







Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control
目录
1. 引言
多模态可控世界生成旨在通过分割、深度、边缘等模态视频输入,在不同时间和空间生成目标世界视频。该能力可减小 CG 模拟器的 “合成-真实” 域差,使生成的世界更真实且保持结构和语义一致。
本文提出 Cosmos-Transfer1,是一个基于扩散模型的条件世界模型,拓展自 Cosmos-Predict1,核心为 DiT(Diffusion Transformer)。通过 ControlNet 机制为每种模态增加独立控制分支,每个分支单独训练,推理时融合。该模型的关键是其空间-时间自适应控制图,可在不同位置、时刻分配不同模态的权重,赋予用户高度控制能力。
我们在多个物理 AI 任务上评估了 Cosmos-Transfer1,包括机器人 Sim2Real 和自动驾驶数据增强,并展示其在 NVIDIA GB200 NVL72 上的实时生成能力。
(2025,Cosmos,世界基础模型 (WFM) 平台,物理 AI,数据处理,分词器,世界基础模型预训练/后训练,3D一致性)
(2023|ICCV,DiT,扩散 transformer,Gflops)使用 Transformer 的可扩展扩散模型
(2023,ControlNet,CFGRW,diffusion,控制组合)向文本到图像扩散模型添加条件控制
1.1 关键词
多模态(Multimodal)、控制图(Control Map)、扩散模型(Diffusion Model)、机器人Sim2Real(Robotics Sim2Real)、自动驾驶(Autonomous Driving)、生成质量(Generation Quality)
2. 预备知识
扩散模型核心为去噪器(denoiser),在 Cosmos 中通过 DiT 实现。如图 1(a) 所示,DiT 由一系列 Transformer 组成,训练目标是预测输入视频 token 上的加性噪声,即 n = D(x_σ,σ)
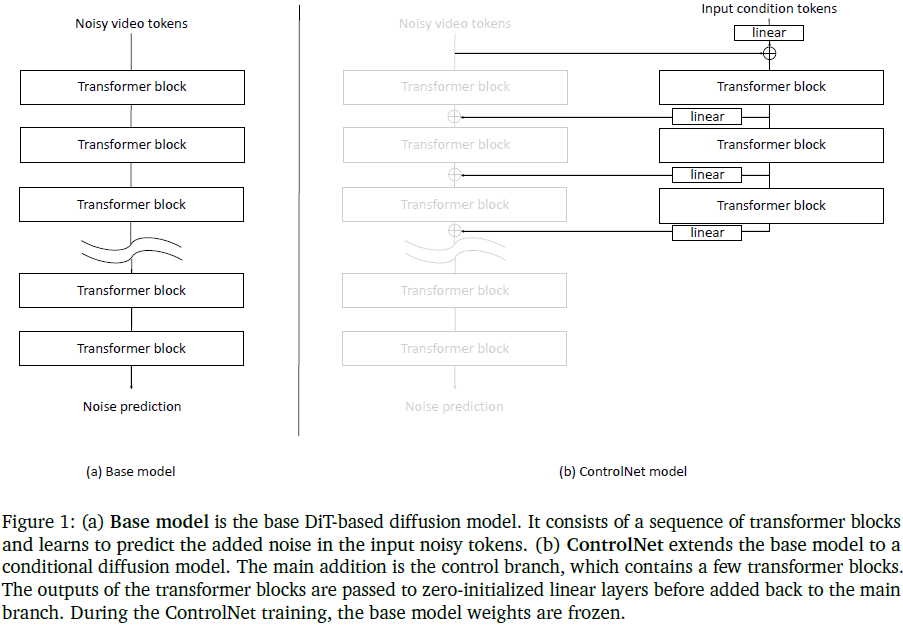
为实现条件控制,本文借鉴了 ControlNet 设计(原用于 UNet),并将其拓展至 DiT 架构。ControlNet 包含一个控制分支,接收模态输入并通过 Transformer 提取条件特征,再通过线性层融合至主干模型。训练时主干模型权重冻结,仅训练控制分支,最终实现条件去噪:
n = D(x_σ,σ,c),其中 c 为条件 token。
每个模态配有一个独立控制分支,推理时将多分支输出融合,支持多模态输入与控制。
3. 方法
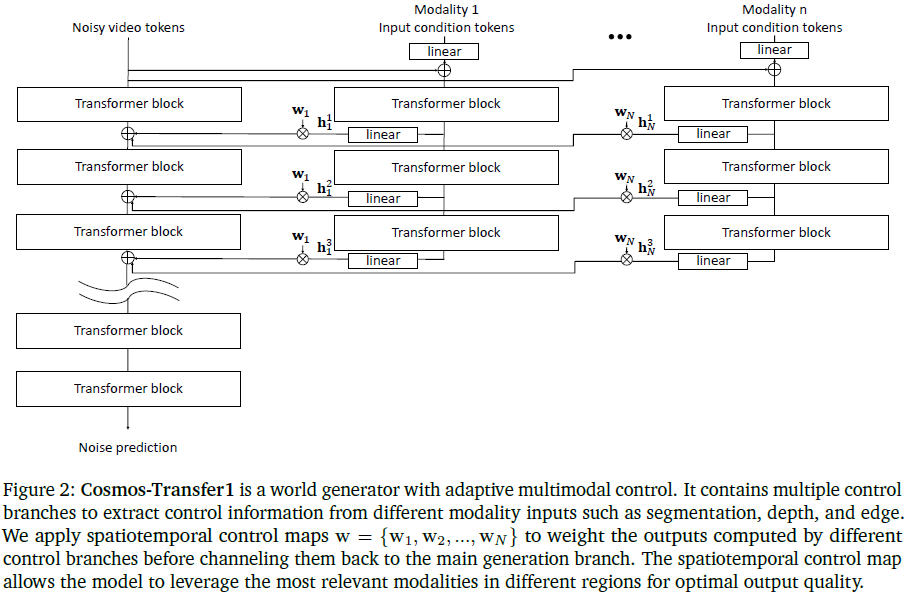
Cosmos-Transfer1 通过 对 Cosmos-Predict1 模型的后训练(post-training)构建,支持任意数量模态输入 c_1, c_2, ..., c_N。每个模态控制分支独立训练,仅在推理时融合。
