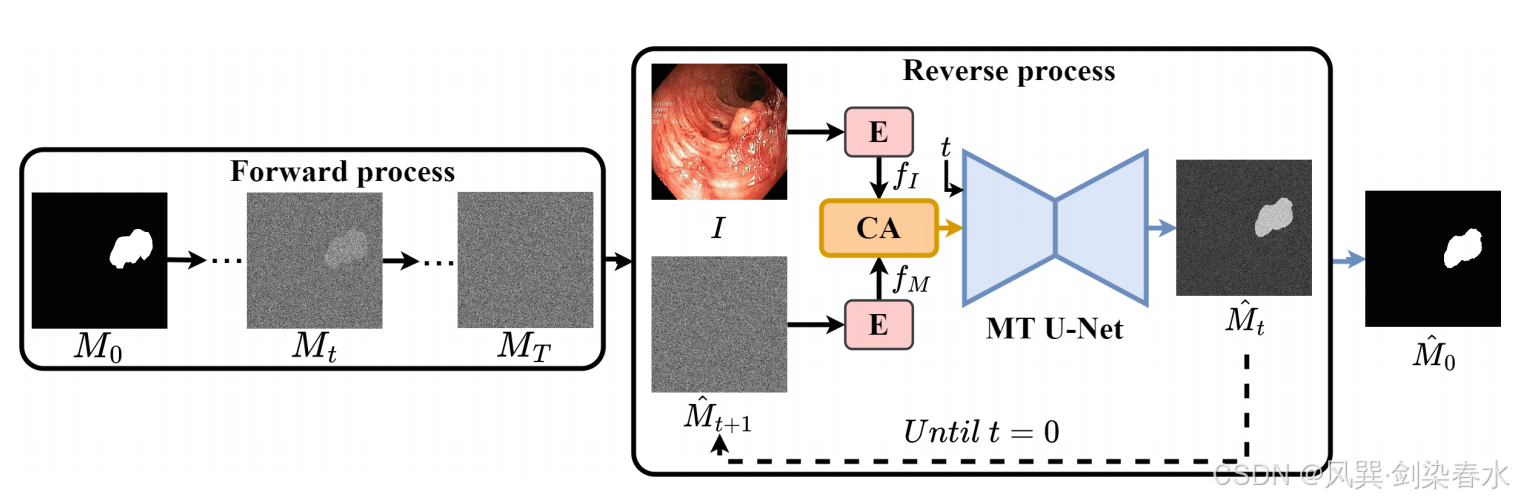
Figure 1 | 带有交叉注意力(CA)的扩散模型来训练 MT U-Net
2.1、Diffusion Model
扩散过程分为两个过程(图1):前向过程和反向过程。在前向过程中,通过 T T T 个时间步逐渐加入高斯噪声,将真实标签 M 0 M_0 M0 转换为噪声 M T M_T MT。在反向过程中,首先,源图像 I I I 和噪声图 M ^ t + 1 \hat M_{t+1} M^t+1 通过编码器 E E E(两个残差-初始块)获得嵌入 f I ∈ R h × w × c 1 f_I \in R^{h×w×c_1} fI∈Rh×w×c1 和 f M ∈ R h × w × c 2 f_M \in R^{h×w×c_2} fM∈Rh×w×c2(下标 I I I 和 M M M 分别表示图像和带噪标签),其中 h h h、 w w w 和 c 1 c_1 c1( c 2 c_2 c2)分别是嵌入的高度、宽度和通道数。
然后,通过特征空间中的交叉注意力(CA)模块对两个嵌入进行对齐。对齐后的特征图作为噪声输入提供给 MT U-Net 以恢复 M ^ t \hat M_{t} M^t,这个反向过程从 t = T − 1 t = T−1 t=T−1 开始,迭代到 t = 0 t=0 