






前言
在机器学习中,我们所使用的用于分类的数据集通常每个类别的数据量是比较平均的,例如鸢尾花数据集、mnist手写数字数据集等。但是,在实际生活当中,大部分的数据都是不平衡的,即某一类的数据量远远超过其他类别。为此,衍生出了很多算法来解决这个问题,例如采样法尤以SMOTE算法出名。本篇博客会使用前一篇博客所使用到的生成对抗网络模型来生成数据量较小的类别的数据,尽管在最终的测试集的表现实在堪忧,后续我也会继续尝试改变参数或者训练方法对其进行改进,以期达到想要的结果。
使用的数据集以及任务描述
本文取材于我的毕业设计,数据集使用的是MIT-BIH心律失常数据库的心拍数据(详细介绍),预期目标是将其按照AAMI所推荐的标准把心跳数据分为N、S、V、F、Q五类,N类为正常心拍,其余为异常心拍,感兴趣的可以自行百度相关知识或参阅相关文献。在该数据库中所提供的数据里N类的数据量是最多的,分割出来的心拍有几万;相反,其余四类的数据量非常少,尤其是F类,数量只有几百。这就导致了在训练过程中的一些问题,训练后的模型对于后面四类的数据的识别准确率相对较低。就具体任务而言,我们更希望能够获得对于后面心拍的准确率,这样才能及时发现心脏问题。
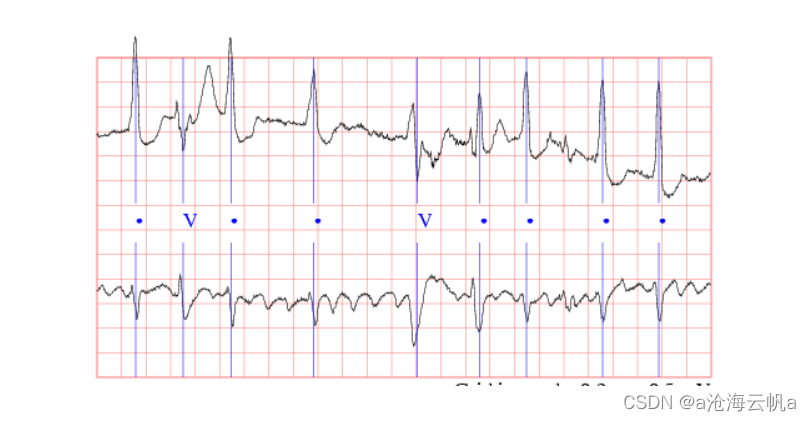
本博客的目标就是使用生成对抗网络产生一些人造数据,用于帮助模型更好的识别数量较少的样本类别的心拍。
代码实现
数据预处理
数据预处理部分的代码请移步和鲸社区,这里仅讲述我的处理思路:
1、获得初始的数据,去噪并完成心拍分割,最后归一化;
2、把这些数据拆分为训练集和测试集;
3、把训练集中的数据的少数量类别分别取出;
4、分别把每一类数据导入生成对抗网络训练;
5、保存生成器模型,生成人造数据并保存;
这里的归一化,我使用的是把数据压缩到[-1,1]之间,保留心拍的幅度0附近起伏,另一个原因也是因为生成器的输出使用的是tanh激活函数。
生成对抗网络模型
本博客使用的模型代码由上一篇博客代码简单改造得来,所以很多地方是相同的,这里只展示核心代码整体的项目代码会放在和鲸社区,代码如下:
在跑代码的过程中,我发现生成器过于简单而鉴别器过于复杂,所以生成器很难得到更好的训练,而我们的目的是获得一个非常良好的生成器,因此这里我为生成器和鉴别器设置了不同的学习率。
adam1 = Adam(lr=0.001,beta_1=0.5)
adam2 = Adam(lr=0.0002,beta_1=0.5)
z_dim = (112,1)
生成器:
g = Sequential()
