







Qwen2.5-Omni Technical Report
目录
1. 引言
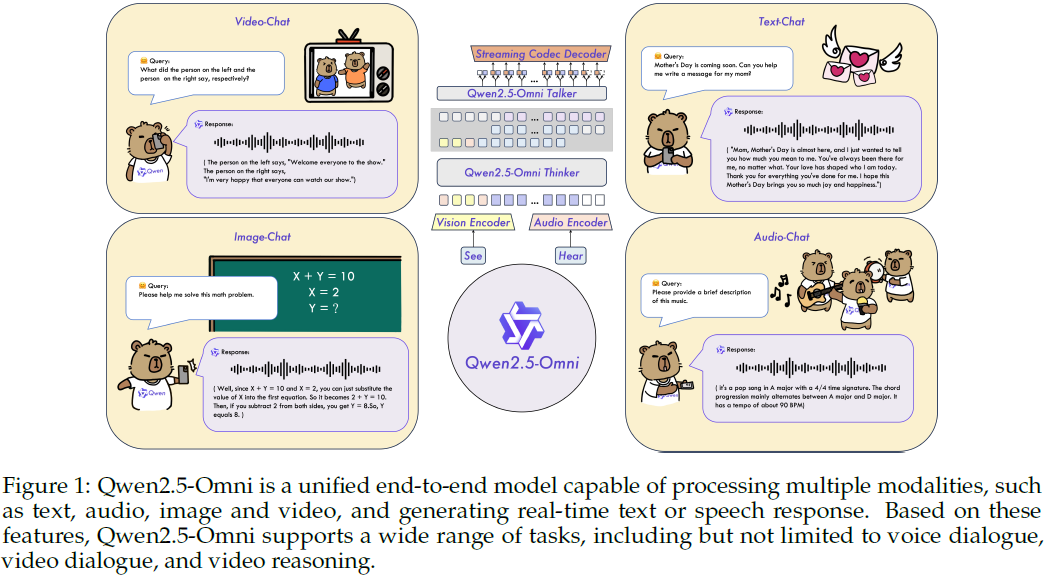
本文提出了 Qwen2.5-Omni,一种端到端多模态模型,能够同时处理文本、图像、音频和视频,并以流式方式生成文本和自然语音响应。为实现多模态信息的实时流式输入,音频和视觉编码器均采用分块处理(block-wise processing),以分担长序列数据的感知和处理任务。
同时,为解决音视频输入的时间同步问题,设计了一种名为 TMRoPE(Time-alignedMultimodal RoPE,时间对齐多模态旋转位置嵌入)的新位置嵌入方法。
为避免文本生成和语音生成之间的干扰,提出了 Thinker-Talker 架构,其中 Thinker 为文本生成模块,而 Talker 为语音生成模块。
Qwen2.5-Omni 在多个多模态基准测试上均达到或超越了同类模型的性能,包括 Omni-Bench 等。
1.1 关键词
多模态模型(Multimodal Model);端到端训练(End-to-End Training);TMRoPE;Thinker-Talker 架构(Thinker-Talker Architecture);流式语音生成(Streaming Speech Generation)
2. 架构
2.1 总体架构
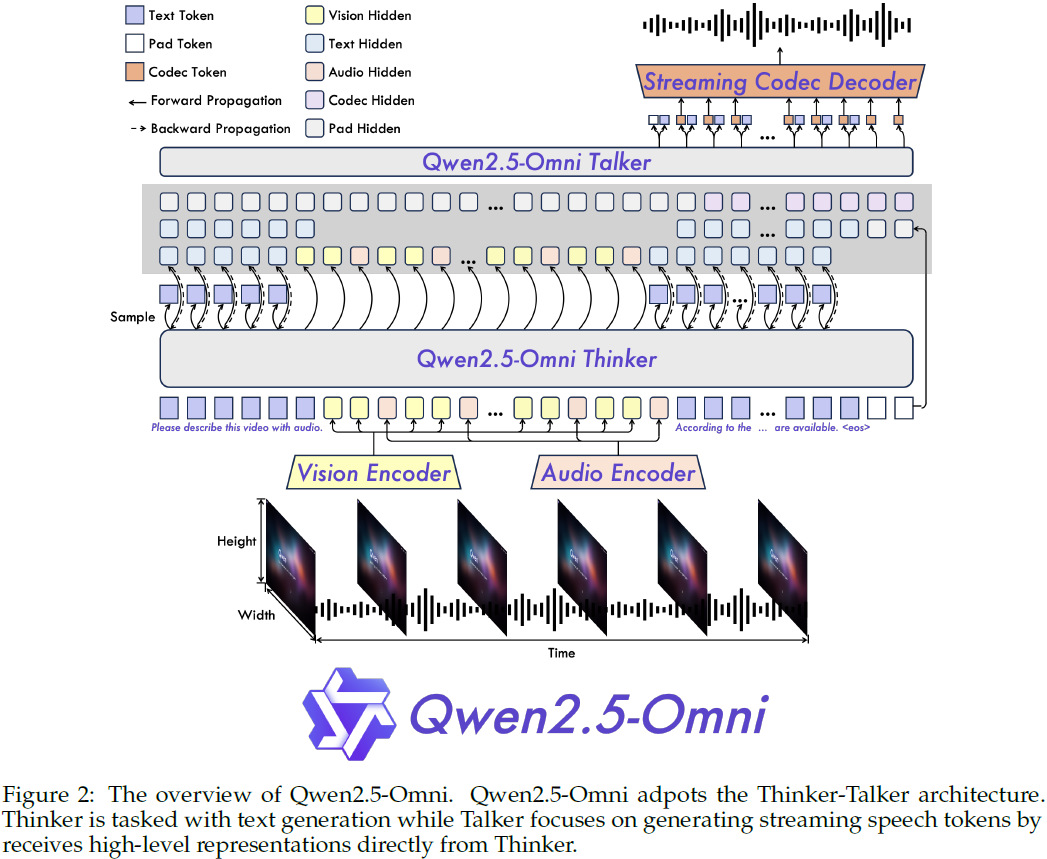
如图 2 所示,Qwen2.5-Omni 采用了 Thinker-Talker 架构:
-
Thinker 类似于 “大脑”,负责接收、处理并理解来自文本、音频、图像和视频的多模态输入,生成高维的语义表示和相应文本。
-
Talker 则类似于 “嘴巴”,实时接收 Thinker 提供的高维表示和生成的文本 token,自回归地生成流式(streaming)语音 token,从而输出流畅自然的语音响应。
