









ABSTRACT
We address the problem of imitating multi-modal expert demonstrations in sequential decision making problems. In many practical applications, for example video games, behavioural demonstrations are readily available that contain multi-modal structure not captured by typical existing imitation learning approaches. For ex-ample, differences in the observed players’ behaviours may be representative of different underlying playstyles.
In this paper, we use a generative model to capture different emergent playstyles in an unsupervised manner, enabling the imitation of a diverse range of distinct behaviours. We utilise a variational autoencoder to learn an embedding of the different types of expert demonstrations on the trajectory level, and jointly learn a latent representation with a policy. In experiments on a range of 2D continuous control problems representative of Minecraft environments, we empirically demon-strate that our model can capture a multi-modal structured latent space from the demonstrated behavioural trajectories.
我们解决了在连续决策问题中模仿多模态专家演示的问题。在许多实际应用中,例如视频游戏,容易获得包含多模态结构的行为演示,这些结构未被典型的现有模仿学习方法捕获。例如,观察到的球员行为的差异可能代表不同的潜在游戏方式。
在本文中,我们使用生成模型以无人监督的方式捕捉不同的紧急游戏风格,从而模仿各种不同的行为。我们利用变分自动编码器来学习在轨迹水平上嵌入不同类型的专家演示,并通过策略共同学习潜在的表示。在代表Minecraft环境的一系列2D连续控制问题的实验中,我们凭经验证明我们的模型可以从所展示的行为轨迹中捕获多模态结构潜在空间。
1INTRODUCTION
Imitation learning has become successful in a wide range of sequential decision making problems, in which the goal is to mimic expert behaviour given demonstrations (Ziebart et al., 2008; Wang et al., 2017; Li et al., 2017; D’Este et al., 2003). Compared with reinforcement learning, imitation learning does not require access to a reward function – a key advantage in domains where rewards are not naturally or easily obtained. Instead, the agent learns a behavioural policy implicitly through demonstrated trajectories.
Expert demonstrations are typically assumed to be provided by a human demonstrator and generally can vary from person to person, e.g., according to their personality, experience and skill at the task. Therefore, when capturing demonstrations from multiple humans, observed behaviours may be distinctly different due to multi-modal structure caused by differences between demonstrators. Variations like these, which are very common in video games where players often cluster into distinct play styles, are typically not modelled explicitly as the structure of these differences is not known a priori but instead emerge over time as part of the changing meta-game.
In this paper, we propose Trajectory Variational Autoencoder (T-VAE) a deep generative model that learns a structured representation of the latent features of human demonstrations that result in diverse behaviour, enabling the imitation of different types of emergent behaviour. In particular, we use a Variational Autoencoder (VAE) to maximise the Evidence Lower Bound (ELBO) of the log likelihood of the expert demonstrations on the trajectory level where the policy is directly learned from optimising the ELBO. Not only can our model reconstruct expert demonstrations, but we empirically demonstrate it learns a meaningful latent representation of distinct emergent variances in the observed trajectories.
模仿学习在各种顺序决策问题中取得了成功,其中的目标是模仿专家行为(Ziebart et al。,2008; Wang et al。,2017; Li et al。,2017; D’) Este等,2003)。与强化学习相比,模仿学习不需要获得奖励功能 - 在自然或不容易获得奖励的领域中的关键优势。相反,代理通过演示的轨迹隐含地学习行为策略。
专家演示通常假定由人类演示者提供,并且通常可以因人而异,例如,根据他们的个性,经验和任务技能。因此,当捕获来自多个人的示范时,由于示范者之间的差异导致的多模态结构,观察到的行为可能明显不同。这些变体在视频游戏中非常常见,其中玩家经常聚集成不同的游戏风格,通常不会明确地建模,因为这些差异的结构不是先验已知的,而是作为变化的元游戏的一部分而随着时间的推移而出现。
在本文中,我们提出了轨迹变分自动编码器(T-VAE)一种深度生成模型,该模型学习人类示范潜在特征的结构化表示,从而产生不同的行为,从而能够模仿不同类型的紧急行为。特别是,我们使用变分自动编码器(VAE)来最大化在轨迹级别上专家演示的对数似然的证据下界(ELBO),其中策略是从优化ELBO直接学习的。我们的模型不仅可以重建专家演示,而且我们凭经验证明它可以在观察到的轨迹中学习不同的紧急变化的有意义的潜在表示。
2RELATED WORK
Popular imitation learning methods include behavior cloning (BC) (Pomerleau, 1991), which is a supervised learning method that learns a policy from expert demonstration of state-action pairs. However, this approach assumes independent observations which is not the case for sequential decision making problems, as future observations depend on previous actions. It has been shown that BC cannot generalise well to unseen observations (Ross & Bagnell, 2010). Ross et al. (2011) proposed a new iterative algorithm, which trains a stationary deterministic policy with no regret learning in an online setting to overcome this issue. Torabi et al. (2018) also improve behaviour cloning with a two-phase approach where the agent first learns an inverse dynamics model via interacting with the environment in a self-supervised fashion, and then use the model to infer missing actions given expert demonstrations. An alternative approach is Apprenticeship Learning (AC) (Abbeel & Ng, 2004), which uses inverse reinforcement learning to infer a reward function from expert trajectories. However, it suffers from expensive computation due to the requirement of repeatedly performing reinforcement learning from tabula-rasa to convergence. Whilst each of these methods has had successful applications, none are able to capture multi-modal structure in the demonstration data representative of underlying emergent differences in playstyle.