t=0(即,当 t = T − 1 t = T−1 t=T−1 时,初始 M ^ t + 1 \hat M_{t+1} M^t+1 即 M ^ T \hat M_{T} M^T ,被设置为 M T M_{T} MT,最终恢复 M ^ 0 \hat M_{0} M^0,预期其与真实值 M 0 M_0 M0 相同)。
图2 展示了 CA 模块的架构,该模块用于对齐
f
M
f_M
fM 和
f
I
f_I
fI,以改善扩散模型的条件。首先,将
f
M
f_M
fM 和
f
I
f_I
fI 分成 patch 块,并通过 Patch Encoding(PE)层展开成向量。(ViT 的 patch 嵌入吧)然后,使用位置编码层(PoE)获得 patch 的位置信息,并将其添加到原始 patch 嵌入中以保持其位置信息。
Figure 2 | 交叉注意(CA)模块的架构
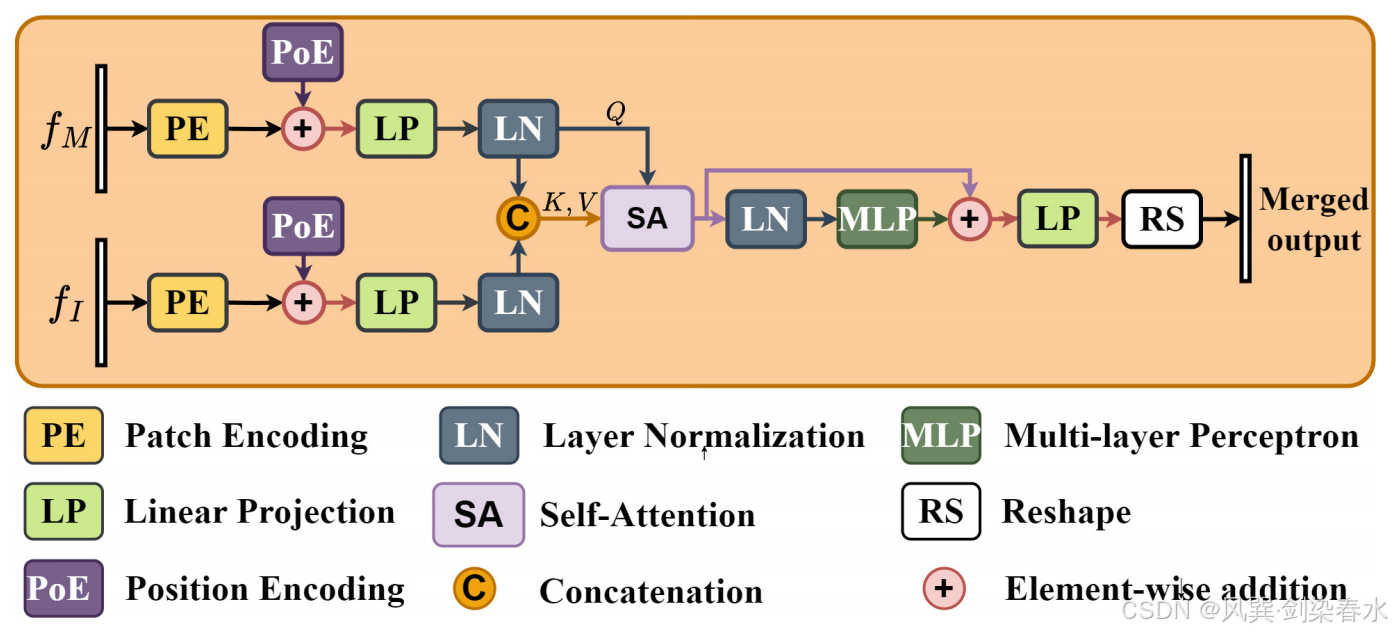
使用线性投影(LP)层对齐两个包含位置信息的 patch 嵌入,并通过层归一化(LN)进行归一化,将两个 LN 之后的输出表示为
f
M
p
∈
R
d
f_M^p∈R^d
fMp∈Rd 和
f
I
p
∈
R
d
f_I^p∈R^d
fIp∈Rd(patch 的
d
d
d 维特征向量)。最后,使用自注意力机制实现高效的特征融合:
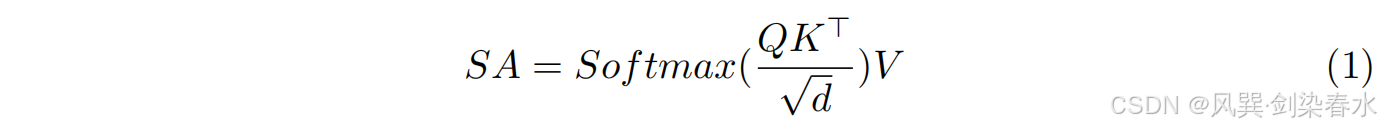
其中,
f
M
p
f_M^p
fMp 是查询(Q),
f
M
p
f_M^p
fMp 和
f
I
p
f_I^p
fIp 的 concat 是键(K)和值(V)。通过层归一化(LN)和两层多层感知机(MLP)对 LSA 的输出进行编码,以提取更多的上下文信息。使用辅助连接(残差)来增强信息传播。最后,应用重塑(RS)层,将 patch 重新调整并组装成与
f
M
f_M
fM 相同的大小。
2.2、Multi-sized Transformer U-Net(MT U-Net)
图3(a) 展示了本文的 MT U-Net 的架构,包括编码和解码部分。编码部分包括一个 Patch Partitioning 层、一个 Linear Embedding 层、一个 PoE 和四个 Encoder block。
Figure 3 | 所提出的 MT U-Net 和 MT 模块的架构

Patch Partitioning 层将输入分割成非重叠的 patch,大小为 2×2。这些 patch 以及时间嵌入被 Linear Embedding 层展平成 D × 1 D×1 D×1 维线性嵌入。然后,将从 PoE 获得的位置信息添加到线性嵌入中,随后通过四个编码器模块。