具体而言:
-
Thinker 基于 Transformer 解码器架构,配备了音频和图像编码器辅助多模态信息的提取。
-
Talker 采用了双轨自回归 Transformer 解码器结构,设计灵感源于 Mini-Omni 模型,直接使用 Thinker 输出的高维表示进行语音 token 的生成,确保语义表达的一致性和实时性。
整体架构设计为端到端训练和推理,Thinker 和 Talker 紧密协作,共享历史上下文信息,形成统一模型。
2.2 模态感知
为了统一处理不同的模态输入,Thinker 将文本、音频、图像和视频(无音频轨)转换为统一的隐含表示序列:
文本处理:采用 Qwen 的 tokenizer,基于字节级 Byte-Pair Encoding(BPE)编码方式,具有 151,643 个常规 token。
音频处理:
-
音频(包括视频中的音轨)统一重采样到 16kHz,将原始音频波形转为 128 通道的梅尔谱图(mel-spectrogram),帧长 25ms,帧移 10ms。
-
使用来自 Qwen2-Audio 的音频编码器,每个音频表示帧对应约 40ms 的原始音频。
视觉处理:
-
使用基于 Vision Transformer(ViT)的视觉编码器,参数规模约为 675M,来源于 Qwen2.5-VL。
-
视觉编码器通过混合图像和视频数据进行训练,确保同时具备图像理解与视频理解的能力。
-
对于视频输入,采用动态帧率抽取帧,以适配音频的采样率;静态图像则视作两个相同的视频帧处理。
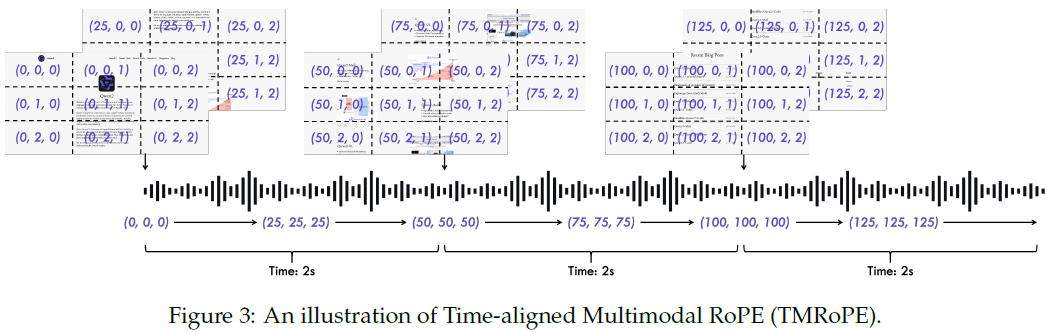
为了同步音视频,本文提出一种特殊的交错时间编码方法和新型的位置编码——TMRoPE(Time-aligned Multimodal RoPE):
-
TMRoPE 将原本的旋转位置嵌入(RoPE)分解为三个部分(时间、高度、宽度)。