g.add(Conv1DTranspose(8,32,activation='relu',input_shape=z_dim))
g.add(BatchNormalization())
g.add(Conv1DTranspose(32,32,activation='relu'))
g.add(BatchNormalization())
g.add(Conv1DTranspose(64,64,activation='relu'))
g.add(BatchNormalization())
g.add(Conv1DTranspose(1,64,activation='tanh'))
g.compile(loss='binary_crossentropy', optimizer=adam1, metrics = ['loss'])
此处使用一维反卷积实现类似上采样的功能,生成(None,300,1)维度的心电数据,模型结构和参数如图。

鉴别器:
d = Sequential()
d.add(Conv1D(filters=32, kernel_size=32, strides=1, padding='SAME', input_shape=(300,1)))
d.add(BatchNormalization())
d.add(LeakyReLU(alpha=0.2))
d.add(Dropout(0.2))
d.add(Conv1D(filters=8, kernel_size=32, strides=1, padding='SAME'))
d.add(BatchNormalization())
d.add(LeakyReLU(alpha=0.2))
d.add(Dropout(0.2))
d.add(Conv1D(filters=4, kernel_size=32, strides=1, padding='SAME'))
d.add(BatchNormalization())
d.add(LeakyReLU(alpha=0.2))
d.add(Dropout(0.2))
d.add(Flatten())
d.add(Dense(128))
d.add(LeakyReLU(alpha=0.2))
d.add(Dense(1,activation='sigmoid'))
d.compile(loss='binary_crossentropy', optimizer=adam2, metrics = ['accuracy'])
d.trainable=False
d.summary()
该模型只实现鉴别是否为人造数据,模型结构如图: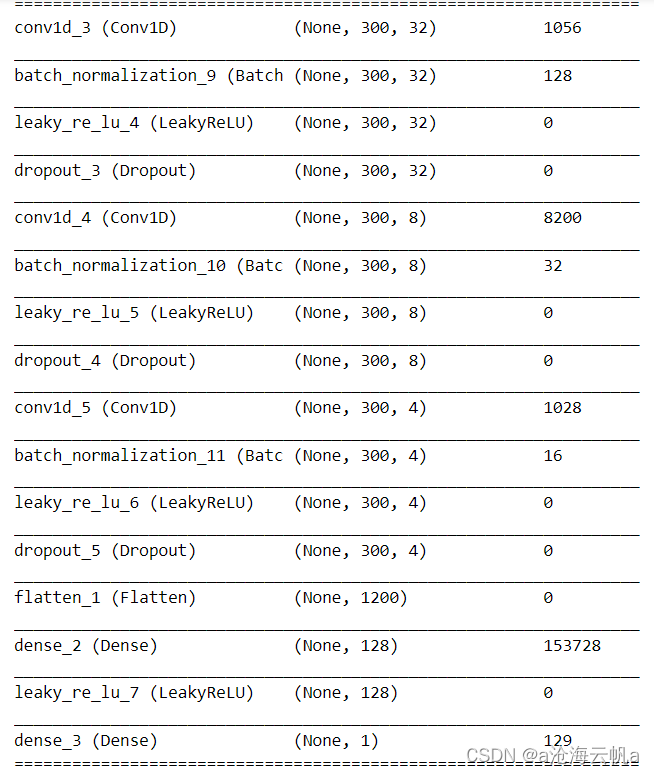
