







Visualizing the loss landscape of Self-supervised Vision Transformer
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0 摘要
掩码自动编码器(Masked autoencoder,MAE)作为视觉 transformer(ViT)中掩码图像建模的代表性自监督方法,引起了广泛关注。然而,即使 MAE 显示出比完全从头监督训练更好的泛化能力,其原因仍未得到探讨。在另一项研究中,提出了重构一致掩码自动编码器(Reconstruction Consistent Masked Auto Encoder,RC-MAE),它采用指数移动平均(EMA)教师形式的自蒸馏方案,并显示出 EMA 教师在优化过程中执行条件梯度校正(gradient correction)。为了进一步从优化的角度探讨 MAE(MAE-ViT)训练的自监督 ViT 为何具有更好的泛化能力以及 RC-MAE 梯度校正的效果,我们可视化了自监督 ViT (MAE 和 RC-MAE)的损失景观(loss landscape),并将其与监督的 ViT(Sup-ViT)进行比较。与之前基于分类任务损失的神经网络损失景观可视化不同,我们通过计算预训练任务损失来可视化 ViT 的损失景观。通过损失景观的视角,我们发现了两个有趣的现象:(1)MAE-ViT 的整体损失曲率比 Sup-ViT 更平滑和宽广。(2)EMA 教师允许 MAE 在预训练和线性探测中扩大凸性区域,导致更快的收敛。据我们所知,这是首次通过损失景观的视角研究自监督 ViT 的工作。
2 基础:MAE 和 RC-MAE
掩码自动编码器(MAE)[19](分割-掩蔽-重建)通过随机掩蔽(mask)大量输入图像块进行自监督学习,然后使用基于 ViT 的编码器 f 对可见图像块进行编码,并使用解码器 h 对掩蔽的图像块进行重建。MAE 将输入图像 X∈R^(C×H×W) 分割成 N 个不相交的图像块 ~X ∈ R^(N×(P^2⋅C)),其中 P^2 代表图像块的面积。MAE 随后对 ~X 的一个随机子集 xi ∈ ~X, ∀i ∈ M 进行掩蔽,其中 M 是掩蔽标记的索引。可见的图像块 xj ∈ ~X, ∀j ∈ V(其中 V 是可见图像块的索引)被传递到编码器,生成编码向量 z = f({xj: j∈V})。随后,解码器 h 根据编码的可见图像块对掩蔽的图像块集合进行重建,得到 ^Y = h(z; {xj: j∈M}),其中 ^Y ∈ R^(N×(P^2⋅C))。损失函数 L_r 仅在掩蔽的图像块上计算,采用均方误差损失函数:
![]()
重构一致性掩码自动编码器(RC-MAE)[25] 提供了一种自监督学习中常用的技术 EMA 教师 [33] 的分析。EMA 教师 T 由先前学生 S 的指数移动平均值组成,其中 α ∈ [0,1] 通过
![]()
可以递归扩展为 T(t) = ∑^t_(i=0) α^i·(1−α)·S^(t−i)。除了 MAE 的重构目标 L_r 外,教师还为学生网络(如 MAE)提供一致性目标 ^Y’。因此,学生网络通过以下目标进行优化:
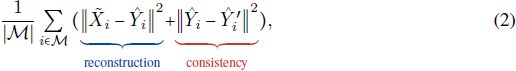
研究发现,在一个简单的线性模型中 [25],教师本质上像一个梯度记忆,当当前输入 x_i 与先前输入 ^xj 相似时(通过点积度量),它会有条件地移除之前的梯度方向。同样,当当前输入与先前输入正交时,点积为 0,教师不会提供校正信号。因此,EMA 教师可能通过在过拟合可能性较大时(例如,输入多样性较低时)主动防止过拟合,并在过拟合可能性较小时(例如,输入多样性较高时)允许模型学习新知识,从而稳定训练。
3 损失景观
为了可视化 ViT 的损失景观(loss landscapes),我们遵循了 [26] 中称为滤波器归一化的可视化策略。具体来说,[26] 获得了两个随机高斯方向向量 δ 和 η 来可视化在 2D 投影空间内的损失表面。需要注意的是,方向向量被归一化为与相应参数 θ 具有相同的范数。然后,通过沿着两个方向上的 2D 点评估损失来获得损失表面,如下所示:
![]()