-
文本输入的三维位置编码退化为一维;音频也采用统一的一维时间编码(每帧对应 40ms,50 帧共 2s)。
-
图像的视觉 token 固定时间编码,但空间位置(高度、宽度)编码独立变化。
-
视频中,每帧的视觉信息时间编码逐帧递增,空间编码与图像相同。
-
对于同时含有音视频的情况,每两秒将视觉和音频表示交错排列,实现模态信息的实时同步。
2.3 生成方式
Qwen2.5-Omni 的生成模块由文本生成和语音生成两部分组成:
文本生成:
-
由 Thinker 直接实现,采用标准大语言模型(LLM)的自回归采样方式进行文本生成。
-
生成过程可结合重复惩罚(repetition penalty)和 top-p 采样策略以提高文本多样性。
语音生成:
-
Talker 同时接收来自 Thinker 的高维表示及已生成文本 token,利用隐式的高维语义信息和显式的文本信息消除语音生成的不确定性。
-
设计高效的语音编解码器(qwen-tts-tokenizer),以自回归方式流式生成音频 token,且生成语音不需要逐词对齐,大幅降低了数据需求和推理难度。
2.4 流式处理设计
针对流式音视频交互中初始包延迟(initial packet latency)的挑战,本文提出了多种优化方案:
支持块式预填充(Chunked-prefills):
-
音频编码器由全局注意力机制转为 2 秒块式注意力。
-
视觉编码器采用 flash attention,并增加 MLP 层合并相邻的 2×2 token 以提升效率。
流式编解码生成(Streaming Codec Generation):
-
提出滑动窗口块注意力机制,限制 DiT 模型的感受野范围。
-
使用 Flow-Matching DiT 模型将音频 token 转为 mel 谱图,再经改进的 BigVGAN 模型重建为波形,从而支持语音的高质量流式生成。
