






Transformer阅读笔记
主要内容:
摒弃CNN和RNN,使用attention机制实现sequence transduction model
网络结构以及component解释:
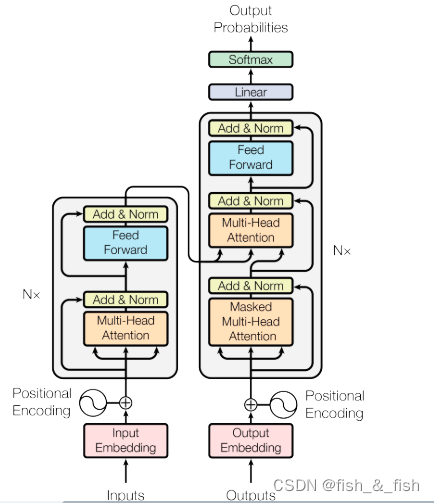
- Positional Encoding(再看看)
补充word的位置信息。就是将单词的位置信息表示出来再补充到输入中。
https://zhuanlan.zhihu.com/p/106644634 - self attention & MUti-Head attention

multi-head attention:使用多个attention,关注不同子空间的信息。生成的多维结果再映射回去

- ADD & NORM
Transformer 每个Block之后都会都跟一层Add & Norm,也就是先做residua再做Layer Norm。如果Add & Norm是跟在multi-head Attention之后,这一层的计算便是 Layer_norm(x + multi-head(x))。 - Feed forward
两层全连接+RELU+Layer norm。FC将数据先映射到高维空间再映射回低维空间可以学习到更加抽象的特征。添加非线性变化,增强word的representation的表达能力。 - mask multi-head attention
mask每个token后面的序列,保证在预测T+1的token时只会用到T及T以前的信息,如果不加future mask,预测T+1时就会用到T+1的文本本身,出现feature leakage。
Q & A:
- CNN && RNN 各自的特点?为什么摒弃了CNN和RNN?
(1) CNN(Convolutional Neural Network)经典基础结构:输入层、隐藏层(卷积层、池化层、全连接层)、输出层;擅长处理结构化数据
RNN (Recurrent Neural Network):经典处理是:(前一个时刻的输出,当前时刻的输入),基础RNN处理短期记忆,变体的LSTM(Long short-term memory)能够保留长期的记忆;擅长处理时序数据
(2) 普通RNN限制在(xt->xt+1)上,无法进行并行优化;LSTM能够保留的长期记忆有一定限度;CNN对于序列化数据的“序列”不敏感 - 向量空间转换 && embedding
https://zhuanlan.zhihu.com/p/475086668
因为低维数据one-hot太过稀疏,所以需要映射,嵌入到高维稠密空间里。 - Attention & self-attention
根据源句子与目标句子是否相同,分成了Attention和Self-Attention。其中,Attention是应用在源句子与目标句子不同时。Self Attention,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。 - 同样是处理序列数据,RNN和attention之间有什么不同呢?
RNN结构由于是单向传导,时序性太强,。而Decoder翻译的时候其实更需要当前要翻译的这个词的信息。而attention不依赖于上一个单词。除此之外,attention相比rnn还大大增加了计算效率(矩阵计算),不同距离的单词也可以很快的完成计算,不管被计算的这两个单词距离多远,计算注意力花的时间是一样的,这样就可以实现并行计算了。 - residual connection
- layer norm & batch norm
- layer norm:
Ba J L, Kiros J R, Hinton G E. Layer normalization;
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. - 不同的激活函数是怎样增强非线性表达的?
- 翻译任务中的BLEU是什么?
- 什么是跨实例的批处理?
- 因式分解技巧和条件计算能提高xt-》xt+1效率?
- CNN能够并行计算,但是操作数随着距离的拉长而增加,这是怎么增加的?
- 为什么平均注意力加权位置降低了有效分辨率?multihead怎么消除的这个影响?
- 什么是end to end memory networks?
- 什么是auto-regressive(2)?
- 怎么看待point-wise fully connected layers ?后面分feedforward
- residual connection是什么?(数学级别)x+sublayer(x)
- layer normalization是什么?(数学级别)
- sublayers和embedding layer各是什么? 512维是哪来的
- 矩阵方差(缩放因子问题)
- averaging指什么?
- 全连接那里的max
- 为什么共享权重矩阵?共享了哪几层的?
- 怎么理解position encoding?数学层面怎么解释?
- https://www.xljsci.com/index/index/documentCompare?pdf_id=12077357















 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