模型引入 空间-时间控制图 w ∈ R^{N×X×Y×T},定义每模态在不同空间(X,Y)和时间(T)的影响力。控制图用于加权每个模态分支的激活值 h^j_i ∈ R^{X×Y×T},最终以 w_i ⋅ h^j_i 的形式融合到主分支。
控制图可手动设计、基于启发式规则或通过神经网络自动学习。
为了提升训练效率和灵活性,控制分支分别训练。该方法相比于直接训练所有分支有如下优势:
- 节省显存,仅需加载一个分支。
- 支持模态间数据不一致性。
- 推理时可动态添加/移除模态。
4. 模态与训练
我们实现了两个主要模型版本:
1)Cosmos-Transfer1-7B:通过后训练 Cosmos-Predict1-7B-Video2World 获得
2)Cosmos-Transfer1-7B-Sample-AV:专为自动驾驶设计,从 Cosmos-Predict1-7B-Video2World 的微调版本(Cosmos-Predict1-7B-Video2World-Sample-AV)上进行后训练获得
每个控制分支均在 1024 张 H100 GPU 上训练 2-4 周,生成视频为 5 秒 1280×704@24fps,对应约 56K token。支持模态如下:
- Blur Visual(Vis):对原视频施加双边模糊,保留色彩结构,适用于纹理增强。
- Edge:使用 Canny 边缘提取,强调结构线条,增强创意生成。
- Depth:由 DepthAnything2 提取深度图,保持场景 3D 几何。
- Segmentation(Seg):用 GroundingDino+SAM2 提取语义分割,保持语义布局。

在自动驾驶模型中,新增模态包括:
- HDMap:通过城市级 LiDAR 地图构建,提供精细道路布局信息。
- LiDAR:由多帧融合补齐的稠密点云投影图,保留精细语义细节。

此外,还训练了一个上扩展 ControlNet 4KUpscaler,用于将 720p 视频放大至 4K,提升细节和真实感。

5. 评估
本节对 Cosmos-Transfer1 进行了全面评估,涵盖不同控制配置下的性能表现,并通过多个真实任务场景(如机器人 Sim2Real 和自动驾驶)进行验证。
TransferBench 评估集:
我们构建了名为 TransferBench 的基准数据集,包含 600 个示例,分布在三大场景中:
-
机器人操作(200条):来自 AgiBot World 数据集,聚焦精细操作和物体交互;
-
自动驾驶(200条):采自 OpenDV 数据集,涵盖复杂交通环境中的动态决策;
-
第一人称日常生活场景(200条):取自 Ego-Exo-4D 数据集,专注于人类中心感知。
此评估覆盖结构化与非结构化环境,能全面衡量 Cosmos-Transfer1 在物理智能任务中的表现。
评估指标:
1)控制信号对齐性
-
