







MIND THE GAP: Domain Gap Control for Single Shot Domain Adaptation for Generative Adversarial Networks
公众号:EDPJ
目录
0. 摘要
我们提出了一种用于单样本(one-shot)域自适应的新方法。该方法的输入是经过训练的 GAN,它可以在域 A 中生成图像,并从域 B 中生成单个参考图像 I_B。所提出的算法可以将经过训练的 GAN 的任何输出从域 A 转换到域 B。我们的方法与当前最先进的技术相比有两个主要优点:首先,我们的解决方案实现了更高的视觉质量,例如,显着减少过度拟合。其次,我们的解决方案允许更多的自由度来控制域间隙,即图像 I_B 的哪些方面用于定义域 B。从技术上讲,我们通过将预训练的 StyleGAN 生成器构建为 GAN 以及用于表示域差距的预训练 CLIP 模型来实现新方法。我们提出了几个新的正则化器来控制域间隙,以优化预训练的 StyleGAN 生成器的权重,使其在域 B 而不是域 A 中输出图像。正则化器防止优化采用单个参考图像的太多属性。我们的结果显示了对现有技术的显着视觉改进以及突出改进控制的多个应用。
1. 简介
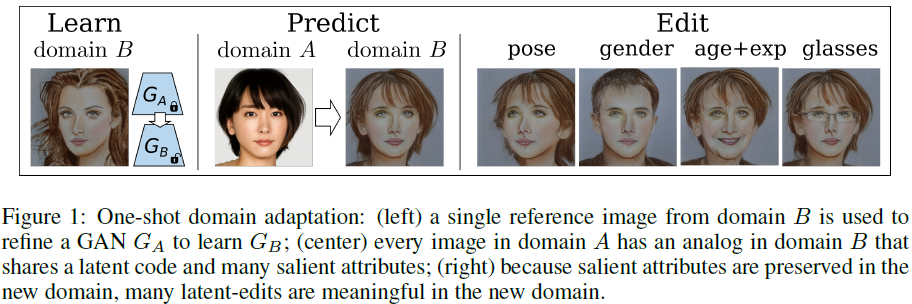
我们提出了一种基于单个目标图像的域自适应新方法。如图 1 所示,给定域 A 的训练好的 GAN 和来自域 B 的单个图像 I_B,我们的方法学习为域 A 中的任何图像在域 B 中找到对应的图像。
我们利用多个现有组件,包括两个出色的预训练网络:
- 首先,我们使用 StyleGAN2 作为预训练 GAN。
- 其次,我们使用预训练的图像 embedding 网络 CLIP, 把图像编码为向量。
- 第三,我们使用 StyleGAN-NADA,它建立在 StyleCLIP 的基础上,将域间隙(或域迁移)编码为 CLIP embedding 空间中的向量。
- 第四,我们利用 II2S 作为 GAN embedding 方法将图像 I_B 转移到域 A 中以获得更好的域间隙估计。
尽管 StyleGAN-NADA 的视觉质量在用作单一图像域自适应方法时已很好,但我们发现了多个可以改进的技术问题,以实现视觉质量的大幅提升。
- 首先,也是最重要的,StyleGAN-NADA 是为 zero-shot 域自适应而设计的,并没有很好的解决方案来基于单个示例图像对域间隙进行建模。他们的实现将域间隙建模为从域 A 中的平均图像到 CLIP embedding 空间中的给定图像 I_B 的向量。然而,这在实践中会导致过拟合,并且迁移结果会丢失输入图像的属性,因此来自域 A 的输入图像会映射到与域 B 中的 I_B 过于相似的图像。我们找到了解决此问题的更好方法。事实上,域间隙应该被建模为从图像 I_B 到域 A 中的类似物的向量,以便域 A 中的图像与参考图像共享显着的域内属性。因此,我们需要解决反向 B 到 A 域迁移问题,我们建议使用最先进的 GAN embedding 方法 II2S 来解决该问题。一个关键的见解是,我们可以使用 II2S GAN 逆映射方法的高度正则化版本来解决将任何相关图像(从域 B)转移到域 A 的逆向问题,这有助于比以前的工作更好地表征语义域差距。进一步的扩展使我们能够微调域间隙的建模,以明确地建模输入图像的哪些属性应该被保留。
