







一. 什么是病理图像?
病理图像的基本特征:
- WSI即全载玻片图像,是将不同染色的组织切片信息从玻璃到数字格式的转换;
- 图像尺寸大,通常在百兆到数G之间;
- 图像呈现丰富的色彩信息,为金字塔结构,在不同的放大倍数下(多层分辨率)检索可提供多种比例的信息,比如TCGA最常见的40x,20x;
- 通常存储为.svs,.tiff,.ndpi, .mrxs格式-可通过本地软件qupath,ImageScope,Python包openslide进行可视化;
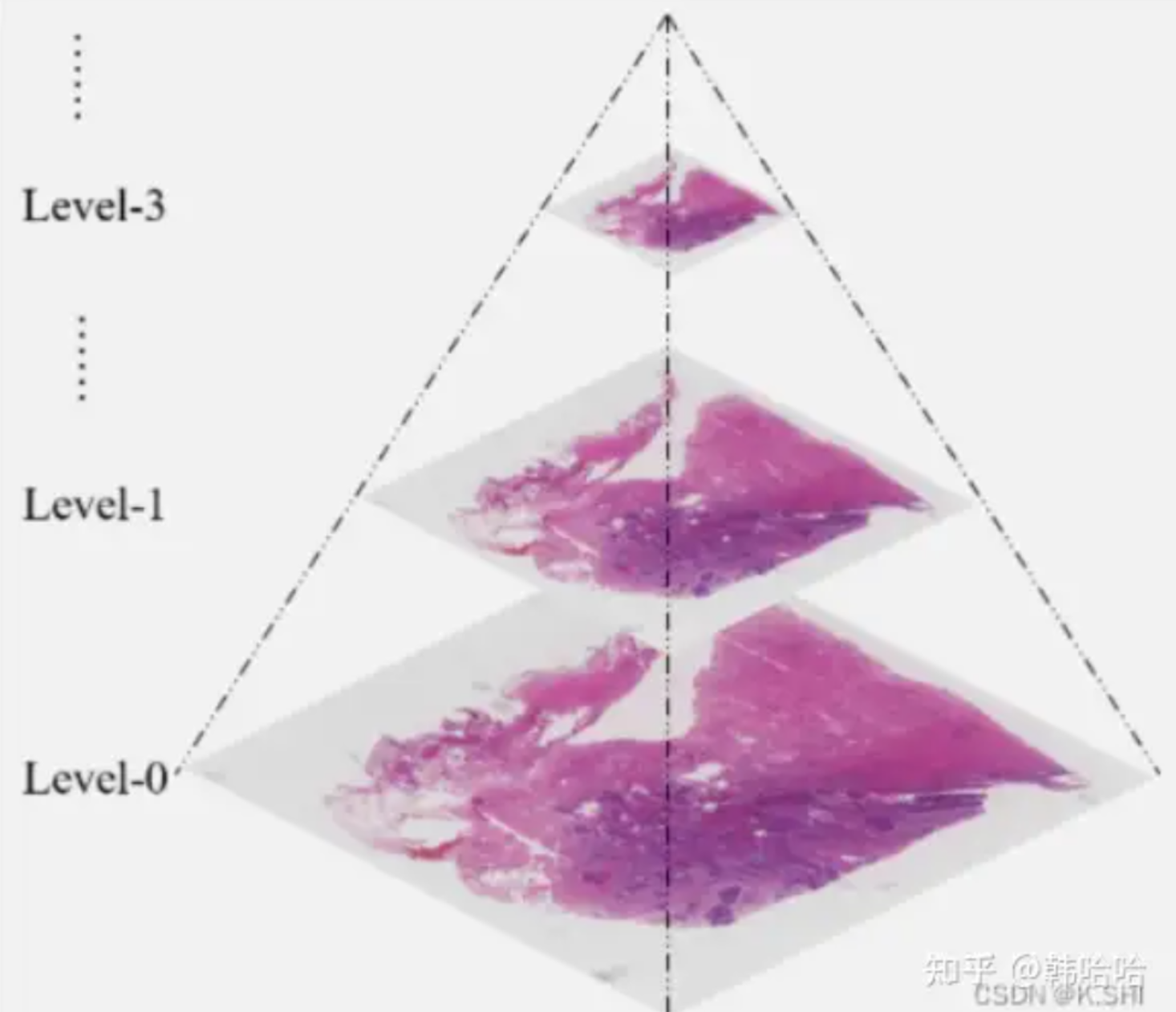
如何理解病理图像的金字塔结构?
