






摘要
跨模态检索是多媒体领域中一项重要而富有挑战性的研究课题。这项任务的大多数现有工作都是有监督的,通常在大量对齐的图像-文本/视频-文本对上训练模型,假设训练和测试数据来自同一分布。如果这一假设不成立,传统的跨模态检索方法在评估时可能会遇到性能下降。在本文中,我们介绍了一个新的任务称为域自适应跨模式检索,其中训练(源)数据和测试(目标)数据来自不同的域。这项任务具有挑战性,因为视觉和文本项目之间不仅存在语义差距和情态差距,而且源域和目标域之间也存在领域差距。因此,我们提出了一种多级对齐网络(MAN),该网络具有两个映射模块,分别在公共空间中投影视觉和文本模式,并使用三个对齐来学习空间中更具辨别力的特征。语义对齐用于缩小语义鸿沟,跨模态对齐和跨域对齐用于缓解模态鸿沟和域鸿沟。在域自适应图像文本检索和视频文本检索环境下的大量实验表明,我们提出的模型MAN始终优于多基线,显示了对目标数据的优异泛化能力。此外,MAN在TRECVID 2017、2018特设视频搜索基准上为大规模文本到视频检索建立了新的技术水平
介绍
跨模式检索的关键是学习一个公共空间,在这个公共空间中可以直接计算不同模式之间的相似度。
在实际应用场景中,如果我们想要为特定的新域(目标域)构建跨模式检索,一种简单的方法是收集大量标记的训练数据,另一种解决方案不是收集新的数据集,而是利用现成的标记跨模式数据。
来自不同数据集的两张时装图片显示出明显的差异。在这种情况下,大多数现有的跨模式检索模型可能会经历显著的性能下降,因为它们假设训练和测试数据来自同一分布。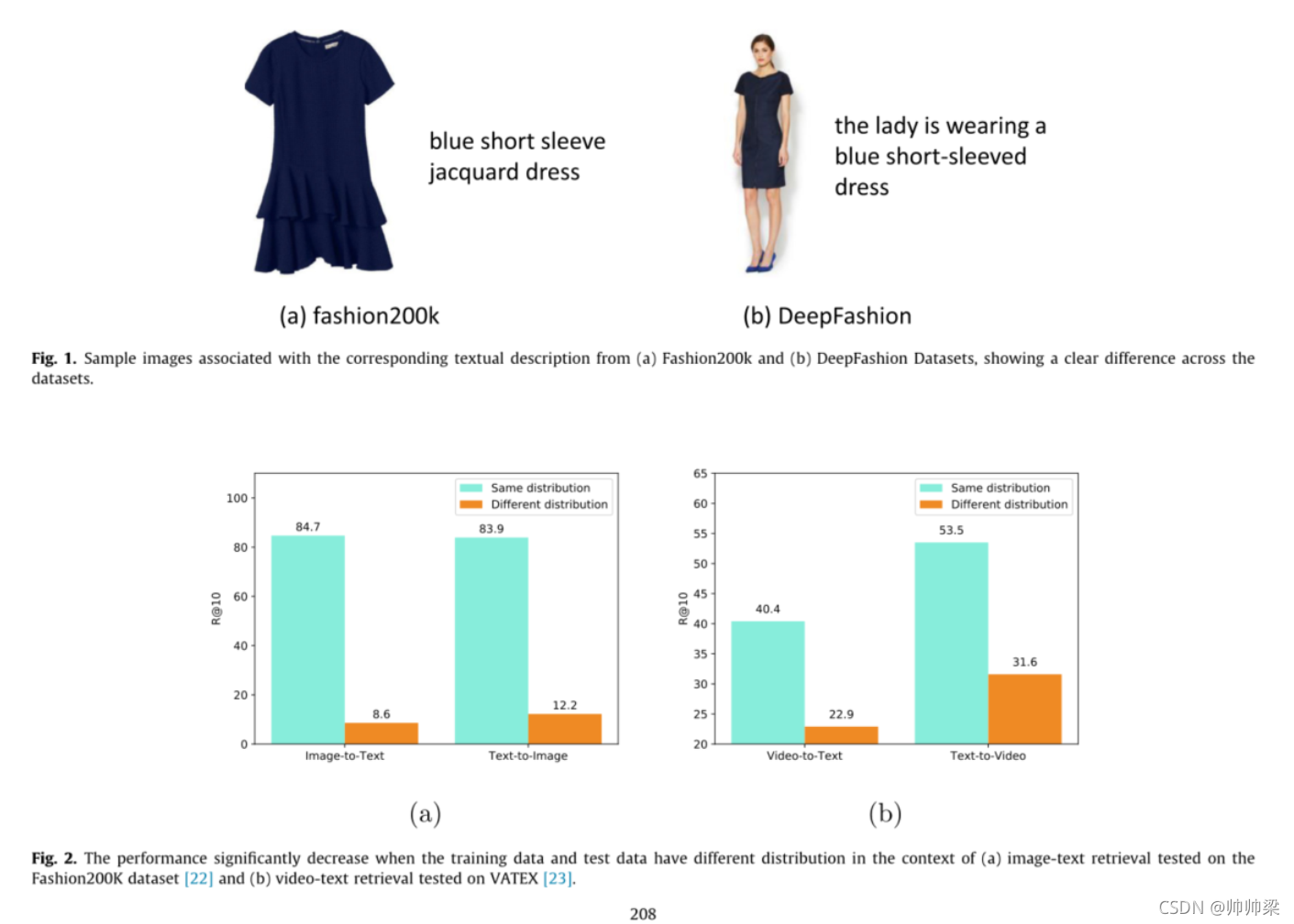
因此,如何使用现成的标记数据集为新的目标领域建立跨模式检索模型仍然是一个悬而未决的问题。我们引入了一个称为域自适应跨模态检索的任务,其中给定多个与未标记目标数据集具有不同数据分布的标记源数据集,它要求建立一个适用于目标域的跨模式检索模型。
