







1.什么是图嵌入
- 将图中的每个节点映射为一个低维的向量表示,映射后的向量应尽可能多的保留原图中节点的关键信息,以便更好地进行下游任务。
2.哪些信息需要被保留?
- 不同的图嵌入算法信息保留的侧重点也不一样,根据不同的下游任务,原图中需要保留的信息重要性程度也不一样(例如节点的邻域信息,结构角色,社区信息等)。
3.如何保留关键信息?
- 大多数技术共同思想就是(个人理解:先给节点一个随机表示,定义一个损失函数,不断迭代优化损失函数来学习节点表示),利用嵌入域中的节点表示,重构出要保留的图域信息(因为良好的节点表示应该能够重构出希望保留的原图关键信息),所以整个节点嵌入的学习过程就是,最小化重构误差来学习这个映射。
4.图嵌入通用框架
- 映射函数:将节点从图域映射到嵌入域
- 信息提取器:提取图域中需要保留的关键信息Q
- 重构器:利用嵌入域的嵌入信息,重构图的关键信息Q,重构后的信息为Q’
- 优化:以提取的关键信息Q和重构的信息Q’为目标优化(定义损失函数),学习映射函数及重构器涉及的参数

5.DeepWalk嵌入算法–保留节点共现关系
-
映射函数
得到每个节点的映射(每个节点的one-hot编码e与训练出的权重矩阵W相乘,结果即此节点映射,权重矩阵每一行表示一个节点的映射),one-hot维度1×N,权重矩阵W维度N×d,映射后向量维度1×d。权重矩阵系统会给一个初值,通过优化损失函数来学习权重矩阵,权重矩阵得到之后,意味着每个节点的嵌入表示也得到。

-
信息提取器:根据随机游走提取节点的共现信息
随机游走(Randow walk):给定一个图节点,从它的邻居节点中随机选取一个并前进到这个节点,接着从选中的节点中重复此过程,直至访问T个节点。这些被访问的节点组成的序列,即图上长度为T的随机游走。为每个节点生成γ个长度为T的随机游走序列。

Random Walk & Skip-gram:随机游走看成自然语言中的句子,节点集是句子中的词汇表,中心节点和其上下文节点(Vcon,Vcen)视为一个共现元组。遍历每个随机游走序列中的节点,将提取到的共现元组添加到信息提取器中。第二步信息提取器的工作完成(提取有共现关系的元组)

-
重构器:根据嵌入信息重构原图共现信息
对于原图中的共现元组,一个良好的嵌入,应该能够推断出原图的信息。这里原图的重要信息就是共现元组,所以重构器对元组出现的概率进行建模,认为共现元组出现的概率要尽可能大,这样学习到的嵌入意味着尽可能的保存了原图中的共现信息。
图注:每个节点有两种映射(中心节点映射+上下文节点映射)

图注:对元组概率建模(softmax),重构器中的共现元组/该中心节点其他所有节点生成的元组(此概率越大,表明嵌入域学习到的共现信息越多)
 图注:对所有共现元组出现的概率建模(利用嵌入域重构图域提取的共现元组信息)
图注:对所有共现元组出现的概率建模(利用嵌入域重构图域提取的共现元组信息)

图注:去掉上式中的重复元组,幂数表示重复元组的频次

-
优化器:(学习目标单词和上下文权重参数)
优化目标是将上式所有共现元组的概率最大化,为了使用梯度下降,取上式负对数,使目标函数最小化,通过多次迭代更新学习,权重参数即更新完成

6.加速DeepWalk学习过程
- 分层softmax
直接计算元组出现的概率时,分母计算量很大,要对所有节点求和。将图的节点当成二叉树的叶子结点,通过二叉树从根节点到叶子结点路径,对共现元组出现的概率建模(中心节点作为输入的二分分类器,分类器不断地选择路径的下一节点)。

图注:从根节点b0前进到左侧节点的概率

图注:从根节点b0前进到右侧节点的概率

图注:节点8和节点3共现的概率

-
负采样
选取与中心节点没共同出现的节点,形成负样本,并定义如下的目标函数,使来自正样本的概率最大化,负样本的概率最小化,来学习节点的表示,和softmax相比,计算复杂度明显降低。softmax分母需要对所有节点求和,负采样只需K个负样本求和。

