






本文提出了 Think-on-Graph 2.0(ToG-2),一种混合检索增强生成(RAG)框架,通过紧密耦合知识图谱(KG)和文本 RAG,以迭代方式从结构化和非结构化知识源检索信息,助力大语言模型(LLMs)在复杂知识推理任务中实现深度和忠实推理,经实验验证其在多个数据集上性能优异且适用于不同 LLMs。
问题
复杂推理任务中的知识检索深度与完整性问题:
- 当前检索增强生成(RAG)方法在处理复杂推理任务时,难以确保检索信息的深度和完整性,导致大语言模型(LLMs)在整合碎片化信息及理解其结构关系方面存在困难,无法保持类人的推理轨迹。
文本RAG的结构化关系捕捉问题:
- 基于文本的RAG方法主要依赖文档内文本内容的向量检索,虽能衡量文本间语义相似性,但难以捕捉文本与文档间的结构化关系,无法有效处理多步推理或跟踪不同信息片段间的逻辑联系。
知识图谱RAG的信息不完整问题:
- 基于知识图谱(KG)的RAG方法虽能有效组织实体间的结构关系,但知识图谱本身存在内在的不完整性,且缺乏本体之外的信息,无法提供详细的上下文内容。
混合RAG方法的检索结果提升问题:
- 现有的混合RAG方法虽尝试整合文本和知识图谱,但仅聚合两者检索的信息,未能通过一种知识源改善另一种的检索结果,在处理需要深度检索详细信息的复杂查询时仍存在不足。
挑战
- 深度知识检索挑战:在处理复杂知识推理任务时,如何从结构化和非结构化知识源中进行深度且可靠的信息检索,以满足复杂推理对知识的需求。
- 推理忠实性挑战:确保大语言模型基于检索到的知识进行推理时,生成的内容具有较高的忠实性,减少幻觉等问题。
- 效率与效果平衡挑战:设计一种既高效又有效的方法,能够在不增加过多计算成本和时间消耗的前提下,提升模型的推理能力,并适用于不同的大语言模型和知识源组合。
创新点
- 紧密耦合的 KG×Text RAG 范式:
提出了一种新的混合 RAG 框架 Think-on-Graph 2.0(ToG-2),紧密耦合基于知识图谱(KG)和基于文本的 RAG 方法(注意与ToG1.0对比,ToG1.0是KG×LLM,如果不了解ToG1.0,可以看THINK-ON-GRAPH: DEEP AND RESPONSIBLE REASON-ING OF LARGE LANGUAGE MODEL ON KNOWLEDGEGRAPH论文讲解_think-on-graph: deep and responsible reasoning of -CSDN博客),实现了深度和可靠的上下文检索以及精确的图谱检索,有效整合了两种知识源的优势。 - 知识引导的迭代检索过程:
通过迭代的方式,在图谱检索和上下文检索之间交替进行,利用知识图谱引导上下文检索,并以文档作为实体上下文实现精确的图谱检索,使模型能够逐步挖掘与问题相关的深度线索,增强推理能力 - 训练无关且即插即用的框架:
ToG-2 是训练无关的,可直接应用于各种大语言模型,具有良好的兼容性和通用性,方便在不同模型和应用场景中部署
贡献
- 提出 ToG-2 框架:
引入了 ToG-2 这一混合 RAG 框架,有效解决了复杂知识推理任务中深度知识检索和模型推理能力提升的问题 - 理论与方法贡献:
详细阐述了 ToG-2 的工作原理,包括初始化、混合知识探索(包含知识引导的图谱搜索和上下文检索)以及基于混合知识的推理等步骤,为基于知识的大语言模型推理提供了新的思路和方法。 - 实验验证优势:通过在多个知识密集型数据集上进行广泛实验,验证了 ToG-2 相较于现有方法的优势,如在 6 个数据集上取得了最先进的性能,能提升小模型推理能力至接近大模型直接推理水平等,为模型在实际应用中的有效性提供了有力证据。
提出的方法(ToG-2)
初始化(Initialization)
- 从给定问题中识别实体,并通过实体链接方法将其与知识图谱中的实体相连,然后进行主题修剪Topic Prune从问题中提取出的关键实体中选择最适合作为知识图谱(KG)探索起点的实体。
- 在第一轮图谱检索前,使用密集检索模型(DRMs)(利用深度学习技术来评估文档或文档片段与查询之间的相关)从与初始主题实体相关的文档中提取前 k 个块,由大语言模型评估信息是否足以回答问题。
混合知识探索(Hybrid Knowledge Exploration)
知识引导的图谱搜索(Knowledge-Guided Graph Search)
- 关系发现(Relation Discovery):在每次迭代开始时,通过函数找到所有主题实体的关系。
- 关系修剪(Relation Prune):根据大语言模型对关系的评分,选择可能找到有用上下文信息的关系,修剪低得分关系。
- 实体发现(Entity Discovery):基于选定的关系找到主题实体的连接实体,随后通过上下文实体修剪步骤选择新的主题实体,完成图谱检索步骤。
知识引导的上下文检索(Knowledge-Guided Context Retrieval)
- 实体引导的上下文检索(Entity-Guided Context Retrieval):收集与候选实体相关的文档,将候选实体的当前三元组转化为简短句子并附加到上下文中,使用 密集检索模型DRMs 计算段落相关性得分,选择得分最高的前 K 个块作为推理阶段的参考。
- 基于上下文的实体修剪(Context-Based Entity Prune):根据候选实体上下文块的排名得分计算其排名分数,选择排名靠前的候选实体作为下一次迭代的主题实体。
基于混合知识的推理(Reasoning with Hybrid Knowledge):
在每次迭代结束时,用所有已找到的知识(包括线索、三元组路径、前 K 个实体及对应上下文块)提示大语言模型,判断知识是否足以回答问题。若足够,则直接输出答案;否则,让大语言模型输出有用线索并重构优化查询,继续下一轮检索,直到达到最大深度。
例子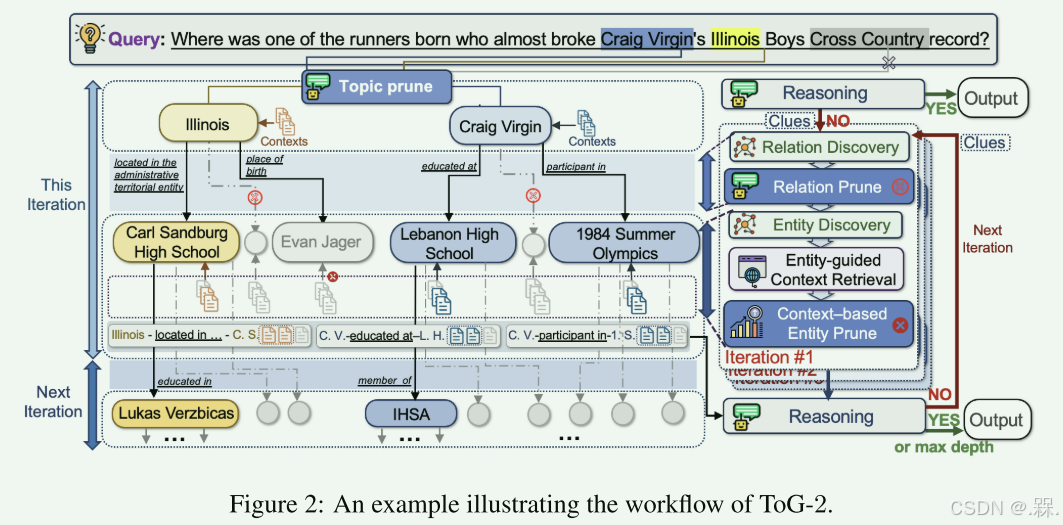
问题:差点打破克雷格-维尔京(Craig Virgin)保持的伊利诺伊州男子越野赛纪录的选手是在哪里出生的?
