







RFLA 阅读笔记
RFLA: Gaussian Receptive Field based Label Assignment for Tiny Object Detection(Arxiv 2022)
先熟悉几个简写:
- RFLA:Gaussian Receptive Field based Label Assignment,基于高斯感受野的标签分配策略
- ERF:Effective Receptive Field,有效感受野
- TRF:Theoretical Receptive Field,理论感受野
- RFD:Receptive Field Distance,感受野距离
- RFDC:Receptive Field Distance Candidates
- HLA:Hierarchical Label Assignment,分层标签分配
摘要
- 动机:基于 anchor-based 和 anchor-free 的标签分配方法 将产生许多离群的尺度很小的 gt 样本,导致检测器对小目标的训练不足
- 解决方案:提出 Gaussian Receptive Field based Label Assignment(RFLA)。
- RFLA 首先利用先验信息,即遵循高斯分布的特征感受野
- 然后,使用 感受野距离(RFD)来直接测量高斯感受野和 gt 之间的相似性,而不是用IoU或中心采样策略来分配样本
- 考虑到基于IoU阈值和中心采样策略对大目标的倾斜,进一步设计一个基于RFD的层次化标签分配(HLA)模块,以实现对小目标的平衡学习
引言
- 标签分配方法对比:

- 从分布的角度思考 prior :
p ( v ∣ x , y ) = ϵ ( x − x 1 ) ϵ ( x 2 − x ) ϵ ( y − y 1 ) ϵ ( y 2 − y ) ( x 2 − x 1 ) ( y 2 − y 1 ) p(v|x,y)=\frac{\epsilon (x-x_1)\epsilon (x_2-x)\epsilon(y-y_1)\epsilon(y_2-y)}{(x_2-x_1)(y_2-y_1)} p(v∣x,y)=(x2−x1)(y2−y1)ϵ(x−x1)ϵ(x2−x)ϵ(y−y1)ϵ(y2−y)
其中 p ( v ∣ x , y ) p(v|x,y) p(v∣x,y) 是先验信息的概率密度函数, ( x , y ) (x,y) (x,y) 是图像上的位置, v v v 是相应位置的权重, ϵ ( ⋅ ) \epsilon (·) ϵ(⋅) 是阶跃函数,当大于零的时候为1,否则为0。 [ ( x 1 , y 1 ) , ( x 2 , y 2 ) ] [(x_1,y_1),(x_2,y_2)] [(x1,y1),(x2,y2)] 是先验信息区域,对于 anchor-based检测器, x 2 − x 1 x_2-x_1 x2−x1 是图像宽度, y 2 − y 1 y_2-y_1 y2−y1 是图像高度;对于 anchor-free检测器, x 2 − x 1 = y 2 − y 1 = 1 x_2-x_1=y_2-y_1=1 x2−x1=y2−y1=1。 - 现有小目标检测方法的问题:
- 第一:当特定 gt 与特定 prior 不重叠时,它们的位置关系无法通过IoU或中心采样策略解决;而大部分的小目标的 gt 与其 prior 不发生重叠
- 第二,当前先验区域主要遵循均匀分布,并对先验区域内的每个位置进行平等对待( v = 常数 v=常数 v=常数);但实际上,当将特征点的感受野重新映射回输入图像时,有效感受野实际上是高斯分布的,均匀分布先验和高斯分布感受野之间的差别将导致 gt 与分配给它的特征点的感受野不匹配
- 贡献:
- 通过实验揭示了当前 anchor-based 和 anchor-free 的检测器在小目标标签分配中存在尺度样本不平衡问题
- 为了缓解上述问题,引入基于感受野标签分配(RFLA)的策略。 RFLA 可以替换主流检测器中的基于 box 和基于 point 的标签分配策略,提高其在 TOD 上的性能
- 在四个数据集上进行了实验。在AI-TOD数据集上得到SOTA效果,且在推理阶段没有额外开销
方法

