







机器学习(八):DBSCAN算法(基础篇)
K-Means算法和 Mean Shift算法都是基于距离的聚类算法,基于距离的聚类算法的聚类结果是球状的簇,当数据集中的聚类结果是非球状结构时,基于距离的聚类算法的聚类效果并不好。
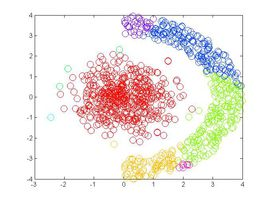
与基于距离的聚类算法不同的是,基于密度的聚类算法可以发现任意形状的聚类。在基于密度的聚类算法中,通过在数据集中寻找被低密度区域分离的高密度区域,将分离出的高密度区域作为一个独立的类别。
密度聚类
密度聚类也被称作“基于密度的聚类”(density-based clustering),此算法假设聚类结构能通过样本分布的紧密程度确定,通常情况下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类以获取最终的聚类结果。
DBSCAN算法
DBSCAN算法是一种著名的聚类算法,它基于一组“邻域”(neighborhood)参数来刻画样本分布的紧密程度。想要了解DBSCAN算法,DBSCAN是一种很典型的密度聚类算法,和K-Means,BIRCH这些一般只适用于凸样本集的聚类相比,DBSCAN既可以适用于凸样本集,也可以适用于非凸样本集。首先需要知道下面几个概念:
给定数据集$D={x_1,x_2,…,x_m} $:,则:
- ϵ \epsilon ϵ-邻域:对 x i ∈ D x_i\in D xi∈D,其 ∈ \in ∈-邻域包含样本集D中于 x j x_j xj不大于 ϵ \epsilon ϵ的样本,即 N ϵ ( x j ) = { x i ∈ D ∣ d i s t ( x i , x j ) ≤ ϵ } N_{\epsilon}(x_j)=\{x_i\in D|dist(x_i, x_j )\le \epsilon\} Nϵ(xj)={xi∈D∣dist(xi,xj)≤ϵ} 其中,dist()默认情况下为欧式距离。(可以将邻域理解为一个圆,圆内包含着一定数量的样本)
- 核心对象:若 x j x_j xj的 ϵ \epsilon ϵ-邻域至少包含 M i n P t s MinPts MinPts个样本,即 ∣ N ϵ ∣ ≥ M i n P t s |N_{\epsilon}| \ge MinPts ∣Nϵ∣≥MinPts,则 x j x_j xj是一个核心对象。(简单理解就是:圆的中心(即核心对象)周围必须超过MinPts个样本。)
- 密度直达:若 x j x_j xj位于 x i x_i xi的 ϵ \epsilon ϵ-邻域中,且 x i x_i xi是核心对象,则称 x j x_j xj由 x i x_i xi密度直达。(可以理解为点 x j x_j xj在以 x i x_i xi为圆心的圆中)
- 密度可达:对 x i x_i xi于 x j x_j xj,若存在样本序列 p 1 , p 2 , . . . , p n p_1,p_2,...,p_n p1,p2,...,pn,其中 p 1 = x i , p n = x j p_1=x_i,p_n=x_j p1=xi,pn=xj,且 p i + 1 p_{i+1} pi+1由 p i p_i pi密度直达,则称 x i x_i xi与 x j x_j xj密度可达。( p 1 , p 2 , p 3 , . . . . p n − 1 都 为 核 心 对 象 , 但 是 p n 不 为 核 心 对 象 ) p_1,p_2,p_3,....p_{n-1}都为核心对象,但是p_n不为核心对象) p1,p2,p3,....pn−1都为核心对象,但是pn不为核心对象)
- 密度相连:对 x i x_i xi和 x j x_j xj,若存在 x k x_k xk使得 x i x_i xi与 x j x_j xj均由 x k x_k xk密度可达,则称 x i x_i xi与 x j x_j xj密度相连。(可以理解为 x i 和 x j x_i和x_j xi和xj都不是核心对象,但是 x k x_k xk为核心对象,并且作为媒介可以密度直达对方。)

基于密度的聚类算法通过寻找被低密度区域分离的高密度区域,并将高密度区域作为一个聚类的“簇”。在DBSCAN算法中,聚类“簇”定义为:由密度可达关系导出的最大的密度连接样本的集合。

DBSCAN算法流程
在DBSCAN算法中,有核心对象出发,找到与该核心对象密度可达的所有样本形成“簇”。DBSCAN算法的流程为:
- 根据给定的邻域参数Eps和MinPts确定所有的核心对象
- 对每一个核心对象
选择一个未处理过的核心对象,找到由其密度可达的的样本生成聚类“簇 - 重复以上过程
数据集:UCI上的iris数据集进行算法测试。
网址:http://archive.ics.uci.edu/ml/index.php
伪代码如下:

我们来看看代码实现:
#-*- coding:utf-8 -*-
import numpy as np
import pandas as pd
import math
def distance(data):
"""
计算样本之间的距离
:param data: 样本
:return: dis(mat)样本之间的距离
"""
m, n = np.shape(data)
dis = np.mat(np.zeros((m, m)))
for i in range(m):
for j in range(i, m):
#计算i和j之间的欧式距离
tmp = 0
for k in range(n):
tmp += (data[i, k] - data[j, k]) * (data[i, k] - data[j, k])
dis[i, j] = np.sqrt(tmp)
dis[j, i] = dis[i, j]
return dis
def find_eps(distance_D, eps):
"""
找到距离的《=esp的索引
:param distance_D: 样本i与其他样本直接按的距离
:param eps: 半径的大小
:return: ind与样本i之间的距离《=eps的样本索引
"""
ind = []
n = np.shape(distance_D)[1]
for j in range(n):
if distance_D[0, j] <= eps:
ind.append(j)
return ind
def dbscan(data, eps, MinPts):
"""
DBSCAN算法
:param data:需要聚类的数据集
:param eps: 半径
:param MinPts: 半径内最少的数据点
:return:
types:每个样本类型,核心点,边界点,噪音点
sub_class:每个样本所属的类别
"""
m = np.shape(data)[0]
# 在types中,1为核心点,0为边界点,-1为噪音点
types = np.mat(np.zeros((1, m)))
sub_class = np.mat(np.zeros((1, m)))
# 用于判断该点是否处理过,0表示未处理过
dealt = np.mat(np.zeros((m, 1)))
# 计算每个数据点之间的距离
dis = distance(data)
# 用于标记类别
number = 1
# 对每一个点进行处理
for i in range(m):
# 找到未处理的点
if dealt[i, 0] == 0:
# 找到第i个点到其他所有点的距离
D = dis[i,]
# 找到半径eps内的所有点
ind = find_eps(D, eps)
# 区分点的类型
# 边界点
if len(ind) > 1 and len(ind) < MinPts + 1:
types[0, i] = 0
sub_class[0, i] = 0
# 噪音点
if len(ind) == 1:
types[0, i] = -1
sub_class[0, i] = -1
dealt[i, 0] = 1
# 核心点
if len(ind) >= MinPts + 1:
types[0, i] = 1
for x in ind:
sub_class[0, x] = number
# 判断核心点是否密度可达
while len(ind) > 0:
dealt[ind[0], 0] = 1
D = dis[ind[0],]
tmp = ind[0]
del ind[0]
ind_1 = find_eps(D, eps)
if len(ind_1) > 1: # 处理非噪音点
for x1 in ind_1:
sub_class[0, x1] = number
if len(ind_1) >= MinPts + 1:
types[0, tmp] = 1
else:
types[0, tmp] = 0
for j in range(len(ind_1)):
if dealt[ind_1[j], 0] == 0:
dealt[ind_1[j], 0] = 1
ind.append(ind_1[j])
sub_class[0, ind_1[j]] = number
number += 1
# 最后处理所有未分类的点为噪音点
ind_2 = ((sub_class == 0).nonzero())[1]
for x in ind_2:
sub_class[0, x] = -1
types[0, x] = -1
return types, sub_class
def epsilon(data, MinPts):
'''计算最佳半径
input: data(mat):训练数据
MinPts(int):半径内的数据点的个数
output: eps(float):半径
'''
m, n = np.shape(data)
xMax = np.max(data, 0)
xMin = np.min(data, 0)
eps = ((np.prod(xMax - xMin) * MinPts * math.gamma(0.5 * n + 1)) / (m * math.sqrt(math.pi ** n))) ** (1.0 / n)
return eps
def loadDataSet(filename):
"""
函数说明:从文件中下载数据,并将分离除连续型变量和标签变量
:parameter:
data - Iris数据集
attributes - 鸢尾花的属性
type - 鸢尾花的类别
sl-花萼长度 , sw-花萼宽度, pl-花瓣长度, pw-花瓣宽度
:return:
"""
iris_data = pd.read_csv(filename) #打开文件
iris_data = pd.DataFrame(data=np.array(iris_data), columns=['sl', 'sw', 'pl', 'pw', 'type'], index=range(149)) #给数据集添加列名,方便后面的操作
attributes = iris_data[['sl', 'sw', 'pl', 'pw']] #分离出花的属性
iris_data['type'] = iris_data['type'].apply(lambda x: x.split('-')[1]) # 最后类别一列,感觉前面的'Iris-'有点多余即把class这一列的数据按'-'进行切分取切分后的第二个数据
labels = iris_data['type'] #分理出花的类别
attriLabels = [] #建立一个标签列表
for label in labels: #为了更方便操作,将三中不同的类型分别设为1,2,3
if label == 'setosa': #如果类别为setosa的话,设为1
attriLabels.append(1)
elif label == 'versicolor': #如果是versicolor的时候设为2
attriLabels.append(2)
elif label == 'virginica': #如果是virginica的时候设为3
attriLabels.append(3)
return attributes, attriLabels
if __name__ == '__main__':
attributes, attriLabels = loadDataSet('iris.data')
data = np.mat(attributes)
eps = epsilon(data, 3)
types, sub_class = dbscan(data, eps, 3)
# print(sub_class)
m = len (attributes)
right = 0
sub_class = sub_class.tolist()[0]
for lens in range(m):
if int(sub_class[lens]) == attriLabels[lens]:
right += 1
a = 100*(m-right)/m
print("错误率:",a, "%")
结果如下:

由于数据集的一些原因,导致算法并不能特别好的进行分类。














 2697
2697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









