










Decoupling with Entropy-based Equalization for Semi-Supervised Semantic Segmentation
半监督语义分割与基于熵的均衡解耦
Paper:https://www.ijcai.org/proceedings/2023/74
Code:None
Abstract
半监督语义分割方法是缓解语义分割中标注消耗高问题的主要解决方案。然而,类不平衡问题使得模型偏向于训练样本充足的头类,导致尾类的性能较差。
为了解决这个问题,我们提出了一种基于师生模型的解耦半监督语义分割( D e S 4 DeS^4 DeS4)框架。具体来说,我们首先提出了一种解耦训练策略,将编码器和分段解码器的训练分开,以实现平衡解码器。
然后,提出了一种基于不可学习原型的分割头来正则化类别表示分布一致性,并在教师模型和学生模型之间进行更好的连接。
此外,提出了一种多熵采样(MES)策略来收集像素表示以更新共享原型以获得类别无偏的头部。
我们在两个具有挑战性的基准(PASCAL VOC 2012 和 Cityscapes)上对所提出的 D e S 4 DeS^4 DeS4 进行了广泛的实验,并比以前最先进的方法取得了显着的改进。
1 Introduction
语义分割是计算机视觉领域最基本的任务之一,它可以应用于自动驾驶汽车和电影编辑等许多应用中。近年来,基于深度神经网络的语义分割取得了显着的进展[He et al, 2016; Chen et al, 2018a] 以及大规模注释良好的分割数据集 [Everingham et al, 2015; Cordts 等人,2016]。