在给定多个与未标记目标数据集具有不同数据分布的标记源数据集的情况下,它要求建立一个适用于目标域的跨模式检索模型。
针对视觉和文本模式,本文提出了一种用于域自适应跨模式检索任务的多级对齐网络(MAN)。MAN首先分别通过视觉编码和文本编码将视觉和文本模态映射到公共空间,并采用三种对齐方式来缓解映射公共空间中的上述差距:用于缩小语义差距的语义对齐,用于缓解模态差距的跨模态对齐,并且采用跨畴对齐来减小畴隙。具体来说,对于语义对齐,我们使用三元组排序损失[25]在公共空间中使语义相关数据接近,而语义无关数据远离。对于域间隙,我们使用多个鉴别器来区分来自不同域的特征,而映射编码器通过对抗性学习将其混淆,从而推动源数据的分布与目标数据很好地对齐。对于模态差异,模拟使用对抗性学习来调整不同模态的数据分布。
材料与方法
在本节中,我们首先正式定义了域自适应跨模式检索问题,然后介绍了我们提出的MAN的模型结构和模型训练描述。为了便于参考,表1列出了本工作中使用的主要缩写。
域自适应跨模态检索
先得到一个 标注的待标签的数据集,然后有一个未标记的目标数据集,目标数据集的视频和文本可能是不成对的,基于上述源数据集和目标数据集,域自适应跨模态检索要求学习一种跨模态检索模型,该模型可以在目标域的上下文中通过文本查询搜索相关图像/视频,或通过图像/视频查询搜索相关句子。
网络体系结构
该网络由三个组件组成:用于提取视觉项目特征的视觉编码器,用于提取句子特征的文本编码器,以及公共空间学习模块,用于对齐所学习的公共空间中的跨模态和跨域表示。
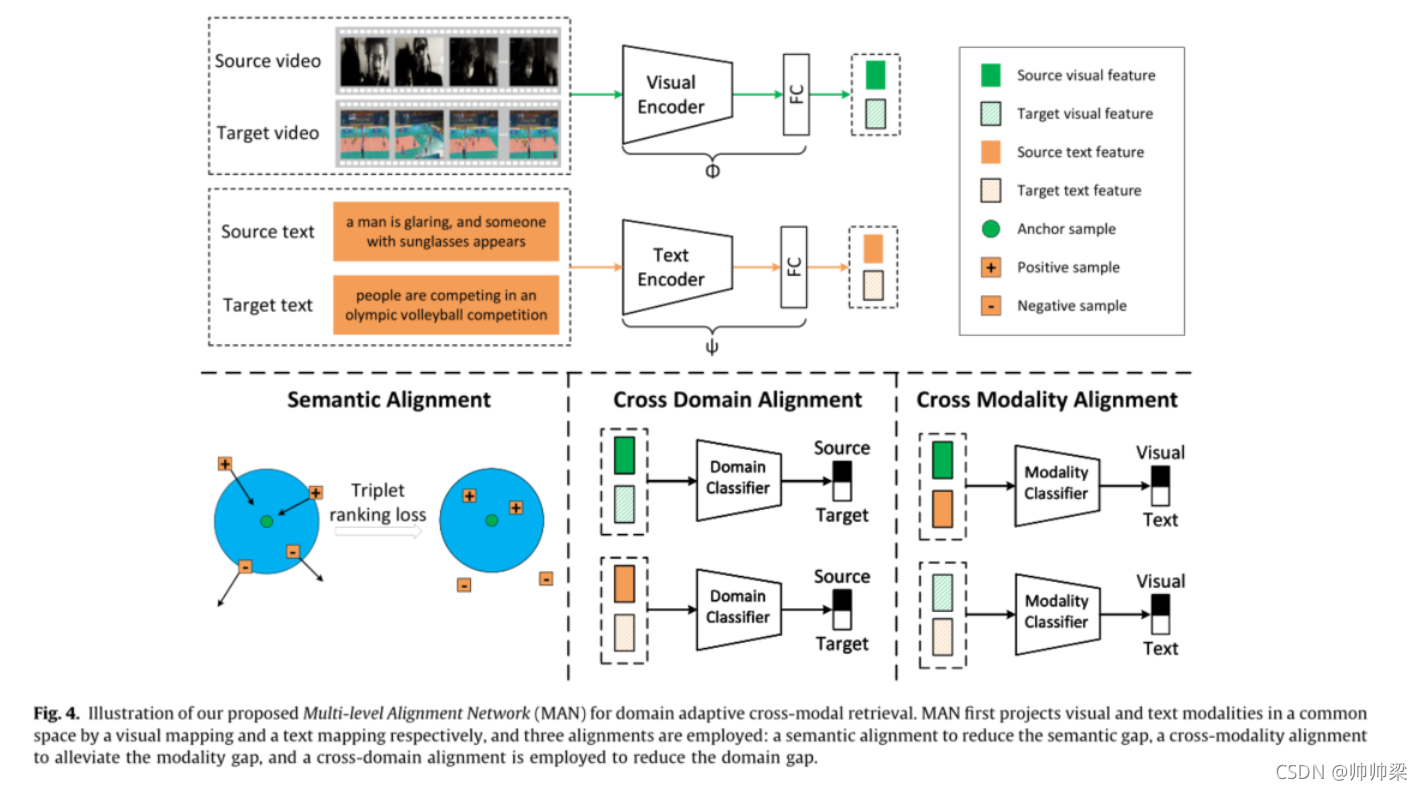