- ToG-2从问题中识别实体克雷格-维尔京、伊利诺伊州、越野赛,主题修剪后将越野赛删除,判断是否有足够的信息来回答问题。如果有,直接输出答案;如果没有则将这两个实体作为知识图谱(KG)探索起点的实体。
- 找上述实体的关系,使用关系修剪排除低得分后得到的关系为位于行政领土实体内、出生地、教育程度和参加。根据选定关系得到新的实体卡尔桑德堡高中、埃文-贾格尔、黎巴嫩高中 Lebanon High School和1984 夏季奥运会,为这四个实体检索上下文并评估,将低相关性实体埃文-贾格尔修剪,此为第一次迭代结果。
- 此时关系修建的结果卡尔桑德堡高中、黎巴嫩高中 Lebanon High School和1984 夏季奥运会,将这三个实体以及对应的三元组和上文文块提示大模型,由大模型判断是否足以回答该问题。若足够,则直接输出答案;否则,让大语言模型输出有用线索并重构优化查询,继续下一轮检索,直到达到最大深度。
指标
评估数据集及指标
- 在多个知识密集型推理基准数据集上进行评估,包括 WebQSP、QALD10-en、AdvHotPotQA、Zero-Shot RE、FEVER 和 Creak 等。其中,FEVER 和 Creak 数据集使用 Accuracy(Acc.)作为评估指标,其他数据集使用 Exact Match(EM)作为评估指标
额外数据集(ToG-FinQA)
- 为更好评估模型在特定领域推理场景下的能力,收集了数千份 2023 年中国财务报表构建了 ToG-FinQA 数据集,包含文档语料库、知识图谱和问答对三个主要部分,并定义了 7 种实体关系类型。该数据集用于评估模型从特定知识源检索信息的能力,因为大语言模型通常缺乏相关领域知识
模型结构
ToG-2 模型结构主要包含以下几个关键部分:
- 实体提取与主题修剪模块:负责从问题中提取实体,并通过主题修剪选择合适的主题实体,作为后续图谱检索和推理的起点。
- 混合知识探索模块
- 知识引导的图谱搜索子模块:由关系发现、关系修剪和实体发现三个组件构成,通过在知识图谱上探索实体间的关系,寻找与问题相关的潜在实体和概念,实现从图谱中挖掘深度知识的功能。
- 知识引导的上下文检索子模块:包含实体引导的上下文检索和基于上下文的实体修剪两个组件,用于从文档中检索与候选实体相关的上下文信息,并根据上下文相关性对候选实体进行筛选,为推理提供丰富的上下文依据。
- 推理模块:基于混合知识探索过程中获取的三元组路径、实体上下文等信息,大语言模型在该模块中进行推理,判断是否能够回答问题。若信息不足,则输出线索并重构查询,继续迭代检索
结论
- 现有基于知识图谱或文本的 RAG 系统在处理复杂知识推理任务时,难以保证深度知识检索。本文提出的 ToG-2 算法框架,通过紧密耦合 KG-based 和 text-based RAG,实现了可靠的图谱检索和知识引导的上下文检索,并通过迭代协同检索过程获取深度知识,从而实现了大语言模型的深度和忠实推理
- 实验结果表明,ToG-2 在不同规模的大语言模型上均显著提升了性能,超越了现有的多种推理方法和 RAG 方法,且无需额外训练成本。
实验解释
实验目的
- 评估 ToG-2 方法在不同知识密集型推理任务中的性能,与多种基线方法进行比较,验证 ToG-2 在处理复杂知识推理任务时的有效性和优势。
- 分析 ToG-2 在不同实验设置(如不同大语言模型作为骨干网络、不同实体修剪工具、不同宽度和深度设置等)下的性能变化,探究影响模型性能的关键因素,为模型优化提供依据。
实验设置
- 数据集:使用多个知识密集型推理基准数据集,包括 WebQSP、QALD10-en、AdvHotPotQA、Zero-Shot RE、FEVER 和 Creak 等,涵盖多跳 KBQA、多跳复杂文档 QA、槽填充和事实验证等多种任务类型。同时构建了领域特定的 ToG-FinQA 数据集,用于评估模型在特定领域推理场景下的能力。
