







HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale

目录
1. 引言
多模态大语言模型(如 GPT-4V)在医学领域的表现受限,主要原因包括:
- 医学视觉知识数据规模小且质量不稳定;
- 医学数据的隐私和授权问题;
- PubMed 尽管提供了大量去标识化的医学图像和文本,但数据噪声严重,影响模型性能。
为解决数据隐私和高标注成本导致的医学视觉-文本数据稀缺问题,本文从 PubMed 中提炼医学图像-文本对,利用 GPT-4V 进行 “非盲” 数据去噪和重格式化,构建了包含 130 万条医学视觉问答样本的 PubMedVision 数据集。
实验证明,PubMedVision 显著提升了 MLLM 的医学多模态能力,并基于该数据集训练了 34B 参数的 HuatuoGPT-Vision 模型,在多个医学多模态基准测试中表现突出。
1.1 关键词
多模态大语言模型(MLLMs)、医学视觉知识、PubMedVision、HuatuoGPT-Vision、数据去噪、视觉问答(VQA)、医学多模态能力、数据集构建、医疗图像、GPT-4V
2. 医学视觉对齐在 MLLM 中的应用
2.1 现有医学 VQA 数据
现有数据集如 VQA-RAD、SLAKE 等规模小且集中于放射学,LLaVA-Med 等数据集尽管利用了 PubMed,但数量有限且存在视觉信息缺失和误解的问题。PubMedVision 目标是构建更大规模、更高质量的医学 VQA 数据集。
2.2 数据工程视角下的医学视觉对齐
视觉知识对齐:MLLM 通过视觉编码器注入医学图像知识,实现图像与语言理解的对齐。
PubMed 数据噪声:PubMed 文本描述与图像不总是准确对应,影响视觉对齐效果。
提高数据质量的努力:本文提出使用 MLLM 进行重格式化(MLLM-Reformatted),比仅使用文本 LLM 生成描述的方法更准确。
- 原始数据并不总是适合用于训练
- 与 PubMed 中的 原生描述(Native Captions)相比,现有工作使用 仅文本LLM 对图像的标题进行重格式化,称为 LLM 重格式化(LLM-Reformatted),这可能导致对图像的误解或文本与图像的不匹配,因为LLM是 “盲” 的(无法直接感知图像)。
