







1 DBSCAN
1.1 基本介绍
Density-Based Spatial Clustering of Applications with Noise
- 将“密集分组”的数据点分组到一个簇中。
- 通过查看数据点的局部密度来识别聚类。
- 对异常值具有鲁棒性,同时也不需要事先告知簇的数量
- 可以发现任意形状的聚类簇
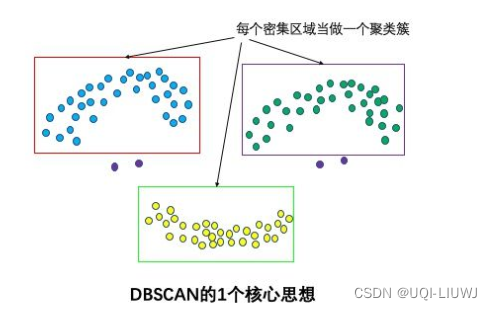
在聚类问题中,如果数据集的各类呈球形分布,可以采用kmeans聚类算法,如果各类数据呈非球形分布(如太极图、笑脸图等),采用kmeans算法效果将大打折扣,这种情况使用DBSCAN聚类算法更为合适

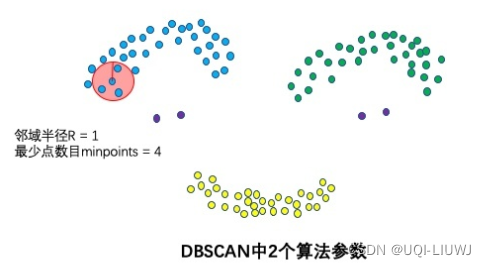
1.2 两个参数:epsilon和minPoint
- DBSCAN 只需要两个参数:epsilon (邻域半径)和 minPoints(最少点数目)。
- Epsilon 是围绕每个数据点创建的用于检查密度的圆的半径
- minPoints 是要将该数据点分类为核心点所需的圆内数据点的最小数量
- 在更高维度中,圆变为超球面,epsilon 变为该超球面的半径,minPoints 是该超球面内所需的最小数据点数。
1.2.1 举例:
比如现在我们有如下的数据点:

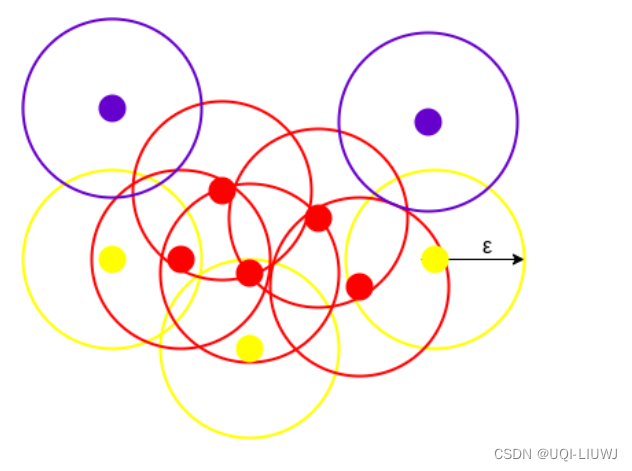
- DBSCAN 在每个数据点周围创建一个 epsilon 半径的圆,并将它们分类为核心点、边界点和噪声。
- 如果数据点周围的圆至少包含“minPoints”个点,则该数据点是核心点。
- 如果点数小于minPoints,那么它被归类为Border Point
- 如果epsilon半径内任何数据点周围没有其他数据点,那么它被视为Noise。
- 上图向我们展示了由 DBCAN 创建的 minPoints = 3 的集群。在这里,我们在每个数据点周围绘制了一个等半径 epsilon 的圆。 这两个参数有助于创建空间集群。
- 圆圈内至少有3个点的所有数据点(3个点包括它自己),都被认为是用红色表示的核心点。
- 圆内所有小于 3 个但大于 1 个点的数据点(包括它自己)都被认为是 边界 点。 它们由黄色表示。
- 圆圈内除了自身之外没有其他点的数据点被认为是紫色表示的噪声。
- 为了在空间中定位数据点,DBSCAN 使用欧氏距离,但也可以使用其他方法(如地理数据的大圆距离)。
- DBSCAN 只需要扫描整个数据集一次,而在其他算法中我们必须多次扫描。
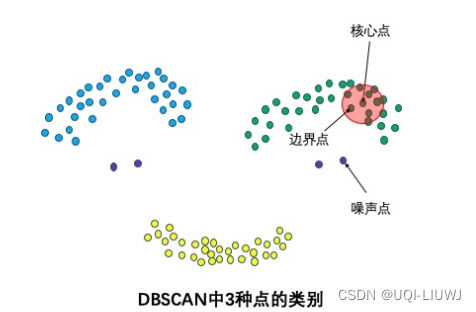
