







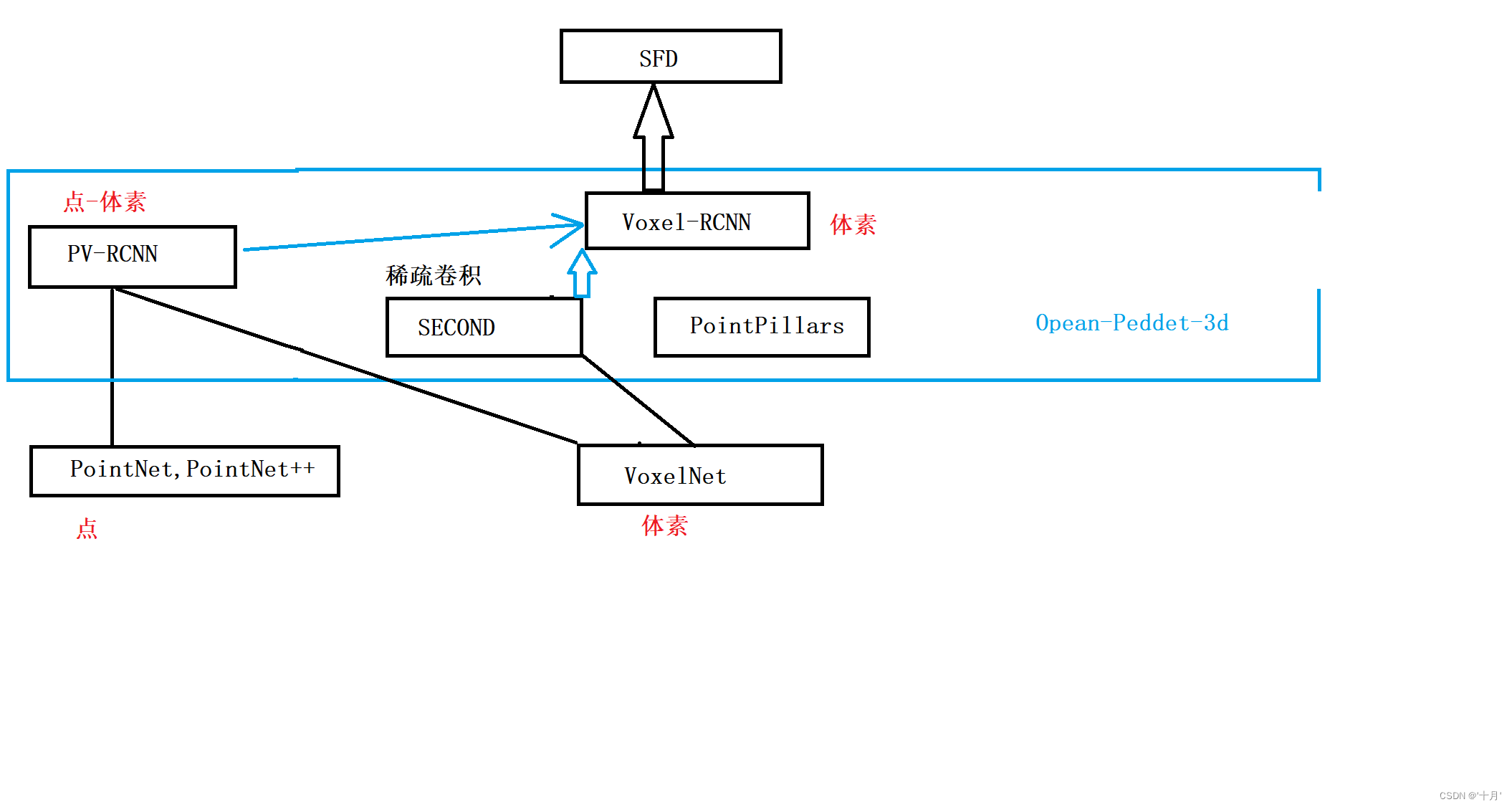
 SECOND模型是VoxelNet的改进版,通过引入稀疏卷积减少计算量,提高3D目标检测速度。此外,模型解决了VoxelNet中反向预测框的损失函数问题,采用FocalLoss平衡正负样本,以及方向分类器优化方向估计。文章详细阐述了稀疏卷积的工作原理和损失函数的改进策略。
SECOND模型是VoxelNet的改进版,通过引入稀疏卷积减少计算量,提高3D目标检测速度。此外,模型解决了VoxelNet中反向预测框的损失函数问题,采用FocalLoss平衡正负样本,以及方向分类器优化方向估计。文章详细阐述了稀疏卷积的工作原理和损失函数的改进策略。
SECOND模型
参考链接【3D目标检测】SECOND算法解析 - 知乎 (zhihu.com)
