







layout: post
title: “yolov5算法笔记1”
date: 2024-4-22 00:32:30 +0800–
categories: [日志]
tags: [yolov5]
1. YOLOv5目标检测基本思想
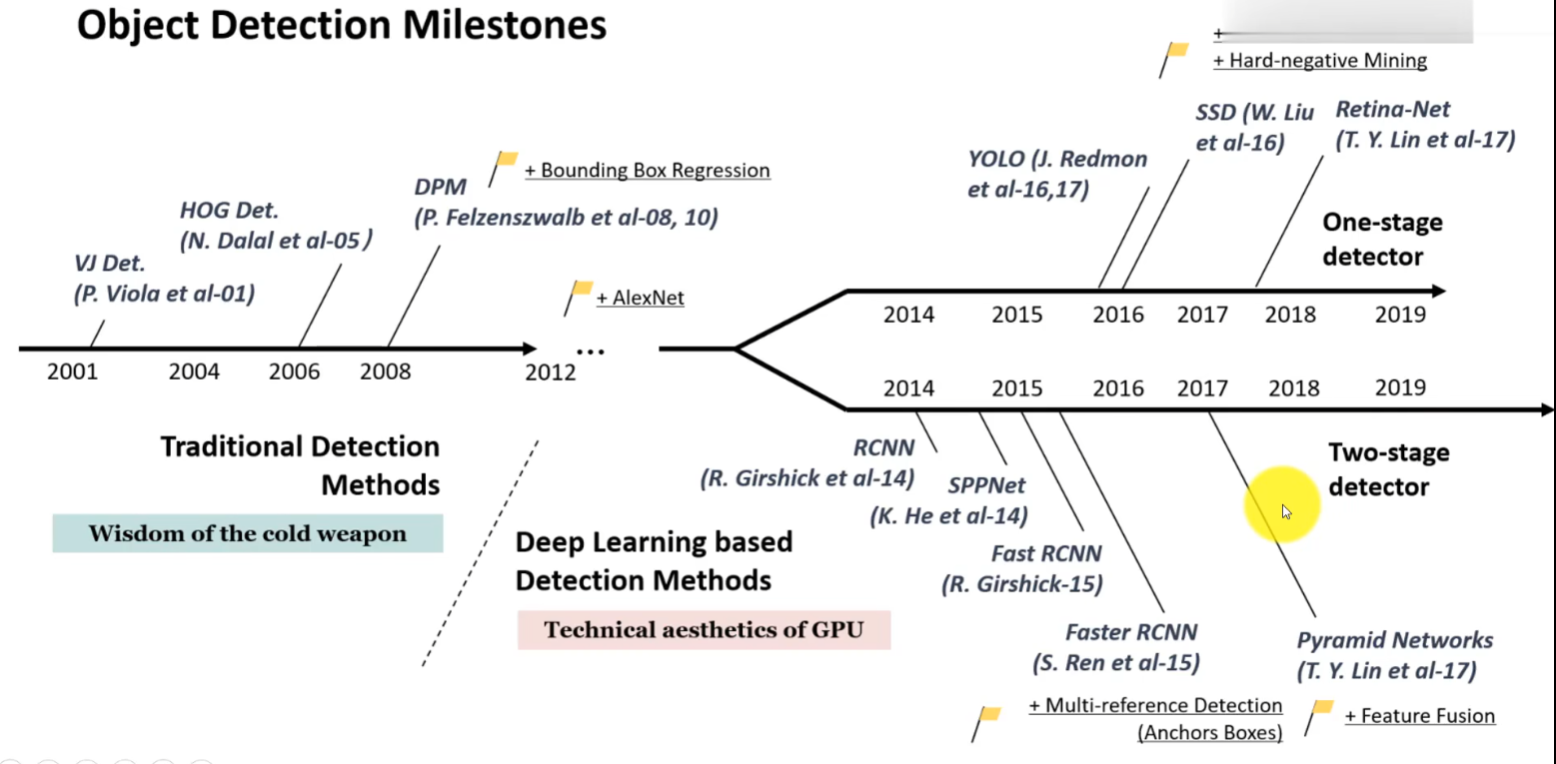
1.1 目标检测的两个发展类型
| 目标检测类型 | 代表网络 | 特点 | 理解 |
|---|---|---|---|
| one-tage detector | YOLO、SSD、Retina-net | 仅用一个CNN网络来直接产生物体的类别概率和位置坐标值 | 准确性不高,但速度快。 |
| two-tage detector | Faster-RCNN | 增加了产生候选区域(Region Pproposal)的阶段,在候选框的基础上得出判定框 | 错误率低,但同时漏洞识别率低,速度慢,不适合实时监测场景。 |
1.2 二者结构图
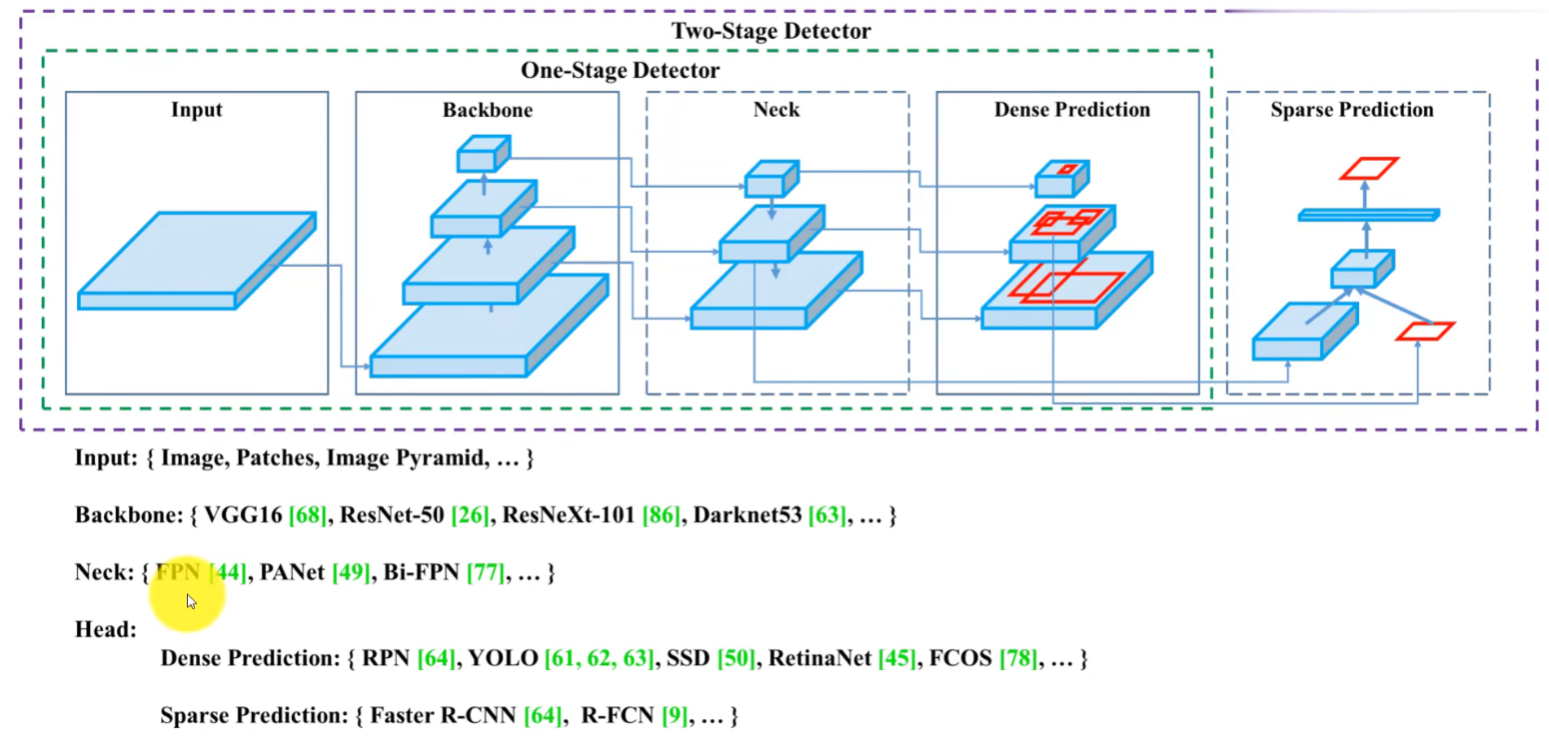
| 局部结构 | 功能 | 理解 |
|---|---|---|
| input | ||
| Backbone(主干网络) | 深度学习骨干网络 | 负责提取特征值,包括结构信息和边缘 |