Blur(SSIM):模糊处理后与原视频结构相似性,值越高越好;
-
Edge(F1):Canny 边缘检测后的 F1 得分,衡量结构线条的一致性;
-
Depth(si-RMSE):深度图之间的缩放不变 RMSE,值越低越好;
-
Seg(mIoU):语义分割结果的平均交并比(IoU),用于衡量语义一致性。
2)生成多样性:对于相同条件输入但不同文本提示生成的视频,通过 LPIPS 比较不同文本提示生成结果差异。
3)整体质量:用 DOVER 技术评分评估视觉美学质量。
5.1 单模态与多模态比较
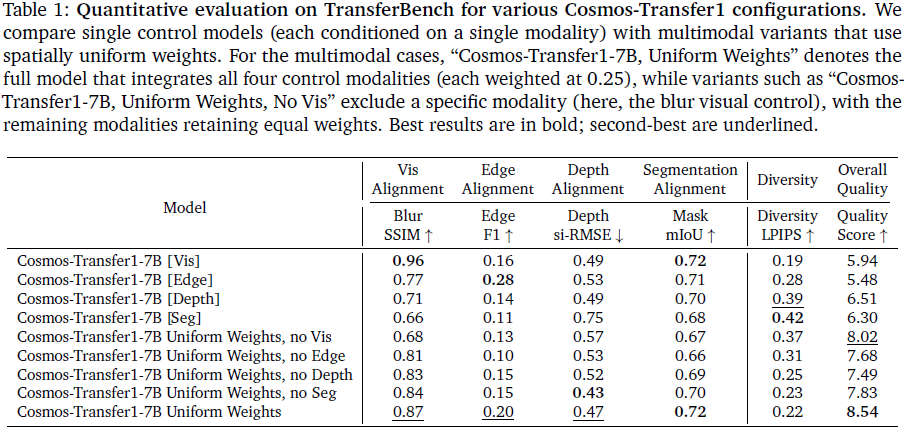
我们先比较单一模态控制模型与多模态控制模型(使用统一空间权重)的性能。
单模态模型表现:
-
Vis 模型在 Blur SSIM 上得分最高(0.96),善于保留整体结构与色彩;
-
Edge 模型在 Edge F1 上最高(0.28),适合细节结构生成;
-
Depth 与 Seg 控制分别在 si-RMSE 和 mIoU 上表现适中;
-
Seg 模型生成最具多样性(Diversity-LPIPS 0.42),但结构保真度较低。
去除某一模态的多模态模型:
-
去掉 Vis 模态后 Blur SSIM 明显下降(0.68);
-
去掉 Edge 后结构对齐减弱;
-
去掉 Depth 或 Seg 后,多样性得分下降,反映这两者对自由度影响大。
融合所有模态模型:
-
在所有指标中取得均衡表现(Blur SSIM 0.87,Edge F1 0.20,Depth si-RMSE 0.47,Seg mIoU 0.72);
-
整体质量评分最高(8.54),说明融合控制对生成质量提升显著。
结论:单模态适合特定任务,多模态控制提供更均衡、更高质量的生成能力。
5.2 时空控制图案例
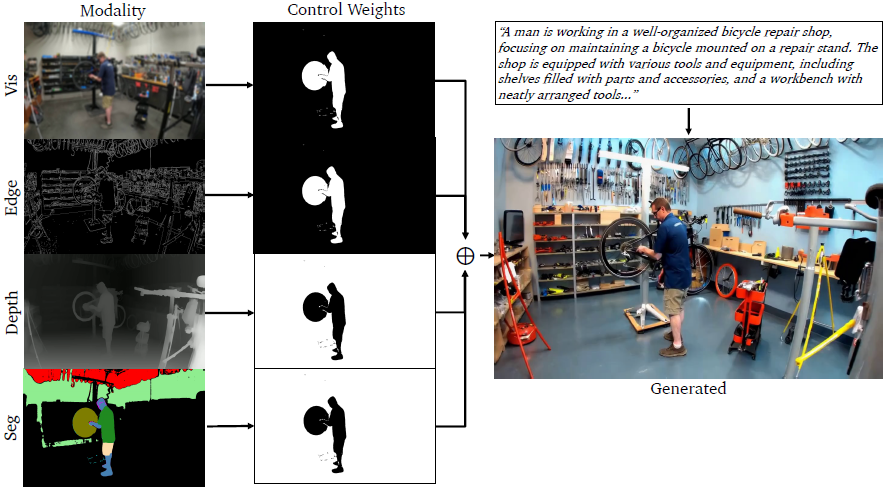
图 6:不同模态(Vis、Edge、Depth 和 Segmentation)下的时空控制加权示意图。
- 控制加权图中,黑色像素区域的权重为 0.0,白色区域的权重为 0.5。
- 我们注意到,尽管标题(caption)仅宽泛描述了一个自行车维修店的场景,但由于蓝色带有白色标志的衬衫以及人物肤色区域受 Vis 和 Edge 控制,这些细节被保留了下来。
- 相比之下,背景区域由 Depth 和 Segmentation 控制,其位置布局保持一致,但颜色和纹理被随机化(例如:红色工具箱、黄色三脚架、白色维修架)。
- 此外,模型还在右侧墙上添加了一个新的工具架。
为进一步提高生成控制的灵活性,我们引入 “SalientObject” 方法构建前景-背景(foreground-background)控制图。具体步骤如下:
-
通过 VLM 模型判断 SAM2+GroundingDINO 的分割掩码属于前景还是背景;
-
为前景分配 Vis 与 Edge 控制(低自由度,确保保真度);