- Dimensions: 表示WSI在最高层次(level 0)的原始尺寸,如 (14000, 22312) 意味着图像的宽度是14000像素,高度是22312像素。level 0是指金字塔的顶层,代表最高分辨率的图像,相当于显微镜下的最高放大倍数。
- Level count: 表示WSI的金字塔结构中的层数。若level count是3,意味着有三个不同的分辨率级别:level 0(最高分辨率)、level 1(中等分辨率)、level 2(最低分辨率)。随着级别的增加(即level 1、level 2等),图像的分辨率会降低,图像尺寸会变小,相当于在显微镜下观察时逐渐降低放大倍数。
- Level dimensions: 这是一个元组列表,显示了每个级别的图像尺寸/分辨率。在这个例子中,level 0的尺寸是(14000, 22312),level 1的尺寸是(3500, 5578),level 2的尺寸是(1750, 2789)。
- Level downsamples: 每个级别的下采样因子。在这个例子中,level 0的下采样因子是1.0(没有缩小),level 1是4.0,level 2是8.0。下采样因子表示每个级别相对于第一个级别的缩放比例1/(2的n次方)。例如,从level 0到level 1,图像尺寸缩小了4倍,代表level 1的1个像素点指代level 0每四个像素点的信息。
- Magnification: 这表示显微镜下观察到的放大倍数。如,level 0的放大倍数是20x。这意味着在最高分辨率级别,每个像素代表实际组织样本中的物理尺寸被放大了20倍。而对于level1, 放大倍数为20x / 4= 5x,即level 1代表实际组织样本中的物理尺寸被放大了5倍。
二、如何预处理病理切片并提取特征
方法一:采用clam(GitHub - mahmoodlab/CLAM: Open source tools for computational pathology - Nature BME)提取特征
下载git上clam的代码,解压后下述操作在该目录中进行。
Step1:查看病理切片属性
# 在clam目录中创建input_dataset目录,存放病理切片(.svs等)
data_dir ="./input_dataset/"
dir_lst = os.listdir(data_dir)
dir_lst = [i for i in dir_lst if i.endswith("svs")]
print(len(dir_lst))
df_wsi = pd.DataFrame(columns = ["Slide name", "Dimensions","Level count", "Level dimensions","Level downsamples","Level_0_magnification"])
for file in dir_lst:
svs_file_path = data_dir + file
slide = openslide.OpenSlide(svs_file_path)
downsample_lst = [int(i) for i in list(slide.level_downsamples)]
app_mag = slide.properties.get('aperio.AppMag', 40) # 如果不存在,返回 'Unknown'
# print(app_mag,svs_file_path)
info = [file,slide.dimensions,slide.level_count,slide.level_dimensions ,downsample_lst,int(app_mag) ]
df_wsi.loc[len(df_wsi)] = info
df_wsi.to_csv("./WSI_stat.csv",index=False)
df_wsi.head(2)

该切片确实存在四个不同的层级(Level count为4),这通常意味着图像数据被分割成了不同分辨率的层,以便于在不同放大倍数下查看。Level_0_magnification为40,代表最大放大倍数,此时分辨率为(128656,88294)。Level downsamples 列显示的[1, 4, 16, 32]表示每个层级相对于最高分辨率层(Level 0)的下采样倍数,分别代表存在放大40倍,10倍,2.5倍,1.25倍视角的图。
Step2:采用病理切片提取
python create_patches_fp.py --source input_dataset/ --save_dir Split_Image --patch_level 1 --patch_size 256 --seg --patch --stitch --preset tcga.csv
# --patch_level 1 指在level1上切割切片,即在放大倍数为10的层面上分割WSI。若取0,则代表在放大倍数为40的视野上分割WSI
# --patch_size 256 指将wsi切割成256*256大小的patch
Step3: 在patch上提取特征
CUDA_VISIBLE_DEVICES=0,1 python extract_features_fp.py --data_h5_dir Split_Image/ --data_slide_dir input_dataset/ --csv_path Split_Image/process_list_autogen.csv --feat_dir Extracted_feature/ --batch_size 256 --slide_ext .svs
方法二:基于Openslide分割图像+ResNet50提取特征
Step1:Openslide分割图像
此代码仅将WSI 分割为patch
python WSI2patch.py --inputdir input_dataset_40x/Class1 --outputdir Split_Image_40x --level 1 --random_seed 39 --maxpatches 100 --imsize 1024
WSI2patch.py 具体的代码为:
import os
import numpy
import pickle
import argparse
from openslide import OpenSlide
from skimage.io import imsave
from tqdm import tqdm
from skimage.exposure import is_low_contrast
import itertools
def get_tissue(image, blacktol=0, whitetol=230):
"""
Given an image and a tolerance on black and white pixels,
returns the corresponding tissue mask segmentation, i.e. true pixels
for the tissue, false pixels for the background.
