










反向传播算法 Back-Propagation 数学推导以及源码详解 深度学习 Pytorch笔记 B站刘二大人(3/10)
数学推导
BP算法 BP神经网络可以说机器学习的最基础网络。对于普通的简单的神经网络层,我们还能通过推导计算得到梯度表达式,但是当网络结构如下图所示
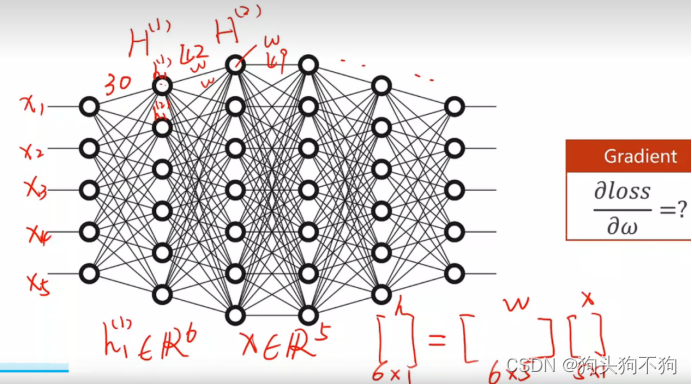
此时梯度grad就变成了非常庞大的计算量,对于复杂的多层级网络,权重w个数多,无法直接对权重w进行解析式求导。面对这种情况我们引入数据结构中的图的概念,通过形成计算图在图上传播梯度,利用链式法则对各个节点的梯度进行求解。
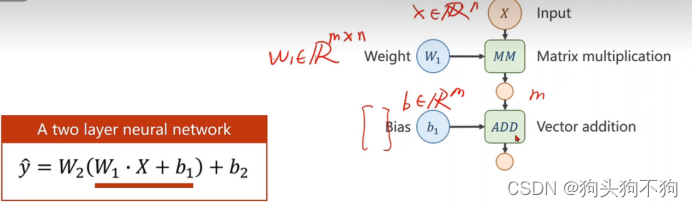
需要注意的是,基础线性单元(一层)的构成,应该以矩阵思维看待,w权重矩阵+b偏置量,将参数和输入输出都视为向量或者矩阵。Matrix cookbook 是主要矩阵运算的参考资料,可以去查阅。
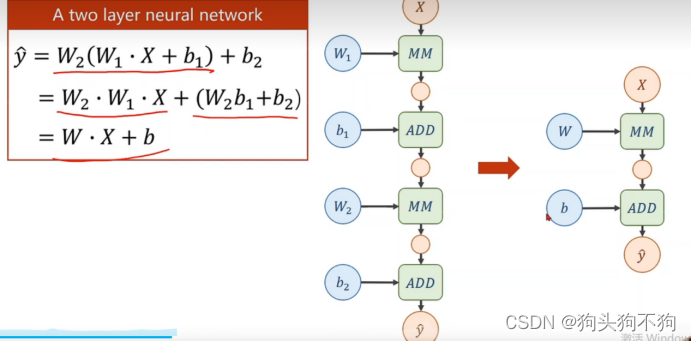
由于各个层都是线性关系,而线性映射之间可以进行线性拼接和化简,会导致多个线性层直接连接与单一线性层的功能相同,无法表示足够的网络复杂程度。在此引入激活函数概念,在各个层之间连接处加入激活函数Sigmoid
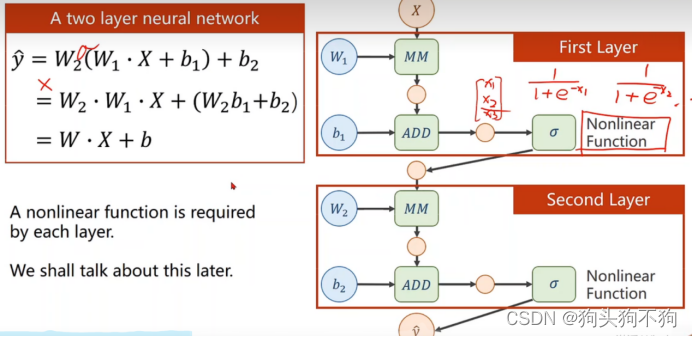
在每一线性层后加上激活函数Nonliner Function,激活函数的本质是非线性映射
eg: sigmoid: x -> 1/1+e^(-x1)
之后通过链式法则,累计求导,实际上就是高数中的复合函数求导和求偏导的相关知识,如下图
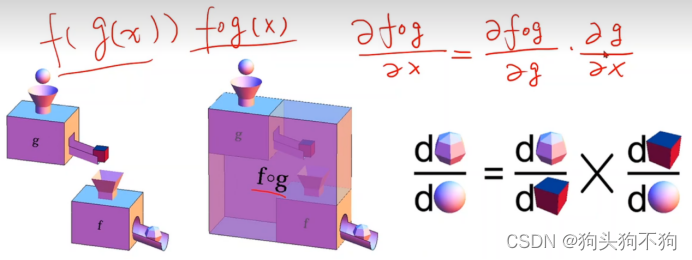
梯度计算过程,首先前馈计算出loss函数,之后根据loss函数,之后反向求loss与输出Z导数,由于Z由输入x和权重w的复合组成,因此可以求出loss与x和w的导数,根据loss的意义,loss最小则模型达到最优,而x输入为固定,则根据w关于loss导数动态调整w进行更新即可得到最新的loss
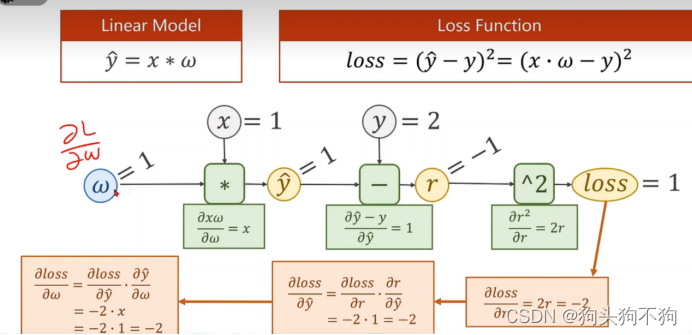
细节:在多层的运算过程中一般会将求导的导数存储在层单元中,pytorch是将导数存储在输入单元x中,而非运算模块f=x*w中
下图是Forward与backward具体流程推导,其中注意wx与wx+b的区别
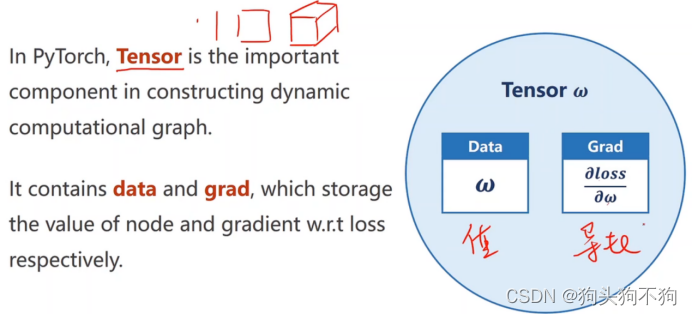
Pytorch基本数据类型tensor,用于储存所有数值(标量,向量,矩阵,高维矩阵),主要成员:data保存权重本身值+grad损失函数对权重的导数
源码解读与实现