感受野建模(Receptive Field Modelling)
- 原来检测器的工作方式:
- anchor-based 的检测器在 FPN 的不同层上平铺不同尺度的先验框,以辅助标签分配,因此在FPN不同层上检测不同尺度的对象
- anchor-free检测器将不同比例范围内的对象分组到不同水平的FPN上进行检测
- 尽管标签分配策略各不相同,但 anchor-based 和 anchor-free 的一个共同点是将适当感受野的特征点分配给不同尺度的对象。
- 因此可以直接将感受野用作标签分配的先验
- 理论感受野TRF:
t r n = t r n − 1 + ( k n − 1 ) ∏ i = 1 n − 1 s i tr_n=tr_{n-1}+(k_n-1)\prod_{i=1}^{n-1}s_i trn=trn−1+(kn−1)i=1∏n−1si
其中 t r n tr_n trn 表示第 n n n 个卷积层上每一个点上的 TRF, k n k_n kn 和 s n s_n sn 表示第 n n n 个层上卷积操作的 卷积核大小 和 stride - 有效感受野ERF:ERF 和 TRF 具有相同的中心点,但每个特征点的 ERF 仅占整个 TRF 的一部分。因此,使用每个特征点
(
x
n
,
y
n
)
(x_n,y_n)
(xn,yn) 的位置作为标准二维高斯分布的均值向量。由于难以获得精确的 ERF,将 ERF 半径
e
r
n
er_n
ern 近似为 TRF 半径的一半。
e
r
n
er_n
ern 的平方用作标准方形卷积核的二维高斯分布的协方差。综上所述,我们将 ERF 的范围建模为二维高斯分布
N
e
(
μ
e
,
Σ
e
)
N_e(μ_e,Σ_e)
Ne(μe,Σe):

感受野距离(Receptive Field Distance)
- 对gt建模:将 gt 框
(
x
g
,
y
g
,
w
g
,
h
g
)
(x_g,y_g,w_g,h_g)
(xg,yg,wg,hg) 建模为标准的二维高斯分布
N
g
(
μ
g
,
Σ
g
)
N_g(μ_g, Σ_g)
Ng(μg,Σg),其中每个 gt 的中心点作为高斯的均值向量,半边长的平方作为协方差矩阵,即

- RFD:研究了高斯分布之间的三种典型距离作为感受野距离候选(RFDC)。这些距离测量包括Wasserstein距离、K-L散度和J-S散度。高斯分布之间的J-S散度没有闭式解,在近似其解时将引入大量计算,因此,不使用J-S散度
分层标签分配(Hierarchical Label Assignment)
- 在分配之前,计算特征点和gt之间的RFD得分矩阵
- 在第一阶段,根据每一个特征点与 每一个gt 的RFD得分进行排序; 然后,将 正标签 分配给前k个RFD得分的特征点; 最后,得到分配结果 r 1 r_1 r1 和已经分配的特征的相应掩码 m m m,其中m是二进制值(0/1)。
- 在第二阶段,为了提高整体召回率和缓解离群值, 通过乘以一个阶段因子
β
\beta
β 把有效半径
e
r
n
er_n
ern 减小,然后重复上述排序策略,对每一个 gt 补充一个正样本,得到分配结果
r
2
r_2
r2。最终的分配结果
r
r
r 如下:
r = r 1 m + r 2 ( 1 − m ) r=r_1m+r_2(1-m) r=r1m+r2(1−m)
其中采用掩码操作 m 是为了避免为那些已经分配了足够样本的 gt 引入过多的低质量样本。并不是说被遮挡的样本会被分配给较小的 gt。将 RFD 与 HLA 策略相结合,我们可以得到完整的 TOD 基于感受野的标签分配 (RFLA) 策略
应用到检测器(Application to Detectors)
- 避免梯度爆炸:将 centerness 修改为如下形式