通过上述设计,Qwen2.5-Omni 能够在实际应用中实时处理多模态信息,快速响应用户输入,显著降低流式应用的延迟。
3. 预训练
3.1 第一阶段:视觉与音频编码器独立训练
固定大语言模型(LLM)的参数,只训练 视觉编码器 和 音频编码器。
使用海量的图像-文本、音频-文本数据对进行训练,以提高模型对视觉、音频与文本之间语义关联的理解能力。
LLM 组件使用 Qwen2.5 的初始参数进行初始化。
视觉编码器继承自 Qwen2.5-VL,音频编码器则基于 Whisper-large-v3 进行初始化。
两个编码器在固定 LLM 的基础上独立训练,先训练适配器(adapter),再逐渐训练完整编码器,构建模型在视觉-文本、音频-文本相关性的基本理解能力。
3.2 第二阶段:联合全参数训练与多模态整合
解冻所有模型参数,全参数联合训练,包含更丰富、更多样的多模态数据,扩大模型对各模态间深层互动的感知。
数据规模显著提升:
- 新增约 800B tokens 的图像和视频数据。
- 新增约 300B tokens 的音频相关数据。
- 新增约 100B tokens 的音视频联合数据。
引入多模态、多任务数据集,强化模型同时处理多模态与多任务的能力,以应对复杂真实场景。
继续保持纯文本数据训练,以巩固模型的语言基础能力。
3.3 第三阶段:长序列数据训练提升理解能力
在前两个阶段,模型最大 token 序列长度限制为 8192 tokens。为了进一步提高模型处理更长、更复杂数据序列的能力,本阶段进行了长序列数据专项训练:
-
引入更长的音频和视频数据。
-
原有文本、音频、图像及视频数据均扩展到 32768 tokens长度。
-
实验证明,序列长度的扩展对提升长序列数据的理解能力效果明显,增强了模型的实用性和泛化能力。
通过以上三个阶段的逐步训练,Qwen2.5-Omni 具备了对文本、音频、图像和视频的强大理解能力,并能够高效地处理多模态数据输入,且适用于真实环境中的长序列输入场景。