现有的基于深度学习的完全监督分割方法需要大量数据,并且需要大规模数据集进行训练。然而,获取分割数据集非常耗时且费力,因为它们是像素级掩模的密集注释。为了缓解这种高注释消耗问题,半监督语义分割受到了广泛关注[French et al, 2020;邹等人,2021; Chen et al, 2021],它提供了利用有限注释和大量未标记图像的潜力。
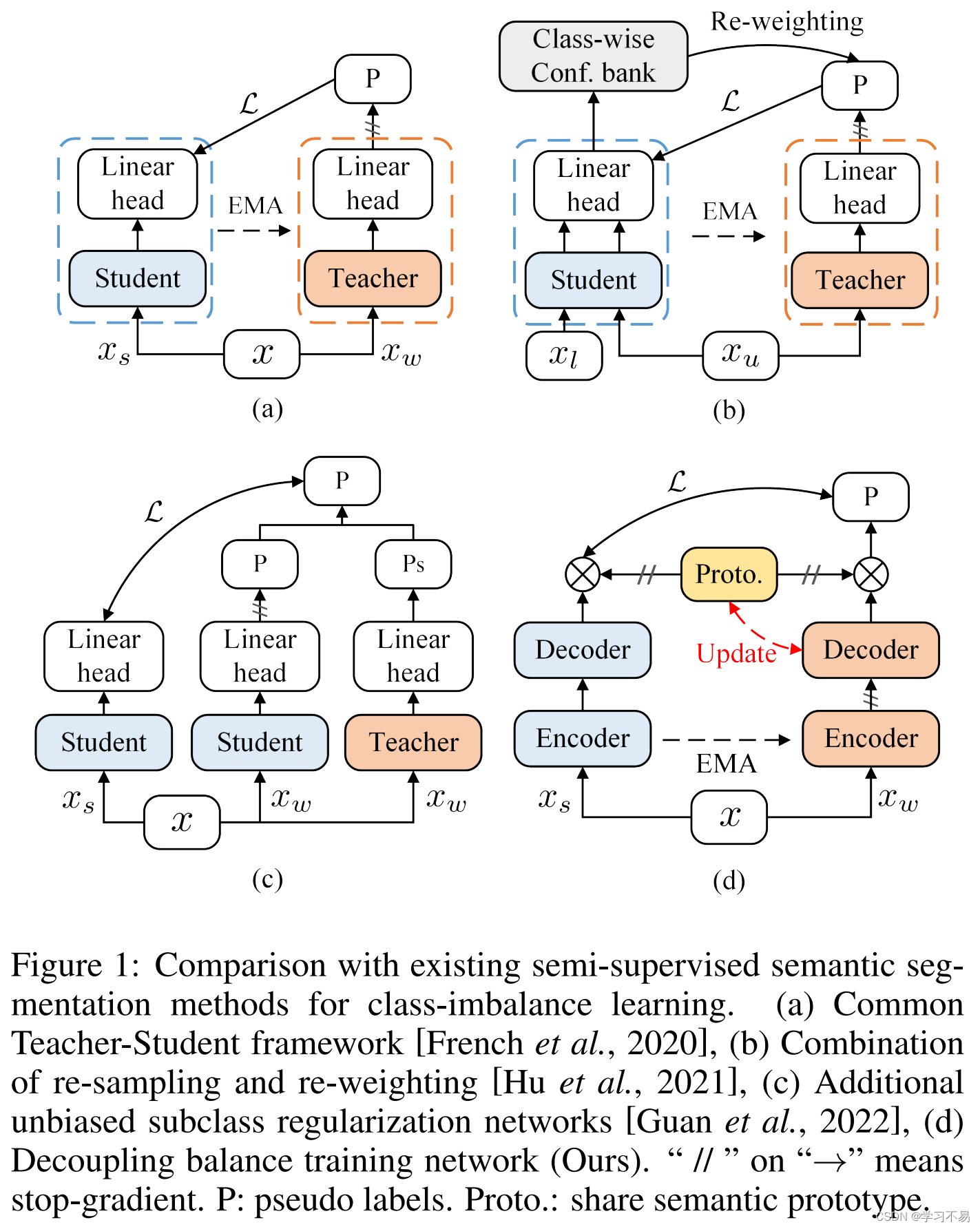
许多半监督分割工作旨在应用一致性正则化 [French et al, 2020;陈等人,2021;张等人,2022]和自我训练[Bachman 等人,2019;陈等人,2020; Fan 等人,2022a] 策略。这些方法通常采用教师-学生范式 [French et al, 2020],并通过教师模型生成的伪标签来监督学生模型,如 图 1(a) 所示。然而,由于模型是使用不平衡数据进行训练的,因此大多数方法受到语义分割的像素分类精度的限制,这导致尾部类别学习的退化。最近,一些工作试图缓解半监督语义分割中的不平衡问题 [1]、[2] 。例如,分布对齐和随机采样 (DARS)[3] 和 UCC [4] 探索了真实分布和伪标记分布之间的不匹配问题,并提出了渐进式数据增强策略和动态数据增强策略。分别是交叉集复制粘贴 (DCSCP)。 AEL [Hu et al, 2021] 通过重新采样和重新加权来解决有偏差的训练问题,如 图 1(b) 所示。它提出了两种基于自适应的数据增强方法和置信库的采样策略。不同的是,USRN 提出了一种具有聚类子类的类平衡子类框架,如 图 1(c) 所示。然而,现有的方法联合学习编码器和解码器,这种学习方式忽略了长尾问题对不同组件的影响。