其中 L 是由参数 θ 参数化的网络的损失函数。 α 和 β 是从 -1 到 1 变化的标量值,分别对应于损失表面的 x 轴和 y 轴。更多实现细节请参考附录 A。
3.1 分析
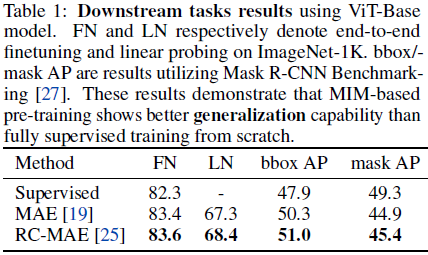
[26] 表明,通过这种基于滤波器归一化的可视化方法,最小化器的平坦度与泛化能力密切相关。此外,许多研究 [6; 22; 32; 23; 21; 26; 37; 9; 10] 得出的结论是,当神经网络收敛到具有小曲率和宽凸性区域的平坦区域时,它们的泛化能力更好。由于我们已经在表 1 中确认了使用 ViT [14] 的自监督学习方法 MAE[19] 和 RC-MAE[25] 比纯监督学习具有更好的泛化能力,在本节中,我们通过观察损失景观分析自监督方法更好泛化能力的原因,并从优化的角度研究 RC-MAE 中 EMA 教师的作用。
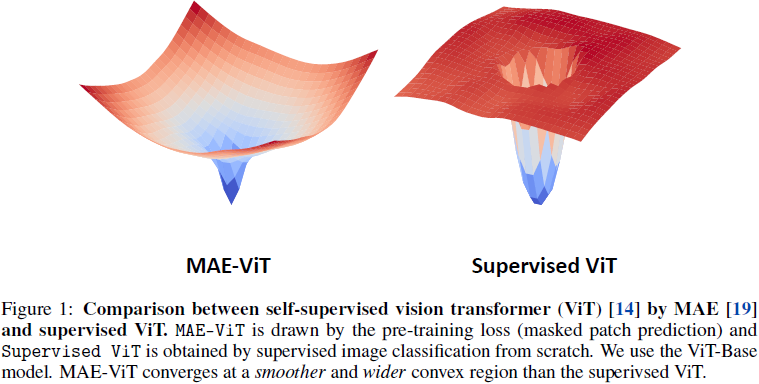
MAE-ViT 与 监督-ViT。 如图 1 所示,从头开始监督的 ViT [14] 显示出更窄的收敛区域(即凸区域),这一点也在 [10] 中观察到。相反,我们可以观察到通过 MAE [19] 进行自监督的 ViT 表现出更宽的损失景观凸区域。这表明,与完全监督模型相比,自监督方法在更广泛的初始条件下可能会收敛。我们注意到,这种更平滑和更宽(wider)的损失景观以及更好的下游任务性能(即泛化结果)与优化文献中的一个事实一致 [22; 23; 21; 32; 6; 10],即具有小曲率的宽凸区域(wide convex region)与神经网络泛化能力良好相关。
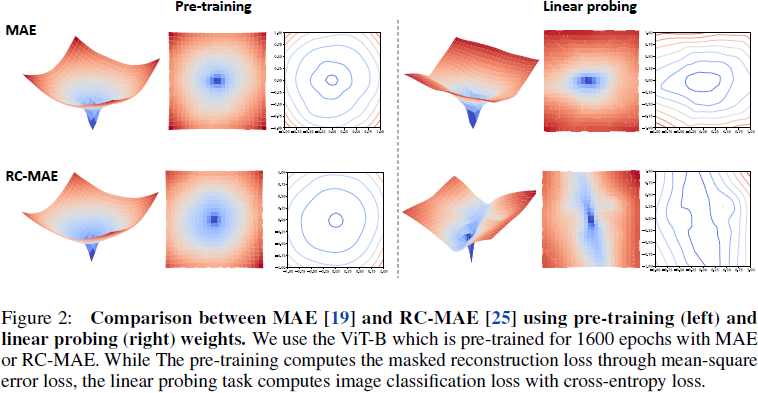
MAE 与 RC-MAE。 图 2 展示了预训练和线性探测(linear probing)的 MAE [19] 和 RC-MAE [25] 自监督 ViT 的损失景观。对于预训练,如图 2(左)所示,损失景观的俯视图和 2D 损失轮廓显示 RC-MAE 从比 MAE 更宽的凸区域收敛。此外,如图 2(右)所示,MAE和RC-MAE的线性探测结果比预训练损失有更复杂的损失曲率。我们推测,冻结特征权重仅学习线性层的线性探测任务对于分类 1K 类别来说很难优化。类似于预训练结果,RC-MAE 具有比 MAE 更宽的凸区域。由于 MAE 和 RC-MAE 之间的唯一区别是增加了 EMA 教师,这表明这种更宽的凸区域可能归因于 RC-MAE 中 EMA 教师的梯度校正效果。此外,Lee 等人 [25] 通过比较重构损失图和微调准确率表明,RC-MAE 的收敛速度比 MAE 更快。MAE 和 RC-MAE 之间的这些损失景观比较以及 [25] 中的实验支持了 RC-MAE 更好的收敛特性。
4 结论和未来工作
在这项工作中,我们通过可视化各种自监督 ViT 的损失景观,研究了自监督 ViT 的泛化能力和 RC-MAE 的梯度校正效果。通过损失景观的视角,我们观察到以下有趣的现象:(1)自监督 ViT 比完全监督 ViT 具有更平滑和更宽的整体损失曲率。(2)自蒸馏架构(即 EMA 教师)允许 MAE 扩展凸性区域,加速收敛速度。然而,关于自监督学习的效果仍有进一步探索的空间。
批量大小:[26] 表明,批量大小影响最小化器的锐度。未来的工作可以探索批量大小对 MIM 预训练的影响。
优化器:[10] 使用了一种锐度感知优化器,可能具有与 RC-MAE 中 EMA 教师相同的一些特性。直接比较和分析可能会得出一些有趣的结论。
与其他自监督方法的比较:我们只分析了基于 MIM 的自监督方法 [19; 25]。然而,在 MIM 方法出现之前,基于实例区分任务(例如对比学习)的方法 [20; 11; 12; 7; 18; 8; 5] 占主导地位。因此,从损失几何的角度研究和比较非 MIM 方法将是有趣的。
定量分析:我们只进行了损失景观的定性分析。然而,[10] 通过计算模型参数上的高斯扰动训练误差和主 Hessian 特征值分别定量了平均平坦度和损失曲率的程度。因此,我们期待未来的工作可以定量比较这些优化动态指标。

















 1311
1311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