- 为了解决这个问题,我们提出使用 多模态 LLM,称为 MLLM 重格式化(LLM-Reformatted)。
- 此外,我们还将其与 GPT4v-蒸馏(GPT4v-Distill)进行比较,这是在通用多模态领域中蒸馏GPT-4V的一种流行方法,例如ShareGPT4V 和ALLaVA-4V。在GPT4v-蒸馏方法中,我们仅向GPT-4V提供图像以生成医学描述。
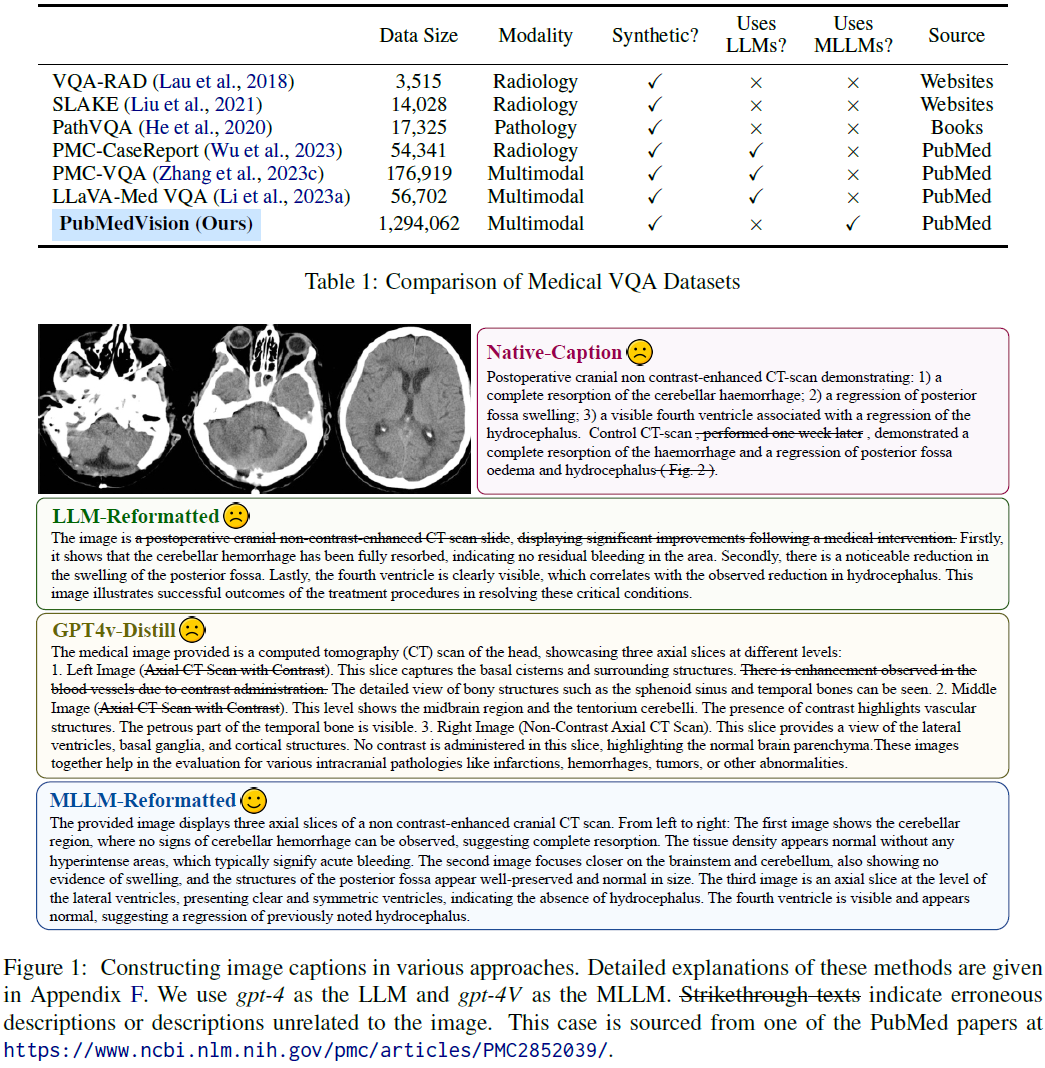
案例分析。图 1 展示了这些方法生成的示例。它表明:
- 原生描述(Native-Caption)存在歧义,并包含与图像无关的内容。
- LLM 重格式化(LLM-Reformatted)将三张子图误解为一张 CT 切片,导致描述具有误导性,且未能排除无关内容。
- GPT4v-蒸馏(GPT4v-Distill)由于缺乏上下文文本,生成了事实性错误的描述。
- 相比之下,MLLM 重格式化(MLLM-Reformatted)通过利用视觉信息和上下文线索,生成了更优质的描述,准确且完整地描述了图像的关键信息。
3. PubMedVision 数据集
3.1 数据收集
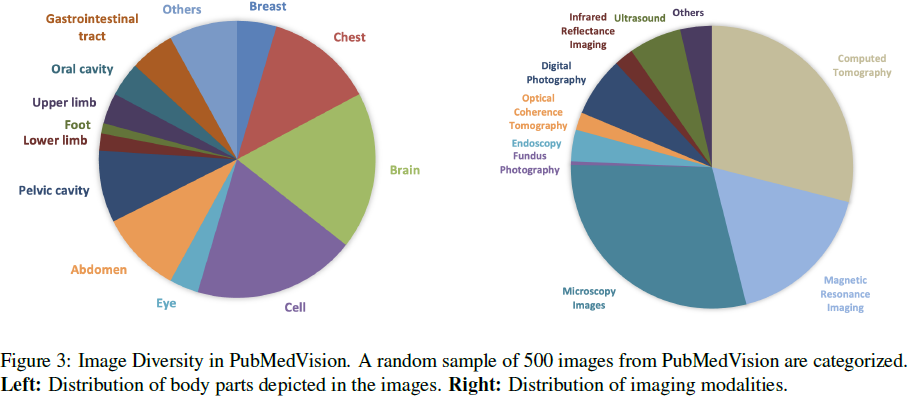
整合了 LLaVA-Med PMC、PMC-Inline 和 PMC-OA 数据,通过医学词汇过滤、低分辨率图像剔除、语义去重等步骤,最终筛选出 91.4 万张医学图像及其文本,构建 130 万条 VQA 数据。
3.2 MLLM 重格式化
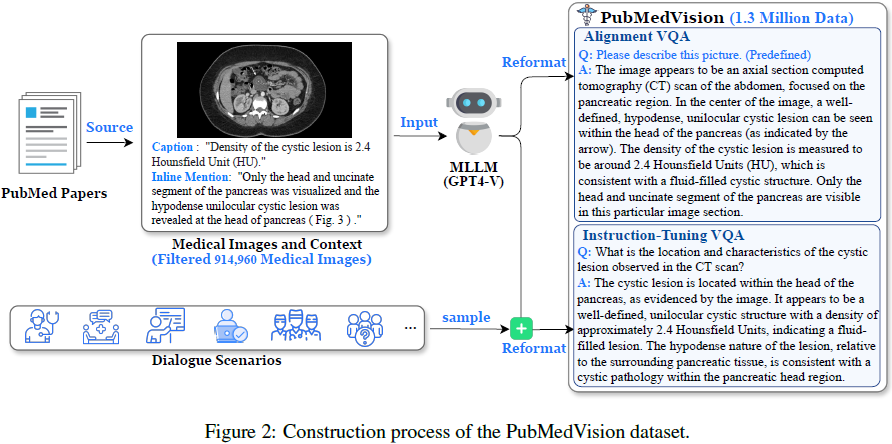
使用 GPT-4V 根据输入图像和语境文本生成详细的医学图像描述 d、图像特定问题 q 和相应答案 a(如图 2 所示),覆盖多种医疗场景(如医生与患者对话、医生间讨论、AI 辅助等)。
PubMedVision 包含 64.7 万条对齐 VQA 和 64.7 万条指令调优 VQA 数据。
对齐 VQA(Alignment VQA)。我们预定义一个问题 q′,并将其与图像描述 d 结合起来形成对齐 VQA (q′, a)。这种详细的图像描述有助于学习从图像到文本的对齐。
- 对齐 VQA 基于生成的图像描述 d 和从预定义问题集中采样的问题 q′。
- 如果涉及多张图像,则从多图像问题集(图 8)中采样 q′,否则从单图像问题集(图 7)中采样。