[1] CVPR2022: Unbiased Subclass Regularization for Semi-Supervised Semantic Segmentation
[2] NeurIPS2021: Semi-Supervised Semantic Segmentation via Adaptive Equalization Learning
[3] ICCV2021: Re-Distributing Biased Pseudo Labels for Semi-Supervised Semantic Segmentation: A Baseline Investigation
[4] CVPR2022: UCC: Uncertainty Guided Cross-Head Co-Training for Semi-Supervised Semantic Segmentation
[5] CVPR2022: CoSSL: Co-Learning of Representation and Classifier for Imbalanced Semi-Supervised Learning
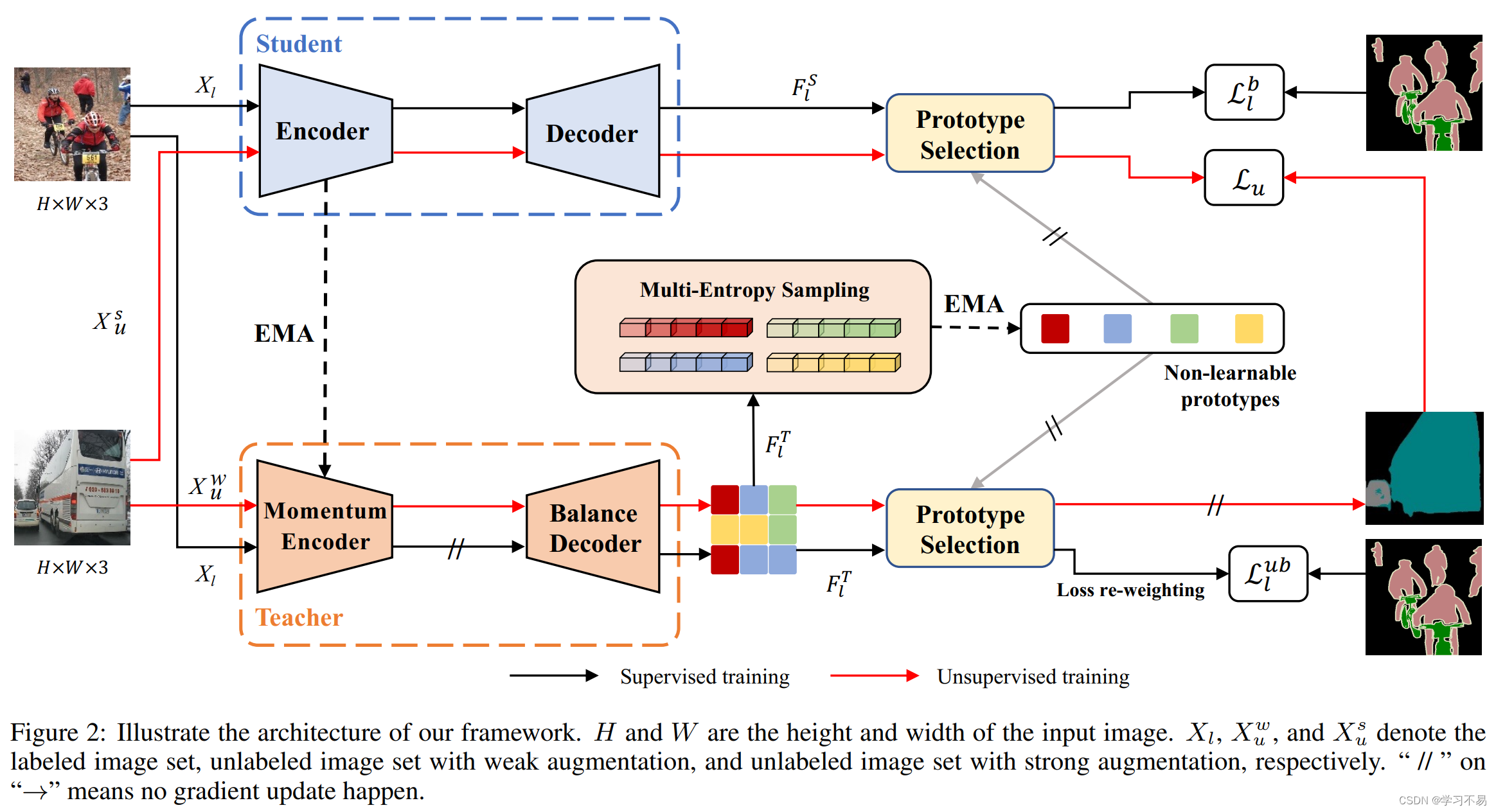
在这项工作中,受到最近成功的不平衡半监督分类算法[5]的启发,我们提出解耦半监督语义分割( D e S 4 DeS^4 DeS4)作为不平衡半监督语义分割框架,如 图 1(d) 所示。在提出的 D e S 4 DeS^4 DeS4 中,我们将编码器和像素级表示(来自解码器)解耦以进行长尾语义分割。具体来说,编码器和分段解码器的训练是解耦的,无需梯度传播,我们的目标是获得鲁棒的编码器和无偏的分段解码器。在师生模式下,我们通过共享分割头连接学生模型和教师模型,以便在两个模型之间交换无偏差信息,这是基于不可学习的原型,而不是仅依赖于伪标签监督。
