







 本文详细介绍了WAV文件的结构,包括采样率、采样值和声道信息,并提供了如何从WAV文件中精确计算播放长度的方法。通过解析文件头和子区块,特别是'fmt'和'data'区块,可以抽取并解析PCM波形数据。WAV文件基于RIFF格式,其内部由多个Chunk组成,包括RIFFWAVE、Format、Fact(可选)和Data Chunk。
本文详细介绍了WAV文件的结构,包括采样率、采样值和声道信息,并提供了如何从WAV文件中精确计算播放长度的方法。通过解析文件头和子区块,特别是'fmt'和'data'区块,可以抽取并解析PCM波形数据。WAV文件基于RIFF格式,其内部由多个Chunk组成,包括RIFFWAVE、Format、Fact(可选)和Data Chunk。
音频简介
WAV即WAVE,是经典的Windows音频数 据封装格式,由Microsoft开发。
44100HZ 16bit stereo 22050HZ 8bit mono
采样率:声音信号在“模数转换”过程中单 位时间内采样的次数。 :
采样值:每一次采样周期内声音模拟信号的 积分值。
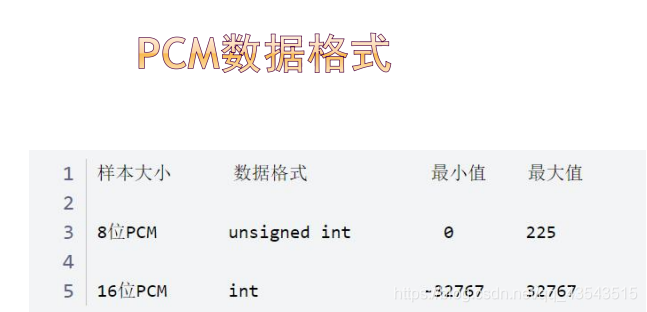
单声道:11.025 KHz 采样值,8 Bit 采样值 (0x00 - 0xFF)。
双声道 :44.1 KHz 采样值,16 Bits 采样值。 高八位表示左声道,低八位表示右声道。
我们就可以根据一个 wav 文件 的大小、采样频率和采样大小 估算出一个 wav 文件的播放长 度。
譬如 “Windows XP 启动.wav” 的文件长度是 424,644 字节, 它是 “22050HZ / 16bit / 立 体声” 格式(这可以从其 “属 性->摘要” 里看到)
但是这还不够精确, 包装标准的 PCM 格式的 WAVE 文件(*.wav)中至少带有 42 个字节的头信息, 在计算播放时间 时应该将其去掉: 所以就有:(424644-42) / (22050162/8) ≈ 4.8140816(秒). 这样 就比较精确了
WAVE文件是以RIFF(Resource Interchange File Format, “资源 交互文件格式”)格式来组织内部 结构的
RIFF文件结构可以看作是树状结构, 其基本构成是称为"块"(Chunk)的单 元,最顶端是一个“RIFF”块, 下面的每个块有“类型块标识(可选)”、 “标志符”、“数据大小”及“数据” 等项所组成
WAVE文件是由若干个Chunk组成的。 按照在文件中的出现位置包括: RIFF WAVE Chunk, Format Chunk, Fact Chunk(可选), Data Chunk。每个chunk 由“标志符”、“数据大小”及“数据” 所组成
每个Chunk有各自的ID, 位于Chunk最开始位置作为标示,而 且均为4个字节。 并且紧跟在ID后面的是Chunk大小(去 除ID和Size所占的字节数后剩下的其他 字节目),4个字节表示