4. 后训练(Post-training)
本节详细介绍了 Qwen2.5-Omni 的后训练阶段,包括数据格式设计、Thinker 模块与 Talker 模块的具体训练策略,以及各个阶段所使用的数据和训练目标。
4.1 数据格式
为了更好地实现指令跟随能力,本研究使用了 ChatML 格式进行指令微调(Instruction-Finetuning),构造了多样化的多模态对话数据,包括:
-
纯文本对话数据
-
视觉模态对话数据
-
音频模态对话数据
-
混合多模态对话数据
ChatML数据格式示例如下:

4.2 Thinker 模块训练
Thinker 模块的训练专注于指令跟随数据,通过使用 ChatML 格式的指令微调数据,增强模型在多模态任务中的指令理解能力。
4.3 Talker模块训练
Talker 模块训练过程共分为三个阶段,逐步提升其流式语音生成的稳定性、自然性和多样性。
第一阶段:上下文连续性学习(Context Continuation Learning)
-
Talker 在第一阶段中训练任务为上下文连续性学习,通过多模态上下文对话数据,进行语音 token 的下一个 token 预测任务。
-
通过多模态情境数据,让 Talker 建立起从语义高维表示到自然语音生成的映射,同时掌握语音情感、韵律和口音的表达能力。
-
采用音色解耦技术(timbre disentanglement),防止模型将特定语音与罕见的文本模式过度关联。
第二阶段:基于强化学习的差异化策略优化(DPO)
由于预训练数据存在标签噪声与发音错误,容易导致模型产生幻觉问题(hallucination),为提升语音生成的稳定性,采用强化学习方法——差异化策略优化(DPO):
-
构建了包含请求文本、回应文本及参考语音的三元组数据 (x, y_w, y_l):
-
x:请求文本
-
y_w:高质量语音
-