每个编码器模块由一个多尺寸 Transformer (MT)模块和一个 Patch Merging 层组成,除了最后一个编码器模块只包含 MT 模块。MT 模块提取多尺度上下文特征, Patch Merging 层对特征图进行下采样。
受 U-Net 的启发,使用跳跃连接来利用编码器中的多尺度上下文信息,以克服下采样过程中空间信息的损失。与编码器模块类似,每个解码器块由一个 MT 模块和一个 patch-expanding 层组成,除了第一个解码器块只包含 MT 模块。patch-expanding 层对特征图进行上采样和重塑操作。最后,使用线性投影层来获得像素级预测。
所提出的多尺度 Transformer(MT)模块(图3(b))与传统的 Transformer 不同。MT 模块由两部分组成:多尺度窗口和移位窗口。多尺度窗口部分提取多尺度上下文信息,而移位窗口部分则丰富了提取的信息。多尺寸窗口部分有 K 个并行分支,每个分支由一个层归一化(LN)、多头自注意力(SA)、辅助连接(残差)和一个两层的多层感知机(MLP)以及 GELU 激活函数组成。在多头自注意力机制中,窗口大小被设置为可变,以提取多尺度上下文特征。各个分支的输出被合并后,进一步送入移位窗口部分。移位窗口部分的结构与多尺寸窗口中的单个分支类似,但在自注意力机制中采用了移位窗口(SW-SA)。
2.3、训练和推理
