







FoldingNet: Point Cloud Auto-encoder via Deep Grid Deformation 论文和代码详解
Paper
该文章发表于2018年的CVPR,文章链接:
FoldingNet: Point Cloud Auto-encoder via Deep Grid Deformation
附加材料链接:
FoldingNet附件材料
Abstract
在本文中,提出了一种新的 end-to-end 的深度自编码器(auto-encoder) 来解决点云上的无监督学习问题。在Encoder 阶段,本文在 PointNet 的基础上提出了一种 graph-based 的结构;在 Decoder 阶段,提出了一种folding-based 的解码器将一个标准2D grid 变形到3D surface,使得解码器重建出的点云和输入点云之间有低重建误差。
本人理解:利用 graph-based 的结构在编码阶段提取点云特征,然后利用 folding-based 的结构在解码阶段重建点云,将重建后的点云和输入点云之间的重建误差作为 loss function。这样,就能学习编码和解码阶段的参数。
1. Introduction
本文提出了一个称为 FoldingNet 的 auto-encoder(AE)。
解码阶段的原理:Intuitively, any 3D object surface could be transformed to a 2D plane through certain operations like cutting, squeezing, and stretching. The inverse procedure is to glue those 2D point samples back onto an object surface via certain folding operations, which are initialized as 2D grid samples. 我感觉,可以理解为网格参数化及其逆映射。图示如下:
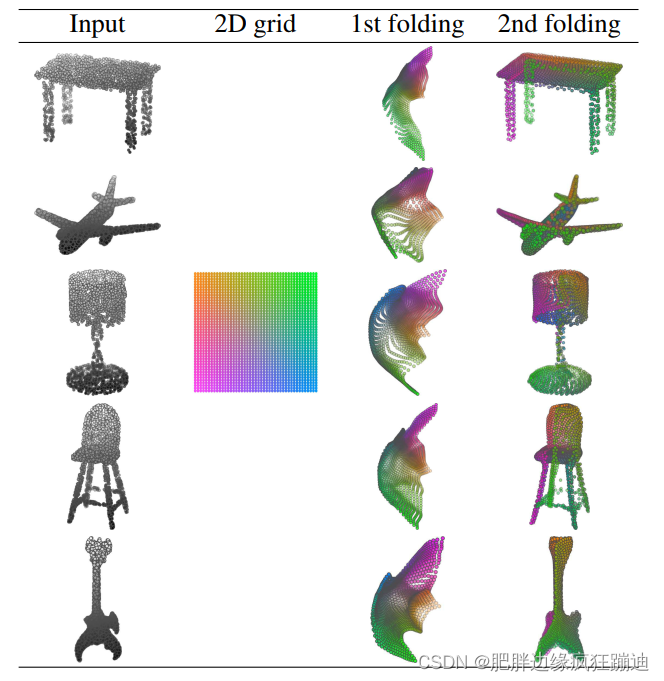
第一列:输入点云。第二列:解码阶段要进行folding的2D grid。第三列:一次folding操作后的输出。第四列:两次folding操作后的输出,即重建的点云。
Contribution:1,训练了一个端对端的深度自编码器,该编码器直接以无序点云作为输入。2,提出了一种新的称为 folding 的解码操作,该操作在点云重建中是通用的并且重构点的顺序是其副产品。3,实验证明,本文的方法与其它无监督方法相比可以得到更高的分类准确性。
2. FoldingNet Auto-encoder on Point Clouds
FoldingNet结构如下:
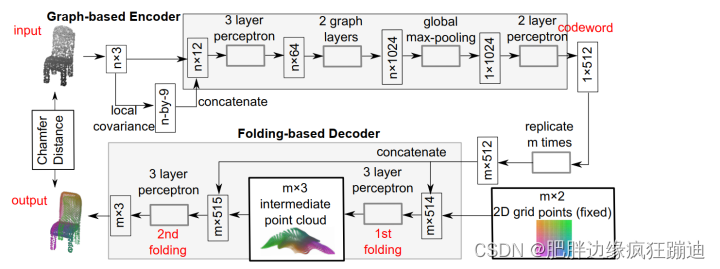
Notation:
Encoder的输入是一个
n
×
3
n\times3
n×3 的矩阵,该矩阵的每一行代表3D点的位置
(
x
,
y
,
z
)
(x,y,z)
(x,y,z) 。输出是一个
m
×
3
m\times3
m×3 的矩阵,该矩阵表示重建后的点云(由
m
m