1.3 可达性和连通性
- 可达性说明一个数据点是否可以直接或间接地从另一个数据点访问,而连接性说明两个数据点是否属于同一个集群。
- 在可达性和连通性方面,DBSCAN中的两个点可以被划分为:
- 直接密度可达(Directly Density-Reachable)
- 密度可达(Density-Reachable)
- 密度连接(Density-Connected)
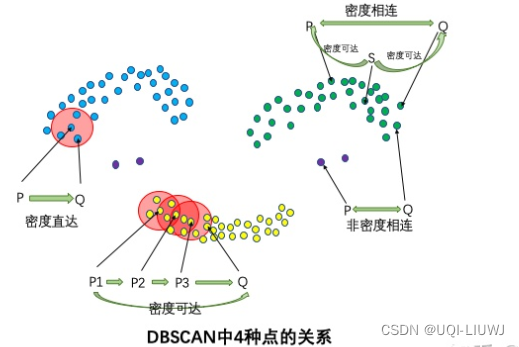
1.3.1 直接密度可达
- 如果满足如下条件,那么点X是点Y直接密度可达的
- X属于Y的邻居(dist(X,Y) ≤epsilon)
- Y是核心点
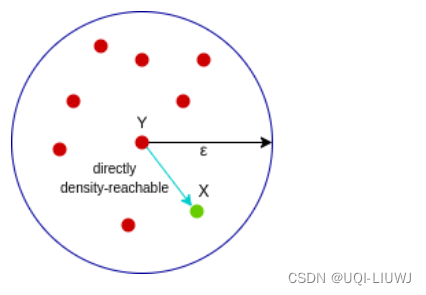
- 上图中X是Y直接密度可达的,但Y不是X的直接密度可达(因为X不是核心点)
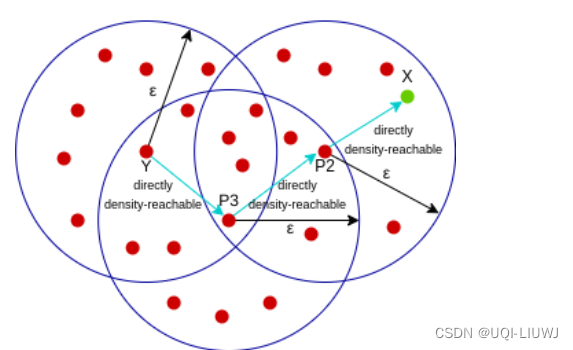
1.3.2 密度可达
- 点x是点y密度可达的,如果:
- 有一点链p1,p2,....,pn,其中:
- p1=x
- pn=y
和pi是直接密度可达的
- 有一点链p1,p2,....,pn,其中:
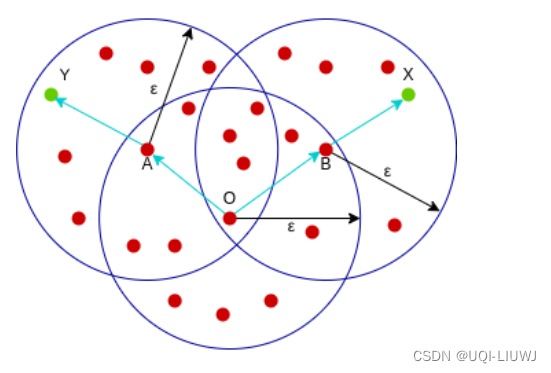
1.3.3 密度连接
- 点X和点Y是密度连接的,如果:
- 有一个点O,X和Y都和O密度可达
1.4 算法描述
- DBSCAN 算法对簇的定义很简单,由密度可达关系导出的最大密度相连的样本集合,即为最终聚类的一个簇。
- DBSCAN 算法的每一个簇里面可以有一个或者多个核心点。
- 如果只有一个核心点,则簇里其他的非核心点样本都在这个核心点的 epsilon 邻域里。
- 如果有多个核心点,则簇里的任意一个核心点的 epsilon邻域中一定有一个其他的核心点,否则这两个核心点无法密度可达。
- 这些核心点的 epsilon邻域里所有的样本的集合组成一个 DBSCAN 聚类簇。
1.5 算法流程
1.5.1 输入输出
输入:数据集,邻域半径 epsilon,邻域中数据对象数目阈值 minPoints;
输出:密度联通簇。
1.5.2 流程
1)从数据集中任意选取一个数据对象点 p;
2)如果对于参数 epsilon 和 minPoints,所选取的数据对象点 p 为核心点,则找出所有从 p 密度可达的数据对象点,形成一个簇;
3)如果选取的数据对象点 p 是边缘点,选取另一个数据对象点;
4)重复(2)、(3)步,直到所有点被处理。
1.6 算法复杂度
O(n2)
1.7 参数的选择
- DBSCAN 对 epsilon 和 minPoints 的值非常敏感。