合成生成对抗网络:
inputs = Input(shape=z_dim)
hidden = g(inputs)
output = d(hidden)
gan = Model(inputs,output)
gan.compile(loss='binary_crossentropy',optimizer=adam1,metrics=['accuracy'])
gan.summary()
用于绘制损失函数变化和训练过程中生成器效果的代码:
def plot_loss(losses):
d_loss = losses["D"]
g_loss = losses["G"]
plt.figure(figsize=(10,8))
plt.plot(d_loss,label="Discriminator_loss")
plt.plot(g_loss,label="Generator_loss")
plt.legend()
plt.show()
def plot_generatored(n_ex=3,dim=(1,3),figsize=(12,2)):
noise = np.random.normal(0,1,size=(n_ex,z_dim[0],z_dim[1]))
generatored_images = g.predict(noise)
generatored_images = generatored_images.reshape(n_ex,300)
plt.figure(figsize = figsize)
for i in range(generatored_images.shape[0]):
plt.subplot(dim[0],dim[1],i+1)
plt.plot(generatored_images[i])
plt.tight_layout()
plt.show()
训练函数主体:
losses = {"D":[],"G":[]}
def train(x_train,epochs=1,plt_frq=1,BATCH_SIZE=128):
batchCount = int(x_train.shape[0]/BATCH_SIZE)
print("Epochs:",epochs)
print("Batch size:",BATCH_SIZE)
print("Batches per epoch:",batchCount)
for e in range(1,epochs+1):
if e == 1 or e%plt_frq == 0:
print('-'*15,'Epoch %d' %e,'-'*15)