对于图像文本检索,给定一幅图像,我们采用在ImageNet上预训练的CNN模型,并利用其最后一个池层的输出作为图像编码特征;给定一个句子,我们采用双向LSTM,并进一步使用最大池层来聚合所有时间步的隐藏状态,输出被视为句子编码特征。由于图像和句子具有不同的形式,它们的编码特征无法直接比较。因此,在编码特征上进一步采用完全连接的层,以将其投影到公共空间中,其中图像-文本相似度可以通过标准距离度量直接计算,例如。余弦距离。为了便于参考,我们将特征提取和投影过程合并到一个空间。请注意,对于目标数据和源数据,我们共享映射模块以将它们映射到公共空间。这样的设计期望将在源领域学到的知识转移到目标领域。
对于视频文本检索,我们使用一种多级视频编码和一种源自[13]的多级句子编码,分别将视频和文本编码并投影到公共空间中。
多级对齐
对于领域自适应跨模态检索,除了跨模态检索中视觉和文本项之间众所周知的语义鸿沟和模态鸿沟外,不同数据集之间还存在领域鸿沟,这使得该问题更具挑战性。在本文中,我们提出了一种多层次对齐方法来增加映射的视觉和文本特征的通用性,它包括一种减少语义差距的语义对齐方法和一种减少模态差距的跨模态对齐方法,以及一种减少域差距的跨域对齐方法。(减少三种差距 )
语义对齐
公共空间中映射特征的基本要求是语义区分性,这使得检索模型能够找到与给定查询语义相关的项。为此,流行的方法是使用三元组排序损失,我们在源数据集上使用这种损失。
跨域对齐
由于上述语义对齐只考虑源数据集而忽略目标数据集,因此仅使用语义对齐学习的特征可能无法很好地用于目标域。为了缓解这种情况,我们还引入了一种跨域对齐,旨在使学习到的特征域保持不变。跨域对齐的目标是学习源域和目标域之间不可区分的表示,从而使在标记的源域上学习的模型能够很好地适用于目标域。
我们还使用它来对齐源域和目标域之间的特征。GAN模型通常由一个发生器和一个鉴别器组成,通常通过一个两人对抗性游戏训练,我们使用GAN来代表作为生成源和目标数据特征表示的生成器,此外,我们还引入了域鉴别器,用于预测输入特征是来自源域还是目标域。
损失函数就是两个gan的集合,我们希望来自不同领域的映射特征尽可能对齐,以便领域分类器无法区分它们。 也就是用gan来生成假的,让鉴别器鉴别不出来真假的意思。