| Neck(颈部) | 多尺度特征图融合,包括一系列的卷积层、池化层,确保从主干网络提取的特征能够被传递到检测头中 | 连接骨干和头部,有助于进一步整合特征并调整它们以更好地适应检测任务。 |
| Dense Prediction | 预测边界框和类别,单阶段检测器,候选框比较密集 | 当需要对图像中的小目标或者细节进行准确的定位和分析时,密集预测效果较好 |
| Sparse Prediction | 预测边界框和类别,双阶段检测器,候选框比较稀疏 | 稀疏预测会牺牲细节信息,但能提高效率,特别是在处理大尺寸图像或视频时。稀疏预测的应用取决于具体需求,有时可以通过合适的采样或策略来平衡精度和效率 |
1.3 目标检测过程
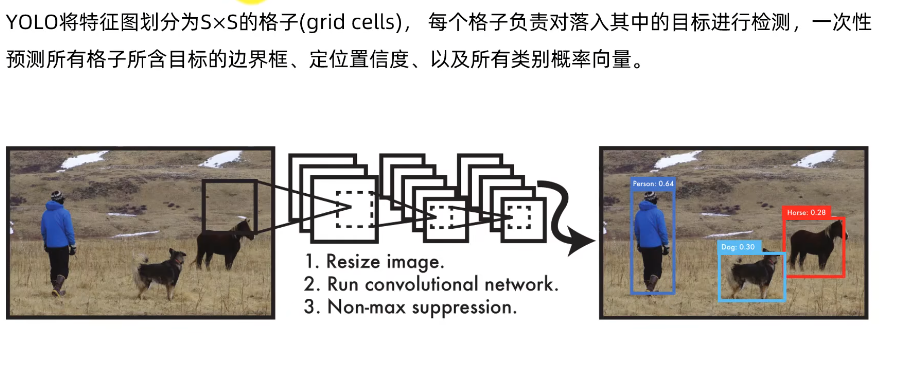
| 检测过程 | 理解 |
|---|---|
| 1. Resize image. | 图片缩放 |
| 2. Run convolutional network. | 卷积网络 |
| 3. Non-maix suppression. | 非最大抑制,用于边缘检测和目标检测 |

| 基本思想 | |
|---|---|
| 1 经过卷积网络把图片划分为S*S的网格 | |