指令调整 VQA(Instruction-Tuning VQA)。我们使用 MLLM 生成的问题 q 和答案 a 作为指令调整 VQA (q, a),以增强指令遵循能力和图像理解能力。
- 与对齐 VQA 不同,问题是由 MLLM 专门针对图像生成的。
- 为了使生成的 q 多样化,我们设计了八种不同的场景(示例见原文附录 D)。我们将场景设置随机抽样到合成提示中,以使 MLLM 能够生成更多不同的问题。
- 标准问答场景提示:制作标准问答场景的指南。
- 医生与患者家属场景提示:一位关心的家属向医生询问患者的病情。
- 医生与医生场景提示:医生之间就医学图像进行专业讨论的场景。
- 实习生与专科医生场景提示:实习生提出问题,专科医生根据医学图像提供详细、翔实的答案的模拟对话。
- 医学教师与学生场景提示:模拟教育互动,教师提示学生分析医学图像并提出可能的诊断。
- 资深医生与实习生场景提示:资深医生通过基于医学图像的问题测试实习生的观察和分析能力的模拟对话。
- 医生和难缠患者场景提示:模拟对话,医生耐心地向持怀疑态度的患者传达诊断结果,使用图像数据以易于理解的方式解释病情,并解决所有疑问以建立信任。
- 评估者和人工智能模型场景提示:模拟交互,质量控制团队成员评估人工智能模型分析复杂医学图像的能力。
- 人工智能模型协助医生场景提示:模拟对话,医生咨询人工智能模型有关医学图像中的细节,以提高诊断准确性。
- 人工智能模型协助患者场景提示:模拟对话,人工智能模型解释患者医学图像上的细节,旨在澄清患者的疑问,同时强调最终解释由专业医生做出。
4. 实验
4.1 实验设置
采用 LLaVA-1.5 架构与 LLaMA-3-8B 进行训练,比较了只用 LLaVA 数据、结合 LLaVA-Med 数据和结合 PubMedVision 数据的模型性能。
4.2 PubMedVision 的有效性
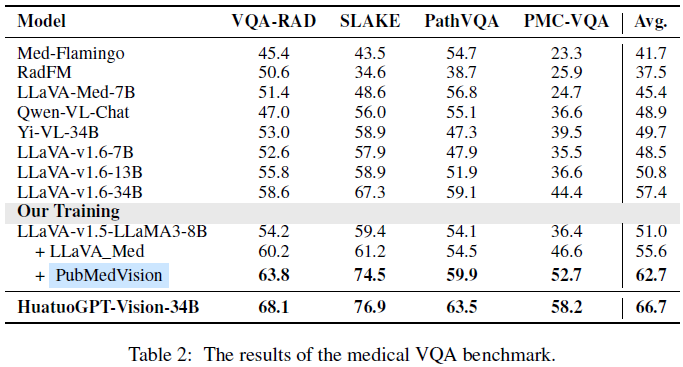
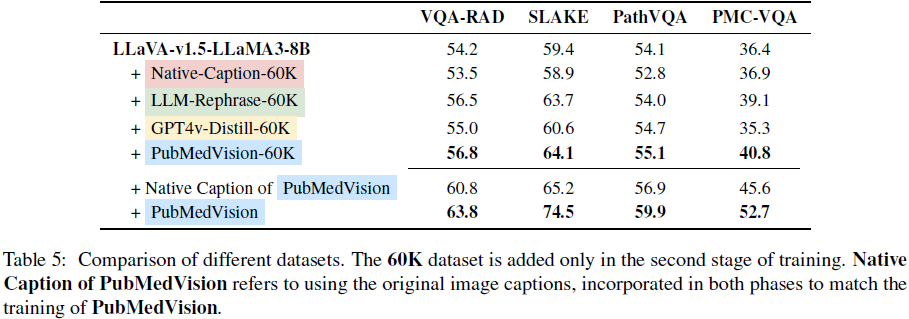
医学 VQA 基准:PubMedVision 使模型在 VQA-RAD、SLAKE 等基准上提升 11.7% 准确率,优于 LLaVA_Med。
OmniMedVQA 评估:在 8 种医学成像模式上,PubMedVision 训练的模型提高了 26.3% 准确率。