- 其次,我们提出了多个新的正则化器来提高质量。
- 第三,我们提出了对 StyleGAN-NADA 中的启发式层选择的技术改进,使其更加直接和稳健。
总之,我们做出以下贡献:
- 我们减少了 one-shot 和 few-shot 域自适应中经常出现的模式崩溃/过拟合问题。我们的结果看起来与伪影(artifacts)较少的目标域图像相似。这些结果也忠实于源域图像的特点,并且能够捕捉到精细的细节。
- 我们的域自适应提供了更多的自由来控制共享公共隐编码的跨域图像之间的“相似性”,这使得使用最先进的图像编辑框架的大量下游应用成为可能,例如姿势自适应、光照自适应、表情自适应、纹理自适应、插值以及图层混合。
2. 相关工作
域自适应。域自适应是使模型适应不同域的任务。该域的不同工作尝试使用源域学习不同域的独立representations 在目标领域进行预测,例如图像分类。
- 更重要的是,通过结合自然语言监督生成不同的图像 representations 一直引起计算机视觉和 NLP 研究社区的兴趣。
- 最近,OpenAI 的对比语言-图像预训练 (CLIP) 的工作表明,transformer 和大型数据集可以生成可迁移的视觉模型。在 CLIP 中,图像和文本均由高维语义 embedding 向量表示,然后可用于 zero--shot 学习。
基于 GAN 的域自适应。在 GAN 领域,针对 few-shot 域适应任务提出了各种模型和训练策略。与我们的工作最相关的是基于 StyleGAN 的领域适应方法,在目标域展示令人印象深刻的视觉质量和语义可解释性。这些方法可以大致分为 few-shot 和 one-shot 域自适应方法。
- StyleGAN-ADA 是一种著名的 few-shot 方法,它提出了一种自适应判别器增强方法,可以在有限数据上训练 StyleGAN。
- 另一项工作 DiffAug 将可微变换应用于真实图像和生成图像以进行稳健训练。
- 与鉴别器相关的方法 FreezeD 冻结鉴别器的较低层以实现领域适应。
- Toonify (justinpinkney/toonify) 在不同生成器的模型权重之间进行插值,以从新领域生成样本。
- 最近的一项工作,通过使用跨域对应地保留源域中样本实例的相对相似性和差异,来减少对有限数据的过拟合。
隐空间解释和语义编辑。自 GAN 出现以来,GAN 对隐空间的解释和理解一直是人们感兴趣的话题。该领域的一些著名作品导致了许多基于 GAN 的图像编辑 应用程序。最近对 StyleGAN 激活空间的研究表明,GAN 可用于下游任务,如无监督和 few-shot 部分分割,提取目标的 3D 模型和其他语义图像编辑应用。
图像 embedding 是用于研究 GAN 可解释性的方法之一。为了使用 GAN 对给定图像进行语义编辑,需要将图像嵌入/投影到其隐空间中。
- Image2StyleGAN 将图像嵌入到称为 W+ 空间的扩展 StyleGAN 空间中。
- 一些后续工作引入了正则化器和编码器,以保持隐编码忠实于 StyleGAN 的原始空间。
