







Scaling Large Vision-Language Models for Enhanced Multimodal Comprehension in Biomedical Image Analysis
目录
3.3 训练优化(Finetuning and Optimization)
4.2 幻觉分析(Hallucination Analysis)
1. 概述
本文研究了大规模视觉语言模型(VLMs) 在 生物医学图像分析 任务中的应用,重点关注其在低剂量放射治疗(low-dose radiation therapy,LDRT) 相关数据上的适应性。
研究团队使用 LLaVA(Large Language and Vision Assistant) 作为基础模型,并通过指令微调(Instruction Tuning) 使其更适用于生物医学领域的多模态理解任务。
实验结果表明,微调后的模型在 视觉问答(VQA)任务上比基础模型表现更优,特别是在 减少幻觉(Hallucination) 和 提升领域特定理解能力 方面。研究采用了 42,673 篇文章 和 50,882 对图像-文本样本 进行训练,并通过 LLM 评审(LLM-as-a-judge) 评估了模型的性能。
本文贡献:
- 提出基于 LLaVA 的医学 VLM 训练方法,提高 AI 处理生物医学图像的能力。
- 构建新的医学 VQA 评测数据集,涵盖 详细描述 + 复杂推理,用于评估 AI 在医疗影像分析中的表现。
- 优化 LLM 微调策略,减少幻觉(Hallucination),提高模型的 可信度和稳定性。
- 引入计算优化策略(LoRA、DeepSpeed、FlashAttention-2),提升大模型训练效率。
2. 研究背景与动机
2.1 视觉语言模型(VLMs)的发展
传统 LLMs(如 ChatGPT、Galactica、BioBERT) 主要依赖文本数据,但科学研究常包含视觉信息(如医学影像、显微镜图像、X-ray 等)。
视觉语言模型(VLMs)结合了预训练视觉编码器(Vision Encoder)和LLM 语言处理能力,使 AI 能够同时理解文本和图像。
2.2 医疗 VLMs 的挑战
现有 VLMs 在生物医学领域适用性有限,容易产生幻觉(Hallucination),即模型输出与事实不符的错误信息。
领域特定知识不足:VLMs 主要在通用数据上训练,难以准确理解专业医学影像。
文本-图像对齐问题:模型可能无法正确关联医学图像与对应的文本描述,影响诊断和分析。
2.3 研究目标
开发专门针对 LDRT 的 VLMs,增强其对生物医学图像的理解能力。
通过微调(Fine-Tuning)减少幻觉,提升模型在医学领域的可靠性。
建立新的视觉问答(VQA)数据集,用于评估医学 AI 的视觉-文本对齐能力。
3. 方法
3.1 数据处理(Data Preprocessing)
数据来源:从 Semantic Scholar 获取 42,673 篇 LDRT 相关文章。
图像提取:使用 pdf2figures 从 PDF 文章中提取 165,000 张医学图像。
低质量图像筛选:采用 Laplacian variance 方法 过滤低分辨率或模糊图像,最终得到 150,000 张高质量图像。
自动生成问答数据:使用 Qwen2-72B-Instruct 生成 52456 组问答数据,涵盖详细描述(Detailed Description) 和 复杂推理(Complex Reasoning) 任务。
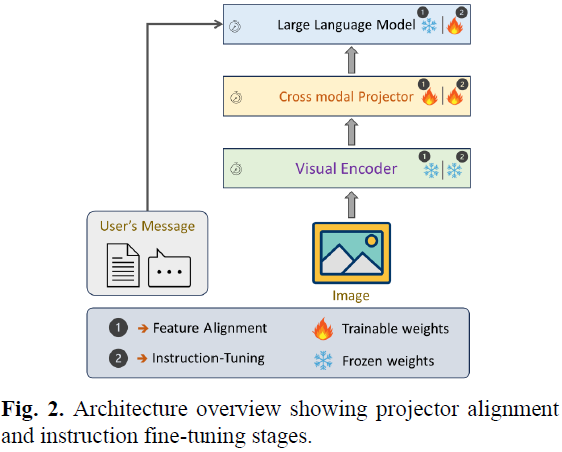