- 基线方法:将 ToG-2 与多种基线方法进行对比,包括 LLM-only 方法(如 Direct Reasoning、Chain-of-Thought、Self-Consistency)、text-based RAG 方法(如 Vanilla RAG)、KG-based RAG 方法(如 Think-on-Graph,即 ToG)、混合 RAG 方法(如 Chain-of-Knowledge,即 CoK;GraphRAG)。所有基线方法均使用 GPT-3.5-turbo 进行评估,并在无监督设置下进行实验。(解释基线方法:一个简单、易于实现的基准模型,用于与更复杂的机器学习模型进行比较。基线模型通常是一个简化的方法,不涉及许多高级技术和优化手段,但它提供了一个起点,帮助研究人员评估其他模型的性能。当开发和优化机器学习模型时,如果一个模型的性能无法显著超过基线,那么这可能意味着模型存在问题,需要进一步改进。)
- 模型参数设置:主要以 GPT-3.5-turbo 作为骨干大语言模型,在实验中设置温度参数为 0。对于其他参数,如关系修剪中的阈值设为 0.2,上下文检索中保留 10(K = 10)个得分最高的句子用于计算实体分数,在推理阶段对大多数数据集采用 2-shot 演示,对 FEVER 数据集采用 3-shot 和 6-shot 演示,并让大语言模型先执行自一致性推理步骤。在混合知识探索过程中,设置宽度 W = 3,最大迭代次数(深度)为 3
实验结果分析
- 主要结果:在多个数据集上,ToG-2 相较于其他基线方法表现出色,在 WebQSP、AdvHotPotQA、QALD10-en 和 Zero-Shot RE 等数据集上取得了更好的性能。在 Fever 数据集上,ToG-2 与 CoK 性能相当,因为 Fever 数据集中的事实陈述主要为单跳关系,不需要深度信息检索;在 Creak 数据集上,ToG-2 与 ToG 性能相似,因为该数据集问题相对简单,可直接通过三元组推理得出结果
- 消融实验
- LLM 骨干网络的影响:通过在 AdvHotPotQA 和 FEVER 数据集上的实验,分析不同能力的大语言模型在 ToG-2 框架下的性能提升情况。结果表明,ToG-2 能提升较弱模型(如 Llama-3-8B、Qwen2-7B)的推理能力至接近强大模型(如 GPT-3.5-turbo)的水平,同时强大模型(如 GPT-3.5-turbo 和 GPT-4o)也能受益于 ToG-2 进一步提升性能。在相关知识未在预训练中暴露且需要知识检索的场景(如 ToG-FinQA 数据集)中,强大模型(如 GPT-4o)能从 ToG-2 中获得更显著的提升
- 实体修剪工具的选择:在上下文实体修剪步骤中,比较了 BGE-Embedding、BGE-reranker、Minilm、BM25 和基于大语言模型的生成式排名等不同方法在 AdvHotPotQA 数据集中的性能。结果显示,BGE-Reranker 性能最佳,其次是 Minilm,经典的 BM25 方法也能取得接近先进模型的效果。综合考虑运行时间和准确性,基于 DRM 的实体修剪方法(如 BGE-Reranker)在成本效益和泛化能力方面表现更优,因此选择该方法用于 ToG-2
- 宽度和深度设置的影响:通过在 AdvHotPotQA 数据集上分析不同最大宽度 W 和深度 D 设置对模型性能的影响,发现随着宽度从 2 增加,模型性能逐渐提升,但超过 3 后边际收益递减;深度超过 3 后模型性能趋于平稳。这表明较大的搜索范围并不总是更好,应根据任务难度进行调整
- 运行时分析:对比 ToG 和 ToG-2 在不同数据集上的运行时,ToG-2 在关系修剪时间上显著优于 ToG,仅为 ToG 的 45%,这得益于其关系修剪组合策略减少了大语言模型的调用次数。在实体修剪阶段,尽管 ToG-2 整合了更多实体上下文知识,但由于使用 DRMs 进行实体修剪,其平均运行时仍能减少至 ToG 的 68.7%。与其他基线方法(如 NaiveRAG、CoK)相比,ToG-2 在保持强大推理能力的同时,实现了较好的成本效益平衡,减少了总 API 调用次数和运行时间