在训练过程中,源图像及其分割真实标签作为输入扩散模型。使用噪声预测损失(
L
N
o
i
s
e
L_{Noise}
LNoise)和交叉熵损失(
L
C
E
L_{CE}
LCE)对扩散模型进行训练。
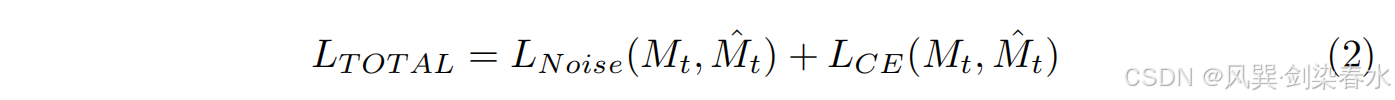
在推理过程中,将从高斯分布中采样的噪声图像与测试图像一起作为输入提供给反向过程。
3、实验与结果
3.1、数据集与评价指标
【1】数据集
(1)结肠镜图像中的息肉分割:Kvasir-SEG(KSEG),CVC-Clinic DB(CVC);
(2)皮肤镜图像中的皮肤病变分割:ISIC 2017(IS17’),ISIC 2018(IS18’)
(3)视网膜底片图像中进行光学杯状结构分割:REFUGE(REF);
【2】评价指标
(1)Dice系数(DC)和交并比(IoU);
3.2、实施细节
(1)通过交叉验证将 MT 模块中的分支数设置为3,窗口大小分别为 4、8 和 16;
(2) Diffusion Transformer U-Net 使用 SGD 优化器进行 40,000 次迭代训练,动量为 0.6,batch size 为 16,学习率设置为 0.0005;
(3)在扩散过程中,使用线性噪声调度器,T = 1000 步;
(4)为了与最近的基于扩散的分割模型进行公平比较,在推理过程中,将平均 25 次预测作为最终预测;
