







How Much Knowledge Can You Pack into a LoRA Adapter without Harming LLM?

目录
1. 引言
大语言模型(LLM)因其在众多任务中的卓越表现而被广泛应用,但其性能受限于预训练期间学到的知识。LoRA(Low-Rank Adaptation)是一种流行的高效训练技术,可用于调整 LLM 以适应特定领域。然而,在使用 LoRA 注入新知识的过程中,可能会损害模型先前学到的知识。
本文通过对 Llama-3.1-8B-Instruct 进行 LoRA 微调,并控制新知识的数量,研究如何平衡新知识的引入与模型整体能力的保持。
研究发现,
- 混合已知与新知识的数据可获得最佳结果,但仍会导致模型在外部问答基准测试上的性能下降。
- 当训练数据偏向某些特定实体时,模型可能倾向于生成过度集中的答案。
- LoRA 训练的模型更倾向于自信地给出答案,并较少拒绝回答。
研究结果突出了 LoRA 适配器的潜在风险,并强调了训练数据的构成和参数调优对平衡新知识整合与保持模型能力的重要性。
2. 相关工作
LLM 的性能在处理长尾事实(long-tail facts)时存在不足,这使得非参数化知识(如检索增强生成 RAG)或知识的直接整合成为可能的解决方案。然而,RAG 需要外部知识库支持,且可能会影响 LLM 原有的内部知识。
在知识更新方面,LoRA 作为一种冻结预训练权重并在 Transformer 层中注入可训练低秩矩阵的技术,被认为是高效的解决方案。然而,LoRA 也存在“灾难性遗忘”问题,可能导致模型对先前学习的知识丧失。此外,许多当前的知识编辑方法在准确性、召回率(recall)和幻觉率之间存在权衡。
3. 研究设计
研究主要评估 LoRA 适配器的知识集成能力及其对模型整体性能的影响。
LoRA 适配原理:LoRA 通过低秩分解方法更新模型的权重矩阵 W:
- W = W_0 + ΔW = W_0 + BA
- 其中 B 和 A 为低秩矩阵,确保可训练参数量远低于完整模型微调。
知识分类:
- 已知知识(HighlyKnown, HK):模型在不同提示下始终能正确回答的问题。
- 可能已知知识(MaybeKnown, MK):模型在不同提示下有时会正确回答的问题。
- 未知知识(Unknown, UK):模型在任何提示下均无法正确回答的问题。