此外,我们提出了一种多熵采样(MES)策略来非参数地更新无偏原型。将按类别表示分布的熵水平分为几个区域,并对每个熵水平区域进行平衡子采样。所提出的 MES 策略极大地提高了类别表示的多样性,同时保持了平衡性。此外,我们利用采样的类别表示通过指数移动平均线(EMA)更新原型。然后,像素表示通过度量学习找到同一类别的最接近原型进行分类。
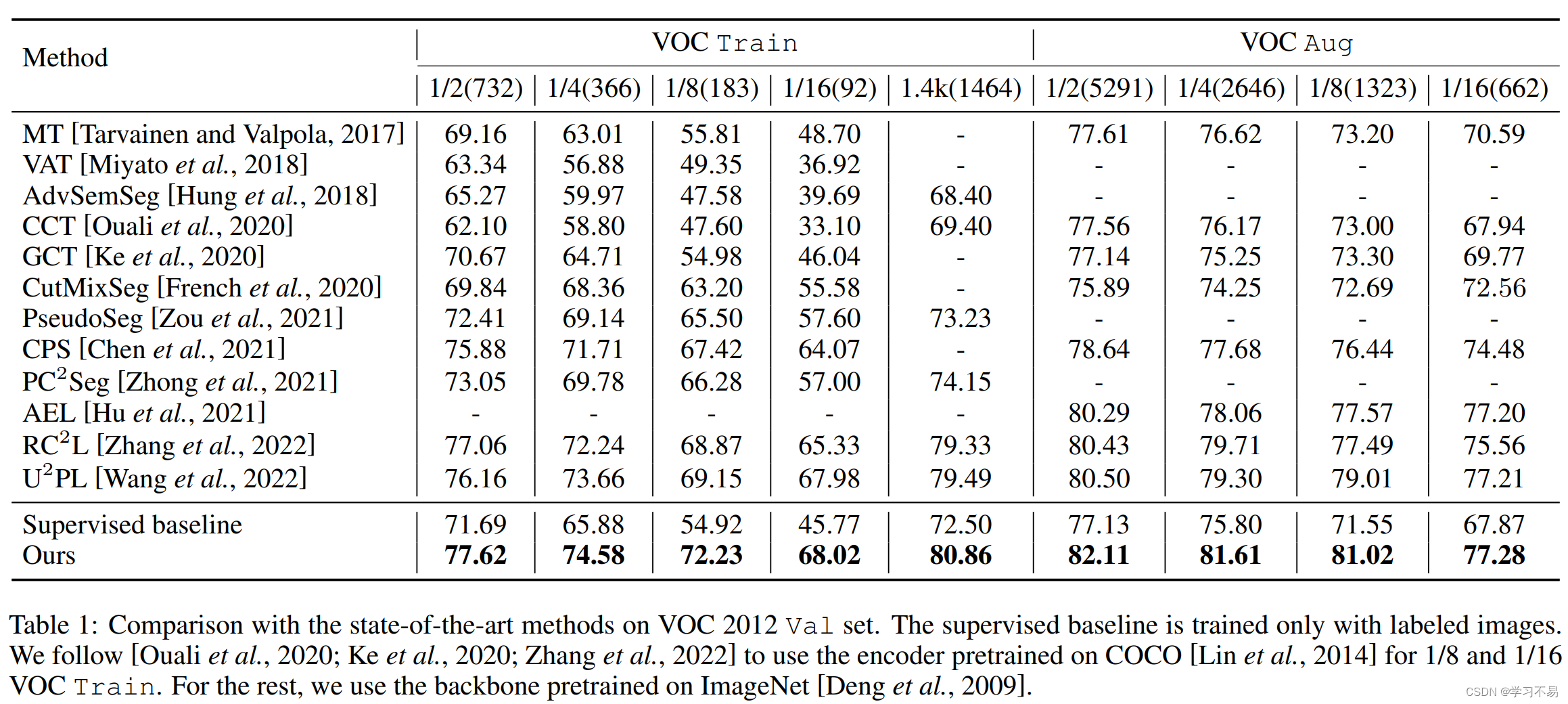
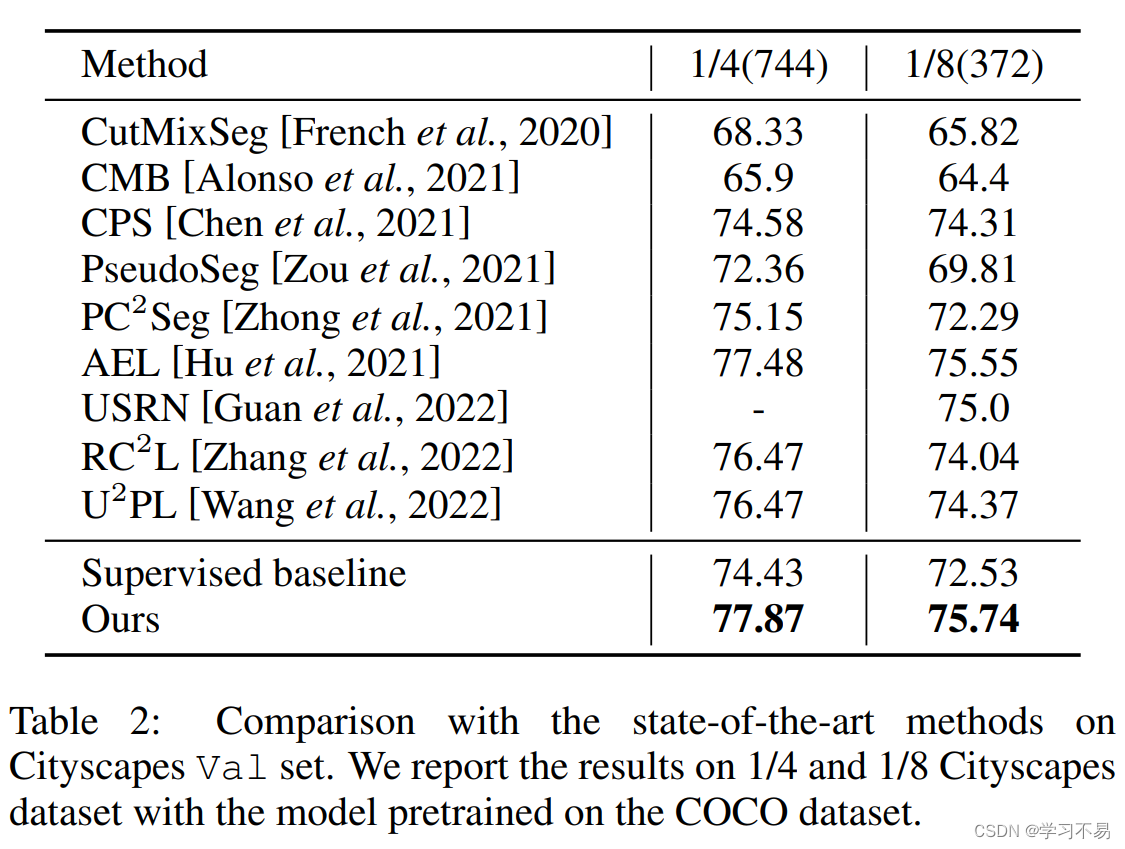
我们在两个广泛使用的数据集上优于其他方法:PASCAL VOC 2012 [Everingham et al, 2015] 和 Cityscapes [Cordts et al, 2016]。例如,我们的方法在 1/2 和 1/4 分区下的 VOC Aug 数据集上实现了 81.61% 和 80.64%,这比之前最先进的方法提高了 2.31% 和 1.63%。综上所述,本文做出以下贡献:
- 我们提出解耦半监督语义分割( D e S 4 DeS^4 DeS4)作为一种不平衡的半监督语义分割框架,其中我们将编码器和解码器的训练分开。
- 我们提出不可学习的原型作为共享且平衡的分割头,更好地链接教师模型和学生模型。同时,提出了一种多熵采样策略,以平衡的方式更新原型。
- 我们在两个公共数据集上始终优于现有最先进的半监督语义分割方法。
2 Related Work