3.3、性能比较
Table 1 | 与 U-Net 和/或 Transformer 相关的最先进方法的比较:在 KSEG、CVC和 IS18 上 采用 80:10:10(训练集:验证集:测试集)实验方案,在 REF 和 IS17 上采用相应的默认划分;
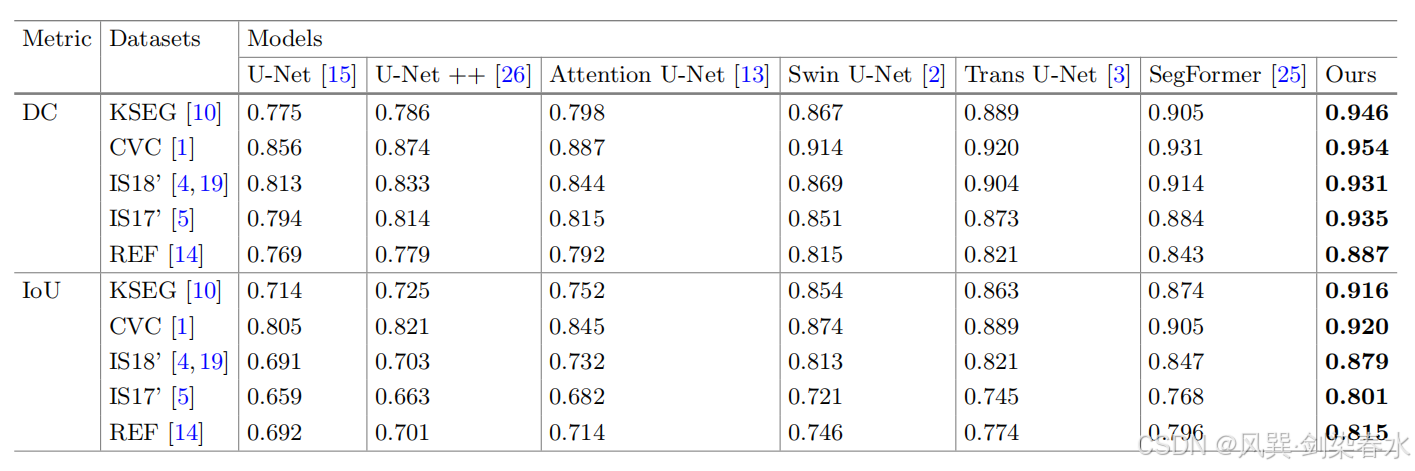
Figure 4 | 在 KSEG、CVC、IS18、IS17 和 REF 数据集上与 SOTA 方法进行定性比较:蓝色轮廓线代表真实标签,绿色轮廓线代表预测结果;
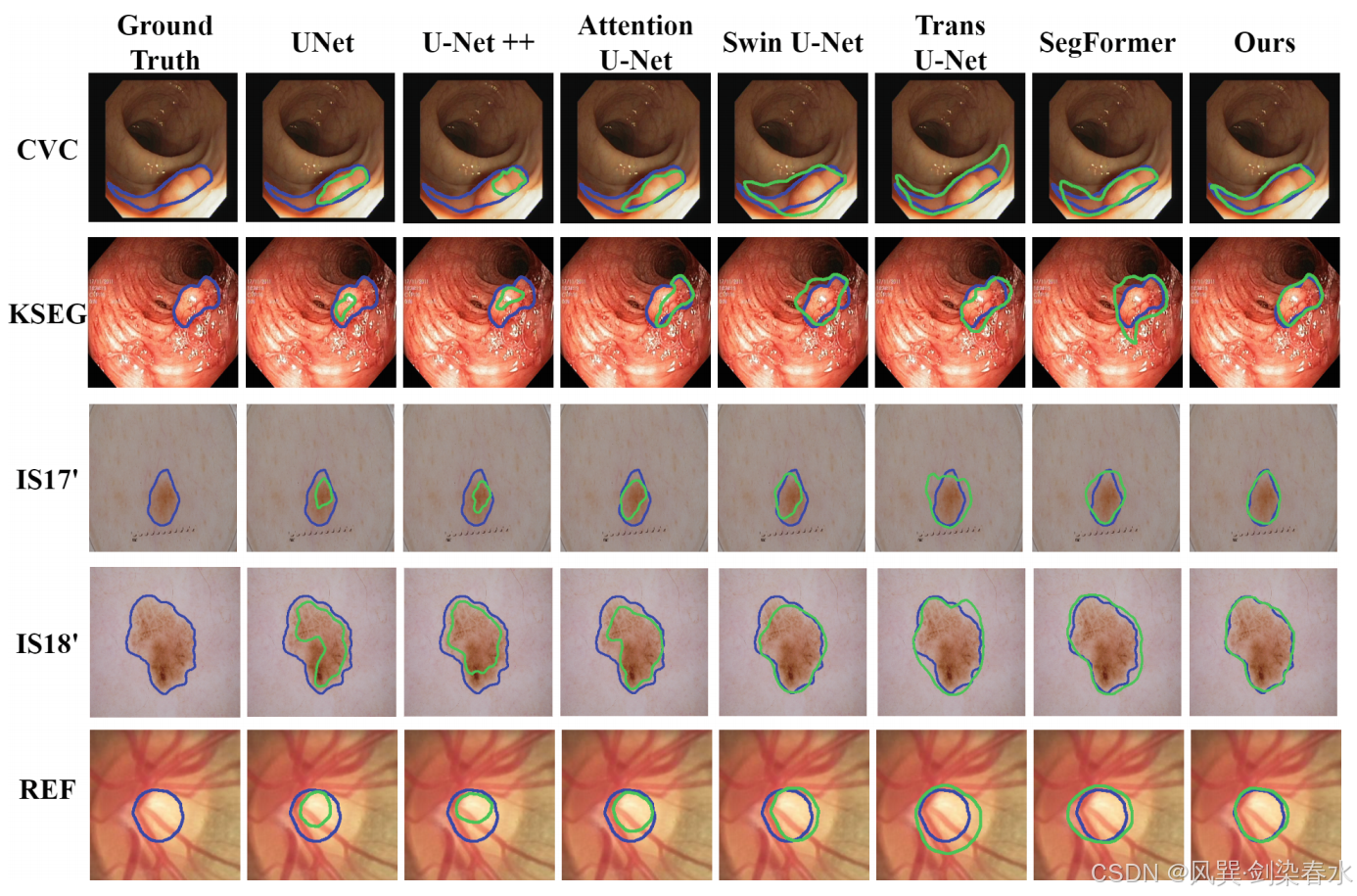
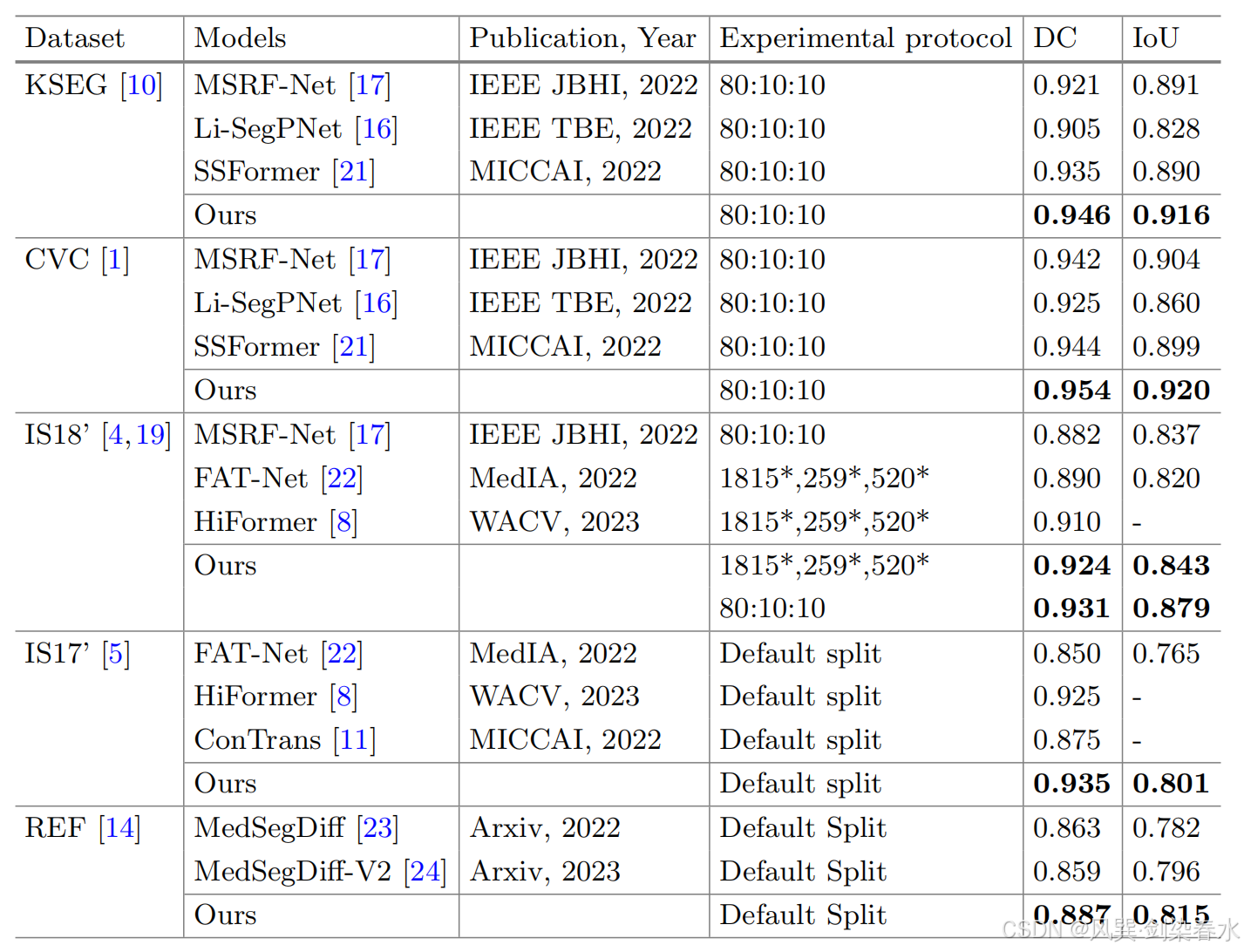
Table 2 | 与SOTA结果的比较:‘-’:未报告结果。‘*’:图像数量;
3.4、消融实验
Table 3 | KSEG、CVC、IS18、IS17 和 REF 上的消融实验: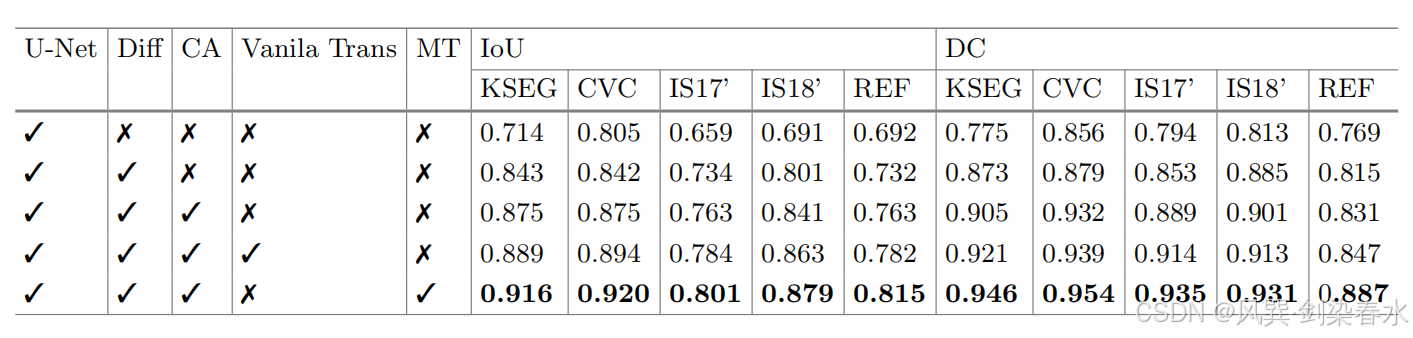
在扩散框架下改 backbone ٩(๑•̀ω•́๑)۶

















 89
89

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