- 因此,了解如何选择 epsilon 和 minPoints 的值非常重要。
- 这些值的轻微变化会显着改变 DBSCAN 算法产生的结果。
- minPoints 的值应该至少比数据集的维数大一,即minPoints>=Dimensions+1。
- 将 minPoints 设为 1 没有意义,因为这会导致每个点成为一个单独的簇。 因此,它必须至少为 3。
- 一般情况下,它是维度的两倍。 但domain knowledge也决定了它的价值
- 如果选择的 epsilon 值太小,则会创建更多的聚类,更多的数据点将被视为噪声。 然而,如果选择太大,那么各种小集群将合并成一个大集群,我们将丢失细节。
2 举例
记epsilon=3,minpoints=3
2.1 数据集

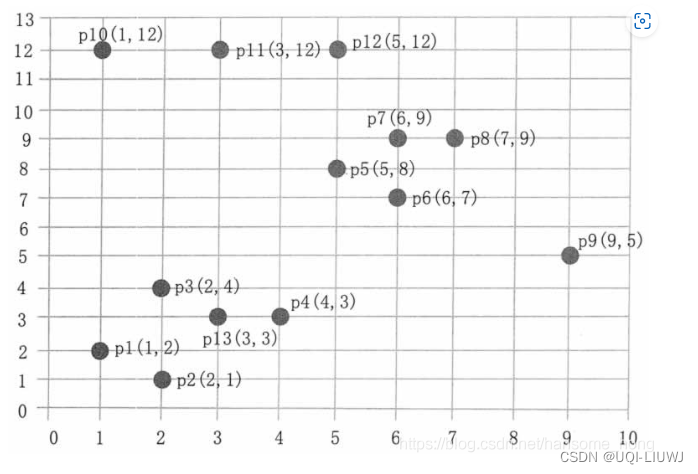
2.2 DBSCAN算法步骤
- 第一步,顺序扫描数据集的样本点,首先取到 p1(1,2)。
- 1)计算 p1 的邻域,计算出每一点到 p1 的距离,如 d(p1,p2)=sqrt(1+1)=1.414。
- 2)根据每个样本点到 p1 的距离,计算出 p1 的 epsilon 邻域为 {p1,p2,p3,p13}。
- 3)因为 p1 的 Eps 邻域含有 4 个点,大于 MinPts(3),所以,p1 为核心点。
- 4)以 p1 为核心点建立簇 C1,即找出所有从 p1 密度可达的点。
- 5)p1 邻域内的点都是 p1 直接密度可达的点,所以都属于C1。
- 6)寻找 p1 密度可达的点,
- p2 的邻域为 {p1,p2,p3,p4,p13},因为 p1 密度可达 p2,p2 密度可达 p4,所以 p1 密度可达 p4,因此 p4 也属于 C1。
- p3 的邻域为 {p1,p2,p3,p4,p13},p13的邻域为 {p1,p2,p3,p4,p13},p3 和 p13 都是核心点,但是它们邻域的点都已经在 Cl 中。
- P4 的邻域为 {p3,p4,p13},为核心点,其邻域内的所有点都已经被处理。
- 7)此时,以 p1 为核心点出发的那些密度可达的对象都全部处理完毕,得到簇C1,包含点 {p1,p2,p3,p13,p4}。
- 第二步,继续顺序扫描数据集的样本点,取到p5(5,8)。
1)计算 p5 的邻域,计算出每一点到 p5 的距离,如 d(p1,p8)-sqrt(4+1)=2.236。
2)根据每个样本点到 p5 的距离,计算出p5的Eps邻域为{p5,p6,p7,p8}。
3)因为 p5 的 Eps 邻域含有 4 个点,大于 MinPts(3),所以,p5 为核心点。