-
为背景分配 Depth 与 Seg 控制(高自由度,增强多样性)。
示例中,前景区域(如人物衣服、肤色)颜色与结构保持一致,而背景区域则随机生成了不同纹理、物体布局等内容,如新增工具架。
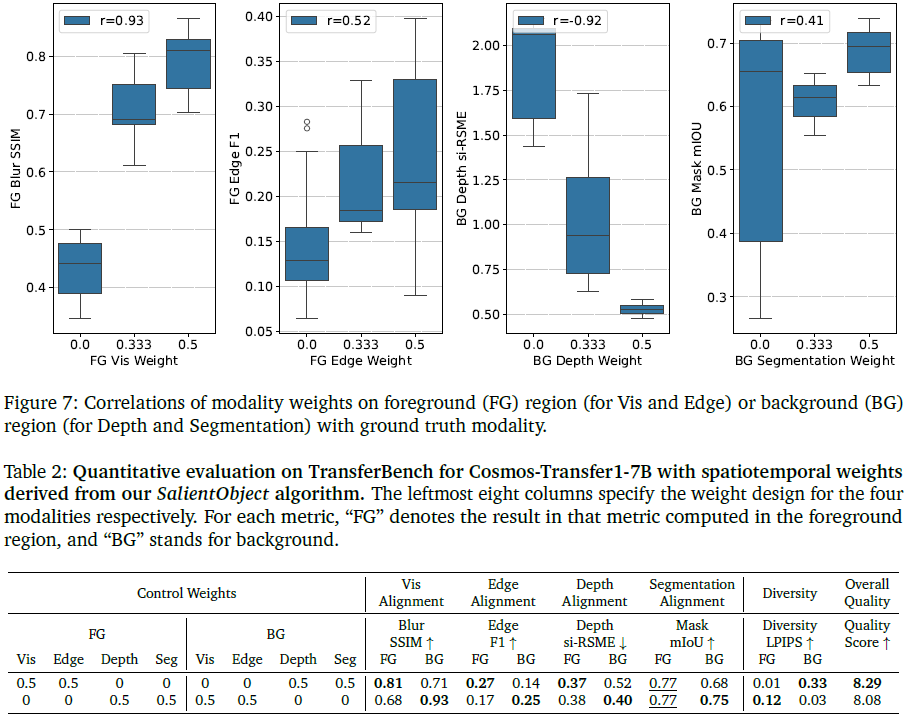
定量实验结果显示:
-
随着前景(FG) Vis/Edge 权重增加,Blur SSIM/Edge F1 在前景区域显著提升;
-
背景(BG)区域 Depth 权重越高,si-RMSE 越低,表示更好的几何对齐;
-
多样性在背景区域权重较高时也显著提升,前景受限于约束而多样性下降。
结论:时空控制图可灵活调整生成区域的精细度与自由度,实现局部保真、整体多样的理想平衡。
5.3 机器人 Sim2Real 数据生成案例分析
在机器人研究中,高质量数据对模型性能提升至关重要。尽管模拟环境可以大规模生成数据,但“合成-真实” 域差导致训练模型难以直接应用于现实世界。
为验证 Cosmos-Transfer1 在机器人数据生成中的效果,本文构建了 20 个厨房场景任务,每个任务使用 NVIDIA Omniverse 与 Isaac Lab 生成,任务包括开关橱柜、搬运厨房用品等。每个场景配有 6 个不同文本提示,形成多样化输入。除 RGB 视频外,还生成了深度图与分割图。
模型对比如下:
-
单模态模型(Vis、Edge、Depth、Seg);
-
多模态模型(带自定义时空控制图)两种设置:
-
设置1:前景控制采用 Vis 与 Edge,背景使用 Seg(目标:保留机器人的结构与外观);
-
设置2:前景仅使用 Edge,背景仍为 Seg(目标:保持结构,允许外观变化)。
-
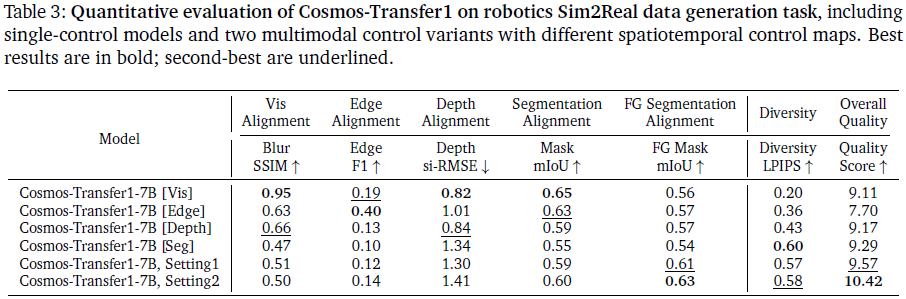
实验结果摘要(见表 3):
-
单模态模型在对应指标上表现突出,例如 Vis 模型 Blur SSIM 为0.95;
-
但多模态设置的整体质量评分更高:设置 2 的质量得分达 10.42,为全部最高;
-
设置 2 的多样性(LPIPS 0.58)与前景一致性(前景 mIoU 0.63)也处于领先;
-
相比单一 Seg 控制,多模态控制可有效减少机器人前景破损现象,提升视频真实感。

图 8:Cosmos-Transfer1 在机器人数据生成任务中的示例结果。
- 左侧列展示了由 NVIDIA Isaac Lab 生成的输入视频,右侧三列则展示了 Cosmos-Transfer1-7B 在不同条件模态与时空控制图配置下生成的结果。
- 每组示例中,上排(single)使用单一模态 “Segmentation” 作为控制信号,整体控制权重为 1;下排则结合了 Segmentation、Edge 和 Vis 三种模态,并应用了时空控制图策略。具体而言,前景区域(机器人部分)使用 Edge、Segmentation 和 Vis 的组合,并分配定制控制权重;而背景区域仅使用 Segmentation,权重为1。
