









医学影像分割是一项艰巨的挑战,而众多数据集中注释数据的匮乏又加剧了这一挑战。半监督方法为缓解这一问题提供了可行的解决方案,而扩散模型的图像生成能力已显示出捕捉语义信息的潜力。本文介绍了通过扩散模型进行半监督医学图像分割的多重一致性(MCSD)。提出了基于扩散的特征引导模块(DFM),它能从预先训练好的扩散模型中提取特征,并使用多尺度特征来引导多一致性分割网络。此外,还引入了双分支图像一致性(DIC)策略,该策略通过生成两个独立的强增强图像来执行多一致性学习,并通过鼓励多层次特征和图像的强输入和弱输入之间保持一致来优化网络。方法优于现有的方法,通过各种标注数据比例的实验结果证明了它在半监督医学图像分割中的有效性。此外,这项研究还指出了扩散模型在半监督医学影像分割中的潜力,并为改进其在医学影像任务中的应用提出了建议。
Introduction
在本文中,提出了一种通过扩散模型进行半监督医学图像分割的多重一致性。目标是超越图像层面扰动的传统限制,充分利用多尺度特征层固有的丰富任务特定语义。为了实现这一目标,扩大了扰动的范围,在各个层面上都加入了扰动,引入了一套更多样化的扰动机制,其中包括图像层面和特征层面的扰动。在特征层面,利用多尺度的中间特征,因此采用扩散模型作为特征提取器,以捕捉图像的内在层次。与之前的方法[19,21]不同,使用扩散模型反向去噪过程中提取的多尺度特征作为扩散特征输入流。在图像层面,从同一幅未标记的弱扰动图像中生成两幅不同的增强图像,并用随机生成的 CutMix 掩码将它们稀疏地连接起来,以生成更多有意义的训练样本。此外,还通过输入具有不同强扰动效果的增强图像和扩散特征流,允许同时利用图像和特征层面的信息。不同程度的扰动相互补充,最终在强扰动和弱扰动图像以及扩散特征图之间使用了多种一致性正则化程序。
-提出了一种通过扩散模型进行半监督医学图像分割的多重一致性方法,名为 MCSD。方法能在图像和特征层面上加强弱输入扰动和强输入扰动之间的一致性,并利用多种类型的一致性优化技术。
-提出了基于扩散的特征引导模块(DFM),以扩展各层次扰动的不同方面。利用扩散模型捕捉图像固有的层次结构,提取多尺度中间扩散特征并有效降低其维度。这些多尺度特征图将反馈到一致性流中,指导特征层的分割任务。
-提出了用于图像级引导的双分支图像一致性(DIC)策略。通过使用随机 CutMix 掩码稀疏连接两个独立的强增强图像,为多一致性学习创建新的有用训练样本。
Method
图 1 展示了通过扩散模型进行半监督医学图像分割的多一致性概述。框架利用扩散模型从图像数据中提取更深层次的特征。它在图像和特征两个层面都采用了多一致性正则化,从而提高了网络在有限训练数据下的性能。