- Improved-Image2StyleGAN (II2S) 使用 P_N 空间对 embedding 进行正则化,以实现高质量图像重建和图像编辑。我们使用这种方法将真实图像嵌入到 StyleGAN 中,并在第 4 节中表明我们的域自适应保留了原始 StyleGAN 的属性。
图像编辑是识别 GAN 所学概念的另一种工具。在 StyleGAN 领域,最近的工作在隐空间中提取了有意义的线性和非线性路径。
- InterfaceGAN 找到线性方向以有监督的方式编辑隐编码。
- 另一方面,GANSpace 在 W 空间中使用 PCA 提取无监督线性方向进行编辑。
- 另一个框架 StyleRig 将 GAN 的隐空间映射到 3D 模型。
- StyleFlow 在隐空间中提取非线性路径以实现顺序图像编辑。
- 在本文中,我们将使用 StyleFlow 来测试域自适应图像的语义编辑。
在基于文本的图像编辑领域,
- StyleCLIP 扩展了 CLIP 以执行基于 GAN 的图像编辑。StyleCLIP 使用 CLIP embedding 向量遍历 StyleGAN 流形,通过调整 GAN 的隐编码,以使生成的图像的 CLIP embedding 类似于目标向量,同时在隐空间中保持接近输入。这种方法的缺点是这些编辑无法将 GAN 的域迁移到其原始流形之外。
- CLIP embedding 的使用启发了 StyleGAN-NADA,它使用细化学习(refinement learning)创建了一个新的 GAN 来进行 zero-shot 域自适应。尽管尚未发布,但他们在随附的代码中演示了 one-shot 域适应。原始域和目标域由 CLIP 文本 embedding 表示,embedding 的差异表示用于迁移域的方向。在随附的源代码中,他们使用了原始域的平均 CLIP 图像 embedding 的引导估计,并使用参考图像或其 CLIP 图像 embedding 来表示新域。
3. 方法
我们的方法涉及微调针对某些原始域 A 训练的 GAN,例如 FFHQ 面孔,使其适应新的相关域 B。在我们的方法中,A 中的图像和 B 中的图像通过共同的隐编码相互关联。可以在域 A 中生成或嵌入的任何图像都可以转移到 B 中相应且相似的图像。我们使用 CLIP embedding 作为语义空间来模拟域 A 和 B 之间的差异,我们使用 StyleGAN 作为图像生成器。
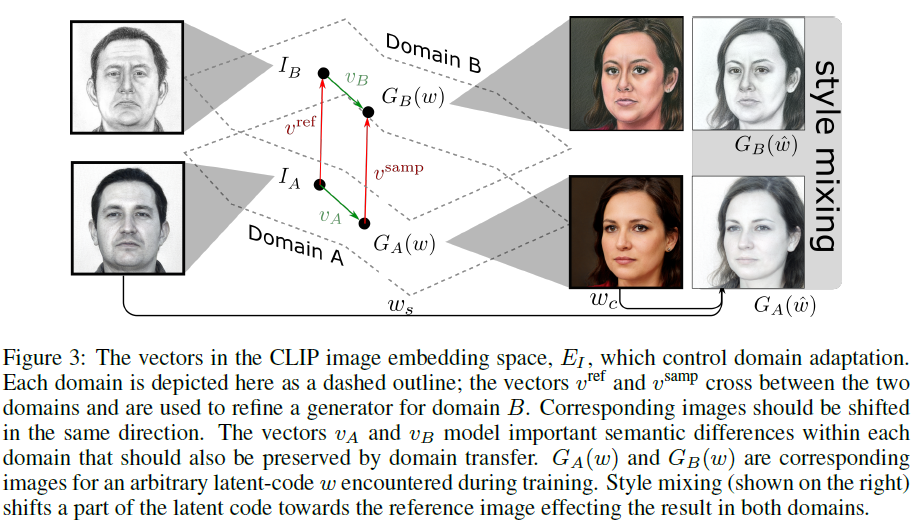
如图 3 所示,我们方法的一个关键是保留域内和跨域的方向。在微调域 A 的 GAN(以获得域 B 的 GAN)之前,我们确定域间隙方向。这个方向称为 v^ref,这是 CLIP embedding空间中的一个向量,它从域 A 中的相应图像 I_A 指向域 B 中的参考图像 I_B。我们使用 CLIP 图像 embedding 模型 E_I 来查找
![]()
在域 A 中为域 B 中的给定图像查找 I_A 是当前最先进技术 StyleGAN-NADA 的一个重大限制,因为它们使用域 A 的均值。域 A 的均值 是 I_A 的一个非常粗略的近似值。与此相反,我们提出了一个逆域自适应步骤,通过将图像 I_B 投影到域 A 中来找到比域 A 的均值更相似和更具体的参考图像样本。原则上,这个问题也是一个域自适应问题,类似于我们要解决的问题,只是方向相反。 主要区别在于我们在域 A 中有一个预训练的 GAN。