只需要让判别的结果D(G(z))接近于1就可以了
实际上最大化D是困难的,因此我们在鉴别器之前插入一个梯度反转层,以反转D的梯度。因此,只需最小化D即可。
跨模态对齐
不同模态的特征通常具有不一致的分布和表示。以前的方法通常通过对相应视频和文本对的一致性建模,将来自不同模式的数据投影到公共空间中,而不考虑不同模式之间的分布一致性。此外,尽管三重态排序损失在一定程度上减少了跨模态间隙,但它仅适用于标记的源域。因此,目标域的跨模态间隙仍然存在。因此,与跨域对齐类似,我们还引入了跨模态对齐来学习模态变体特征。具体来说,我们介绍了两种模态鉴别器,一种用于源域,另一种用于目标域。交叉熵损失也被用来训练模态鉴别器。
跟上面的一样,
联合训练与推理
损失是三个相加。
对于训练好的参数,我们使用余弦相似性来度量他的相似度,
对于检索,给定一个查询,我们根据与给定查询的余弦相似性按降序对所有候选图像进行排序。
结论
在本文中,我们介绍了一种新的任务域自适应跨模态检索,其中训练数据和测试数据具有不同的分布。由于任务中存在语义鸿沟、领域鸿沟和情态鸿沟,这项任务非常具有挑战性。针对这一任务,我们提出了一个多级对齐网络,该网络通过三个对齐模块学习跨域和模式的对齐视觉语义嵌入。我们的模型与视觉和文本编码器正交,允许我们灵活地采用最先进的视觉和文本编码器结构。在视频文本检索和图像文本检索环境下进行的大量实验验证了该方法的有效性。在未来,我们将探索适用于域自适应跨模式检索的视觉和文本编码器结构。在本文中,我们在跨模态检索的具体案例中展示了域自适应思想,它们原则上可以推广到其他基于检索的任务,例如视频到视频检索。

















 1781
1781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