| 2 到物体的bounding boxes+confindence | 2 Class Probability map类别概率图 |
| 3 得到最终检测结果 |
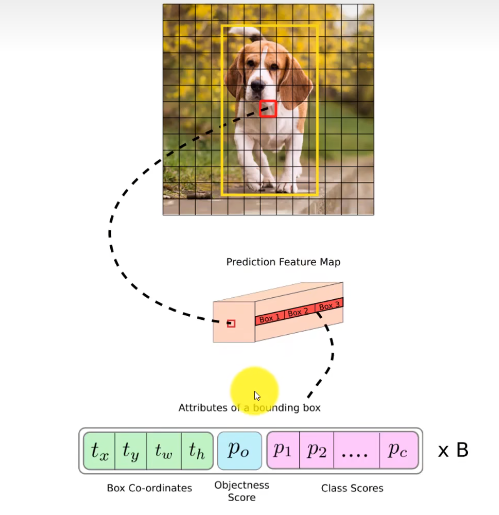
| 理解 | |
|---|---|
| box co-ordinates (边界坐标框) | 指定了图像中检测到的对象的位置和范围 |
| objectness score | 指示给定边界框中包含感兴趣对象的置信度 |
| class scores | 表示模型对每个类别的预测置信度,可能是哪个分类,每个类别的不同得分 |
| 后面乘以B是指有多少个边界框的预测。多边界框预测是在每个尺度下,对图像进行密集的边界框预测,以尽可能地覆盖可能包含目标的区域。这些边界框在位置、大小和形状上会有所不同,以尝试捕捉目标的各个部分和姿态。 |
1.4 多尺度融合
多尺度融合通过引入多个不同尺度的特征图,可以提供更全面的特征表示,从而改善目标检测的效果。
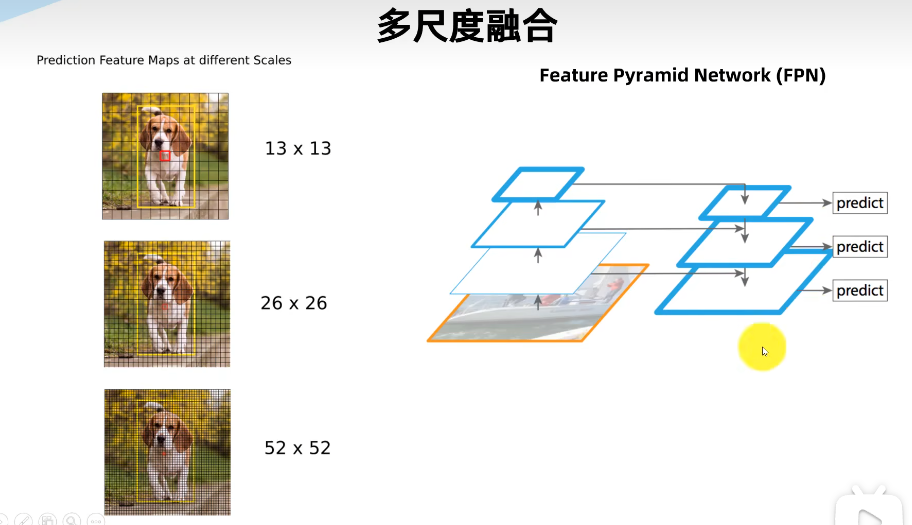
| 步骤 | 作用 |
|---|---|
| 1.特征提取 | 使用卷积神经网络(CNN)从输入图像中提取多个不同尺度的特征图 |
| 2.尺度融合 | 将来自不同尺度的特征图进行融合,通过上采样或下采样等操作,使它们具有相似的分辨率或尺寸 |