- 手动分析:对 ToG-2 在 AdvHotPotQA 数据集中的 50 个推理结果进行手动分析,发现文本上下文(Doc-enhanced Answer)是复杂 QA 任务中最重要的信息来源,占比约 42%;三元组链接(Triple-enhanced Answer)单独使用时因缺乏详细上下文难以提供深入见解,占比较小,但在引导推理方面有一定作用;两者结合(Both-enhanced Answer)的模式效果显著,占比 32.26%。同时,ToG-2 在处理复杂问题时能减少大语言模型的幻觉问题,但在信息检索方面仍面临挑战,如知识源不完整和检索模型的局限性等。此外,EM 评估指标在处理复杂生成任务时存在不足,ToG-2 在使用该指标时存在较多假阴性情况,表明模型仍有提升空间(解释假阴性:模型未能正确识别出正类的情况,通常用于分类任务中)
用到的外部工具
- 实体链接工具:使用 Azure AI 提供的针对 Wikipedia 的实体链接 API(What is entity linking in Azure AI Language? - Azure AI services | Microsoft Learn),用于将问题中的实体与知识图谱中的实体进行链接
- 密集检索模型(DRMs):在上下文检索过程中,利用 BGE-embedding 模型(未进行微调)计算段落的相关性得分,用于实体引导的上下文检索和基于上下文的实体修剪等步骤
剩余挑战和未来工作
- 信息检索瓶颈问题:尽管 ToG-2 在各数据集上表现出色,但在信息检索方面仍面临瓶颈,主要源于知识源的不完整性(如 Wikidata 存在不准确、矛盾或缺失信息,许多 Wiki 实体在 Wikipedia 页面缺少关键细节)以及检索模型的局限性(不同类型问题需不同信息,通用检索模型难以应对)。未来可通过插件整合更全面的知识图谱和更先进的检索模型来优化 ToG-2。
- 模型对复杂问题的理解问题:大语言模型在处理复杂或不明确问题时可能误解意图,如在特定问题中回答了相关但不完全符合问题要求的答案。未来可探索如何提高模型对复杂问题的理解能力,以提升回答的准确性。
- 评估指标的局限性问题:EM 指标在评估生成式任务时存在不足,难以正确匹配别名和处理不同细节程度的答案。尽管本文因效率、成本和潜在偏差等因素选择 EM 进行粗略评估,但评估指标的改进仍是未来研究方向之一,可考虑更合理的评估方法或结合多种评估方式来更全面地评估模型性能。
数据集
- 评估数据集
- WebQSP:一个多跳知识库问答(KBQA)数据集,用于评估模型在复杂知识库问题上的推理能力
- QALD10-en:另一个多跳 KBQA 数据集,为链接数据上的问答挑战提供了多样化的测试场景,可检验模型在处理结构化知识方面的性能
- AdvHotPotQA:是 HotPotQA 数据集的一个具有挑战性的子集,属于多跳复杂文档问答数据集,能有效测试模型在复杂文档推理和多跳推理任务中的表现
- Zero-Shot RE:一个槽填充数据集,用于评估模型在零样本情况下处理关系抽取任务的能力
- FEVER:一个事实验证数据集,要求模型判断给定陈述是否与事实相符,通过 Accuracy 指标评估模型在事实判断方面的准确性
- Creak:另一个事实验证数据集,同样用于评估模型对事实陈述的验证能力
- 额外构建的数据集(ToG-FinQA)
- 构建目的:为评估模型在特定领域(金融领域)推理场景下的能力,该领域要求从特定知识源检索信息,而大语言模型通常缺乏相关知识,因此构建此数据集
- 数据集组成
- 文档语料库:包含数千份 2023 年中国财务报表,作为实体上下文的来源
- 知识图谱:从文档中提取公司和其他组织作为实体,并定义了 7 种关系类型(如子公司、主营业务、供应商、兄弟公司、大宗交易、附属关系和客户),用于构建实体间的结构化关系
- 问答对:基于文档语料库和知识图谱,手动设计了 97 个多跳问题,涵盖市场分析、竞争对手分析、大宗交易、客户分析和供应商分析等主题


















 803
803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