Arguments:
- image: numpy ndarray, rgb image.
- blacktol: float or int, tolerance value for black pixels.
- whitetol: float or int, tolerance value for white pixels.
Returns:
- binarymask: true pixels are tissue, false are background.
"""
binarymask = numpy.ones_like(image[:, :, 0], bool)
for color in range(3):
# for all color channel, find extreme values corresponding to black or white pixels
binarymask = numpy.logical_and(binarymask, image[:, :, color] < whitetol)
binarymask = numpy.logical_and(binarymask, image[:, :, color] > blacktol)
return binarymask
def randomized_regular_seed(shape, width, randomizer):
maxi = width * int(shape[0] / width)
maxj = width * int(shape[1] / width)
col = numpy.arange(start=0, stop=maxj, step=width, dtype=int)
line = numpy.arange(start=0, stop=maxi, step=width, dtype=int)
randomizer.shuffle(col)
randomizer.shuffle(line)
for p in itertools.product(line, col):
yield p
def randomized_patches(slide, level, patchsize, randomizer, n_max):
counter = 0
shape = slide.level_dimensions[level]
for i, j in randomized_regular_seed(shape, patchsize, randomizer):
# check number of images already yielded
if counter >= n_max:
break
# get the image
x = j * (2 ** level)
y = i * (2 ** level)
image = numpy.array(slide.read_region((x, y), level, (patchsize, patchsize)))[:, :, 0:3]
# check whether image is yieldable
if (not is_low_contrast(image)) and (get_tissue(image).sum() > 0.5 * patchsize * patchsize):
counter += 1
yield x, y, level, image
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--inputdir", type=str, help="directory where to put the WSIs.")
parser.add_argument("--outputdir", type=str, help="directory where to put the patches.")
parser.add_argument("--level", type=int, default=0, help="resolution pyramid level to extract patches.")
parser.add_argument("--random_seed", type=int, default=39,
help="random seed used for randomization processes.")
parser.add_argument("--maxpatches", type=int, default=20,
help="maximum number of patches to extract from a slide.")
parser.add_argument("--imsize", type=int, default=512, help="size of the side of an image (in pixels)")
args = parser.parse_args()
# then create data directories and put patches inside
if not os.path.exists(args.outputdir):
os.makedirs(args.outputdir)
# randomizer
randomizer = numpy.random.RandomState(seed=args.random_seed)
print("Generate patches.")
for slidename in tqdm(os.listdir(args.inputdir)):
slidepath = os.path.join(args.inputdir, slidename)
slide = OpenSlide(slidepath)
for x, y, level, image in randomized_patches(slide, args.level, args.imsize, randomizer, args.maxpatches):
outpath = os.path.join(args.outputdir, slidename + '_' + str(x) + '_' + str(y) + '_' + str(level) + '.png')
imsave(outpath, image)
切割结果如下:

Step2:ResNet50提取特征
若不需要对模型进行微调,直接根据预训练的模型提取特征,代码如下:
此处参考:https://blog.csdn.net/weixin_43409127/article/details/132678957?spm=1001.2014.3001.5506
import torch
import torch.nn as nn
import os
from torchvision import models, transforms
from torch.autograd import Variable
import numpy as np
from PIL import Image
import torchvision.models as models
import pandas as pd
file_path='./images/'
save_path = ''
transform1 = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor()])
names = os.listdir(file_path)
resnet50 = models.resnet50(pretrained=True)
feature_extractor = torch.nn.Sequential(*list(resnet50.children())[:-1]) #去掉最后的fc层
for name in names:
pic=file_path+name
img = Image.open(pic)
img1 = transform1(img)
x = Variable(torch.unsqueeze(img1, dim=0).float(), requires_grad=False)
y = feature_extractor(x).squeeze().cpu() #去掉多余的一维
torch.save(y,save_path+name[:-4]+".pth")


















 1653
1653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