-
实际训练过程
批处理(batch)方式完成的,每生成一个随机游走序列W后,提取共现信息,基于共现信息形成目标函数,基于目标函数计算梯度,执行所涉及节点的更新。
7.node2vec嵌入–保留节点共现信息
- 一种有偏的随机游走,根据一定的概率选取下一邻居节点,生成随机游走序列之后,提取共现信息,根据嵌入域重构原图共现元组,优化目标函数,学习参数。和DeepWalk过程一样,区别就是生成随机游走时,DeepWalk选取下一节点是等概率的。
- 在决定下一节点t+1时,既考虑当前t节点,又考虑t-1节点,dis表明最短路径长度,p和q是两个超参数。P值小,优先选取离t-1较近的节点,类似于广度优先搜索,使类似结构的节点表示相似。如果q值小,选取下一节点时离t-1远,相当于深度优先搜索,使邻居节点表示相似。



- 边的Embedding
可以对节点的Embedding进行平均
8.LINE:Large-scale Information Network Embedding
- 引入二阶相似度概念(如果两个节点的邻居节点相似,那么这两个节点的映射向量也是相近的),和前面的随机游走最大区别在于重构的信息是边,而不是游走序列中的元组,也可以看成长度为1的游走序列的特例。
- 一阶相似性
两个节点的联合概率分布(对两个节点的嵌入向量sigmoid,求出概率),经验概率分布(两节点边的权重 / 图中所有边的权重和),损失函数(两个分布的距离)。KLdiversion(求两个分布的距离),对KLdiversion化简(边的权重是固定值,对其没影响),得到左下侧等式。

- 二阶相似性
联合概率(给定节点 i 下产生邻居 j 的概率),经验概率(节点 i 和 j 边的权重 / 节点 i 所有边的权重),算两个分布的KLdiverison,最终化简如左下式。
- 一阶和二阶embedding训练完成后,直接拼接两个embedding即节点的最终嵌入表示。
9.struc2vec嵌入算法–保留结构角色
-
保留节点共现方法,学习到的嵌入域,使邻近节点的嵌入向量相似。对于有些下游任务,可能希望更多的保留节点结构信息(使结构角色相似的节点,嵌入域向量相近)。

-
距离信息
f:节点u和v在k跳邻居下的相似性;R:节点的K跳邻居集合;S(s):对集合s中的点按照度排序;g:俩个节点度序列的距离。(对于长度不同的序列使用DTW动态时间调整算法)

-
为什么用DTW算度序列之间的距离
节点各阶度序列之间距离近,说明节点在图上结构相似(节点结构相似的定义),衡量节点在图上结构的相似性。 -
构建多层带权重图
根据两两节点在K跳邻居下的相似度构建每层边的权重,

-
顶点采样序列
本层游走的概率:U和V边的权重 / 和U相连的所有边的权重和。

-
使用Skip-Gram生成节点embedding
根据在多层权重图上的游走序列(选取图中中边权重大的节点=即度序列比较相似的节点=结构相似的节点),提取共现元组,生成节点嵌入向量(和DeepWalk过程一样,只是序列生成的方式不一样,这里侧重于提取节点的结构信息),实际应用中应根据不同的下游任务(各下游任务需要提取图的信息侧重点不一样)选择不同的嵌入算法。
10.SDNE:Structural Deep Network Embedding
-
Deepwalk,node2vec,LINE,struc2vec使用了浅层结构,不能捕获高度非线性网络结构,产生了SDNE方法,使用多个非线性层捕获node的Embedding
-
算法流程:输入图的邻接矩阵第i行的值,带入encoder中压缩,学习到的中间向量(Embedding),用decoder将Embedding解码成输入向量相同维度的向量
-
二阶损失函数: 输出向量和输入向量的均方误差,如果i和j节点不相连,b向量=1,如果i和j节点相连,b向量>1,更关注相连接的接点。
-
一阶损失函数:相邻接点的均方误差。