4)以 p5 为核心点建立簇 C2,即找出所有从 p5 密度可达的点,可以获得簇 C2,包含点 {p5,p6,p7,p8}。
- 第三步,继续顺序扫描数据集的样本点,取到 p9(9,5)。
1)计算出 p9 的 Eps 邻域为 {p9},个数小于 MinPts(3),所以 p9 不是核心点。
2)对 p9 处理结束。
- 第四步,继续顺序扫描数据集的样本点,取到 p10(1,12)。
- 1)计算出 p10 的 Eps 邻域为 {p10,pll},个数小于 MinPts(3),所以 p10 不是核心点。
- 2)对 p10 处理结束。
- 第五步,继续顺序扫描数据集的样本点,取到 p11(3,12)。
- 1)计算出 p11 的 Eps 邻域为 {p11,p10,p12},个数等于 MinPts(3),所以 p11 是核心点。
- 2)从 p12 的邻域为 {p12,p11},不是核心点。
- 3)以 p11 为核心点建立簇 C3,包含点 {p11,p10,p12}。
- 第六步,继续扫描数据的样本点,p12、p13 都已经被处理过,算法结束。
3 算法优劣
3.1 优点
- 1)和传统的 k-means 算法相比,DBSCAN 算法不需要输入簇数 k 而且可以发现任意形状的聚类簇
- 2)聚类结果没有偏倚,而 k-means 之类的聚类算法的初始值对聚类结果有很大影响。
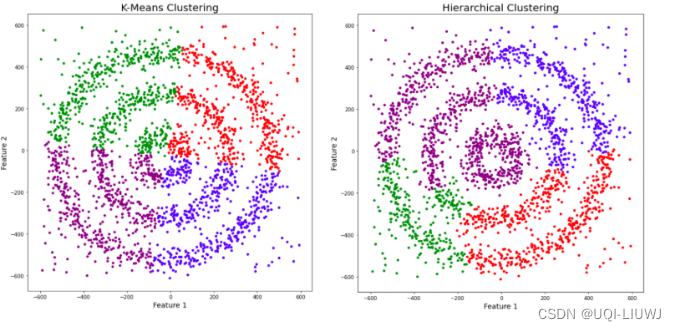
- 3)同时,在聚类时可以找出异常点。(如下图的比较)
相比于K-means和分层聚类,DBSCAN 不仅能够正确地聚类数据点,而且还能完美地检测数据集中的噪声。

3.2 缺点
1)样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用 DBSCAN 算法一般不适合。
2)样本集较大时,聚类收敛时间较长
3)调试参数比较复杂时,主要需要对距离阈值epsilon,邻域样本数阈值minpoint进行联合调参,不同的参数组合对最后的聚类效果有较大影响。
4)对于整个数据集只采用了一组参数。如果数据集中存在不同密度的簇或者嵌套簇,则 DBSCAN 算法不能处理。为了解决这个问题,有人提出了 OPTICS 算法。
参考内容
How Does DBSCAN Clustering Work? | DBSCAN Clustering for ML (analyticsvidhya.com)


















 1961
1961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