论文地址:Sensors | Free Full-Text | SECOND: Sparsely Embedded Convolutional Detection (mdpi.com)
代码链接:traveller59/second.pytorch: SECOND for KITTI/NuScenes object detection (github.com)
模型解决问题
模型来自于VoexlNet。
论文提出的主要动机为:
(1)考虑到VoxelNet论文在运算过程中运算量较大,且速度不佳。作者引入了稀疏3D卷积去代替VoxelNet中的3D卷积层,提高了检测速度和内存使用;
(2)VoxelNet论文有个比较大的缺点就是在训练过程中,与真实的3D检测框相反方向的预测检测框会有**较大的损失函数,**从而造成训练过程不好收敛。
其他的创新点:
(1)比如数据增强这块,作者使用了数据库采样的操作;
(2)对于正负样本数量的极度不平衡问题,作者借鉴了RetinaNet中采用的Focal Loss。
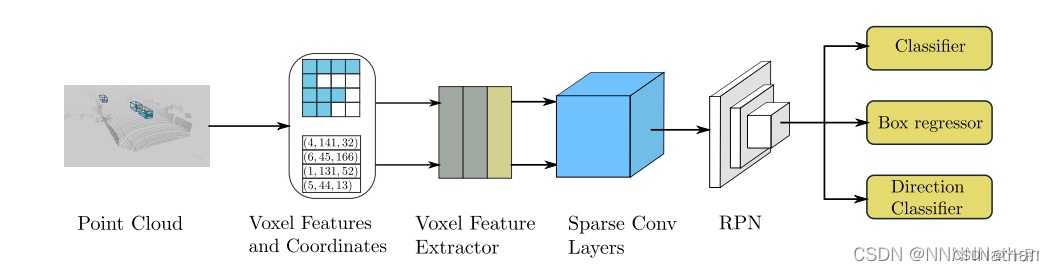
网络结构
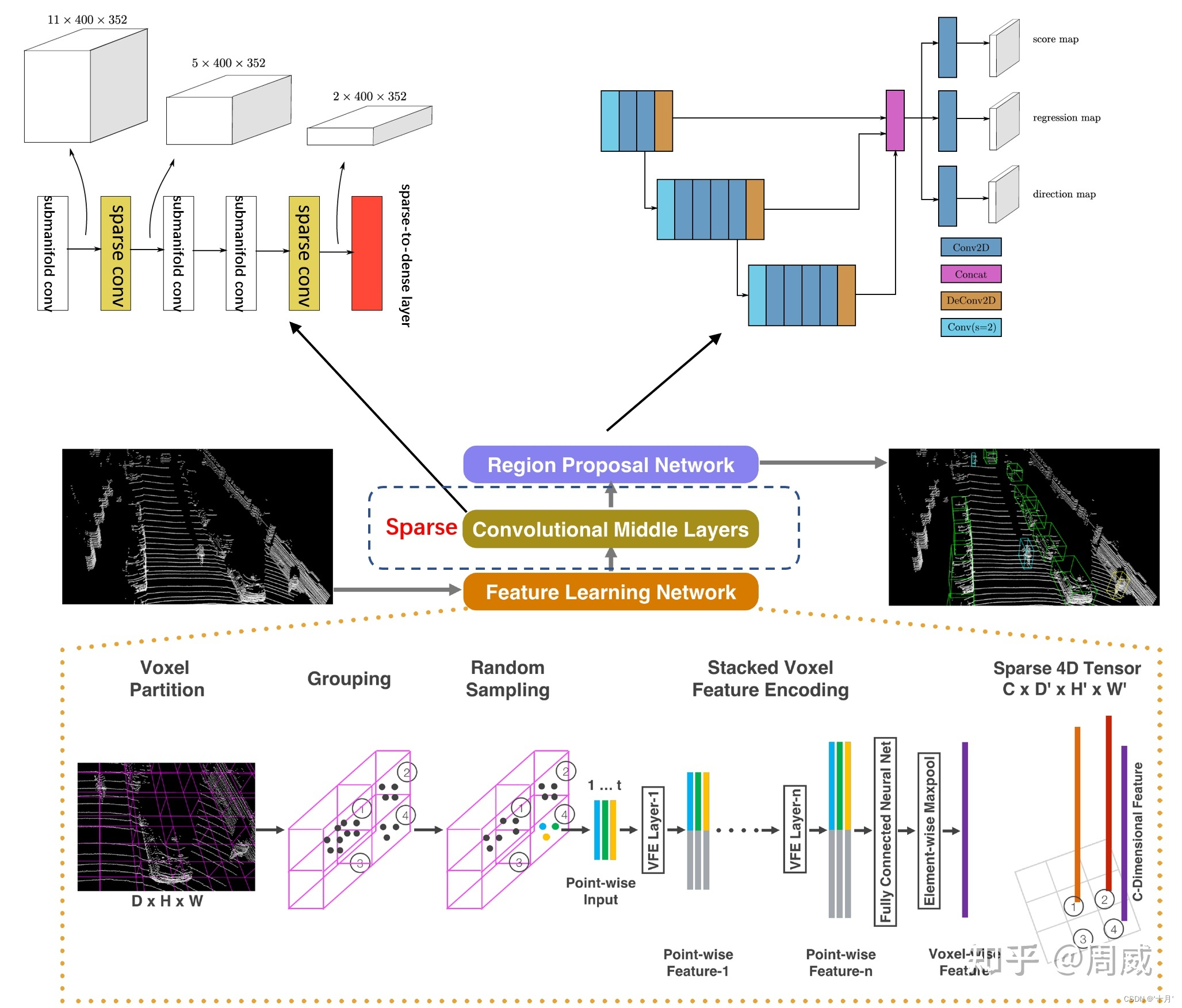
模型来自于VoxleNet,主要对于中间卷积层以及最后的RPN层进行改进。
原始VoxelNet结构:

SECOND结构:
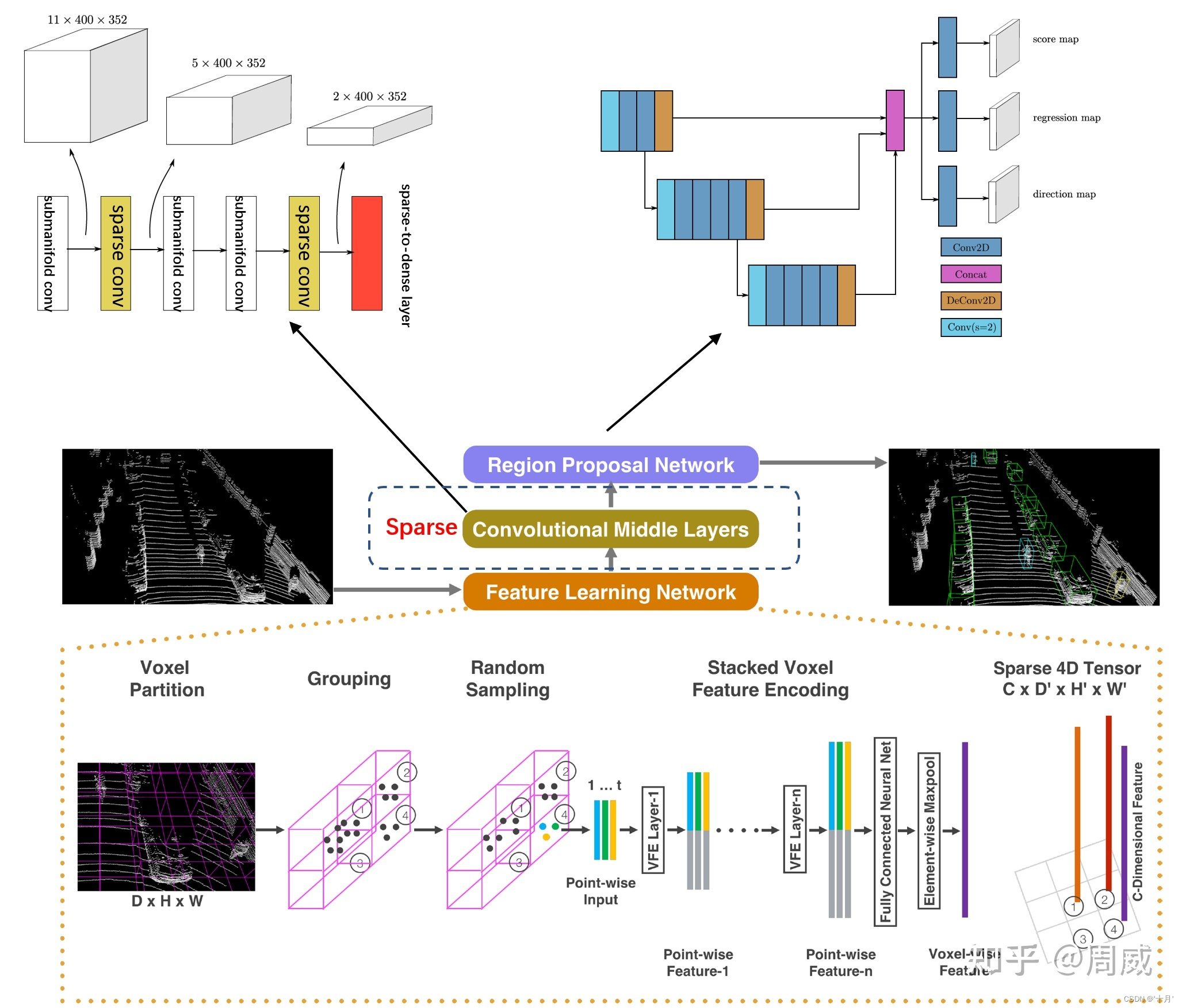
原论文模型图:
3D稀疏卷积特征提取
提出原因
卷积神经网络已经被证明对于二维图像信号处理是非常有效的。然而,对于三维点云信号,额外的维数 z 显著增加了计算量。
另一方面,与普通图像不同的是,大多数三维点云的体素是空的,这使得三维体素中的点云数据通常是稀疏信号。
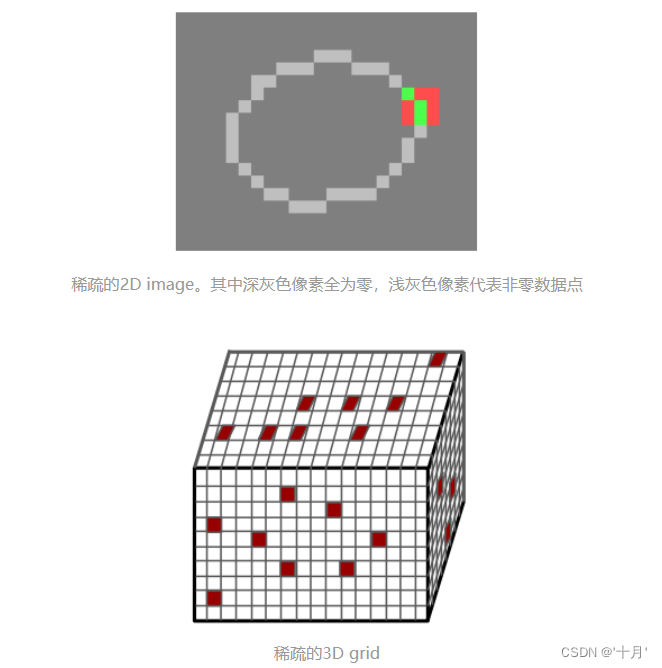