for _ in range(batchCount):
image_batch = x_train[np.random.randint(0,x_train.shape[0],size=BATCH_SIZE)]
noise = np.random.normal(0,1,size=(BATCH_SIZE,z_dim[0],z_dim[1]))
generatored_images = g.predict(noise)
#train d
#set data set which is composed of 2 parts
x = np.concatenate((np.reshape(image_batch,(-1,300,1)), generatored_images))
#y are labels
y = np.zeros(2*BATCH_SIZE)
y[:BATCH_SIZE] = 0.9
d.trainable = True
d_loss = d.train_on_batch(x,y)
#train g
#set up data set
noise = np.random.normal(0,1,size=(BATCH_SIZE,z_dim[0],z_dim[1]))
y2 = np.ones(BATCH_SIZE)
d.trainable = False
g_loss = gan.train_on_batch(noise,y2)
losses["D"].append(d_loss[0])
losses["G"].append(g_loss[0])
if e==1 or e%plt_frq==0:
plot_generatored()
print('鉴别器损失:',d_loss[0])
print('生成器损失:',g_loss[0])
g.save('./generate_model/Q_%d.h5'%e)
plot_loss(losses)
train(x_train=X_train,epochs=1000,plt_frq=100)
这里我设置了1000轮的迭代并且每百轮保存一次生成器模型,对于四种类别均训练出一个对应的生成器模型,取其中训练最佳的模型。
效果展示
由于生成对抗网络的特殊性,其生成的数据是否合格判断起来比较困难,之后也衍生出了WGAN用于判断生成器的质量。我们的最终目标是获得一个良好的生成器,所以我们需要生成器的损失越小越好,鉴别器的损失越大越好。除此之外就只能依靠人的直观感受了。
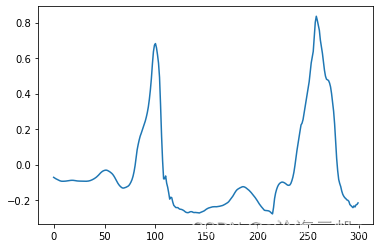
