







Transformer在文本领域取得相当大的成功,那么如果将transformer模型以及注意力机制应用到图像领域,会不会也取得非常好的效果呢,那么transformer又将如何应用在图像领域呢?
在图像处理中,自注意力机制可以用来捕捉图像中不同区域之间的关系,这对于许多计算机视觉任务非常有用,比如图像分类、物体检测、语义分割等。下面我将解释自注意力机制在图像处理中的应用方式。
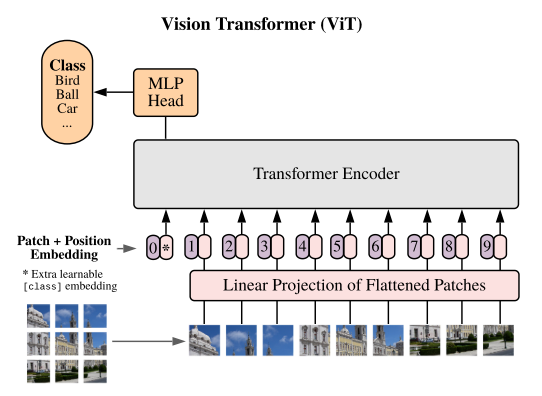
图像到序列的转换
首先,要将图像输入到transformer模型中,需要将图像转换成一系列向量。步骤如下:
- 图像分割:将图像划分为多个固定大小的块或区域,每个区域通常称为一个patch。
- 特征提取:对每个patch使用卷积神经网络(CNN)或其他方法提取特征,这些特征向量通常具有一定的维度,例如512维。
- 序列化:将提取的特征向量按照顺序排列形成一个序列。每个向量代表图像的一个局部区域。
自注意力机制的应用
将图像转换为特征向量序列之后,就可以利用自注意力机制来捕捉这些向量之间的相互关系。具体工作流程如下:
- 生成查询、键和值向量
- 对于每个特征向量,使用线性变换生成对应的查询(Query)、键向量(Key)和值向量(Value)。
- 这些向量的生成通常是通过矩阵乘法完成的,其中特征向量与一组权重矩阵相乘。
- 计算注意力分数
- 计算每个查询向量与所有键向量之间的点积相似度。
- 使用缩放因子来避免梯度消失问题,通常通过除以键向量的根号下的维度大小。
- 应用softmax函数将相似度转换为概率分布,表示各个键向量与当前查询向量的相关性。
- 加权平均
- 根据注意力分数对相应的值向量进行加权平均,得到最终的注意力输出。
- 注意力分数较高的值向量对最终输出的贡献更大。
- 多头注意力
- 为了捕获图像中不同尺度和类型的关系,通常使用多头注意力机制。
- 每个注意力头独立计算注意力权重,并将他们组合起来形成最终的输出。
应用场景
包括但不限于:
- 图像分类:通过对图像中的不同区域进行注意力加权,模型可以更好地关注那些对分类最有帮助的区域。
- 物体检测:自注意力可以帮助模型聚焦于潜在的物体边界框,并有助于区分背景和前景
- 语义分割:注意力机制可以突出显示图像中属于同一类别的像素,从而提高分割精度。
- 图像生成:在生成模型中,自注意力可以帮助模型学习生成图像中各个部分之间的关系。
















 5706
5706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