我们使用 II2S GAN 逆映射方法来为类似于 I_B 的图像找到可能位于域 A 内的隐编码。I2S 和 II2S 方法使用来自 StyleGAN2 的 W 空间的扩展版本。W 编码使用了 18 次,一次性用于 StyleGAN2 中的每个风格块。当允许每个元素独立变化时,产生的隐空间称为 W+ 空间。I2S 表明,额外的自由度允许 GAN 对更广泛的图像集进行逆映射,具有非常详细的重建能力,II2S 表明,一个额外的正则化项可以使隐编码接近其原始分布,从而使隐编码操作更加稳健。II2S 使用超参数 λ,可以增大该参数以使用更多正则化生成隐编码,因此在 W+ 隐空间的更高密度区域中。

此参数的效果如图 2 所示。原始工作中建议的值为 = 0.001,但是,较低的 λ 值使 II2S 找到与由原始 GAN 的映射网络生成的隐编码相距太远的隐编码,从而产生不太可能来自域 A 的图像,低估了域之间的差距。在域迁移的上下文中,我们发现使用 = 0:01 很有用,如图 2 所示。结果是 W+ 空间中的隐编码 w^ref 向域 A 的高密度部分迁移。然后,从该代码生成的图像 I_A 是域 A 中对应于 I_B 的图像。
如图 2 所示,我们使用 II2S 找到一个图像 I_A,我们认为它与 I_B 相似,但仍然可能在域 A 内。原则上,II2S 有可能找到 I_A,它与 I_B 足够相似到可以认为是相同,在这种情况下,两个域重叠。然而,我们关注不同域的情况,向量 v_ref 表示域 A 和域 B 之间的间隙或迁移的方向。我们使用细化学习(refinement learning)来训练新的生成器 G_B,使得从 G_B 生成的图像(相对于来自 G_A 的图像)平行于 CLIP 空间中的 v^ref 移动。所需的迁移由图 3 中的红色箭头指示。
在训练期间,使用 StyleGAN2 的映射网络生成隐编码 w。 G_A 和 G_B 都用于从相同的隐编码生成图像,但是 G_A 的权重被冻结并且在训练期间只有 G_B 被更新。细化学习的目标是 G_B 保留域 A 内的语义信息,但它也会生成跨越域间隙的图像。在优化域 B 的生成器时,我们冻结了 StyleGAN2 “ToRGB” 层的权重,并且映射网络也被冻结了。训练的整体过程如图4所示。
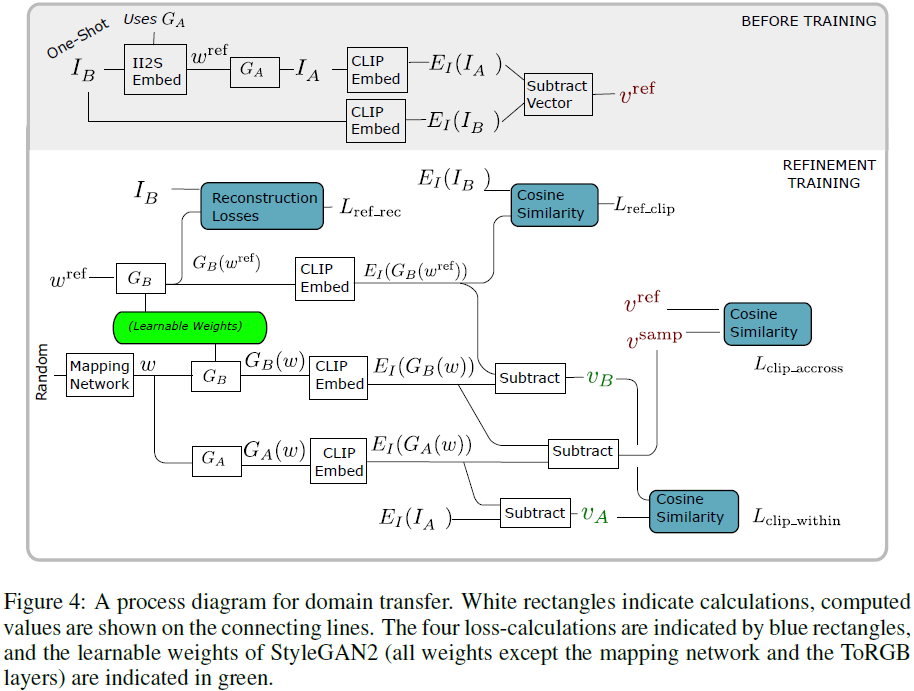
训练的目标是将 CLIP embedding 从域 A 沿与 v^ref 平行的方向移动。 我们使用向量 v^samp 来表示训练期间网络 G_B 在单个样本上的域偏移。 我们有
![]()
作为使用两个生成器从相同的 w 隐编码生成的相应图像的跨域向量。 我们使用 loss
![]()
其中 sim(a,b) 是余弦相似度。当域迁移向量平行时,这个损失项被最小化。
重要的是,参考图像 I_B 与生成的图像 G_B (w^ref) 相匹配,无论是在语义意义上(通过 CLIP embedding 的相似性来衡量)还是在视觉意义上。我们使用两个 loss 来完成此操作:L_ref-clip 和 L_ref-rec。第一个 loss 衡量原始和重建参考图像的 CLIP embedding 的变化,
![]()