3.2 模型架构(Model Architecture)
本文基于 LLaVA(Large Language and Vision Assistant) 进行优化,核心组件包括:
- 视觉编码器(Vision Encoder):使用 CLIP ViT-L/14 处理图像。
- 跨模态投影器(Cross-Modal Projector):一个 2 层 MLP,将图像特征映射到 LLM 词向量空间。
- 语言模型(Language Model):采用 Vicuna-13B 作为 LLM,处理文本信息并生成答案。
3.3 训练优化(Finetuning and Optimization)
两阶段训练:
- 投影器对齐(Projector Alignment):优化投影器参数,确保视觉特征与 LLM 兼容。
- 指令微调(Instruction Tuning):在固定视觉编码器的情况下,微调 LLM 以优化回答质量。
内存优化:使用 Gradient Checkpointing 和 FlashAttention-2 以降低 GPU 内存占用。
计算优化:采用 DeepSpeed ZeRO3 进行高效并行计算。
参数高效调优:使用 LoRA(Low-Rank Adaptation),减少可训练参数数量,提高训练效率。
4. 实验与结果分析
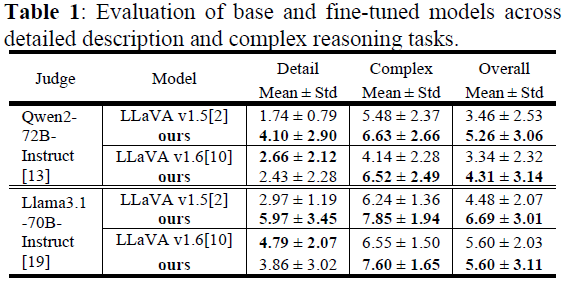
4.1 视觉问答(VQA)任务评估
评测方式:使用 Qwen2-72B-Instruct 和 Llama-3.1-70B-Instruct 作为评委模型(LLM-as-a-judge)。
评分标准:从相关性(Relevance)、有用性(Helpfulness) 和 准确性(Accuracy) 进行评分(0-10)。
实验结果:
- 微调模型在 详细描述任务(Detailed Description)和 复杂推理任务(Complex Reasoning) 上的表现优于基础模型。
- 在整体表现(Overall Mean Score)上也优于基础模型。
4.2 幻觉分析(Hallucination Analysis)
ROUGE 评分:衡量模型输出与真实答案的匹配度,微调后模型的 ROUGE 得分显著提高。
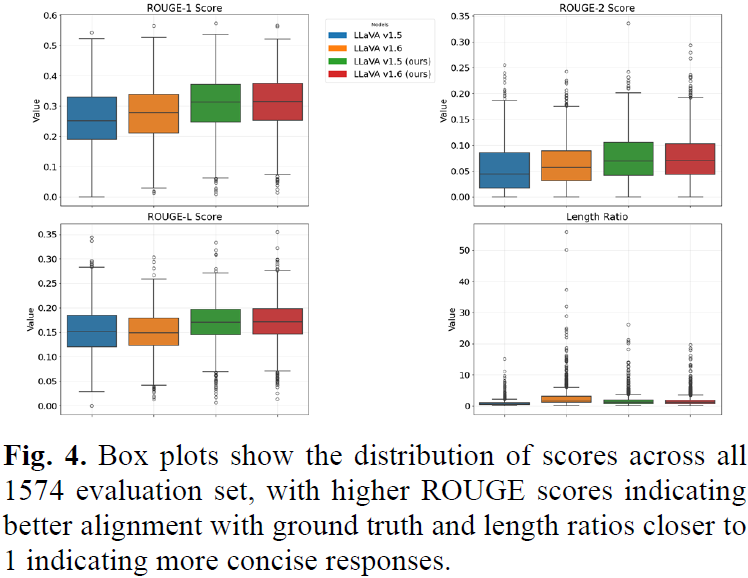
语言不确定性分析:LLaVA v1.6 在测试集中使用 "appears"(可能是)1,451 次,微调模型仅使用 49 次,表明其回答更具确定性和可信度。这说明微调后模型 减少了过度推测和错误信息,提高了回答的可靠性。
5. 结论
本文提出了一种 面向生物医学图像分析的 VLM 微调方法,并构建了新的医学视觉问答(VQA)评测数据集。实验结果表明,微调后的模型在 多模态理解、医学推理、减少幻觉 方面均有显著提升。研究为 AI 在医疗影像分析领域的应用 提供了新思路,有望推动 智能医疗助手、自动影像诊断 等方向的发展。
未来研究方向:
- 扩展至更多生物医学应用(如 X-ray、MRI 诊断、病理学图像分析)。
- 与真实临床数据结合,测试模型在实际医疗场景中的适用性。
- 优化数据生成方法,减少自动合成数据带来的偏差,提高数据质量。
- 探索多模态融合策略,结合 文本、图像、视频、基因数据 进行联合分析。
论文地址:https://arxiv.org/abs/2501.15370
进 Q 学术交流群:922230617

















 120
120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