- 结果表明,采用时空控制图的 Cosmos-Transfer1-7B 能更好地保留前景机器人结构的真实感。
5.4 自动驾驶数据增强案例分析
与机器人不同,自动驾驶领域已有大量真实数据,但这些数据呈现 “长尾分布”——大量常规场景、少量关键情况(如极端天气、突发障碍)。因此,增强边缘案例数据具有重要意义。
Cosmos-Transfer1 可用于将实际场景结合控制信号(如 HDMap、LiDAR)和文字描述,生成多样化视觉版本,为测试和训练提供数据增广。

图 9 案例:比较仅使用 Depth、Seg 与两者结合的生成结果:
-
Depth 单独使用时中间车道线缺失;
-
Seg 单独使用时生成的车辆朝向错误;
-
两者结合后能生成车道结构合理、车辆朝向正确的视频。

图10 案例:比较仅用 HDMap(第 1 行)、仅用 LiDAR (第 2 行)与融合控制信号(第 5 行)的效果:
-
(第 3 行)HDMap 控制下车道布局清晰但细节较少;
-
(第 4 行)LiDAR 提供丰富细节(如交通锥)但车道线不准确;
-
(第 5 行)两者结合后兼具结构正确与细节丰富,场景真实性更高。


图 11 与图 12 展示了不同天气与光照场景的生成示例,如雾天、夕阳、雪景与火灾环境。即使训练数据未直接包含这些极端情景,模型依然能利用已有知识生成逼真的视频,反映出强大的泛化能力。
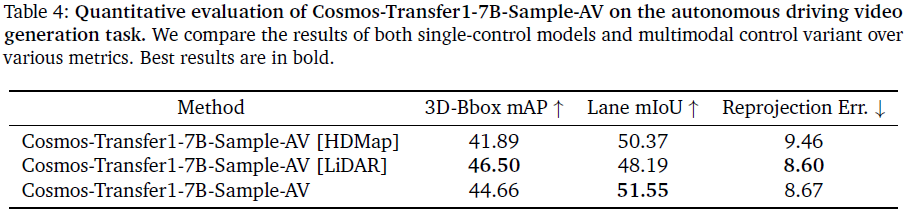
定量评估摘要(见表 4):
-
LiDAR 控制模型在 3D-Bbox mAP(46.50)与 重投影误差(8.60)上表现最佳;
-
HDMap 控制模型在 车道 mIoU 上更优(50.37);
-
融合控制模型在三项指标上均衡,mIoU 最高(51.55),综合性能最佳。
此外,本文还将 Cosmos-Transfer1 与 NVIDIA Omniverse 的 Sensor RTX 模拟系统结合,通过模拟生成 LiDAR 数据,并用训练于真实数据的模型进行控制,取得良好效果。这表明 Cosmos-Transfer1 可用于增强仿真平台的视觉多样性与真实性。
6. 实时推理
本节介绍了如何借助 NVIDIA 的新一代计算平台 GB200 NVL72,实现 Cosmos-Transfer1-7B 模型的实时视频生成。
GB200 NVL72 系统包含:
-
36 个 Grace CPU
-
72 个 Blackwell GPU
-
全部通过 NVLink 网络进行任意对任意(any-to-any)连接
此架构非常适合大模型并行执行,尤其在训练与推理阶段支持的张量并行(Tensor Parallelism)与上下文并行(Context Parallelism)能力,被多个大型基础模型广泛采用。
该架构非常适合模型并行技术,例如张量并行(Tensor Parallelism)和上下文并行(Context Parallelism)。这些技术已被众多大型基础模型采用,包括世界基础模型(World Foundation Models),适用于训练和推理场景。