文件头 RIFF/WAV 文件标识段 声音数据格式说明段
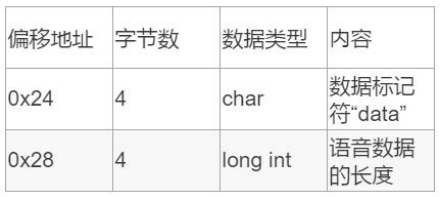
数据体:由 PCM(脉冲编码调制)格式表示的 样本组成。 单声道 WAV 文件中,声道0代表左声道,声道1 代表右声道;多声道 WAV 文件中,左右声道的 样本是交替出现的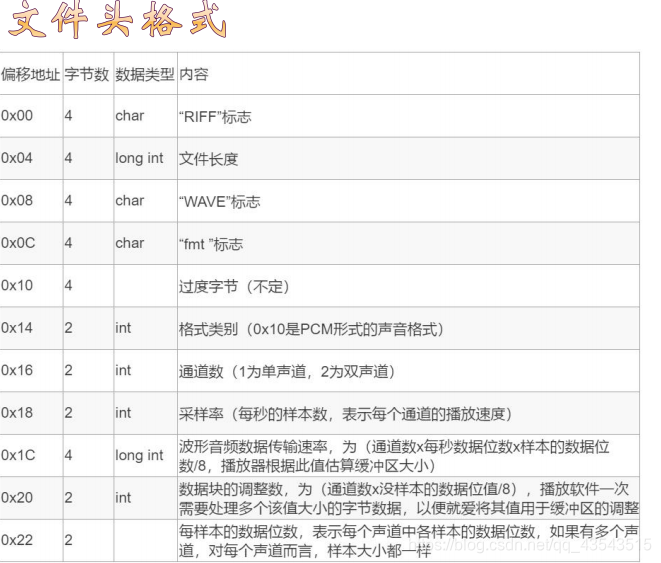

As an example, here are the opening 72 bytes of a WAVE file with bytes shown as hexadecimal numbers: 52 49 46 46 24 08 00 00 57 41 56 45 66 6d 74 20 10 00 00 00 01 00 02 00 22 56 00 00 88 58 01 00 04 00 10 00 64 61 74 61 00 08 00 00 00 00 00 00 24 17 1e f3 3c 13 3c 14 16 f9 18 f9 34 e7 23 a6 3c f2 24 f2 11 ce 1a 0d …
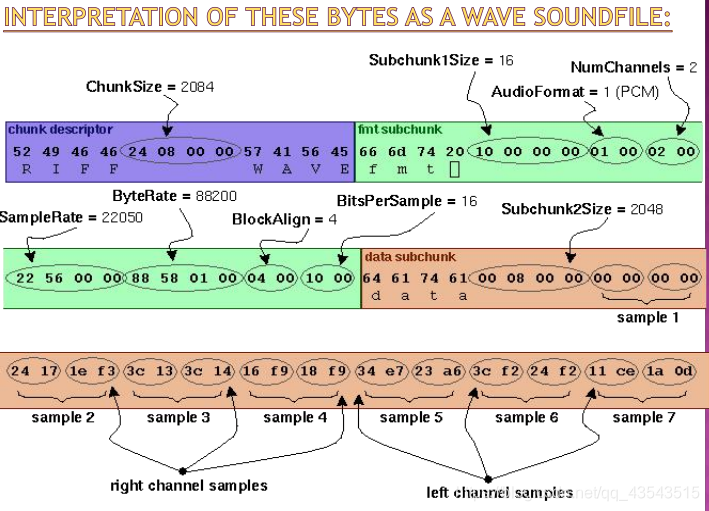