其中 l ∗ , t ∗ , r ∗ , b ∗ l^*,t^*,r^*,b^* l∗,t∗,r∗,b∗ 是FCOS定义的回归目标, ϵ ( ⋅ ) \epsilon (·) ϵ(⋅)是阶跃函数, c c c 是一个设置为0.01因子,以避免当回归目标的中心点在 gt 框之外时出现梯度消失问题。
实验结果
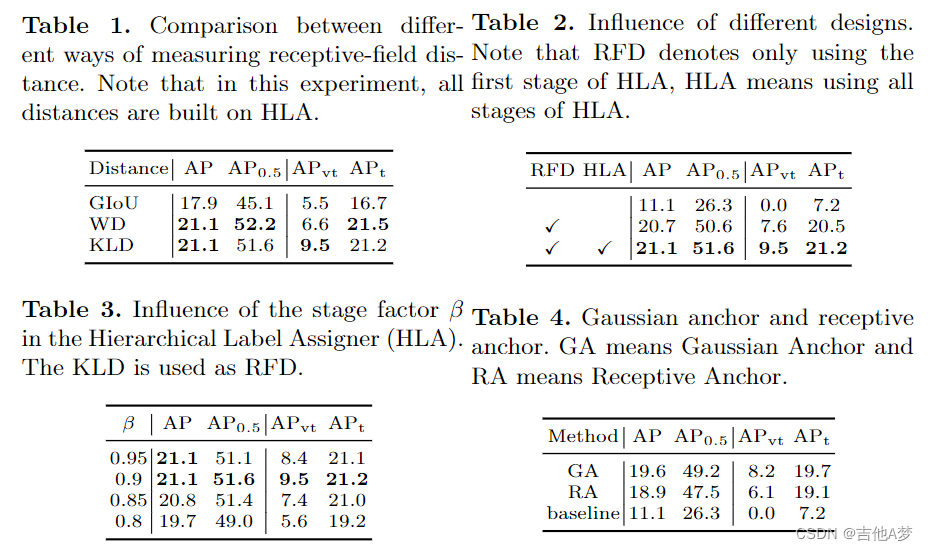
- 消融学习。
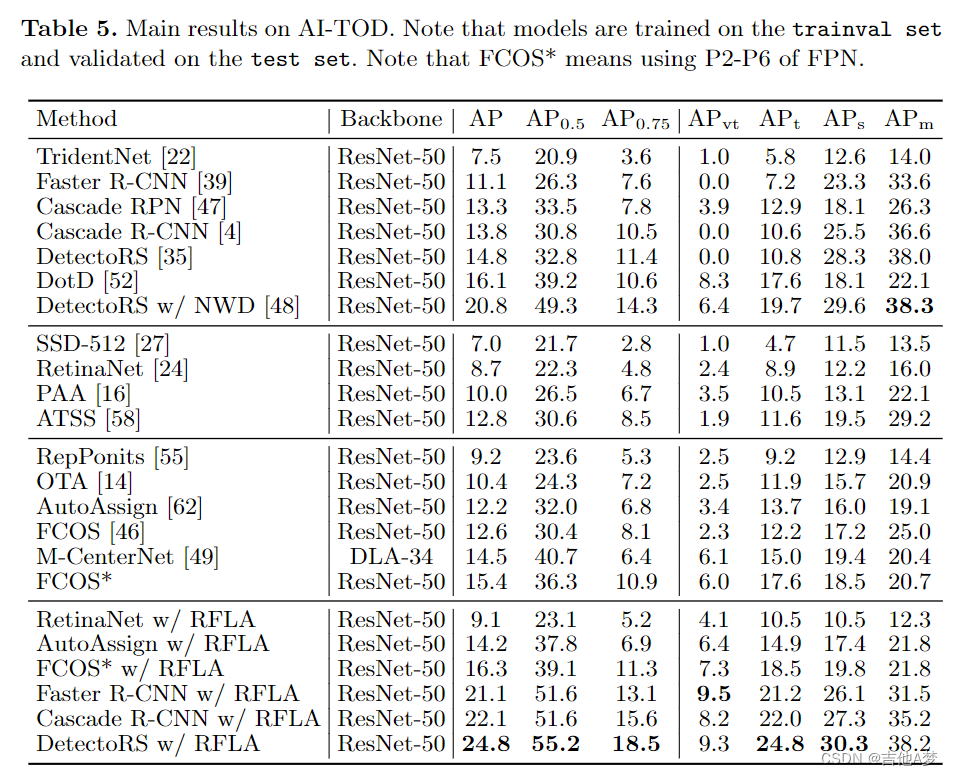
- AI-TOD上的结果。
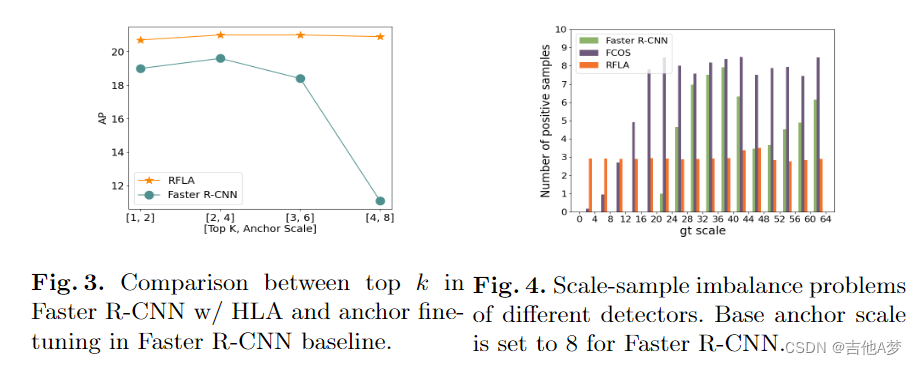
- 比较。
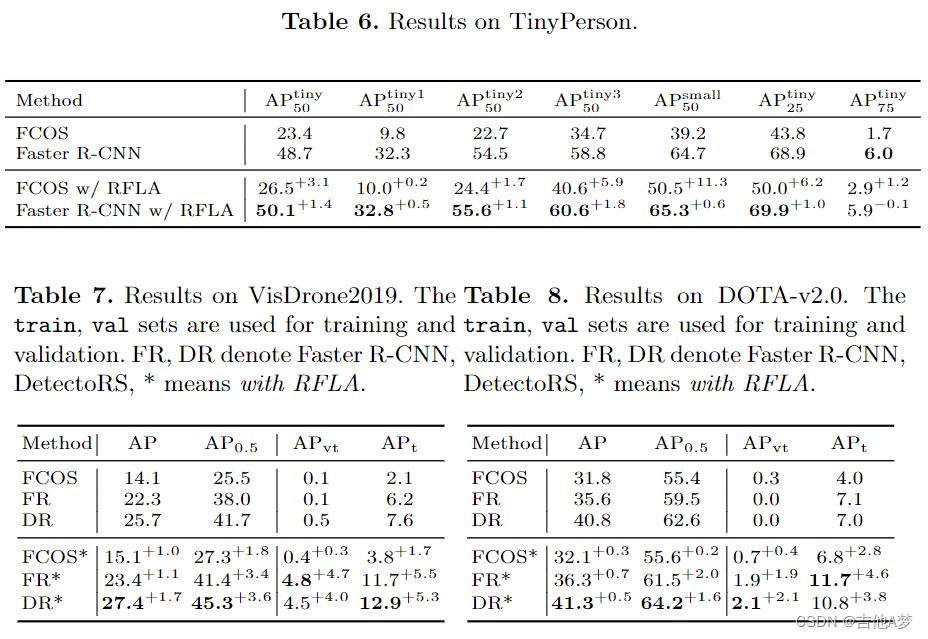
- 各种result。
- 可视化结果。

问题
- 为什么特征图上的点映射回原图上的时候,得到的有效感受野是呈现高斯分布的?
- 有效感受野 t r n tr_n trn 得到的是一个向量吗?
- HLA那里,是给每一个gt分配多个特征点,还是给每个特征点分配多个gt。这一块的没看明白,可能需要看看代码。
- 这篇文章的v1版本中,论文引用没有用有颜色的字体标记,我还以为 [48,51] 这样的东西是一个区间,原来是引用。
- “分层标签分配” 的第一阶段里面,掩码 m 表示的是已经分配了的特征点和未分配的特征点,这个掩码 m 和实例分割中的掩码不是同一个东西。














 2840
2840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