我们是否只能有效地计算稀疏数据的卷积,而不是扫描所有的图像像素或空间体素?否则这些空白区域带来的计算量太多余了。这就是 sparse convolution 提出的motivation。
模型中的使用
-
构建 Input Hash Table 和 Output Hash Table
模型输入:离散图像数据
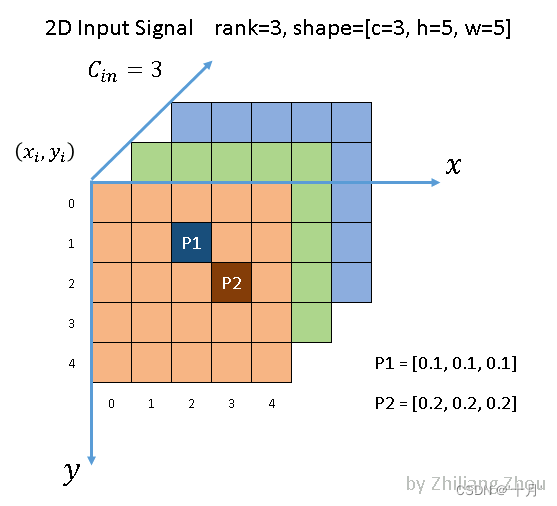
模型输出结构:
一种是 regular output definition,就像普通的卷积一样,只要kernel 覆盖一个 active input site&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6291
6291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