More recently, the learning of a latent space for imitation learning has been studied in the literature. Generative Adversarial Imitation Learning (GAIL) (Ho & Ermon, 2016) learns a latent space of demonstrations with a Generative Adverserial Network (GAN) (Goodfellow et al., 2014) like ap-proach which is inherently mode-seeking and does not explicitly model multi-modal structure in the demonstrations. This limitation was addressed by (Li et al., 2017), who built on the GAIL framework to infer a latent structure of expert demonstrations enabling imitation of diverse behaviours. Similarly, (Wang et al., 2017) combined a VAE with a GAN architecture to imitate diverse behaviours. However, these methods require interacting with the environment and rollouts of the policy whilst learning. For comparison we note our method does not need access to the environment simulator during training and is computationally cheaper, as the policy is learned simply by gradient descent using a fixed dataset of trajectories. Additionally, whilst the aim in GAIL is to keep the agent behaviour close to the expert’s state distribution, our model can serve as an alternative approach to capturing state sequence structure.
In work more closely related to our approach, (Co-Reyes et al., 2018) have also proposed a Variational Auto encoder (VAE) (Kingma & Welling, 2013) that embeds the expert demonstration on the trajectory level which showed promising results. However their approach only encodes the trajectories of the states whereas ours encodes both the state and action trajectories, which also allows us to learn the policy directly from the probabilistic model rather than adding a penalty term to the ELBO. Rabinowitz et al. (2018) also learns an interpretable representation of the latent space in a hierarchical way, but their focus is more on representing the mental states of other agents and is different from our goal of imitating diverse emergent behaviours.
流行的模仿学习方法包括行为克隆(BC)(Pomerleau,1991),这是一种监督学习方法,通过状态 - 动作对的专家演示来学习策略。然而,这种方法假设独立观察,而顺序决策制定问题并非如此,因为未来的观察依赖于先前的行动。已经证明BC不能很好地概括为看不见的观察结果(Ross&Bagnell,2010)。罗斯等人。 (2011)提出了一种新的迭代算法,该算法训练一个固定的确定性策略,在线设置中没有后悔学习来克服这个问题。托拉比等人。 (2018)还通过两阶段方法改进行为克隆,其中代理首先通过以自我监督的方式与环境交互来学习逆动力学模型,然后使用该模型来推断给定专家演示的缺失动作。另一种方法是学徒学习(AC)(Abbeel&Ng,2004),它使用逆强化学习从专家轨迹推断出奖励函数。然而,由于需要重复地从表格到收敛进行强化学习,所以它遭受昂贵的计算。虽然这些方法中的每一种都有成功的应用,但没有一种能够在演示数据中捕获多模态结构,代表了游戏风格中潜在的紧急差异。