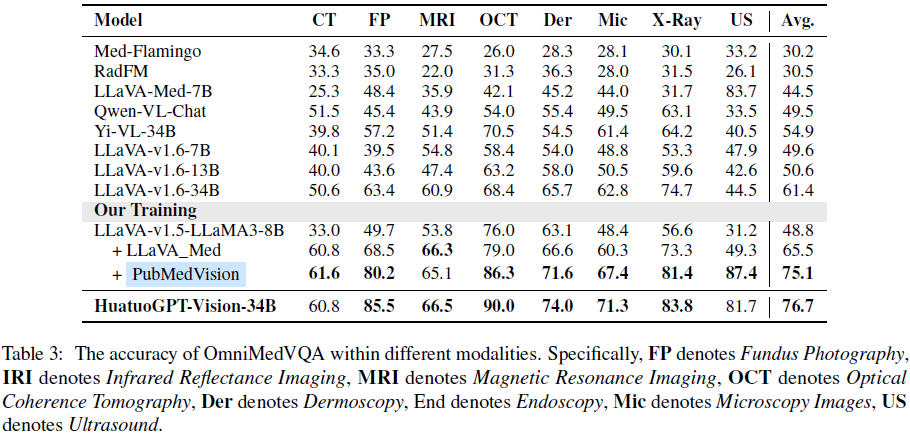
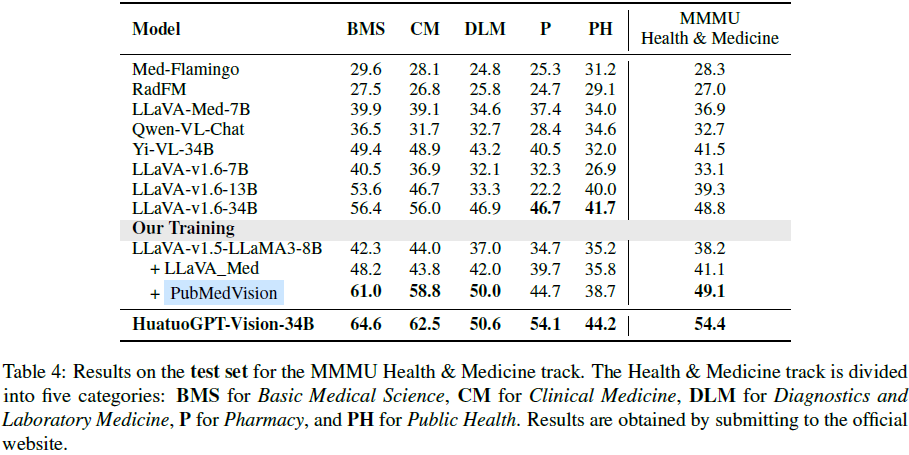
MMMU 医学赛道:PubMedVision 使模型在 MMMU 健康与医学赛道上超越其他开源模型,接近更大参数模型的性能。
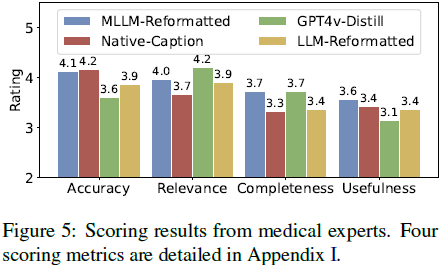
4.3 数据质量
专家评分显示,MLLM-Reformatted 方法在准确性、相关性、完整性和实用性上均表现最佳,验证了 PubMedVision 数据的高质量。
5. 相关工作
5.1 多模态大语言模型
近年来,多模态大语言模型(MLLMs)的发展利用了 LLaMA 等 LLM 的能力,将视觉特征集成到文本空间中。值得注意的是,
- Flamingo(Alayrac等,2022)通过在 LLM 中引入交叉注意力层来整合视觉特征。
- 为有效对齐多模态特征,BLIP2(Li等,2023b)通过创新的 Q-former 将预训练的视觉编码器与 LLM 集成。
- InstructBLIP(Dai等,2024)进一步通过引入指令跟随数据提升了模型性能。
- 顺应这一趋势,LLaVA(Liu等,2024)及后续的 MLLM(Zhu等,2023;Ye等,2023)利用高质量的多模态数据进行指令调优,显著提升了表现。
- 此外,ALLVA(Chen 等,2024)展示了即使是一个小型模型(3B),在高质量的视觉问答(VQA)数据支持下也能取得令人印象深刻的成果,凸显了多模态数据的重要性。
5.2 医学 MLLM
受 ChatDoctor(Yunxiang等,2023)、MedicalGPT(Xu,2023)、HuatuoGPT(Zhang等,2023a;Chen等,2023a)和 Apollo(Wang等,2024)等医学 LLM 成功的鼓舞,研究者们一直致力于开发能够理解医学图像的医学多模态LLM。
- Med-Flamingo(Moor等,2023)将 Flamingo 扩展到医学领域,通过医学多模态数据进行预训练。
- LLaVA-Med(Li等,2023a)通过筛选 PubMed 论文中的图像-文本对和较小的 LLM 合成 VQA 数据集,基于 LLaVA 的参数训练了一个医学 MLLM。