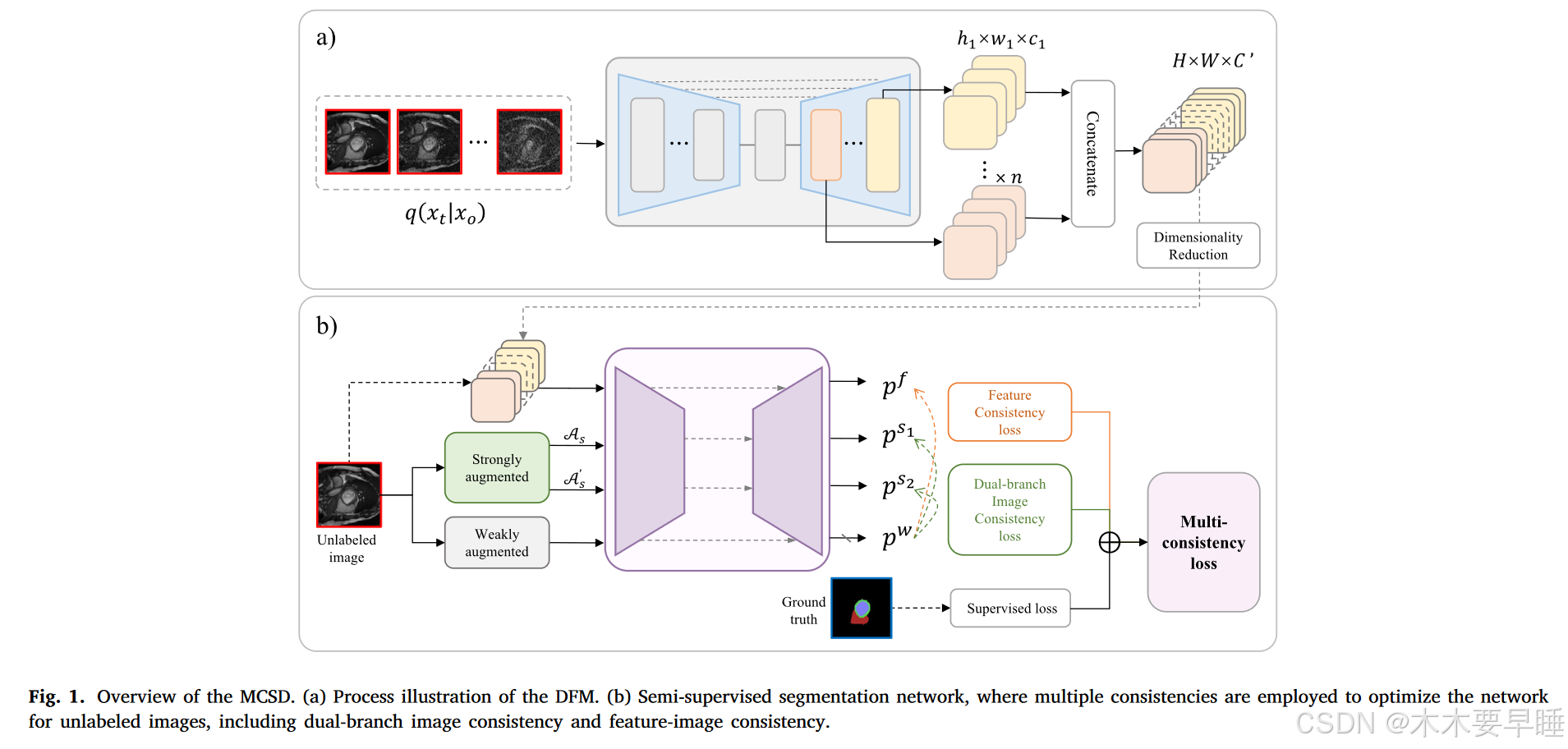
具体来说,首先以无监督的方式在未标记的医学图像上对扩散模型进行预训练。从预训练扩散模型的特定时间步骤和特定 U-Net 块中提取特征,并将它们串联起来,以获得基于扩散模型的特征引导视图,用于后续的下游分割任务。受 Fixmatch 和 Unimatch 的启发,对同一图像进行不同程度的扰动,并将从扩散模型中获得的特征以及强扰动和弱扰动的图像输入网络。最后,将弱扰动视图的预测结果转化为伪标签,并计算其他输入视图的预测结果与伪标签之间的一致性。训练数据集由 N 个标注图像和 M 个未标注图像组成,其中标注图像表示为 DN = {X1, ... , XN } ⊂ R^H×W ×C 与相应的标签 {Y1, ..., YN }⊂ R^H×W ,未标记的图像表示为 DM = {X1, ..., xm }⊂R^H×W ×C 。C 表示每幅图像的通道数。
Diffusion-based Feature-guided Module
基于扩散的特征引导模块(DFM)使用扩散模型在未标记的数据集上进行预训练,以从预训练的扩散去噪 U-Net 解码器中获得多元特征图。FDG 的工作流程如图 1a 所示。具体来说,首先使用无标记数据对扩散模型进行无监督训练。对于给定的无标签图像 x0 ∈ R^H×W ×1,根据公式(2)加入高斯噪声进行破坏。根据公式(3),噪声预测网络εθ(xt,t)由 B 块组成。不过,并不涉及所有区块中的所有特征张量,而是只选择部分区块中的特征张量进行后续处理。对于 U-Net 解码器中特定时间步长的特定块,提取的特征张量可以表示为 M b′ t′ = { M b1 t′ , M b2 t′ , ..., M bj t′ } 。.然后,利用双线性插值和连接运算将 U-Net 的中间表征上采样到输入大小,生成特征图,该特征图汇总了 U-Net 中间层的固有特征。最后,对特征图进行降维处理。 出于对内存的考虑,采用二维卷积层来限制聚合特征的通道数量。这种方法在不影响特征图空间分辨率的情况下,有效减少了模型中的参数数量。在组合和提取特征时减少通道数量有助于增强模型的表现力。因此,最终的特征图可以表示为:
![]()
经过这一过程,训练图像中所有像素的特征张量就形成了,被视为特征表示。特征图的总维数为 7680。将进行有效性实验,并在讨论对时间步骤、U-Net 解码器中的块和特征维度的选择进行分析。与其他方法的不同之处在于,不是提取单一时间步骤的特征,而是汇总多个时间步骤和 U-Net 块的特征向量。这些多尺度特征图包含更丰富的信息,可为后续的多连贯分割模型提供更多指导。此外,还对大型特征图采用了有效的降维模块,使其对模型更加友好,并减少了模型参数的数量。