最近,在文献中已经研究了用于模仿学习的潜在空间的学习。生成性对抗性模仿学习(GAIL)(Ho&Ermon,2016)通过生成性逆境网络(GAN)(Goodfellow et al。,2014)学习示范的潜在空间,就像ap-proach本身就是模式寻求而没有明确地模型中的多模态结构。这个限制由(Li et al。,2017)解决,他建立在GAIL框架上,推断出能够模仿不同行为的专家示范的潜在结构。同样,(Wang et al。,2017)将VAE与GAN架构相结合,以模仿不同的行为。但是,这些方法需要在学习的同时与环境进行交互并推出策略。为了进行比较,我们注意到我们的方法在训练期间不需要访问环境模拟器,并且在计算上更便宜,因为仅使用固定的轨迹数据集通过梯度下降来学习策略。此外,虽然GAIL的目标是使代理行为保持接近专家的状态分布,但我们的模型可以作为捕获状态序列结构的替代方法。
在与我们的方法更密切相关的工作中,(Co-Reyes等,2018)也提出了一种变分自动编码器(VAE)(Kingma&Welling,2013),它将专家演示嵌入轨迹水平,显示出有希望的结果。然而,他们的方法只编码状态的轨迹,而我们的方法编码状态和行动轨迹,这也允许我们直接从概率模型学习政策,而不是在ELBO中添加惩罚项。 Rabinowitz等人。 (2018)也以层次方式学习潜在空间的可解释表示,但他们更关注的是代表其他代理人的心理状态,并且不同于我们模仿不同的新兴行为的目标。
3METHODS
3.1 PRELIMINARIES

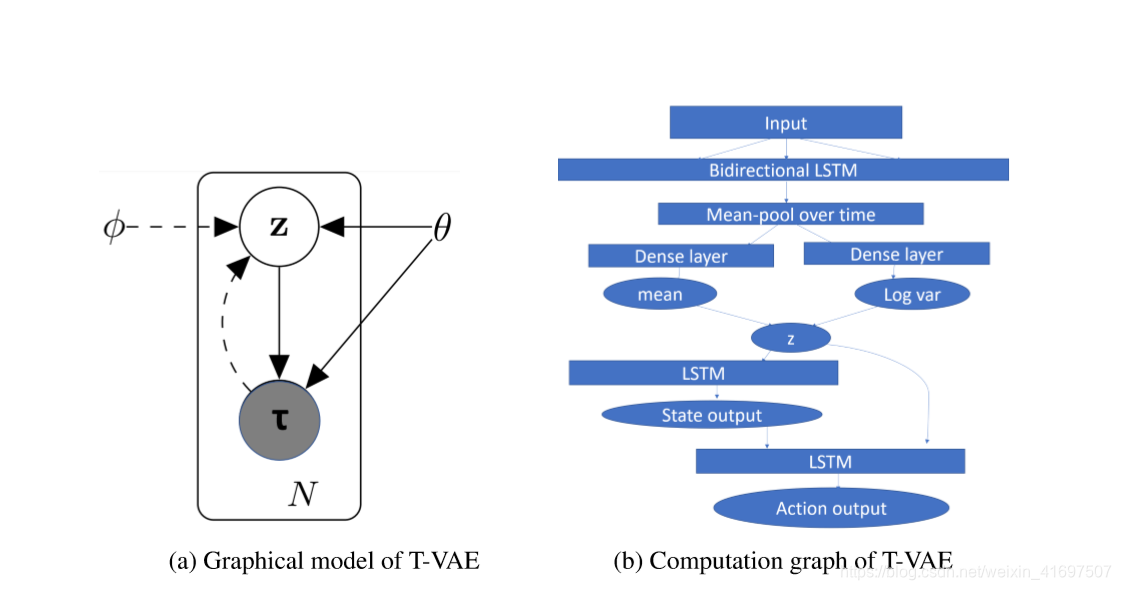
3.ENCODER NETWORK
We encode whole trajectories into the latent space in order to embed useful features of different behaviours and extract distinguishing features which differ from trajectory to trajectory. Note that the latent z is therefore a single variable rather than a sequence that depends on t. In order to utilise
我们将整个轨迹编码到潜在空间中,以嵌入不同行为的有用特征,并提取不同于轨迹到轨迹的区别特征。 请注意,潜在z因此是单个变量而不是依赖于t的序列。 为了利用


3.VARIATIONAL BOUND
The marginal likelihood for each trajectory can be written as

GENERATING TRAJECTORIES

4EXPERIMENT
4.1 2D NAVIGATION EXAMPLE
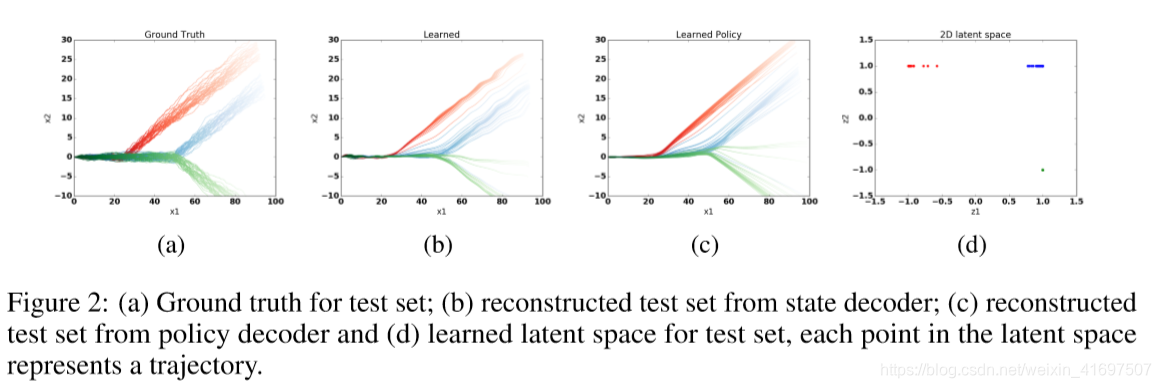
We first apply our model to a 2D navigation example with 3 types of trajectories representative of players moving towards different goal locations. This experiment confirms our approach can detect and imitate multi-modal structure demonstrations, and learns a meaningful and consistent latent representation. Starting from (0; 0), the state space consists of the 2D (continuous) coordinates and the action is the angle along which to move a fixed distance (=1). The time horizon is fixed to be 100.
In Figure 2, the ground truth trajectories are given in (a), and we reconstruct the trajectories through the state decoder and the policy decoder in (b) and © respectively. It can be seen that they are consistent with each other and represent the test set well. The latent embedding can be found in (d), where we can clearly identify 3 clusters corresponding to the 3 types of trajectories.