该 loss 确保 G_B 可以重建 embedding。 与 L_clip-accross 不同,这个 loss 不是基于两个域之间embedding 的变化,而是通过将 G_B 对齐到 CLIP 空间中的全局 embedding 来引导 G_B,确保 I_B 在 G_B 的域中保持固定。
第二个 loss 是基于感知和像素级精度的重建损失,
![]()
其中 L_PIPS 是感知 loss,L_2 是像素之间的平方欧氏差。这种 loss 的目的是确保保留图像的视觉质量,而不仅仅是语义质量。除 L_ref-clip 之外,这是必要的,因为虽然 CLIP embedding 捕获了图像的许多语义和视觉质量,但仍有许多感知上不同的图像可以产生相同的 CLIP embedding。这在图 6 中可见,没有重建损失 G_B 无法保留输入的一些重要视觉质量(例如对称性)。

GAN 有减少训练过程中变化的趋势,尤其是在小样本微调中。我们通过保留与域差距无关的语义信息来解决这个问题。与域变化无关的语义变化不应受到 G_B 的影响。因此,域 A 中连接参考图像和样本图像的向量应平行于域 B 中的相应向量。
![]()
设 v_A 是一个向量,将带有隐编码 w 的样本图像连接到 CLIP 空间中的参考图像。这个向量表示域 A 内的语义变化,我们希望匹配的语义变化发生在域 B 内。
![]()
让 v_B 表示域 B 中的相应向量。我们引入 loss
![]()
当两个域内更改相同时,它取最小值。最终 loss 是 loss 的加权和
![]()
这四个 loss 指导 G_B 的 refinement 过程。在这些 loss 中,L_clip-across 是由 StyleGAN-NADA 提出的。其他 loss 是本文的新贡献。
风格混合。在训练之后,生成器 G_B 生成在语义上与参考图像 I_B 相似的图像。然而,我们观察到视觉风格可能不够相似。我们将此归因于目标域可能是新生成器 G_B 生成的图像的子集。 StyleGAN-NADA 使用第二个隐挖掘网络(latent-mining)解决了这个问题,以便识别 G_B 域内与参考图像更好匹配的隐编码分布。我们的方法利用了 W+ 空间中的隐编码结构。W+ 空间中的隐编码可以分为 18 个块,每块 512 个元素,每个块影响 StyleGAN2 的不同层。根据经验,W+ 编码的后面的块已被证明对图像的样式(例如纹理和颜色)有更大的影响,而前面的层会影响图像的粗略结构或内容。我们将图像中的隐编码划分为 w = (w_C , w_S),其中 w_C 由捕获图像内容的 W+ 隐编码的前 m 个块组成,而 w_S 由其余块组成并捕获样式。在这项工作中,除非另有说明,否则我们将使用 m = 7。然后使用线性插值基于参考图像迁移样式,形成 ^w = (w_C; ^w_S),其中
![]()
其中, 是 w^ref 的最后(18 - m)块。考虑根据 StyleGAN2 映射网络的隐编码分布获得的随机 w 生成的图像分布,如果 α = 0,则图像 G_B(^w) 的分布包括参考图像,还包含各种其他精细的视觉风格。如果 α = 1,则图像 G_B(^w) 仍将具有多样化的内容,但它们都将非常接近 I_B 的视觉风格。这种方法的一个重要应用是照片的条件编辑。为实现这一点,首先我们采用真实输入图像 I_real 并在域 A 中使用生成器 G_A 上的 II2S 将其逆映射,以找到 W+ 隐编码 w_real。然后, G_B (w_real) 在域 B 中生成相应的图像。然后我们可以通过插入样式代码 (8) 来计算 ^w_real,这样最终图像 G_B (^w_real) 与 I_real 相似,但内容和视觉风格都发生了朝向域 B 的变化 。