2.1 Semantic Segmentation
全卷积网络 [Long et al, 2015] 以端到端的方式有效地学习密集特征。由于这是一项开创性的工作,因此在FCN的基础上从各个方面提出了一些增强功能,例如:增强感受野 [Chen et al, 2018a],结合多尺度上下文特征 [Chen et al, 2016;赵等人,2017; Ding et al, 2018],并研究注意力操作[Fu et al, 2019;丁等人,2019]。此外,近年来语义分割的显着改进是通过更强大的主干架构实现的,例如基于 CNN 的方法中的 ResNet [He et al, 2016] 和基于 Transformer 的方法中的 ViT [Dosovitskiy et al, 2020]。目前,已经做出了许多努力来探索分割头中 Transformer 的远程依赖关系 [Xie et al, 2021;程等人,2021;郑等人,2021; Ding et al, 2021],显示出显着的结果。
2.2 Semi-supervised Semantic Segmentation
半监督语义分割方法注重将标记图像与未标记图像相结合进行训练,减少了手动标注的耗时。之前的方法通过区分伪标签来研究生成对抗网络(GAN)[Hung et al, 2018]以获取未标记的数据。最近,基于一致性正则化的半监督学习的显着进展推动了几项工作 [1, 2, 3] 和自我训练[Lee,2013; Fan 等人,2022a]。
例如,GCT [4] 强制具有不同初始化但具有相同架构的两个模型之间的一致性。 PseudoSeg [5] 引入了 Grad-CAM 以获得更高质量的伪标签。 CPS [Chen et al, 2021] 提出了双并行模型并执行跨模型监督来训练语义分割网络。