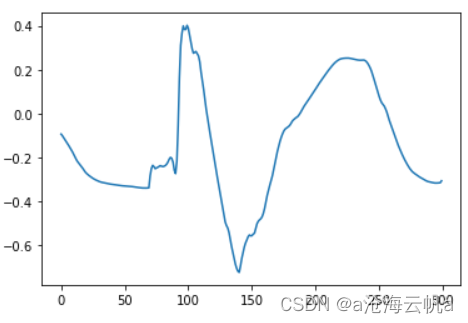
下图是V类的原始数据中的一张(已去噪和归一化):
下面是生成器生成的V类数据:
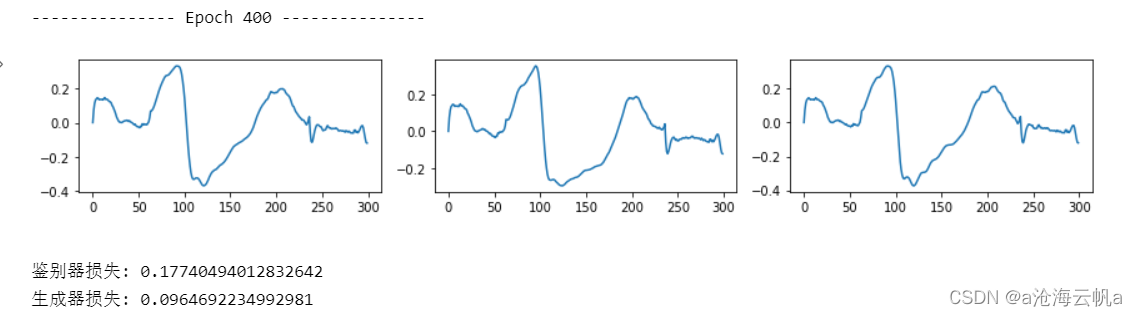
还是可以明显的感觉到,人造数据比原始数据还有很大差距。
这是Q类数据,属于未定义的数据:
这是Q类人造数据:
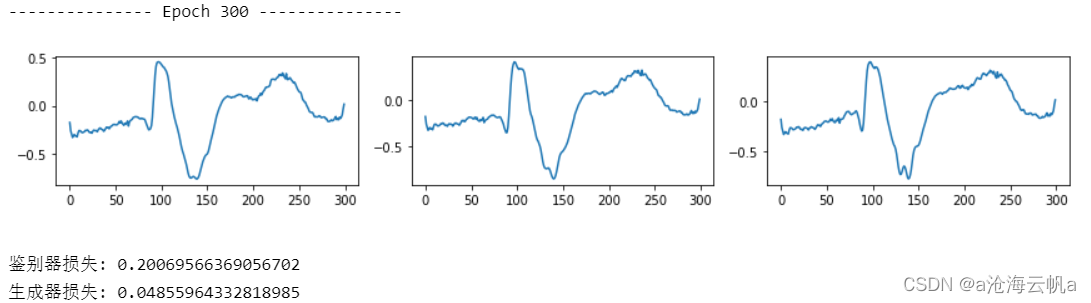
未定义的Q类是我所使用的模型训练出来的生成器里生成数据最好的一类,当然,还是可以看到人造数据相对来说看起来仍有一些类似于噪声的干扰。
最合适的用于判断生成器效果的当然是将其用于分类模型的训练,但是,非常遗憾,目前我得到的数据并没能帮助模型变得更加优秀,反而对模型有很大的拖累。如下图: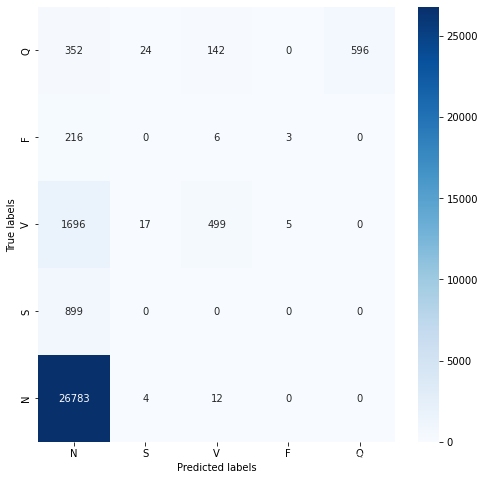
可以发现这样的模型完全没有达到预期目标,对比我使用SMOTE算法扩充的数据训练出来的效果,差之甚远。
总结
尽管在测试集上的数据分类效果很差劲,但是在训练过程中的训练集的效果是比较好,下图是训练的准确率变化:
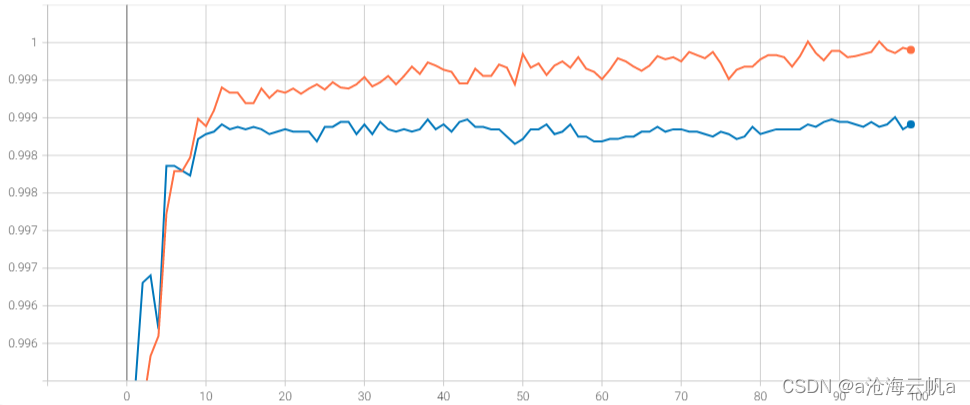
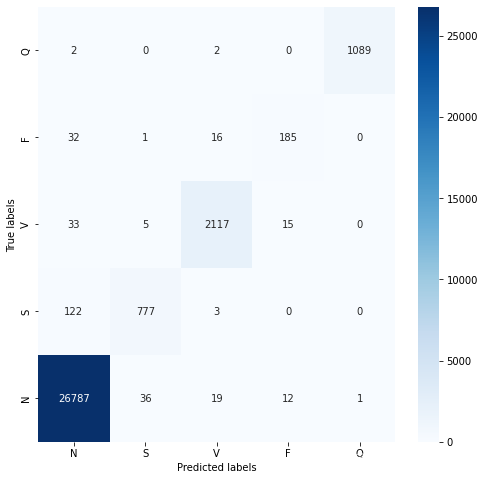
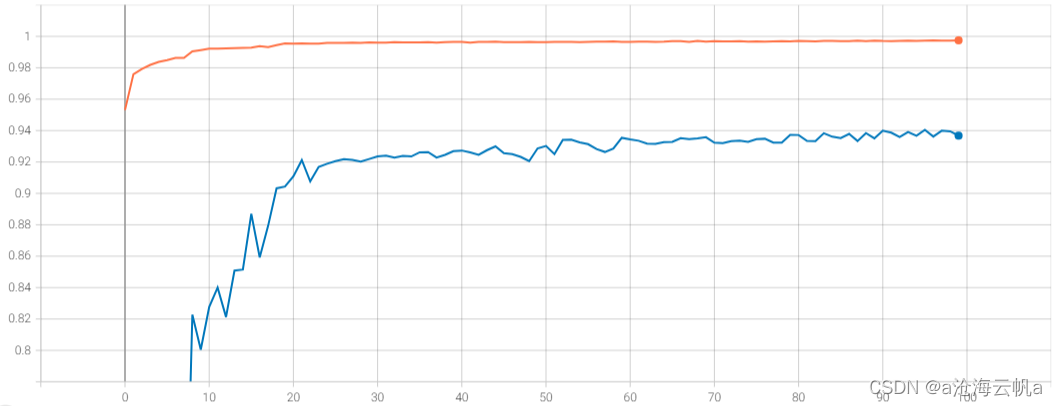
对比smote算法的训练过程:
分类混淆矩阵:
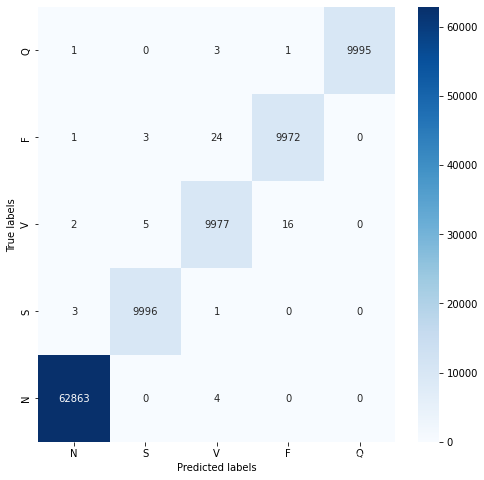
可以发现,模型还是较好的学习到了心拍数据的一些特征的,但是在测试集上的表示确实过于差劲了,我觉得可能的原因可能是:
1、首先也是最可能的原因就是生成器生成的数据是有问题的,因为生成器模型是比较简单的,而且使用的是反卷积的方式来生成这种时域特征很强的数据,这种人造数据很难“蒙骗”分类模型;
2、其次,分类模型把训练的重点放在了人造数据的那部分,导致训练集的效果不错,但测试集上效果很差;
3、最后,就是模型出现了过拟合现象,但从SMOTE算法的扩充数据的训练过程看,这种情况不太可能。
后面可以保留鉴别器模型,在人造数据导入前使用鉴别器鉴别,鉴别为非人造数据的那部分数据才加入到训练集中,或许表现会更好一些。
我还在尝试更改生成对抗网络的模型结构、参数等,期望可以获得更好的效果。
全部代码,请移步和鲸社区生成对抗网络——ECG数据不平衡优化

















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