m 个点组成)。重建后点云的数目
m
m
m 不一定要和输入点云的数目
n
n
n 一致。记输入点云为
S
S
S ,重建后的点云为
S
^
\hat{S}
S^ ,则重建误差定义为 (extended)Chamfer distance:
d
C
H
(
S
,
S
^
)
=
max
{
1
∣
S
∣
∑
x
∈
S
min
x
^
∈
S
^
∣
∣
x
−
x
^
∣
∣
2
,
1
∣
S
^
∣
∑
x
^
∈
S
^
min
x
∈
S
∣
∣
x
^
−
x
∣
∣
2
}
d_{CH}(S,\hat{S})=\max\{\frac{1}{|S|}\sum_{x\in S}\min_{\hat{x}\in\hat{S}}||x-\hat{x}||_2,\frac{1}{|\hat{S}|}\sum_{\hat{x}\in \hat{S}}\min_{x\in S}||\hat{x}-x||_2\}
dCH(S,S^)=max{∣S∣1x∈S∑x^∈S^min∣∣x−x^∣∣2,∣S^∣1x^∈S^∑x∈Smin∣∣x^−x∣∣2}
2.1 Graph-based Encoder Architecture
Encoder是多层感知机(MLP)和基于图的最大池化层(graph-based max pooling layers)的串联。graph是通过输入点云位置的 K-NNG(K-nearest neighbor graph)构造的,文章中说他们选取 K = 16 K=16 K=16 。
Local Covariance:对于输入点云中的每一个点 v v v ,计算它的局部协方差矩阵,并把该 3 × 3 3\times3 3×3 的矩阵向量化为 1 × 9 1\times9 1×9 。 v v v 的局部协方差的计算是根据 v v v 的K-NNG邻域计算的。
Encoder的结构:首先对于输入点云中的每个点计算其局部协方差;然后将大小为 n × 3 n\times3 n×3 的输入点云的位置和大小为 n × 9 n\times9 n×9 的局部协方差串联成大小为 n × 12 n\times12 n×12 的矩阵输入到一个3层MLP(该3层MLP是是shared MLP)中,输出是大小为 n × 64 n\times64 n×64 的矩阵;然后将 n × 64 n\times64 n×64 的矩阵喂给两个连续的graph layers,每一层都会对每个输入点的邻域根据K-NNG进行局部最大池化,然后再经过一个1D卷积进行特征升维;然后再经过全局最大池化,得到大小为 1 × 1024 1\times1024 1×1024 的矩阵;最后经过两层MLP对1024为特征进行降维,得到大小为 1 × 512 1\times512 1×512 的codeword(又称code,其实就是编码后提取的特征)。总结,计算其局部协方差 → \to → 三层感知机 → \to → 两个连续的graph layers → \to → 全局最大池化 → \to → 两层感知机。
2.2 Folding-based Decoder Architecture
Decoder用了两个连续的3层MLP将一个固定的2D grid变形为输入点云的形状,即进行重建点云。