编程细节,在进行数据类型定义的时候将w的tensor数据类型中求导的标识符定义为真**(tensor数据类型默认不进行梯度求导以节省运算)**

此时,运算符重载,进行tensor与tensor之间的乘法运算,将x自动进行数据转化变换为tensor类型,同时该计算模块由于内部成员w是需要进行梯度计算的tensor类型x,则该计算模块x*w也自动将梯度计算的表示符转化为true
需要注意的是,在tensor的计算中是按照图的形式进行生成,每进行一次调用和运行,就动态生成一次计算图
- .backward()函数将整条计算链上的梯度全部进行计算并存储**,在进行一次backward后,将之前生成的计算图进行清除释放**
- .data运算,通过.data运算是直接运算其中的存储数据进行标量计算,而不构建计算图,如果使用w直接进行计算将在运算过程中构建计算图,产生大量冗余计算。
3.在计算中不可以定义sum使用sum += l将loss值累加,同样因为l为张量,在与标量sum进行计算的过程中将生成计算图,产生冗余运算。如使用需要使用语句 sum += l.item()
整体代码
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0 ,6.0]
w = torch.Tensor([1.0]) # 预测模型的参数w应当作为tensor量进行定义
w.requires_grad = True # 将tensor中的求导标识符定义为True,默认为False
def forward(x):
return x * w # 注意:此时由于w是tensor张量,在进行乘法时自动讲x转换为张量,进行张量乘法
def loss(x,y):
y_pred = forward(x) #调用forward函数计算预测值
return (y_pred - y)**2 #返回损失
print("predict (before training)", 4, forward(4).item()) # 输出未训练的结果
for epoch in range(100):
for x,y in zip(x_data, y_data):
l = loss(x,y) #计算损失函数
l.backward() #计算梯度,注意此时进行的是计算图运算
print("\t grad:", x, y, w.grad.item()) # w属于张量,运算将生成计算图,因此用item函数调用标量数据
w.data = w.data - 0.01 * w.grad.item()
w.grad.data.zero_() #梯度清零
print("progress:", epoch, l.item())
print("predict (after training)", 4, forward(4).item()) #输出训练预测值















 2303
2303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