相比于通常参数量庞大、一次只生成一个 token 的大型语言模型(LLM)不同,Cosmos-Transfer1-7B 模型的参数量较轻,但生成的是整个视频序列(数万个 token),而非单 token 逐步生成。
为提升推理效率,本文采用了如下并行方案:
-
非注意力层使用数据并行(Data Parallelism):每个GPU拥有完整模型副本,处理不同数据;
-
注意力层使用 head 并行(Head Parallelism):每个GPU处理部分 attention head;
-
每个 Blackwell GPU 配备 192GB HBM,可存储完整模型;
-
生成一段 5 秒 720p 视频时,共需处理约 56K token,被均匀划分至各 GPU;
-
注意力操作需 GPU 之间共享完整 token 序列,因此使用 all-to-all 通信机制;
-
模型使用 32个 attention head,并利用 classifier-free guidance 技术分别处理正负提示;通过将正/负条件各自分配给 GPU 子集,可实现完全并行处理。
该策略避免了传统方法中繁琐的 key-value 汇总过程,也提升了内存带宽效率,尤其适用于 Blackwell 架构的高速注意力实现(FMHA)。

表 5 是使用不同数量 GPU 时的性能表现,可以看出:
-
扩散阶段占整体计算负载的 99% 以上;
-
随着 GPU 数量增加,扩散阶段推理时间几乎线性下降;
-
使用 64 张 GPU 时生成5秒视频仅需 4.2 秒,实现 低于实时(sub-realtime)吞吐。
7. 相关工作
本节概述了 Cosmos-Transfer1 所涉及的关键研究方向,并对相关代表性工作进行了分类回顾。主要包括三个方面:视觉域迁移、扩散模型的空间控制机制 和 生成模型用于增强仿真能力。
视觉域迁移(Visual Domain Transfer)。大量研究致力于从抽象视觉表示(如分割图、草图等)向真实感图像或视频的迁移:
-
在图像领域,已有研究将语义分割图或草图转换为高质量图像(如 Dundar et al., Fontanini et al., Huang et al., Wang et al. 等);
-
在视频生成方向,相关工作如 Wang et al.、Esser et al.、Chung et al. 等则将此方法拓展到时间维度,生成结构连贯的视频内容。
这些方法广泛应用于内容创作、虚拟现实、自动驾驶、机器人模拟等多个领域。
扩散模型的空间控制机制(Spatial Control in Diffusion Models)。扩散模型近年来在文本到图像/视频生成方面取得显著进展。为提升空间可控性,研究者提出了多种增强机制,分为两类:
1)无需额外训练的控制方法(Training-free approaches),如 Bansal et al., Chen et al., Xue et al. 提出的遮挡或注意力掩码方法。
2)需在预训练模型基础上微调的新结构(Training-required methods),效果通常优于无训练方法。代表性工作包括:
-
ControlNet(Zhang et al., 2023):通过冻结主干模型,仅训练附加控制分支实现条件控制;
-
随后扩展工作包括 Ju et al., Qin et al., Sun et al., Zhao et al. 等;
-
Chen et al.(2024)将 ControlNet 从 UNet 架构扩展到 Transformer 架构,使其适用于视频生成。
近期也有视频控制相关工作:
-
Lin et al.(2024)将图像级 ControlNet 适配至视频;
-
Jain et al.(2024)提出了利用掩码注意力进行空间视频控制的免训练方法。
用生成模型增强仿真系统(Enhancing Simulation with Generative Models)。实际部署物理智能系统(如机器人或自动驾驶)面临高成本与安全风险,因而仿真至关重要。近年来,生成式 AI 极大提升了仿真系统的真实感与多样性。
1)GAN 时代方法:
-
CycleGAN(Rao et al., 2020)用于改善合成图像的真实感;
-
RetinaGAN(Ho et al., 2021)强调在保留目标信息的同时增强视觉自然性,提升强化学习任务效果。
2)扩散模型方法:
-
Zhao et al.(2024)基于 ControlNet 和扩散模型,将语义图等模拟输出转换为真实感驾驶图像,优于 GAN;
-
Pronovost et al.(2023)基于潜变量扩散模型生成复杂交通情境,提升自动驾驶测试的多样性与危险覆盖。
3)视频级世界模型:NVIDIA(2025)推出的一整套开源世界模型(如 Cosmos 系列),用于机器人控制与场景理解,是对传统仿真系统的重大增强。
8. 结论
Cosmos-Transfer1 是一种具备自适应多模态控制能力的扩散模型,可用于高质量、可控的世界视频生成。其引入的控制分支与时空控制图机制提供了灵活性与精度的平衡。
通过在机器人与自动驾驶领域的广泛评估,展示了其在缩小合成与现实差距、提升多样性和视觉质量方面的优势。其在 GB200 NVL72 平台上的实时推理能力也展示了其实际部署潜力。
论文地址:https://arxiv.org/abs/2503.14492
项目页面:https://github.com/nvidia-cosmos/cosmos-transfer1
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群

















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