Decoder的结构:首先将Encoder得到的codeword重复 m m m 次得到大小为 m × 512 m\times512 m×512 的矩阵,并将该矩阵与 m × 2 m\times2 m×2 的矩阵(表示点云个数为 m m m 的2D grid,可以理解为初始的重建点云)进行串联,得到大小为 m × 514 m\times514 m×514 的矩阵;然后将上面 m × 514 m\times514 m×514 的矩阵喂给一个3层MLP,输出一个大小为 m × 3 m\times3 m×3 的矩阵(表示第一次folding后重建的点云);然后将上面 m × 3 m\times3 m×3 的矩阵和 m × 512 m\times512 m×512 的矩阵(重复的codeword)串联为大小为 m × 515 m\times515 m×515 的矩阵,并将其喂给一个3层MLP,输出就是重建的点云。总结,就是将Encoder得到的特征和需要变形的点云串联得到新的特征,输入给3层感知机;如此重复两次,得到重建的点云。
3. Theoretical Analysis
通过构造性的证明,说明了本文提出的解码器对于任意输入点云是通用的。
4. Experimental Results
文章里给出了具体的数据集以及训练时的参数。
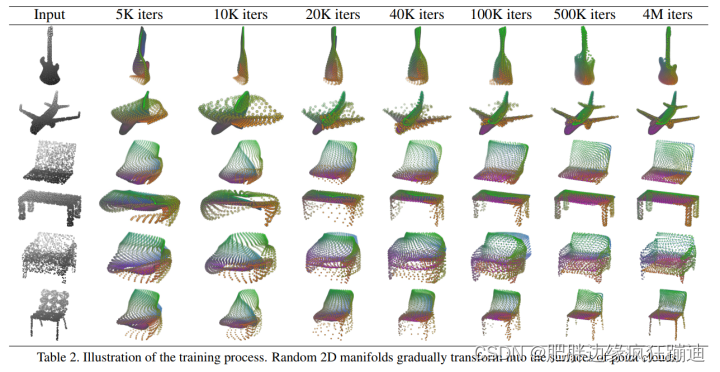
4.1 Visualization of the Training Process
为了展示解码器如何将2D grid变为3D点云。给出了随着训练迭代次数进行的结果展示。
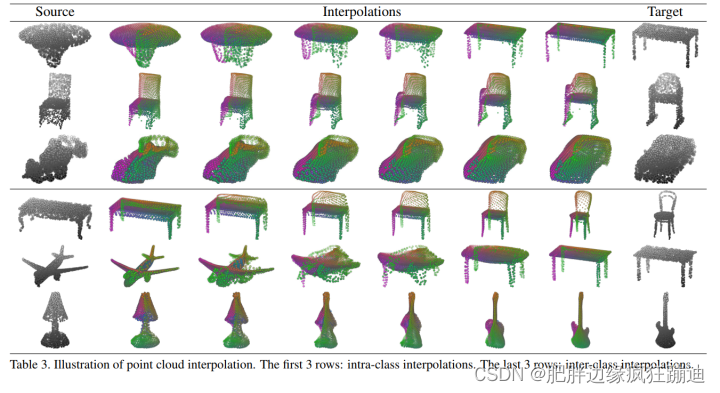
4.2 Point Cloud Interpolation
证明codeword提取了输入的自然表示的一种常见方法是,查看自编码器是否能够在数据集的两个输入之间实现有意义的新插值。
4.3 Illustration of Point Cloud Clustering
利用FoldingNet得到的codeword进行聚类。

4.4 Transfer Classification Accuracy
展示本文FoldingNet在三维点云表示学习和特征提取方面的效率。通过在ModelNet数据集上用codeword训练SVM,在ShapeNet数据集上训练得到codeword的自编码器(即在一个训练集上训练本文的自编码器,在另一个训练集上训练SVM)来实验证明FoldingNet的传输鲁棒性。

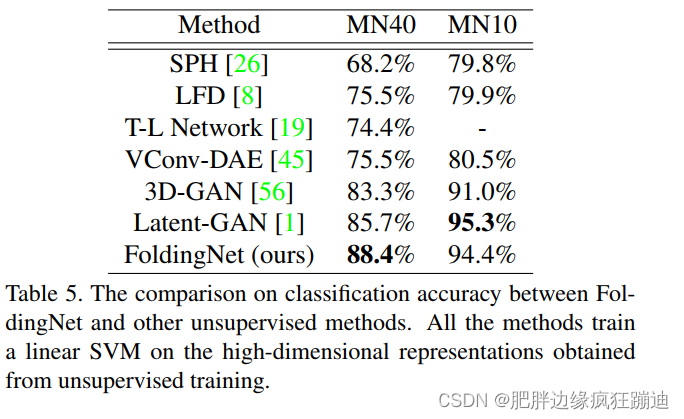
4.5 Semi-supervised Learning:What Happens when Labeled Data are Rare
通过改变训练集中有label的数据的比例,来观察利用FoldingNet得到的codeword进行SVM的实验结果。
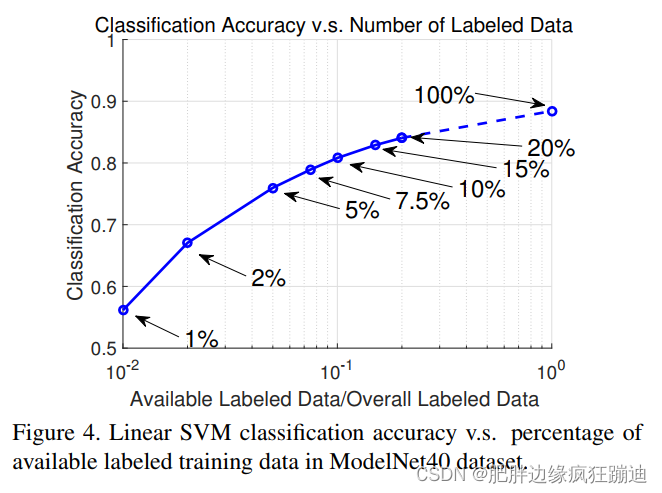
4.6 Effectiveness of the Folding-Based Decoder
通过和一个全连接网络的解码器进行比较,说明FoldingNet中的folding-based decoder的effectiveness。