Figure 3 shows interpolations as we navigate through the latent space, i.e. we sample a 4 by 4 grid in the latent space, and generate trajectories using the state decoder and the policy decoder. We can see that the T-VAE shows consistent behaviour as we interpolate in the latent space. This confirms that our approach can detect and imitate latent structure, and that it learns a meaningful latent representation that captures the main dimensions of variation.
我们首先将我们的模型应用于2D导航示例,其中3种类型的轨迹代表玩家朝向不同的目标位置移动。该实验证实了我们的方法可以检测和模仿多模态结构演示,并学习有意义且一致的潜在表示。从(0; 0)开始,状态空间由2D(连续)坐标组成,动作是移动固定距离(= 1)的角度。时间范围固定为100。
在图2中,地面实况轨迹在(a)中给出,并且我们分别通过状态解码器和(b)和(c)中的策略解码器重建轨迹。可以看出它们彼此一致并且很好地代表了测试集。潜在嵌入可以在(d)中找到,其中我们可以清楚地识别对应于3种类型的轨迹的3个簇。
图3示出了当我们在潜在空间中导航时的插值,即我们在潜在空间中采样4乘4网格,并使用状态解码器和策略解码器生成轨迹。我们可以看到,当我们在潜在空间中插值时,T-VAE显示出一致的行为。这证实了我们的方法可以检测和模仿潜在结构,并且它学习了一个有意义的潜在表示,捕获变异的主要维度。

Figure 3: Intepolation of latent space for (a) state decoder; and (b) policy decoder. It can be observed that the top left corner, top right corner and bottom right corner behave like the red, blue and green type of trajectories respectively and the bottom left corner has a mixed behaviour.
图3:(a)状态解码器的潜在空间的插值; (b)政策解码器。 可以观察到,左上角,右上角和右下角分别表现为红色,蓝色和绿色类型的轨迹,左下角具有混合行为。
2D CIRCLE EXAMPLE
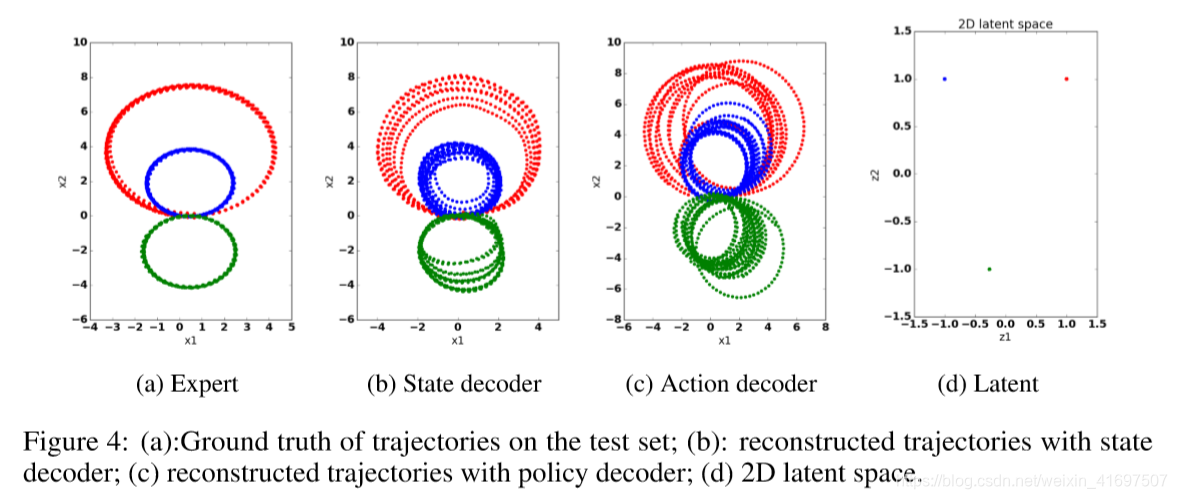
Figure 4: (a):Ground truth of trajectories on the test set; (b): reconstructed trajectories with state decoder; © reconstructed trajectories with policy decoder; (d) 2D latent space.
We next apply our model to another 2D example, designed to replicate the experimental setting in Figure 1 of Li et al. (2017). There are three types of circles (in the figures these are coloured in red, blue and green) as shown in Figure 4a. The agent starts from (0; 0), the observation consists of the continuous 2D coordinates and the action is the relative angle towards which the agent moves. The reconstructed test set using state decoder and policy decoder, and visualisations of the 2D latent space can be found in Figure 4.
These results show that when the sequence length is not fixed (as in the previous example), T-VAE is still able to produce consistency between the state and policy decoders and learn latent features
that underpins different behaviours. Furthermore, as figure 1 in Li et al. (2017) already showed that both behaviour cloning and GAIL fail at this task whereas InfoGAIL and now T-VAE perform well, it seems that using a latent representation to capture long term dependency is crucial in this example.