此外,许多作品受益于通过无监督对比学习来学习像素级表示。 PC2Seg [Zhong et al, 2021] 强制执行标签空间一致性正则化和特征对比属性。 U2PL [Wang et al, 2022] 根据像素的可靠性选择像素并排除不可靠的样本。 RC2L [Zhang et al, 2022] 鼓励区域级一致性和对比属性来解决假阴性问题并简化对比学习训练过程。
[1] CVPR2021: Semi-Supervised Semantic Segmentation With Cross Pseudo Supervision
[2] CVPR2022: Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
[3] IJCAI2022: Region-level Contrastive and Consistency Learning for Semi-Supervised Semantic Segmentation
[4] ECCV2020: Guided Collaborative Training for Pixel-Wise Semi-Supervised Learning
[5] ICLR2021: PseudoSeg: Designing Pseudo Labels for Semantic Segmentation
此外,还有很多努力 [1, 2] 一直致力于克服像素类别不平衡问题。 AEL [1] 提出了自适应数据增强方法和采样策略,USRN [2] 训练无偏子类分类器来正则化不平衡的伪标签,并设计基于熵的门模块。 UCC [3] 提出动态跨集复制粘贴(DCSCP)策略来解决错位和类不平衡问题。
[1] NeurIPS2021: Semi-Supervised Semantic Segmentation via Adaptive Equalization Learning
[2] CVPR2022: Unbiased Subclass Regularization for Semi-Supervised Semantic Segmentation
[3] CVPR2022: UCC: Uncertainty Guided Cross-Head Co-Training for Semi-Supervised Semantic Segmentation
在这项工作中,我们首先提出了一种以半监督方式进行语义分割的解耦训练策略。它将编码器和解码器的训练解耦。其次,与 [Guan et al, 2022] 执行 KMeans 聚类并使用原型作为额外的类中心不同,我们为教师模型和学生模型提出了一个不可学习的基于原型的分类器,并且我们还提出了一种新颖的平衡原型更新的抽样策略。
2.3 Class-imbalance Learning
类别不平衡学习是一个被广泛研究的基本问题。许多作品试图通过损失函数重新加权来解决类别不平衡问题。例如,焦点损失 [Lin et al, 2017] 调整每个样本的损失权重以适应训练数据的不同类别标签,从而导致数据集中产生更多噪声。还有一些工作通过随机线性插值[Chawla et al, 2002]、多阶段训练[Yin et al, 2019]等方式获得训练样本数量均衡的重采样数据。此外,SPE [Liu et al, 2020]提出了一种自定进度的集成策略,通过重新采样来有效地平衡数据集。