y_l:低质量语音
-
-
根据词错率(WER)与标点停顿误差率设计奖励函数,利用如下损失函数进行优化:
-
通过强化学习优化阶段,显著降低语音生成过程中的发音错误与不合适停顿等问题。
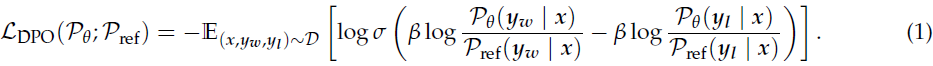
第三阶段:多说话人指令微调(Multi-Speaker Instruction Finetuning)
-
在最后阶段,Talker 模块进一步接受多说话人数据微调,使模型获得指定音色生成语音的能力。
-
有效提高生成语音的自然性(Naturalness)和音色控制能力,使生成语音更加逼近人类语音的表达效果。
5. 评估
5.1 模态理解能力评估(X→文本)
本节评估模型在不同模态输入(文本、音频、图像、视频以及混合模态)下生成文本响应的能力。
5.1.1 文本→文本评估
本部分评测了 Qwen2.5-Omni 在一般任务、数学科学任务和编程任务方面的表现。
-
一般任务:使用 MMLU-Pro、MMLU-redux、LiveBench0803;
-
数学与科学任务:使用 GPQA、GSM8K、MATH;
-
编程任务:使用 HumanEval、MBPP、MultiPL-E、LiveCodeBench;
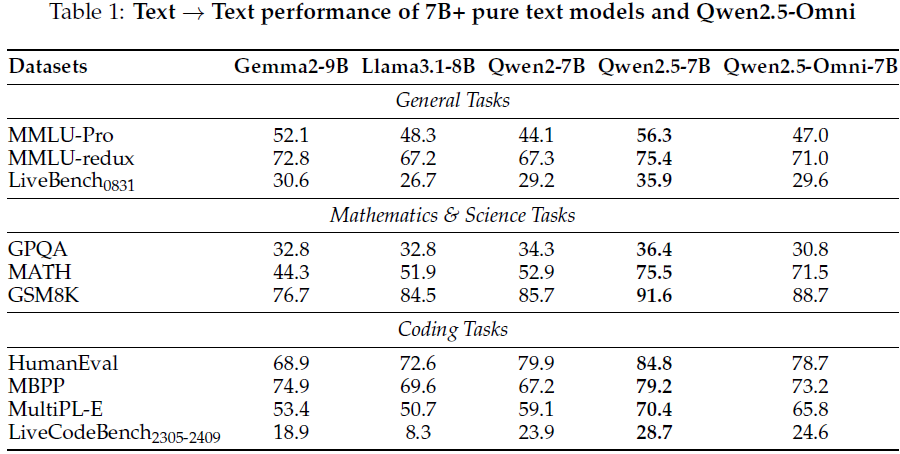
评估表明,Qwen2.5-Omni在大多数任务中优于 Qwen2-7B,与 Qwen2.5-7B 性能接近。
5.1.2 音频→文本评估
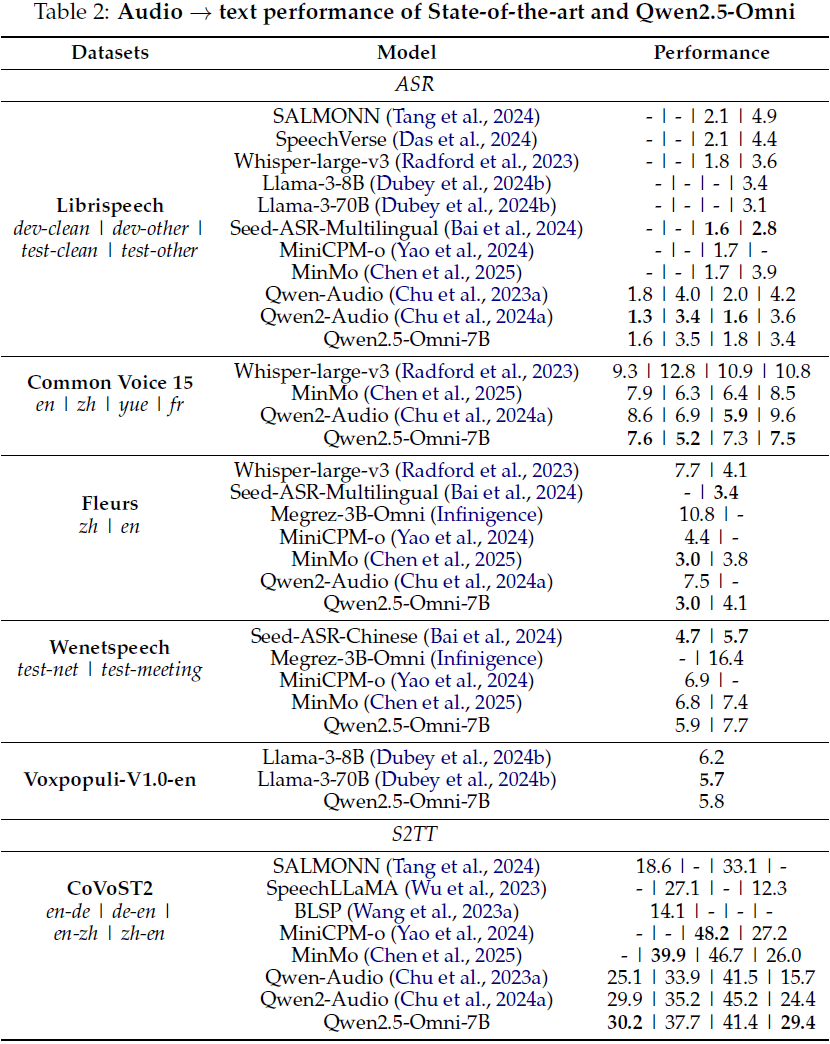
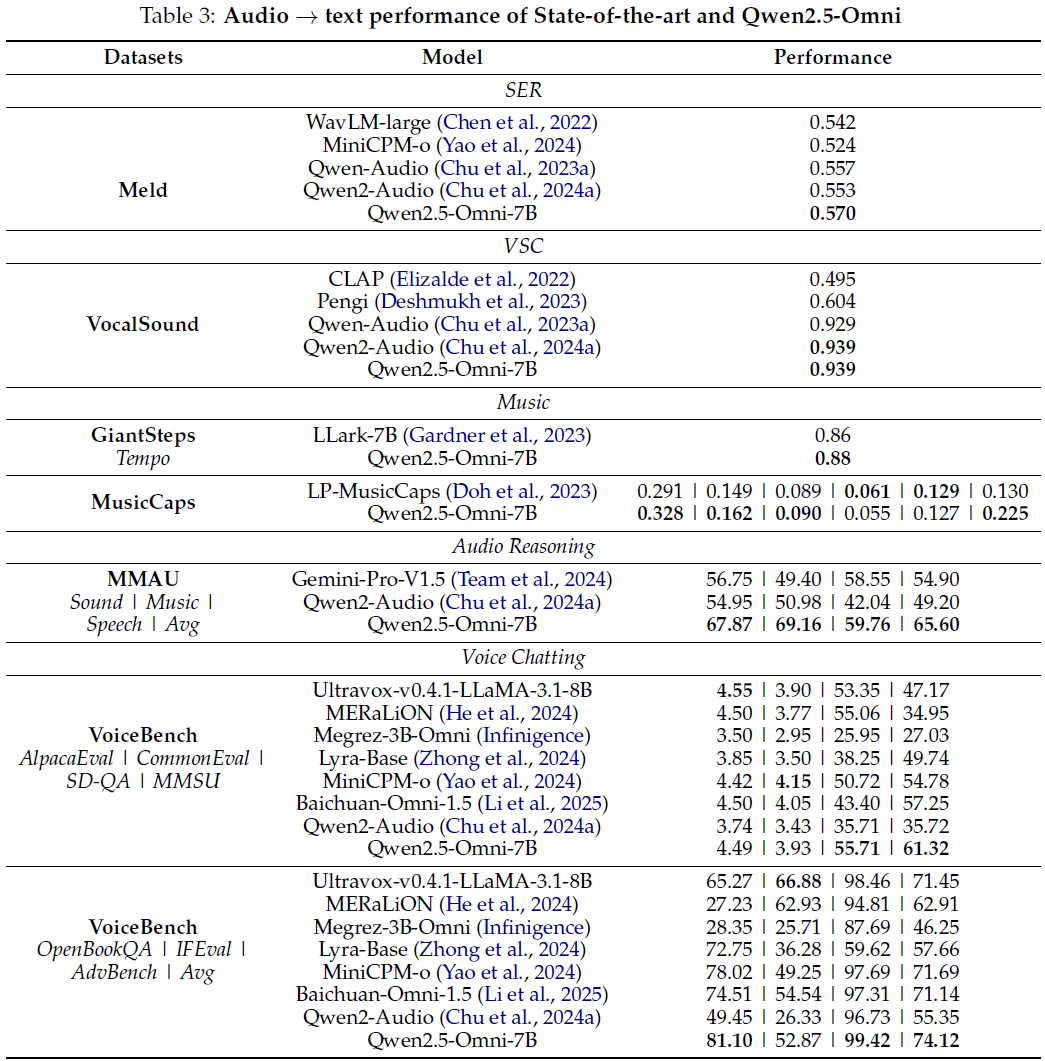
评估涵盖音频理解(ASR、S2TT、SER、VSC、音乐任务)、音频推理及语音对话任务:
-
音频理解任务(如语音识别和语音翻译):在 LibriSpeech、CommonVoice、Fleurs 等数据集上的表现超越现有模型;