图4:(a):测试集上轨迹的基本事实; (b):用状态解码器重建轨迹; (c)使用政策解码器重建轨迹; (d)2D潜伏空间。
接下来,我们将模型应用于另一个2D实例,旨在复制Li等人的图1中的实验设置。 (2017年)。有三种类型的圆圈(在图中这些圆圈用红色,蓝色和绿色着色),如图4a所示。代理从(0; 0)开始,观察由连续的2D坐标组成,动作是代理移动的相对角度。使用状态解码器和策略解码器的重建测试集以及2D潜在空间的可视化可以在图4中找到。
这些结果表明,当序列长度不固定时(如前例所示),T-VAE仍然能够在状态和策略解码器之间产生一致性并学习潜在特征
这支撑着不同的行为。此外,如Li等人的图1所示。 (2017)已经表明行为克隆和GAIL都在这项任务失败,而InfoGAIL和现在的T-VAE表现良好,似乎使用潜在表示来捕获长期依赖性在这个例子中是至关重要的。
4.3 ZOMBIE ATTACK SCENARIO
Finally, we evaluate our model on a simplified 2D Minecraft-like environment. This set of experiments show that T-VAE is able to capture long-term dependencies, model mixed action space, and the performance is improved when using a rolling window during prediction. In each episode, the agent needs to reach a goal. There is a zombie moving towards the agent and there are two types of demonstrated expert behaviour: the ”attacking” behaviour where the agent moves to the zombie and attacks it before going to the goal, or the ”avoiding” behaviour where the agent avoids the zombie and reaches the goal. The initial position of the agent and the goal are kept fixed whereas the initial position of the zombie is sampled uniformly at random. The observation space consists of the distance and angle to the goal and the zombie respectively, and there are two types of actions:
1)the angle along which the agent moves by a fixed step size (=0.5), and 2) a Bernoulli variable indicating whether to attack the zombie in a given timestep or not, which is very sparse and typically only equals to 1 once for the ’attacking’ behaviour. Thus, this experiment setup exemplifies a mixed continuous-discrete action space. Episodes end when the agent reaches the goal or the number of time steps reaches the maximum number allowed, which is defined to be the maximum sequence length in the training set (30).
Figure 5 shows the ground truth and reconstruction of the two types of behaviours on the test set, and Figure 6 shows the learned latent space. We also provide animations: https: //youtu.be/fvcJbYnRND8 and ’avoiding’ ’region’https://youtu.be/DAruY-Dd9z8. These show test time behaviour where we randomly sample from the posterior distribution of the latent variable z in the latent space corresponding to the ’attacking’ cluster.
To examine the diversity of the generated behaviour, we randomly select a latent z in the ’attacking’ and ’avoiding’ clusters in Figure 6a and generate 1000 trajectories. The histogram for different statistics are displayed in Figure 7, where the top and bottom rows represent ’attacking’ and ’avoiding’ behaviour respectively. We can see a clear differentiation between these two different latent variables. Although the agent does not always succeed in killing the zombie, as shown in Figure 7b, the closest distances to the zombie (shown in Figure 7d) are almost all within the demonstrated range, meaning that the agent moves to the zombie but attacked at slightly different timing.
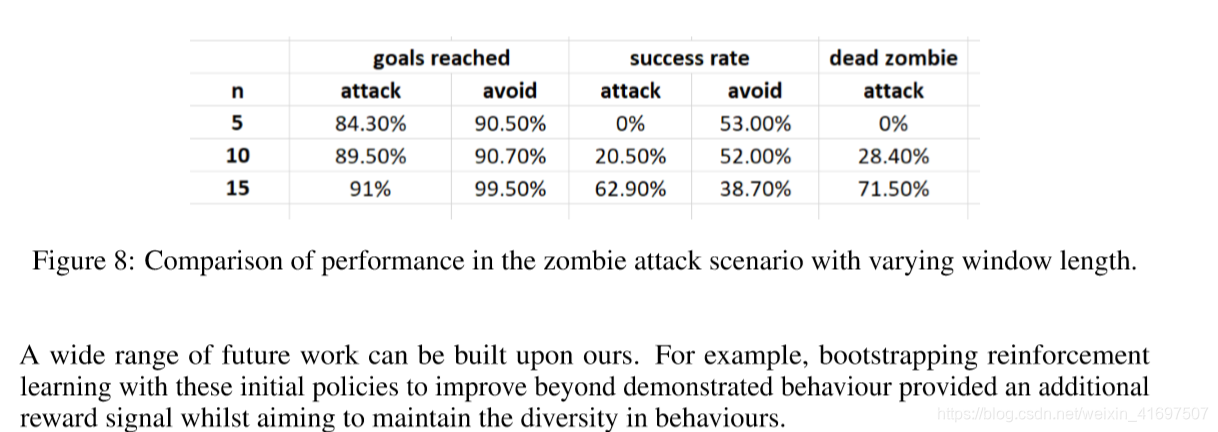
Results comparing with different rolling window length can be found in Figure 8. For the attacking agent, each episode is a success if the zombie is dead and the agent reaches the goal. For the avoiding agent, each episode is a success if the agent reaches the goal and is beyond the zombie’s attacking range. It can be seen that for small rolling window lengths, the performance is worse for ’attacking’ agent, since the model fails to capture long-term dependencies but provided a sufficient window length diverse behaviours can be imitated.