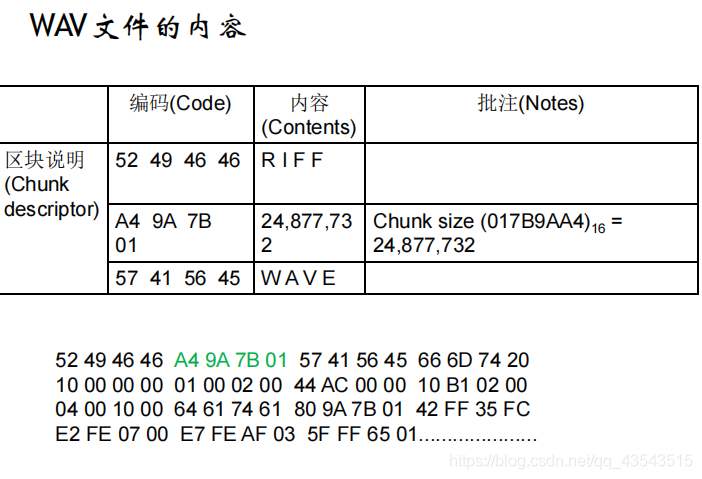
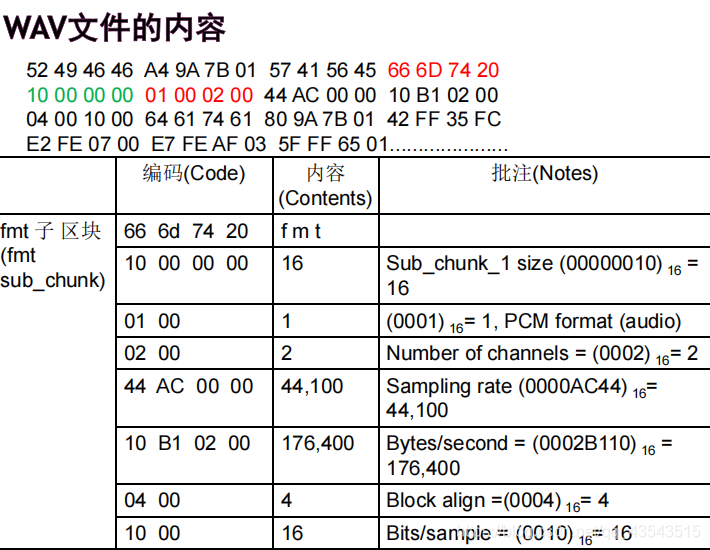
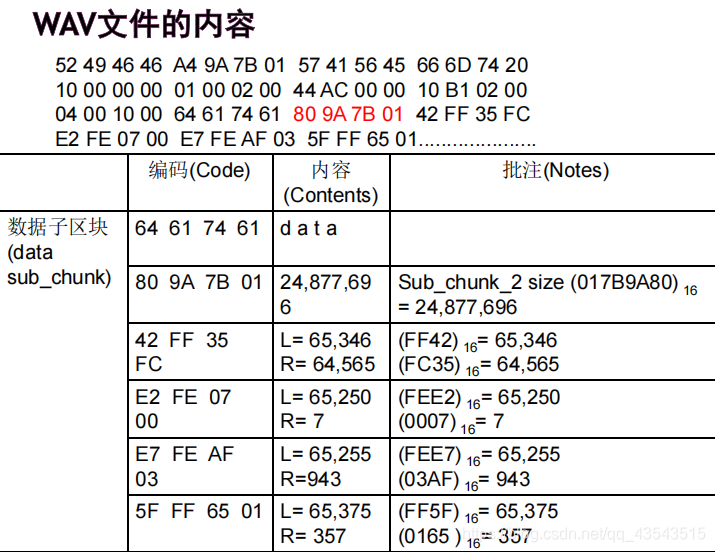
以上面的WAV文件为例,要抽取出声音的PCM波形 时,先要找到标示为「fmt」的子区块(sub_ chunk), 知道所存的波形是PCM格式,它有两个声道,取样 频率为44,100 Hz,每个取样为16位。 接下去找到标示为「data」的子区块,知道后面 接着的是24,877,696个byte的左右两声道波形数 据。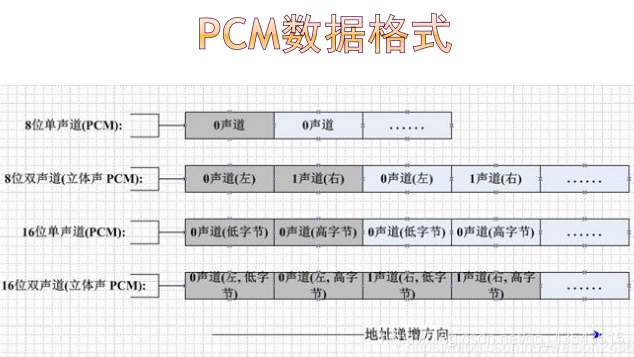


















 4480
4480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