4. 结果
在本节中,我们将展示我们工作的定性和定量结果。与我们的方法最密切相关的工作是 StyleGAN-NADA,我们将其作为主要比较对象。该论文主要讨论 zero-shot 域自适应,但该方法也可以完成one-shot 域自适应。此外,它展示了对现有技术的令人印象深刻的改进,甚至在视觉质量方面击败了许多 SOTA few-shot 方法。因为我们的方法可以显着改进 StyleGAN-NADA 中所示的结果,这强调了我们的想法在减少过拟合方面的重要性。

视觉评估。在图 5 中,我们比较了我们在人脸上的结果与两种最相关的竞争方法——StyleGAN-NADA 和 few-shot 域适应。结果表明,我们的方法仍然忠实于域 A 中嵌入图像的原始身份,而其他两种方法会出现过拟合,即塌缩到不保留显着特征(例如人的身份)的狭窄分布。我们在补充材料中展示了额外的视觉结果,包括汽车和狗的结果以及微调域适应的结果。
 消融研究。我们进行消融研究来评估我们框架的每个组件。在图 6 中,展示了 II2S embedding、不同 loss 和样式混合/插值对输出的影响。
消融研究。我们进行消融研究来评估我们框架的每个组件。在图 6 中,展示了 II2S embedding、不同 loss 和样式混合/插值对输出的影响。
 图像编辑功能。我们方法的另一个重要方面是我们能够在域 B 中保留原始 StyleGAN(域 A)的语义属性。我们可以通过学习生成器 G_B 对域 B 中的图像进行编辑,而无需在新域重新训练图像编辑框架 。图 7 显示了新域 B 中的图像编辑功能。我们使用 StyleFlow 编辑(例如光照、姿势、性别等)来显示新域中可能进行的细粒度编辑。
图像编辑功能。我们方法的另一个重要方面是我们能够在域 B 中保留原始 StyleGAN(域 A)的语义属性。我们可以通过学习生成器 G_B 对域 B 中的图像进行编辑,而无需在新域重新训练图像编辑框架 。图 7 显示了新域 B 中的图像编辑功能。我们使用 StyleFlow 编辑(例如光照、姿势、性别等)来显示新域中可能进行的细粒度编辑。
 局限性。我们的方法有几个局限性(见图 8)。由于 one-shot 域适应问题的挑战性性质,其中一些限制是固有的。其他限制可以在未来的工作中解决。首先,当我们在域 A 中找到与域 B 中的输入相对应的初始图像时,我们不会尝试控制语义相似性。未来的工作应该鼓励图像具有相似的语义。其次,我们只在相关域之间迁移,例如,本文未探讨将 FFHQ 人脸转移到汽车领域。第三,与 StyleGAN 的原始分布相关,当对象转换为规范位置(例如与 FFHQ 相同的面部姿势)时,嵌入到 Style-GAN 中效果最佳。 参考图像中物体的极端姿势有时会失败。