模型可靠性: 研究考察模型在多轮知识编辑后的稳定性,即是否仍然能够保持先前的编辑,并评估知识获取的可靠性。
不良效应评估: 采用 TruthfulQA 和 MMLU 基准评测模型的推理能力与真实度,以观察 LoRA 训练是否会损害原始模型的能力。
4. 实验
实验使用 Llama-3.1-8B-Instruct 进行 LoRA 训练,重点评估模型对未知知识的学习情况及其对整体性能的影响。
数据构建:
- 训练数据基于 DBpedia 知识图谱生成,包括 <主语,关系,宾语> 三元组,并确保这些数据未包含于 LLM 预训练语料中。
- 采用 TriviaQA 数据集生成额外的 HighlyKnown 样本,以帮助测试模型在已知知识上的表现。
微调策略:
- 训练数据包含 1、10、50、100、500、3000 个未知知识样本(q,a)。
- 仅根据新知识对 LoRA 进行微调具有挑战性。可用合成数据扩充(augment)训练数据集,包括 0、1、10 个已知知识样本或问题(q)的同义改写
评估方法:
- 使用 5-shot 方式评估 MMLU(知识与推理能力)。
- 使用 0-shot 方式评估 TruthfulQA(真实性)。
- 计算知识转变(Knowledge Shifts):
- 正向转变(Positive shift):如 UK → HK 或 MK → HK。
- 负向转变(Negative shift):如 HK → UK 或 HK → MK。
5. 分析
研究分析了 LoRA 训练对知识获取和保持的影响。
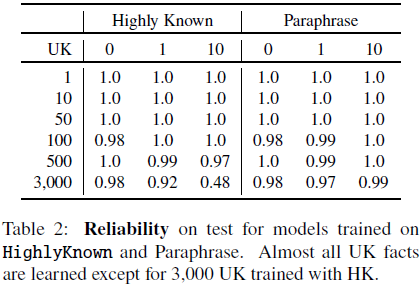
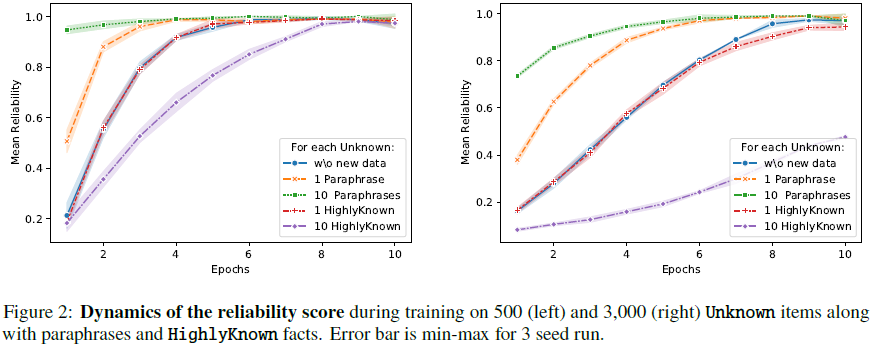
准确性(Accuracy):
- 模型最多可学习 500 个未知样本,而 3000 个未知样本的训练需要更多轮次才能收敛。
- 在少量未知数据(≤100)的情况下,加入 HighlyKnown 样本有助于减少负向转变。
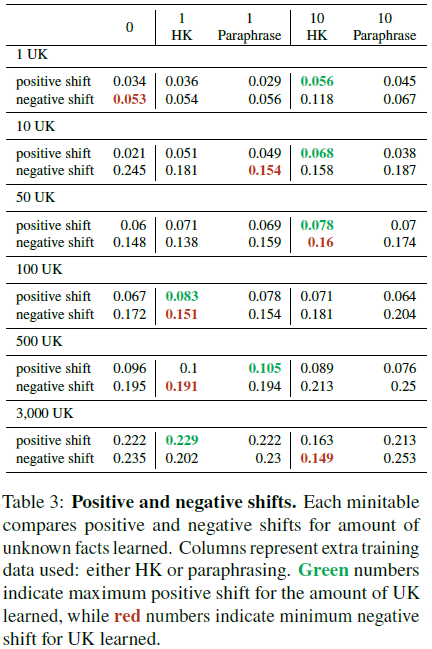
知识转变(Knowledge Shifts):
- 负向转变(丢失知识)通常比正向转变(学习新知识)更频繁。
- 添加 HighlyKnown 数据可有效减少负向转变。
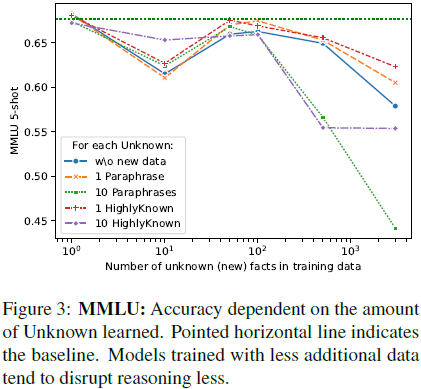