-
音频推理任务:在 MMAU benchmark 上达到最优;
-
语音对话任务:在 VoiceBench benchmark 的多项任务中明显优于其他同规模模型;
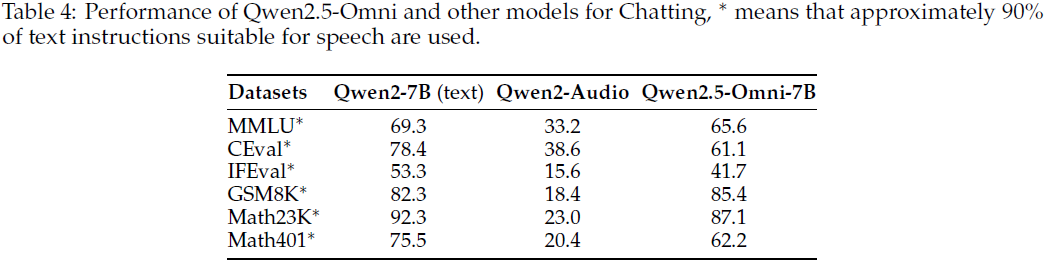
为了进一步探索多样化语音交互的性能,将来自几个纯文本基准的文本指令转换为语音。
- 相比于 Qwen2-Audio,Qwen2.5-Omni 明显缩小了与使用文本指令的 Qwen2-7B 之间的差距,
- 表明 Qwen2.5-Omni 在端到端多样化语音交互方面取得了实质性的进步。
5.1.3 图像→文本评估
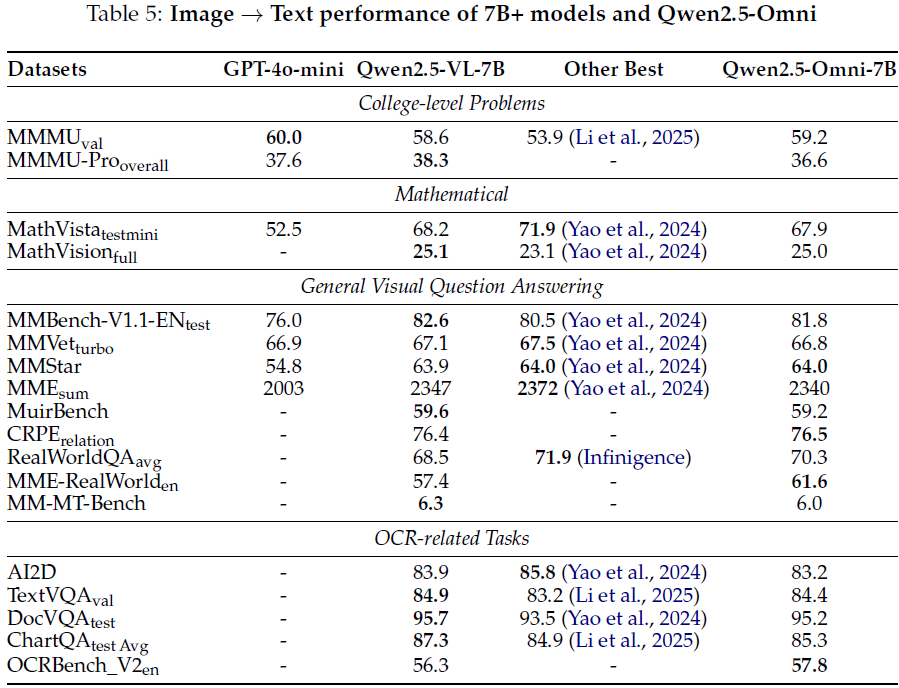
针对大学级别问题、数学问题、通用视觉问答任务和 OCR 任务进行评估:
-
在 MMMU、MathVision、MMBench-V1.1、TextVQA、DocVQA、ChartQA 等基准数据集上均表现出色;
-
在视觉定位(Visual Grounding)任务上表现显著,RefCOCO、ODinW 等任务均优于大多数开源模型;
- 评估表明 Qwen2.5-Omni 在视觉理解领域处于先进水平。
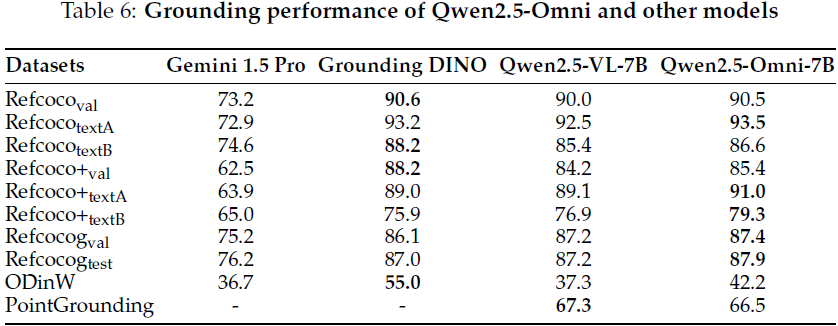
对于视觉接地(visual grounding),
- Qwen2.5-Omni 在从框接地(box-grounding)到点接地(point-grounding)的大多数基准测试中都优于其他模型,并且在开放词汇目标检测上取得了 42.2mAP 的良好性能,
- 这揭示了 Qwen2.5-Omni 强大的视觉接地能力。
5.1.4 视频(无音频)→文本评估
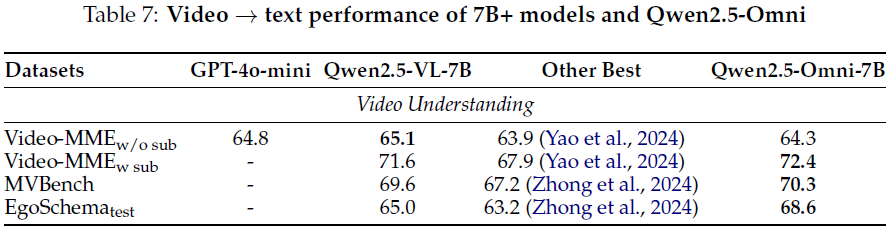
评测了视频理解能力,使用了 Video-MME、MVBench、EgoSchema 数据集:
-
在以上数据集上整体表现优于其他现有开源模型,体现出对复杂视频语义理解的强大能力。
5.1.5 混合模态→文本评估
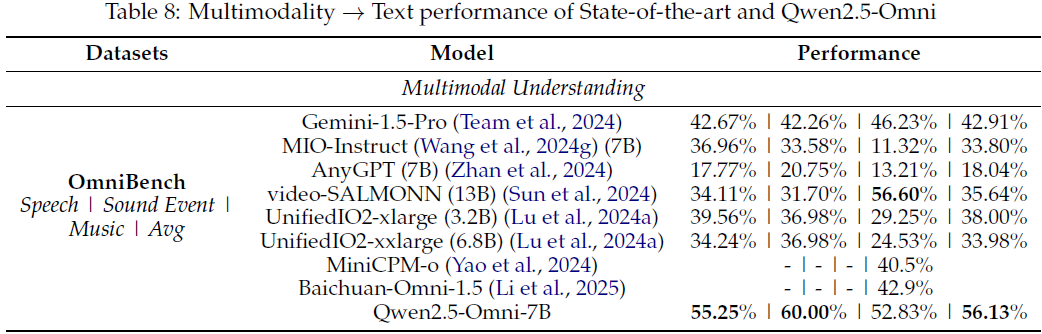
在多模态基准测试中:
-
OmniBench 的综合表现远超其他多模态模型,特别在语音、声音事件和音乐方面性能突出。
5.2 语音生成能力评估(X→语音)
5.2.1 零样本语音生成评估
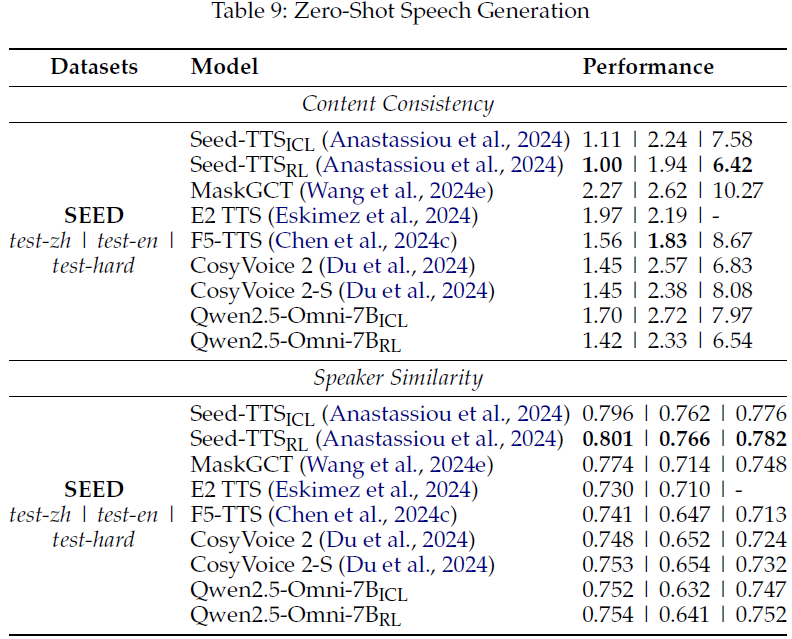
在 SEED 数据集上评测模型生成语音的内容一致性(WER)与说话人相似度(SIM):
-
经强化学习优化(RL)后,Qwen2.5-Omni 显著减少了生成语音中的发音错误及停顿不自然的问题;
-
在零样本条件下语音质量达到或超过现有最优模型(如 Seed-TTS、CosyVoice 2)。
5.2.2 单说话人语音生成评估
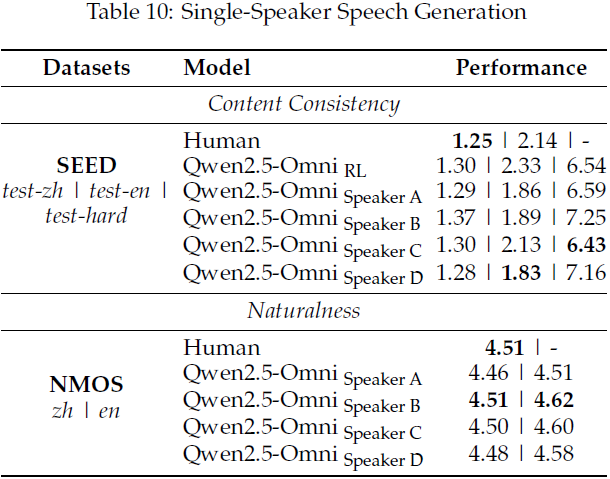
在经过指定说话人微调的情况下:
-
模型语音稳定性(SEED)和自然性(NMOS)显著提升;
-
在自然度方面接近人类录音水平,同时内容一致性保持稳定,体现了对个性化语音风格的精准捕捉能力。
6. 结论
Qwen2.5-Omni 通过 Thinker-Talker 架构和 TMRoPE 位置嵌入方法,成功实现了多模态实时理解和流式语音生成,表现出优于现有同类模型的性能。这一技术在视频 OCR、音视频协作理解等领域具有广泛前景,是迈向通用人工智能(AGI)的一次重要进展。
论文地址:https://arxiv.org/abs/2503.20215
项目页面:https://github.com/QwenLM/Qwen2.5-Omni
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