局限性。我们的方法有几个局限性(见图 8)。由于 one-shot 域适应问题的挑战性性质,其中一些限制是固有的。其他限制可以在未来的工作中解决。首先,当我们在域 A 中找到与域 B 中的输入相对应的初始图像时,我们不会尝试控制语义相似性。未来的工作应该鼓励图像具有相似的语义。其次,我们只在相关域之间迁移,例如,本文未探讨将 FFHQ 人脸转移到汽车领域。第三,与 StyleGAN 的原始分布相关,当对象转换为规范位置(例如与 FFHQ 相同的面部姿势)时,嵌入到 Style-GAN 中效果最佳。 参考图像中物体的极端姿势有时会失败。
5. 结论
我们提出了一种新的 one-shot 域自适应方法。这项工作的主要成就是获得了前所未有的质量结果,同时减少了先前工作中观察到的过拟合。我们工作的技术关键组成部分是,把域间隙建模为 CLIP embedding 空间中的向量。这是一种保留域内变化的方法,以及用于细粒度的基于属性控制的几个扩展。我们还介绍了几个新的正则化器和一种风格混合方法。
附录

控制风格间隙。我们的方法提供了一种通过显式控制从域 A 采样或嵌入域 A 的图像样式来控制域 A 和域 B 之间的域间隙的方法。图 10 显示,我们可以通过增加样式混合参数 α,控制参考图像的样式保留程度,这对于其他任何方法都是不可能的。这使用户可以更好地控制内容的生成和编辑。
参考
Zhu, Peihao, et al. "Mind the gap: Domain gap control for single shot domain adaptation for generative adversarial networks." arXiv preprint arXiv:2110.08398 (2021).
S. 总结
S.1 核心思想
本文方法的核心是保留域内和域间方向,如图 3 所示。
域内方向(v_A,v_B)指的是:语义信息 / 语义多样性。若域 A 所有的语义信息 v_A 都被域 B 复制(v_B 与 v_A 平行),当进行域迁移时,域 B 就能保留域 A 的语义多样性。
域间方向指的是:域间隙 / 域差异。以 StyleGAN-NADA 为例,当域间方向由文本确定时,文本描述的方向就是要进行域迁移的方向。当域间方向由参考图像确定时,需要找出域 B 中的参考图像 I_B 在域 A 中的对应图像 I_A,它们的 embedding 之间的差异就是域差异,也就是进行域迁移的方向。
S.2 步骤
在域 A 中为域 B 中的给定图像查找 I_A 是本方法的核心,也是当前最先进技术 StyleGAN-NADA 的一个重大限制,因为它们使用域 A 的均值。域 A 的均值 是 I_A 的一个非常粗略的近似值。与此相反,我们提出了一个逆域自适应步骤,通过将图像 I_B 投影到域 A 中来找到比域 A 的均值更相似和更具体的参考图像样本。
S.3 风格混合
W+ 空间中的隐编码可以分为 18 个块,每个块影响 StyleGAN2 的不同层。W+ 编码的后面的块对图像的样式(例如纹理和颜色)有更大的影响,而前面的层会影响图像的粗略结构或内容。可以通过对后面的块(风格块)实行插值(对源域和目标图像的风格块进行加权和),来控制风格混合(迁移)程度。

















 7324
7324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