最后,我们在简化的类似Minecraft的环境中评估我们的模型。这组实验表明,T-VAE能够捕获长期依赖关系,建模混合动作空间,并且在预测期间使用滚动窗口时性能得到改善。在每集中,代理需要达到目标。有一个僵尸向代理移动,有两种类型的已证明的专家行为:代理移动到僵尸并在进入目标之前攻击僵尸的“攻击”行为,或者代理人避开的“避免”行为僵尸并达到了目标。代理的初始位置和目标保持固定,而僵尸的初始位置随机均匀采样。观察空间分别由目标和僵尸的距离和角度组成,有两种类型的动作:
1)代理移动固定步长(= 0.5)的角度,和2)指示是否在给定时间步长内攻击僵尸的伯努利变量,这是非常稀疏的,通常仅等于1 '攻击’行为。因此,该实验设置举例说明了混合的连续离散动作空间。当代理达到目标或时间步数达到允许的最大数量时,情节结束,这被定义为训练集(30)中的最大序列长度。
图5显示了测试集上两种行为的基本事实和重建,图6显示了学习的潜在空间。我们还提供动画:https://youtu.be/fvcJbYnRND8和’avoid’'region’https://youtu.be/DAruY-Dd9z8。这些显示了测试时间行为,其中我们从对应于“攻击”聚类的潜在空间中的潜在变量z的后验分布中随机抽样。
为了检查所生成行为的多样性,我们在图6a中的“攻击”和“避免”群集中随机选择潜在z并生成1000个轨迹。不同统计数据的直方图如图7所示,其中顶行和底行分别代表“攻击”和“避免”行为。我们可以看到这两个不同潜在变量之间的明显区别。虽然代理并不总能成功杀死僵尸,如图7b所示,与僵尸的最近距离(如图7d所示)几乎都在所示的范围内,这意味着代理移动到僵尸但略有攻击不同时间。
与不同滚动窗口长度相比的结果可以在图8中找到。对于攻击代理,如果僵尸已经死并且代理达到目标,则每一集都是成功的。对于避免代理人,如果代理人达到目标并超出僵尸的攻击范围,则每一集都是成功的。可以看出,对于小滚动窗口长度,“攻击”代理的性能更差,因为模型无法捕获长期依赖性但提供了足够的窗口长度,可以模仿不同的行为。
5 CONCLUSION
In this paper, we proposed a new method – Trajectory Variational Autoencoder (T-VAE) – for imitation learning that is designed to capture latent multi-modal structure in demonstrated behaviour. Our approach encodes trajectories of state-action pairs and learns latent representations with a VAE on the trajectory level.
T-VAE encourages consistency between the state and action decoders, helping avoid compound errors that are common in simpler behavioural cloning approaches to imitation learning. We demonstrate that this approach successfully avoids compound errors in several tasks that require long-term consistency and generalisation.
Our model is successful in generating diverse behaviours and learning a policy directly from a probabilistic model. It is simple to train and gives promising results in a range of tasks, including a zombie task that requires generalisation given a moving opponent as well as a mixed continuous-discrete action space.
在本文中,我们提出了一种新的方法 - 轨迹变分自动编码器(T-VAE) - 用于模仿学习,旨在捕获已演示行为中的潜在多模态结构。 我们的方法编码状态 - 动作对的轨迹,并在轨迹水平上用VAE学习潜在表示。
T-VAE鼓励状态和动作解码器之间的一致性,有助于避免复杂错误,这种错误在模仿学习的简单行为克隆方法中很常见。 我们证明了这种方法成功地避免了需要长期一致性和泛化的几个任务中的复合错误。
我们的模型成功地生成了多种行为,并直接从概率模型中学习策略。 训练并在一系列任务中给出有希望的结果是很简单的,包括僵尸任务,需要在移动的对手和混合的连续离散动作空间的情况下进行泛化。
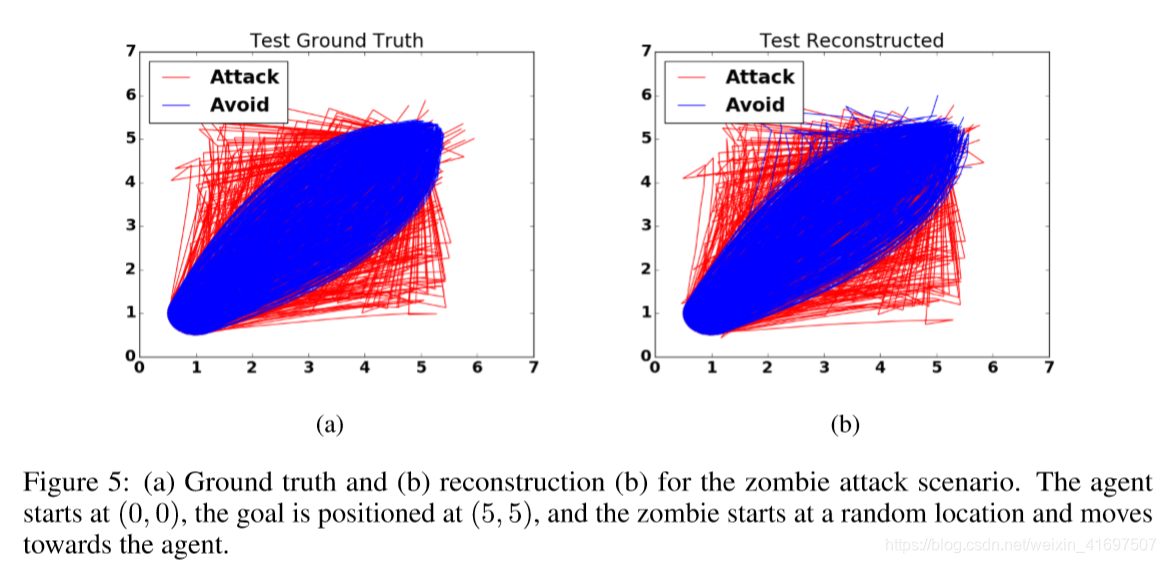
Figure 5: (a) Ground truth and (b) reconstruction (b) for the zombie attack scenario. The agent starts at (0; 0), the goal is positioned at (5; 5), and the zombie starts at a random location and moves towards the agent.