| 3.信息整合 | 融合后的特征图与原始的单一尺度特征图相结合,以保留每个尺度的信息,并且加强对不同尺度目标的检测能力 |
| 4.目标检测 | 使用综合后的特征图进行目标检测,其中包括了多个尺度的信息,从而提高了算法的准确性 |
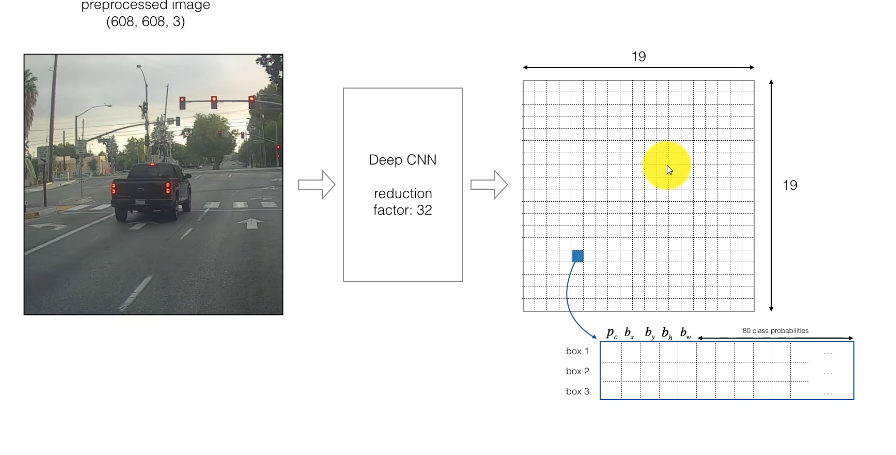
输入原图大小为608x608大小,通过大小为32倍率的下采样之后,原图被分割为19x19的大小进行目标检测后得到三个边界框。每个边界框中的结果分别有位置信息,目标得分(置信度),分类得分。
| 思考 | |
|---|---|
| 多尺度融合与多边界框预测是否在工作内容上有重复范围? | 多尺度融合和多边界框预测在YOLO中是两个不同的概念,它们之间没有直接的重复。 多尺度融合是指在网络的不同层次(或不同尺度)上检测目标,以便捕捉不同大小和分辨率的目标。这可以提高算法对于各种尺度目标的检测性能。 多边界框预测则是在每个尺度下,对图像进行密集的边界框预测,以尽可能地覆盖可能包含目标的区域。这些边界框在位置、大小和形状上会有所不同,以尝试捕捉目标的各个部分和姿态。 |
| 多尺度融合和多边界框预测是相互配合的,通过在不同尺度上进行边界框的预测,并结合多尺度信息,来提高目标检测的准确性。 |
1.5锚框机制.