Dual-branch image consistency
通过基于扩散的特征引导模块来获取未标记图像的多尺度特征图。扩散模型在图像制作中的实用性已得到广泛证实,证明了其捕捉语义相关信息的能力。通过自我监督训练,扩散模型可以发现医学图像中与生俱来的层次结构,使其成为出色而有效的特征提取工具。从反向去噪过程中提取的丰富特征可以在图像和特征两个层面上指导后续任务。同时,在图像层面,提出了双分支图像一致性(DIC)策略,通过鼓励双视角图像信息的一致性来增强模型的鲁棒性和泛化能力。DIC 的工作流程如图 1b 所示。对每张未标记的图像 xu 进行不同程度的扰动,即弱扰动 w(如裁剪)和强扰动 s(如色彩抖动),生成两张独立的强增强图像,用于多一致性学习。然后,用随机生成的 CutMix 将强增强图像连接起来,创建新的信息训练样本。受 Noisy Student [2] 的启发,我们引入了随机网络 dropout ,为未标记的图像引入噪声扰动,从而增强网络的泛化能力。
具体来说,从 UniMatch 提出的 DusPerb 中汲取了灵感。为了更好地利用图像和特征层面的信息,同时结合扩散特征流,从同一张未标记的弱扰动图像中生成两张独立的增强图像,并引入 CutMix [8] 数据增强技术来提供不同的强扰动,从而增强模型对数据的理解和泛化能力。通过使用 CutMix 数据增强技术,可以将两幅未标记的强增强图像 xs1 和 xs2 结合起来,创建新的强增强未标记训练样本( xs, ̃ yu),如下所示:
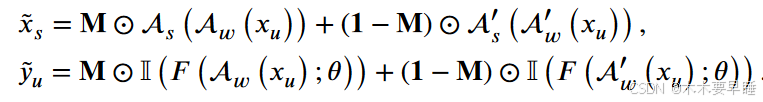
二进制掩码 M∈{0, 1}H×W 表示填充和提取在训练集两幅图像中的位置,而 1 则表示填充的二进制掩码。符号 ⊙ 表示逐元素乘法运算。这种图像的混合过程与最初的 CutMix [8] 非常相似。用另一张训练图像的补丁替换图像区域,可以生成局部更自然的图像。I(⋅) = argmax(⋅) 和 yu 表示相应的未标记输入图像的伪标签,θ 表示分割网络 F (θ) 的参数。虽然图像的强扰动和弱扰动定义明确,但每两种扰动操作并不相同,分别表示为 A 和 A′。对图像和特征的操作可表示如下:
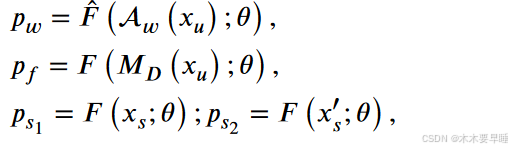
其中,教师模型 ̂ F 输入的弱扰动未标记图像的预测结果被转换为伪标签,强扰动下的未标记图像及其相应的多尺度特征图被输入学生模型 F。这里,xs 和 x′ s 表示两个独立增强的原始图像 xs 的不同强扰动版本。相应地,ps1 和 ps2 表示对这两种不同输入的预测。最后,计算伪标签和学生模型预测之间的一致性损失,以优化模型。