比较方法:Representation learning and adversarial generation of 3d point clouds。编码阶段,先对点云进行字典排序,并在点序列上运用一维CNN;解码阶段,用了三层的全连接网络。
Code
代码链接:
FoldingNet代码
1. 功能函数组件
# 根据点的id找到对应的特征
def index_points(point_clouds, index):
"""
Given a batch of tensor and index, select sub-tensor.
Input:
points: input points data, [B, N, C]
idx: sample index data, [B, N, k]
Return:
new_points:, indexed points data, [B, N, k, C]
"""
device = point_clouds.device
batch_size = point_clouds.shape[0]
view_shape = list(index.shape)
view_shape[1:] = [1] * (len(view_shape) - 1)
repeat_shape = list(index.shape)
repeat_shape[0] = 1
batch_indices = torch.arange(batch_size, dtype=torch.long, device=device).view(view_shape).repeat(repeat_shape)
new_points = point_clouds[batch_indices, index, :]
return new_points
# k最近点邻域
def knn(x, k):
"""
K nearest neighborhood.
Parameters
----------
x: a tensor with size of (B, C, N)
k: the number of nearest neighborhoods
Returns
-------
idx: indices of the k nearest neighborhoods with size of (B, N, k)
"""
inner = -2 * torch.matmul(x.transpose(2, 1), x) # (B, N, N)
xx = torch.sum(x ** 2, dim=1, keepdim=True) # (B, 1, N)
pairwise_distance = -xx - inner - xx.transpose(2, 1) # (B, 1, N), (B, N, N), (B, N, 1) -> (B, N, N)
idx = pairwise_distance.topk(k=k, dim=-1)[1] # (B, N, k)
return idx
2. 网络结构
# graph layer的结构
class GraphLayer(nn.Module):
"""
Graph layer.
in_channel: it depends on the input of this network.
out_channel: given by ourselves.