- 此外,Zhang 等(2023c)通过在 PMC-OA(Lin等,2023)上进行自我指令,创建了 PMC-VQA 数据集,用于医学 VQA,并基于此开发了 MedVInT。
- RadFM(Wu等,2023)整合了大量医学多模态数据,包括 2D 和 3D 放射学图像,构建了一个放射学 MLLM。然而,最近的研究(Hu等,2024)表明,当前的医学模型在医学多模态应用中仍落后于通用医学模型,凸显了需要更高质量的数据集来推动医学多模态应用。
5.3 医学 VQA 数据集
为了提升图像-文本对齐并开发医学多模态聊天机器人,研究者们专注于构建医学 VQA 数据集。
- QA-RAD(Lau等,2018)、SLAKE(Liu等,2021)和 Path-VQA(He等,2020)是最早的医学VQA数据集之一。然而,它们的样本规模较小(少于2万条),且多样性有限,主要集中在放射学领域。
- 随后,PMC-VQA(Zhang等,2023c)通过使用 PubMed 论文中的图像-文本数据并使用 LLM 将其重写为 VQA 格式,扩展了数据集规模。
- LLaVA-Med VQA(Li等,2023a)的数据来自筛选 PMC-15M(Zhang等,2023b)中的高质量数据,并使用 LLM 合成 VQA。
- PMC-CaseReport(Lau等,2018)从 PubMed 中筛选案例图像并使用 LLM 生成 VQA,尽管它仅保留了放射学模式图像。目前,仍需要更全面和更大规模的医学 VQA 数据集。
6. 结论
本文通过 MLLM 驱动的重格式化方法,从 PubMed 中提炼高质量医学视觉数据,构建了大规模的 PubMedVision 数据集,显著提升了医学 MLLM 的多模态能力,并训练了性能卓越的 HuatuoGPT-Vision 模型。
未来工作需关注 MLLM 的幻觉问题、数据场景多样性、选择偏差及医学专业覆盖范围。
论文地址:https://aclanthology.org/2024.emnlp-main.418/
项目页面:https://github.com/FreedomIntelligence/HuatuoGPT-Vision
进 Q 学术交流群:922230617 或加 V:CV_EDPJ 进 V 交流群

















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