Multi-consistency loss
方法基于 Fixmatch [4],但不同之处在于,对于无标记数据,不仅利用双分支图像一致性,还利用扩散特征级一致性正则化来帮助网络学习更多信息。总目标函数由有监督损失 ls 和无监督损失 lu 组成:
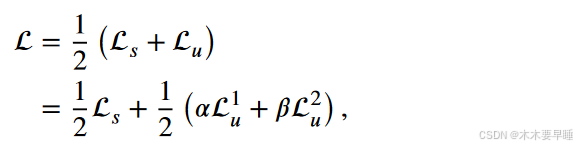
其中参数 α 和 β 是一致性损失的权重。有监督项 ls 代表交叉熵损失。相比之下,无监督损失 lu 调节强扰动和弱扰动下预测的一致性,包括特征一致性损失 l1 u 和双分支图像一致性损失 l2 u。
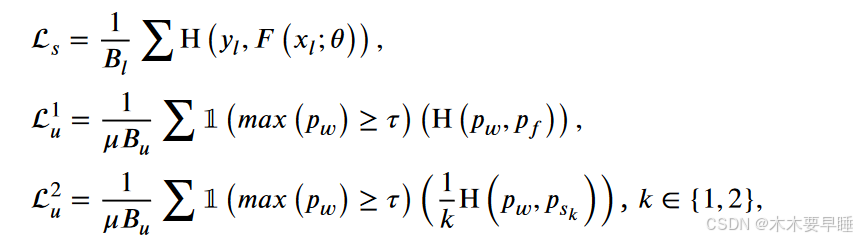
其中,B 是批量大小,τ 是预定义的置信度阈值,用于过滤掉不可靠的标签,而 H 则使两个概率分布之间的熵最小化。使用 FixMatch 框架作为基础半监督框架,并使用 U-Net 作为学生-教师模型的骨干网络,两者具有相同的架构。在网络的上采样和下采样之间应用模型噪声滤除,滤除率设定为 0.5。
Experiments
Implementation details
采用了 Dhariwal 和 Nichol [36] 预先训练好的带有预定义参数的引导扩散模型。该阶段的批量大小为 24,学习率设置为 1e-4。在第 50、150 和 250 步时,分别从 U-Net 解码器的第二、第四和第六块提取特征。从不同步骤获得的特征在同一特征块内沿着特征维度进行串联。这些 U-Net 块和时间步骤采用了与 [14] 中所述类似的特征提取设置。出于对内存的考虑,使用二维卷积层来降低集成特征的维度。通常情况下,如果只对沿特征维度的变换感兴趣,一个卷积层就足够了,不需要额外的模块,从而保持了简洁性并降低了模型的复杂度。
在 ACDC 数据集中,以 256 × 256 的分辨率训练扩散模型,并通过双线性插值将提取的特征上采样到原始分辨率。最终得到维度为 30 的特征向量,作为扩散特征输入到分割网络流中。在推理过程中,根据原始图像的大小对预测结果进行缩放,并将其堆叠成三维体积,然后计算相应的评价指标。同时,使用 ACDC 数据集的设置来训练 M&Ms 数据集。鉴于 M&Ms 数据集的规模更大,将训练迭代次数从 300 次增加到 600 次。



















 1071
1071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