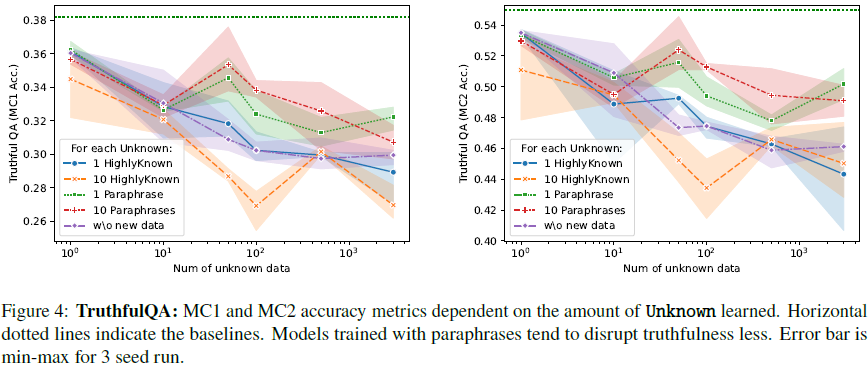
基准测试结果(Benchmarks):
- LoRA 训练通常会导致 MMLU 评测成绩下降,尤其是加入过多 HighlyKnown 或 Paraphrase 样本时。
- TruthfulQA 评测中,训练数据包含更多 Paraphrase 样本的模型表现较佳,表明 LoRA 训练可能影响模型的真实性回答能力。
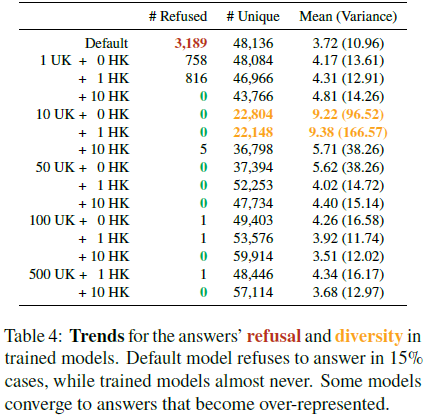
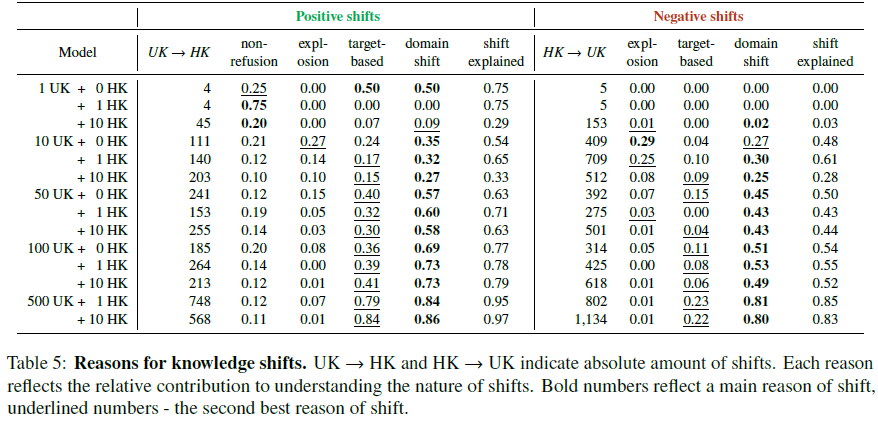
解释知识转变的原因:
- LoRA 训练后的模型更少拒绝回答问题(从 15% 降至接近 0%)。
- 训练后的模型可能会偏向生成某些特定答案(即 “答案爆炸” 现象)。
6. 额外实验:Mistral
为了验证 LoRA 适配器的影响是否适用于其他 LLM,研究对 Mistral-7B-Instruct-v0.3 进行了相同的实验。
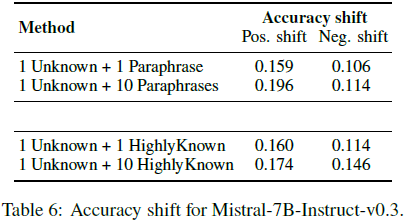
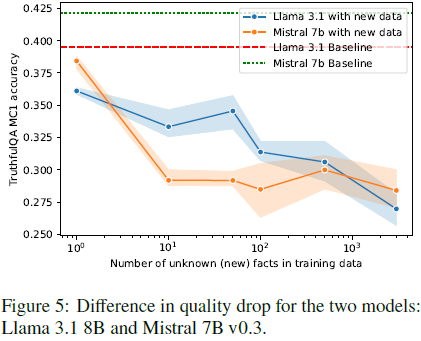
结果显示:
- 知识转变趋势相似,即 HighlyKnown 样本的加入有助于减少负向转变。
- 模型质量下降趋势相同,随着训练数据中新知识的增加,Mistral 7B 也出现类似的性能下降。
7. 结论
研究表明:
- 结合未知与已知知识的训练数据可优化知识学习效果,但可能损害模型的整体能力。
- 少量新知识的引入可能导致大幅推理能力下降(MMLU 下降)。
- LoRA 训练后的模型更倾向于自信作答,甚至在不确定情况下也会强行生成答案。
- LoRA 训练可能使模型在某些问题上产生 “答案爆炸”,即频繁重复某些特定答案。
论文地址:https://arxiv.org/abs/2502.14502
项目页面:https://github.com/AIRI-Institute/knowledge-packing
进 Q 学术交流群:922230617 或加 V:CV_EDPJ 进 V 交流群
合作联系同上,请备注说明

















 3474
3474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