"""
def __init__(self, in_channel, out_channel, k=16):
super(GraphLayer, self).__init__()
self.k = k
self.conv = nn.Conv1d(in_channel, out_channel, 1)
self.bn = nn.BatchNorm1d(out_channel)
def forward(self, x):
"""
Parameters
----------
x: tensor with size of (B, C, N)
"""
# KNN
knn_idx = knn(x, k=self.k) # (B, N, k)
knn_x = index_points(x.permute(0, 2, 1), knn_idx) # (B, N, k, C)
# Local Max Pooling
x = torch.max(knn_x, dim=2)[0].permute(0, 2, 1) # (B, N, C)
# Feature Map
x = F.relu(self.bn(self.conv(x)))
return x
# 编码器的结构
class Encoder(nn.Module):
"""
Graph based encoder.
"""
def __init__(self):
super(Encoder, self).__init__()
self.conv1 = nn.Conv1d(12, 64, 1)
self.conv2 = nn.Conv1d(64, 64, 1)
self.conv3 = nn.Conv1d(64, 64, 1)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(64)
self.bn3 = nn.BatchNorm1d(64)
self.graph_layer1 = GraphLayer(in_channel=64, out_channel=128, k=16)
self.graph_layer2 = GraphLayer(in_channel=128, out_channel=1024, k=16)
self.conv4 = nn.Conv1d(1024, 512, 1)
self.bn4 = nn.BatchNorm1d(512)
def forward(self, x):
b, c, n = x.size()
# get the covariances, reshape and concatenate with x
knn_idx = knn(x, k=16)
knn_x = index_points(x.permute(0, 2, 1), knn_idx) # (B, N, 16, 3)
mean = torch.mean(knn_x, dim=2, keepdim=True)
knn_x = knn_x - mean
covariances = torch.matmul(knn_x.transpose(2, 3), knn_x).view(b, n, -1).permute(0, 2, 1)
x = torch.cat([x, covariances], dim=1) # (B, 12, N)
# three layer MLP
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
# two consecutive graph layers
x = self.graph_layer1(x)
x = self.graph_layer2(x)
x = self.bn4(self.conv4(x))
x = torch.max(x, dim=-1)[0]
return x
# 对应于Decoder中的三层感知机,但是并没有像上面一样显示构造,而是用了一个数组,本质上是一样的
class FoldingLayer(nn.Module):
"""
The folding operation of FoldingNet
"""
def __init__(self, in_channel: int, out_channels: list):
super(FoldingLayer, self).__init__()
layers = []
for oc in out_channels[:-1]:
conv = nn.Conv1d(in_channel, oc, 1)
bn = nn.BatchNorm1d(oc)
active = nn.ReLU(inplace=True)
layers.extend([conv, bn, active])
in_channel = oc
out_layer = nn.Conv1d(in_channel, out_channels[-1], 1)
layers.append(out_layer)
self.layers = nn.Sequential(*layers)
def forward(self, grids, codewords):
"""
Parameters
----------
grids: reshaped 2D grids or intermediam reconstructed point clouds
"""
# concatenate
x = torch.cat([grids, codewords], dim=1)
# shared mlp
x = self.layers(x)
return x
# 解码器结构
class Decoder(nn.Module):
"""
Decoder Module of FoldingNet
"""
def __init__(self, in_channel=512):
super(Decoder, self).__init__()
# Sample the grids in 2D space
xx = np.linspace(-0.3, 0.3, 45, dtype=np.float32)
yy = np.linspace(-0.3, 0.3, 45, dtype=np.float32)
self.grid = np.meshgrid(xx, yy) # (2, 45, 45)
# reshape
self.grid = torch.Tensor(self.grid).view(2, -1) # (2, 45, 45) -> (2, 45 * 45)
self.m = self.grid.shape[1]
self.fold1 = FoldingLayer(in_channel + 2, [512, 512, 3])
self.fold2 = FoldingLayer(in_channel + 3, [512, 512, 3])
def forward(self, x):
"""
x: (B, C)
"""
batch_size = x.shape[0]
# repeat grid for batch operation
grid = self.grid.to(x.device) # (2, 45 * 45)
grid = grid.unsqueeze(0).repeat(batch_size, 1, 1) # (B, 2, 45 * 45)
# repeat codewords
x = x.unsqueeze(2).repeat(1, 1, self.m) # (B, 512, 45 * 45)
# two folding operations
recon1 = self.fold1(grid, x)
recon2 = self.fold2(recon1, x)
return recon2
# 整体自解码器结构
class AutoEncoder(nn.Module):
def __init__(self):
super().__init__()
