







一、通俗易懂介绍:什么是Neural ODE?
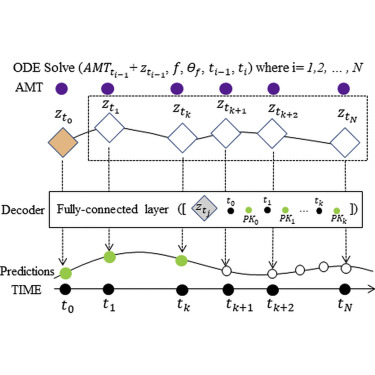
1.1 核心思想
Neural ODE(神经常微分方程)由陈天琦等人在2018年提出,将神经网络视为连续动态系统,用常微分方程(ODE)替代传统离散网络层。
- 传统神经网络:如ResNet,可看作离散跳跃过程:
(残差连接)
- Neural ODE:将层数“连续化”,通过ODE描述状态变化:
输入→输出:通过ODE求解器从初始时刻t0积分到终止时刻t1。
1.2 举个栗子 🌰
假设要预测患者病情发展:
- 传统RNN:每小时记录一次数据,用离散时间步建模。
- Neural ODE:将病情变化建模为连续过程,根据任意时刻的微分方程 dtdh=f(h,t) 预测状态。
二、应用场景与优缺点
2.1 应用场景
| 领域 | 任务 | 优势体现 |
|---|---|---|
| 时间序列预测 | 医疗监测、股票价格预测 | 任意时间点插值,无需固定时间步 |
| 生成模型 | 连续归一化流(CNF)生成图像/文本 | 高效密度估计,可逆变换 |
| 物理模拟 | 粒子运动轨迹预测 | 符合物理守恒定律的连续动力学 |
| 强化学习 | 连续控制策略优化 | 平滑策略更新,避免离散动作抖动 |
2.2 优缺点对比
| 优点 | 缺点 |
|---|---|
| ✅ 内存高效:反向传播不需存储中间状态 | ❌ 训练速度慢:ODE求解器迭代耗时 |
| ✅ 连续深度:自适应计算复杂度(精度/速度) | ❌ 数值稳定性:依赖ODE求解器精度 |
| ✅ 物理可解释:自然建模连续动力学系统 | ❌ 调试困难:梯度可能爆炸或消失 |
三、模型结构详解
3.1 整体架构
输入数据 → ODE函数(神经网络) → ODE求解器 → 输出预测
3.1.1 ODE函数
- 由神经网络 fθ 定义,输入为状态 h(t) 和时间 t,输出为状态导数 dh/dt。
- 示例结构:
ODEFunc( nn.Linear(dim, hidden_dim), nn.Tanh(), nn.Linear(hidden_dim, dim) )
3.1.2 ODE求解器
- 常用方法:Runge-Kutta(如
dopri5)、Euler法。 - 自适应步长:根据误差估计调整积分步长。
3.1.3 输入输出
- 输入:初始状态 h0(如时间序列的初始观测值)。
- 输出:在目标时刻 t1 的状态 h(t1)。
四、数学原理
4.1 前向传播
状态变化由ODE描述:
解由ODE求解器计算:
4.2 反向传播:伴随方法(Adjoint Method)
为高效计算梯度,引入伴随状态 :
- 前向积分:计算 h(t1)。
- 反向积分:从 t1 到 t0 解伴随方程:
- 梯度计算:
优势:内存复杂度为 O(1)(传统反向传播为 O(N),N 为步数)。
五、代表性变体及改进
5.1 FFJORD(Free-Form Continuous Dynamics)
- 改进点:结合连续归一化流(CNF),实现高维数据高效生成。
- 公式:
概率密度变化由连续性方程描述:
5.2 HNN(Hamiltonian Neural Networks)
- 改进点:引入哈密顿力学,保证能量守恒。
- 动力学方程:
其中 H(q,p) 由神经网络参数化。
5.3 Neural SDE(神随机微分方程)
- 改进点:在ODE中引入随机噪声项,建模不确定性。
- 公式:
Wt 为维纳过程(布朗运动)。
六、PyTorch代码示例
6.1 基础Neural ODE实现
import torch
import torch.nn as nn
from torchdiffeq import odeint
# 定义ODE函数(神经网络)
class ODEFunc(nn.Module):
def __init__(self, dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, 64),
nn.Tanh(),
nn.Linear(64, dim)
)
# 初始化权重
for m in self.net.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight, mean=0, std=0.1)
nn.init.constant_(m.bias, 0)
def forward(self, t, h):
# 输入h: [batch_size, dim]
# 输出dh/dt: [batch_size, dim]
return self.net(h)
# 创建模型
dim = 2
ode_func = ODEFunc(dim)
# 初始状态
h0 = torch.randn(32, dim) # batch_size=32
# 时间点
t = torch.tensor([0., 1.]) # 从t=0积分到t=1
# 前向传播(使用dopri5求解器)
h1 = odeint(ode_func, h0, t, method='dopri5')[1]
print("输出形状:", h1.shape) # [32, 2]
# 定义损失函数和优化器
target = torch.randn(32, dim)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(ode_func.parameters(), lr=0.01)
# 训练循环
for epoch in range(100):
optimizer.zero_grad()
h1_pred = odeint(ode_func, h0, t, method='dopri5')[1]
loss = criterion(h1_pred, target)
loss.backward()
optimizer.step()
print(f"Epoch {epoch}, Loss: {loss.item():.4f}") 6.2 使用FFJORD生成数据
from ffjord import FFJORD
# 创建FFJORD模型
model = FFJORD(input_dim=2, hidden_dims=[64, 64], num_blocks=5)
# 输入噪声(标准正态分布)
z = torch.randn(100, 2)
# 生成样本
x, log_prob = model(z, reverse=True)
# 计算损失(最大似然)
loss = -log_prob.mean()
loss.backward() 七、总结
Neural ODE通过连续动力学系统重新定义了深度学习模型,在内存效率、物理建模等方面具有革命性优势。其变体如FFJORD、HNN等进一步拓展了在生成模型和科学计算中的应用。未来方向可能包括:
- 快速求解器:开发专用硬件加速ODE积分。
- 不确定性量化:结合贝叶斯框架与SDE。
- 跨学科应用:如气候模拟、量子化学计算。

















 5112
5112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