图5:(a)地面实况和(b)僵尸攻击情景的重建(b)。 代理从(0; 0)开始,目标位于(5; 5),僵尸从随机位置开始并向代理移动。
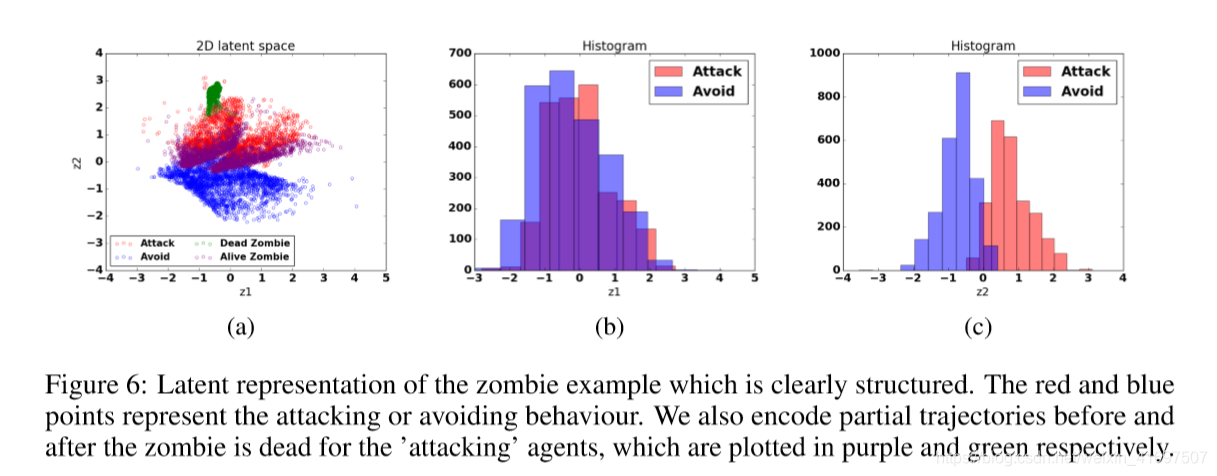
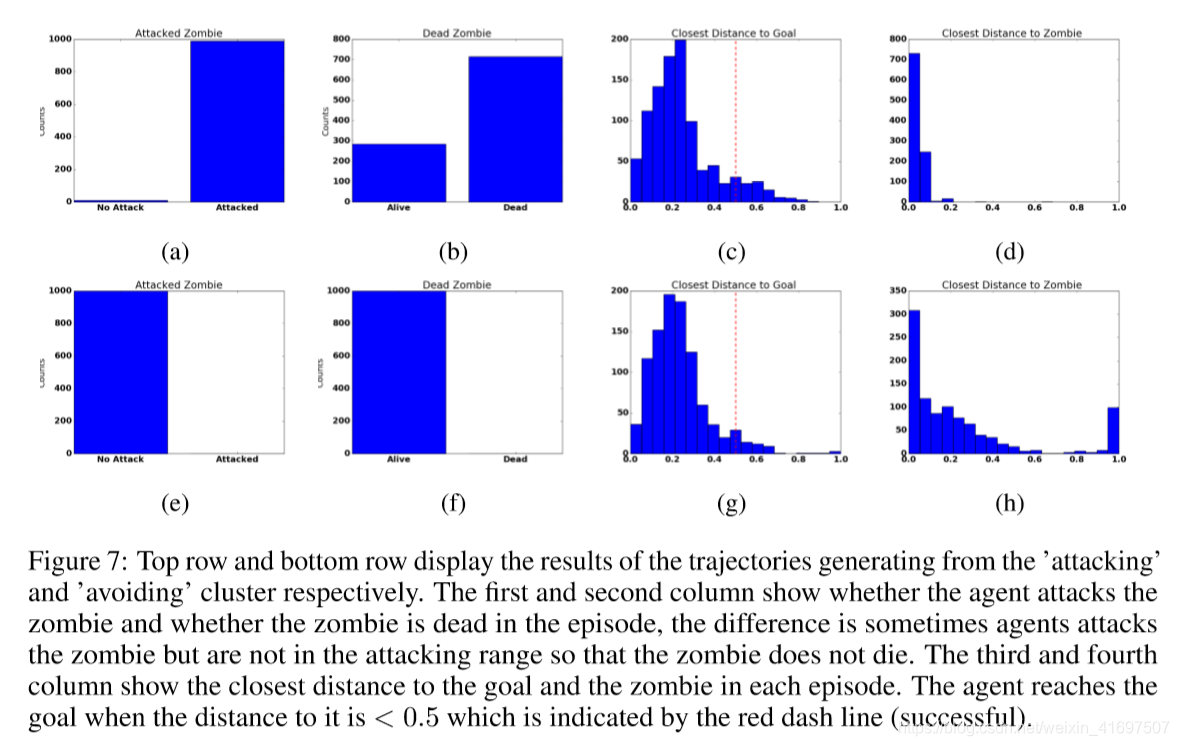
Figure 7: Top row and bottom row display the results of the trajectories generating from the ’attacking’ and ’avoiding’ cluster respectively. The first and second column show whether the agent attacks the zombie and whether the zombie is dead in the episode, the difference is sometimes agents attacks the zombie but are not in the attacking range so that the zombie does not die. The third and fourth column show the closest distance to the goal and the zombie in each episode. The agent reaches the goal when the distance to it is < 0:5 which is indicated by the red dash line (successful).
图7:顶行和底行分别显示从’攻击’和’避免’集群生成的轨迹的结果。 第一列和第二列显示代理是否攻击僵尸以及僵尸是否在剧集中死亡,不同的是有时候攻击者攻击僵尸但不在攻击范围内以便僵尸不会死亡。 第三和第四列显示每个剧集中与目标和僵尸的最近距离。 当代理距离<0:5时,代理到达目标,由红色虚线表示(成功)。
A wide range of future work can be built upon ours. For example, bootstrapping reinforcement learning with these initial policies to improve beyond demonstrated behaviour provided an additional reward signal whilst aiming to maintain the diversity in behaviours.
我们可以在此基础上开展广泛的未来工作。 例如,使用这些初始策略进行强化学习以改善已证明的行为,提供额外的奖励信号,同时旨在保持行为的多样性。
REFERENCES
Pieter Abbeel and Andrew Y Ng. Apprenticeship learning via inverse reinforcement learning. In Proceedings of the twenty-first international conference on Machine learning, pp. 1. ACM, 2004.
John D Co-Reyes, YuXuan Liu, Abhishek Gupta, Benjamin Eysenbach, Pieter Abbeel, and Sergey Levine. Self-consistent trajectory autoencoder: Hierarchical reinforcement learning with trajectory embeddings. arXiv preprint arXiv:1806.02813, 2018.
Claire D’Este, Mark O’Sullivan, and Nicholas Hannah. Behavioural cloning and robot control. In Robotics and Applications, pp. 179–182, 2003.