self.encoder = Encoder()
self.decoder = Decoder()
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
3. 训练Auto-encoder
# 参数设置
parser = argparse.ArgumentParser()
parser.add_argument('--root', type=str, default='/home/rico/Workspace/Dataset/shapenet_part/shapenetcore_partanno_segmentation_benchmark_v0')
parser.add_argument('--npoints', type=int, default=2048)
parser.add_argument('--mpoints', type=int, default=2025)
parser.add_argument('--batch_size', type=int, default=16)
parser.add_argument('--lr', type=float, default=1e-4)
parser.add_argument('--weight_decay', type=float, default=1e-6)
parser.add_argument('--epochs', type=int, default=400)
parser.add_argument('--num_workers', type=int, default=4)
parser.add_argument('--log_dir', type=str, default='./log')
args = parser.parse_args()
# prepare training and testing dataset
train_dataset = ShapeNetPartDataset(root=args.root, npoints=args.npoints, split='train', classification=False, data_augmentation=True)
test_dataset = ShapeNetPartDataset(root=args.root, npoints=args.npoints, split='test', classification=False, data_augmentation=True)
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=args.num_workers)
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False, num_workers=args.num_workers)
# device
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# model
autoendocer = AutoEncoder()
autoendocer.to(device)
# loss function
cd_loss = ChamferDistance()
# optimizer
optimizer = optim.Adam(autoendocer.parameters(), lr=args.lr, betas=[0.9, 0.999], weight_decay=args.weight_decay)
batches = int(len(train_dataset) / args.batch_size + 0.5)
min_cd_loss = 1e3
best_epoch = -1
print('\033[31mBegin Training...\033[0m')
for epoch in range(1, args.epochs + 1):
# training
start = time.time()
autoendocer.train()
for i, data in enumerate(train_dataloader):
point_clouds, _ = data
point_clouds = point_clouds.permute(0, 2, 1)
point_clouds = point_clouds.to(device)
recons = autoendocer(point_clouds)
ls = cd_loss(point_clouds.permute(0, 2, 1), recons.permute(0, 2, 1))
optimizer.zero_grad()
ls.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print('Epoch {}/{} with iteration {}/{}: CD loss is {}.'.format(epoch, args.epochs, i + 1, batches, ls.item() / len(point_clouds)))
# evaluation
autoendocer.eval()
total_cd_loss = 0
with torch.no_grad():
for data in test_dataloader:
point_clouds, _ = data
point_clouds = point_clouds.permute(0, 2, 1)
point_clouds = point_clouds.to(device)
recons = autoendocer(point_clouds)
ls = cd_loss(point_clouds.permute(0, 2, 1), recons.permute(0, 2, 1))
total_cd_loss += ls.item()
# calculate the mean cd loss
mean_cd_loss = total_cd_loss / len(test_dataset)
# records the best model and epoch
if mean_cd_loss < min_cd_loss:
min_cd_loss = mean_cd_loss
best_epoch = epoch
torch.save(autoendocer.state_dict(), os.path.join(args.log_dir, 'model_lowest_cd_loss.pth'))
# save the model every 100 epochs
if (epoch) % 100 == 0:
torch.save(autoendocer.state_dict(), os.path.join(args.log_dir, 'model_epoch_{}.pth'.format(epoch)))
end = time.time()
cost = end - start
print('\033[32mEpoch {}/{}: reconstructed Chamfer Distance is {}. Minimum cd loss is {} in epoch {}.\033[0m'.format(
epoch, args.epochs, mean_cd_loss, min_cd_loss, best_epoch))
print('\033[31mCost {} minutes and {} seconds\033[0m'.format(int(cost // 60), int(cost % 60)))














 1403
1403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