最近的努力表明,将表示和分类器解耦[Kang et al, 2019; Tang et al, 2020] 可能有利于长尾分类。受这些方法的启发,CoSSL [Fan et al, 2022b] 提出了一个用于不平衡半监督分类的共同学习框架。
与 SPE [Liu et al, 2020] 不同,我们对各种类别采用多熵采样,而不是二元分类。同时,CoSSL [Fan et al, 2022b] 仅通过伪标签链接教师模型和学生模型,我们提出了一个共享的不可学习原型作为桥梁,将类别无偏见的信息传输给学生并统一类别嵌入教师模型和学生模型的空间。
3 Method
4 Experiment
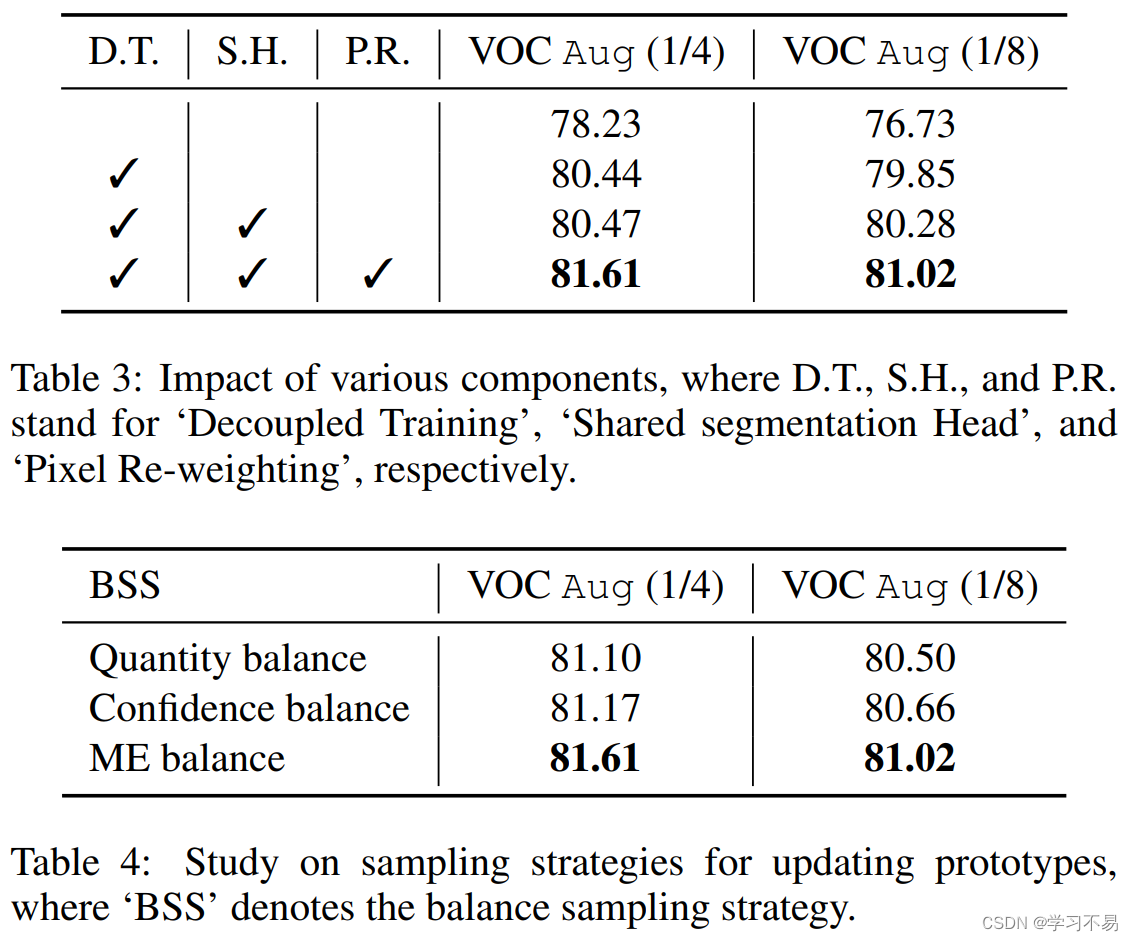
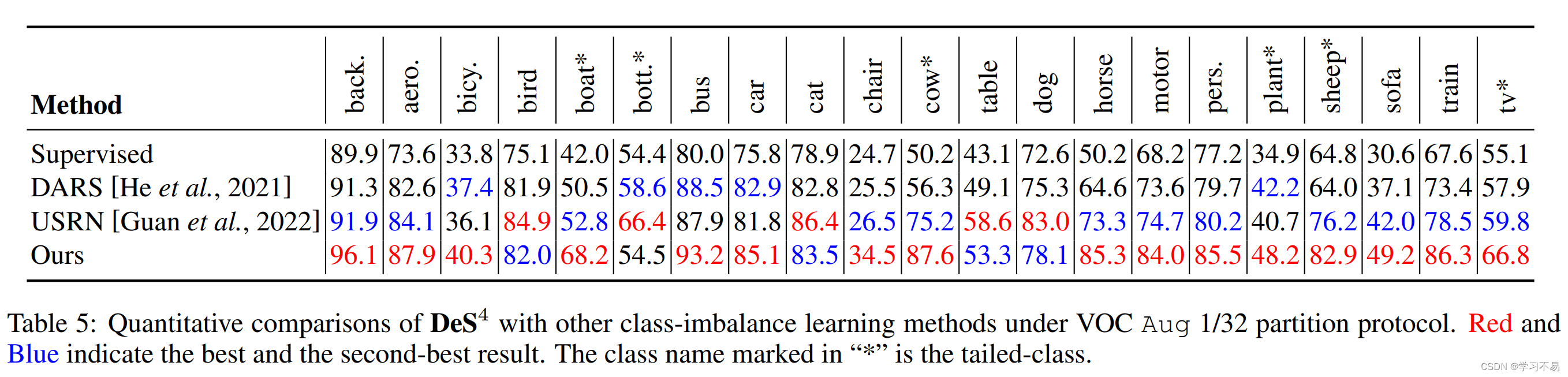
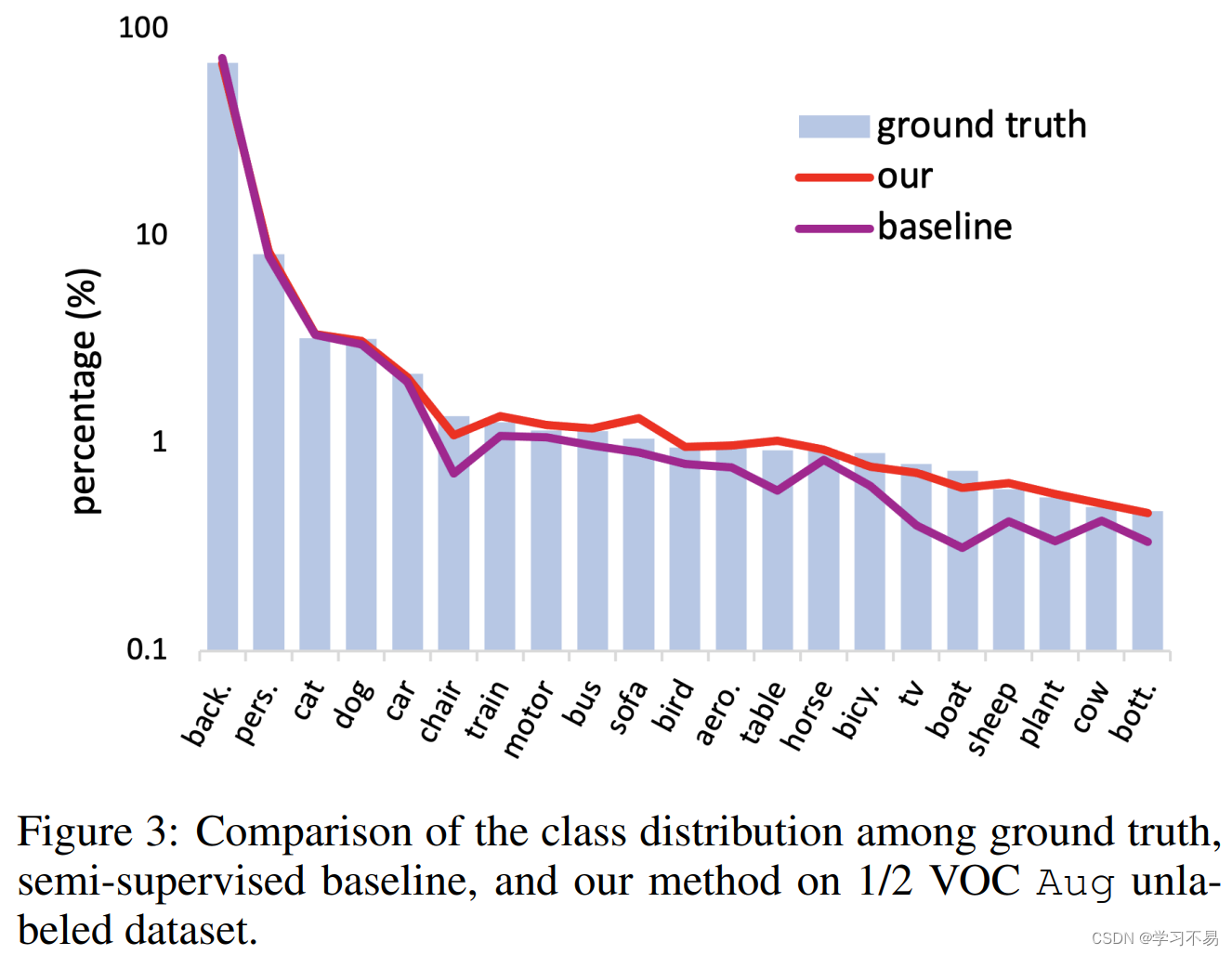

5 Conclusion
我们开发了一个解耦半监督语义分割( D e S 4 DeS^4 DeS4)框架。我们提出解耦编码器和解码器的训练,以实现教师模型的平衡分割解码器。然后,我们提出了一种基于共享的不可学习原型的分类器来连接和统一教师模型和学生模型的类别嵌入空间。此外,提出了多熵采样策略来非参数更新共享原型,以实现教师模型的类无偏分类器。实验结果表明,我们的方法比以前最先进的方法取得了更好的性能。















 1821
1821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