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural informa-tion processing systems, pp. 2672–2680, 2014.
Jonathan Ho and Stefano Ermon. Generative adversarial imitation learning. In Advances in Neural Information Processing Systems, pp. 4565–4573, 2016.
Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
Yunzhu Li, Jiaming Song, and Stefano Ermon. Infogail: Interpretable imitation learning from visual demonstrations. In Advances in Neural Information Processing Systems, pp. 3812–3822, 2017.
Dean A Pomerleau. Efficient training of artificial neural networks for autonomous navigation. Neural Computation, 3(1):88–97, 1991.
Neil C Rabinowitz, Frank Perbet, H Francis Song, Chiyuan Zhang, SM Eslami, and Matthew Botvinick. Machine theory of mind. arXiv preprint arXiv:1802.07740, 2018.
Stephane´ Ross and Drew Bagnell. Efficient reductions for imitation learning. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pp. 661–668, 2010.
Stephane´ Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the fourteenth international conference on artificial intelligence and statistics, pp. 627–635, 2011.
Faraz Torabi, Garrett Warnell, and Peter Stone. Behavioral cloning from observation. arXiv preprint arXiv:1805.01954, 2018.
Ziyu Wang, Josh S Merel, Scott E Reed, Nando de Freitas, Gregory Wayne, and Nicolas Heess.
Robust imitation of diverse behaviors. In Advances in Neural Information Processing Systems, pp.
5320–5329, 2017.
Brian D Ziebart, Andrew L Maas, J Andrew Bagnell, and Anind K Dey. Maximum entropy inverse reinforcement learning. In AAAI, volume 8, pp. 1433–1438. Chicago, IL, USA, 2008.


















 473
473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