- 总优化目标:一阶+二阶+正则项
- 为什么正则项有权重参数:削弱权重参数对模型的影响(权重参数是训练数据训练出的),提高模型的泛化能力。

11.总结
- DeepWalk:采用随机游走,形成序列,采用skip-gram方式生成节点的embedding
- node2vec:不同的随机游走策略,形成序列,类似于skip-gram方式生成节点embedding
- LINE:捕获节点的一阶和二阶相似度,分别求解,再将一阶和二阶拼接在一起,作为节点的embedding
- struc2vec:对图的结构信息进行捕获,在其结构重要性大于邻居重要性时,有较好效果
- SDNE:采用多个非线性层的方式捕获一阶和二阶相似性
12.保留节点状态的图嵌入算法
-
节点状态=节点共现信息+节点的全局状态
保留共现信息的组件:与前面介绍的DeepWalk,Node2vec一样
保留全局状态的组件:目的不是保留图中节点的全局状态分数,而是保留他们的全局状态分数排序,重构器恢复排序信息 -
提取器
计算节点的全局状态分数(Degree Centrality,Betweenness Centrality等中心性度量方式均可计算全局状态分数),获得全局状态排名,对其降序排列。 -
重构器
从嵌入域中恢复提取器中的排名信息,重构器对节点的相对排序建模
图注:对节点 i 在节点 j 之前的概率建模
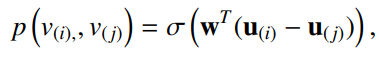
图注:重构节点的全局信息
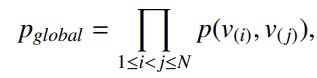
图注:优化目标函数,该目标函数可以和保留共现信息的目标函数结合,使学习到的节点可以留共现信息和全局状态
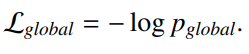
13.modularity(模块度最大化)–保留社区结构信息
-
保留面向节点的结构信息
一种是节点对的连接信息,另一种是节点邻域的相似度信息。这两种信息都可以从原图中提取,并以矩阵形式表示。 -
提取器
提取节点对的连接信息:表示成邻接矩阵A的形式
提取邻域相似度信息:表示成矩阵S
图注:Ai 表示邻接矩阵的第 i 行,即节点 i 的邻域信息,当节点 i 和 j 共享的邻居越多时,Sij就越大

-
重构器和目标
重构器旨在恢复 A 和 S 这两种类型的信息,为了同时重构它们,对两个矩阵线性组合,n 控制领域相似度的重要程度。
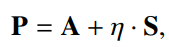
目标函数:W是两个映射函数的参数,与DeepWalk设计相同
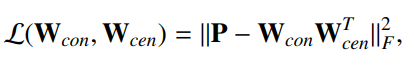
-
保留社区结构–模块度最大值(modularity)
模块度Q衡量社区内的边数在给定图和随机图之间的差别,较大的Q表明发现了更好地社区,可以通过最大化模块度Q来检测社区。
图注:代表随机生成图中节点 i 和 j 之间有边连接的可能性(节点的度相乘 / 图的度),h表示 i 和 j 同属于某一社区的标识符值,假定有2个社区
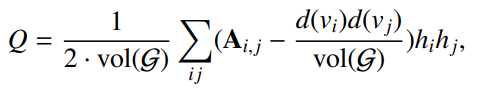
图注:简化成矩阵表示
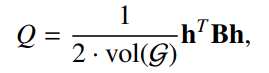
图注:去掉某些常数项后,Q化简如下,H的每一列表明一个社区,每一行表明一个节点属于某个社区的one-hot编码,tr表示矩阵的迹。

-
总体目标
同时保留节点的结构信息和社区结构信息,引入矩阵C重构指示矩阵H(将社区信息和节点表示联系在一起)
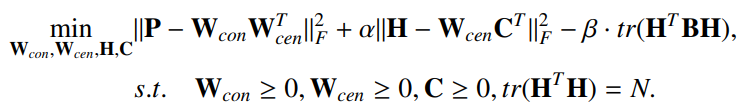














 1298
1298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