锚框预测是指在目标检测任务中使用预定义的一组框来尝试捕捉图像中可能包含目标的区域。这些预定义的框通常被称为锚框(anchor boxes)或者先验框(prior boxes)。
在目标检测算法中,锚框预测通常与卷积神经网络(CNN)结合使用。CNN会对输入图像进行特征提取,并在每个位置上对图像进行密集的锚框预测。每个锚框都有多个属性,如位置、大小和长宽比等。这些属性会在训练过程中进行学习,以使得模型能够更准确地预测目标的位置和类别。
| 思考 | |
|---|---|
| 锚框预测和多边界框预测有何关系? | 锚框预测通常用于初始化目标检测过程,提供一组初始的候选框,用于覆 盖可能包含目标的区域。 多边界框预测则是在锚框的基础上进行进一步的细化和调整,以更准确地确定目标的位置和形状。 在一些目标检测算法中,如Faster R-CNN,首先会使用锚框预测来生成候选框,然后再使用分类和回归网络对这些候选框进行进一步的分类和精细化。 |
1.6 yolov5算法思想
| grid cells | grid cells是指将输入图像划分成固定大小的网格,每个网格称为一个grid cell。每个grid cell通常包含一个固定尺寸的边界框,模型在每个grid cell内进行目标检测和分类预测。 |
| GT | GT"通常指的是"Ground Truth",即真实标签或真实数据。在目标检测任务中,GT通常是指标注在训练数据上的真实目标位置和类别信息。 |
首先通过特征提取网络对输入图像提取特征,得到一定大小的特征图,
比如13x13 (相当于416x416图片大小),然后将输入图像分成13x13个grid cells.
YOLOv3/v4: 如果GT中某个目标的中心坐标落在哪个grid cell中,那么就由
该grid cell来预测该目标。每个grid cell都会预测3个不同尺度的边界框。
YOLOv5: 不同于yolov3/v4,其GT可以跨层预测,即有些bbox在多个预测
层都算正样本;匹配数范围可以是3-9个。
预测得到的输出特征图有两个维度是提取到的特征的维度,比如13x13,还有一个维度(深度)是Bx (5+C)
注: B表示每个grid cell预测的边界框的数量(YOLO v3/v4中是3个) ;
C表示边界框的类别数(没有背景类,所以对于VOC数据集是20) ;
5表示4个坐标信息和一一个目标性得分( objectness score)。
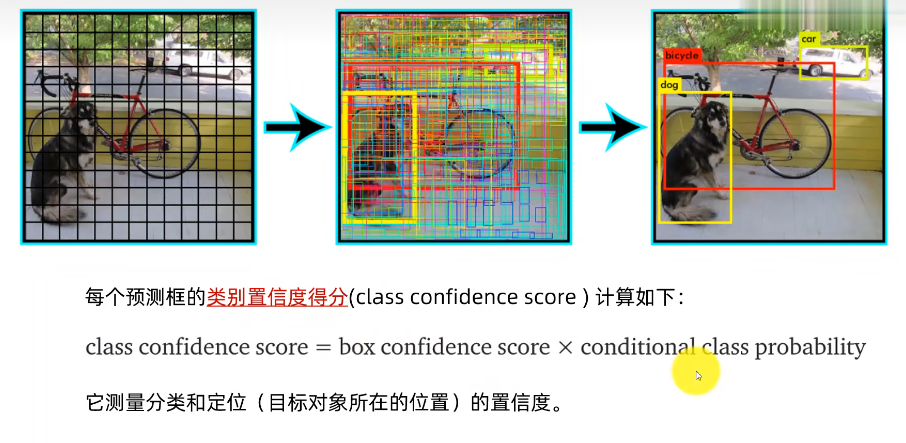

| 名词 | 理解 |
|---|---|
| pr(object) | 表示目标存在于一个网格单元格内的概率 |
| IOU(交并比) | 衡量了预测边界框与真实边界框之间的重叠。它通过将两个框之间的交集面积除以它们的并集面积来计算。较高的IOU表示预测和真实边界框之间有更好的对齐。 |
| pre(class|object) | 在YOLO的输出中,每个边界框都有一个与之相关的类别概率向量,向量的长度等于类别的数量。然后,通过应用softmax函数,将这个向量转换成概率分布,使得每个类别的概率值在0到1之间且总和为1 |


| 步骤 | |
|---|---|
| 1.输入 | 一组检测结果,每个检测结果通常由四个值组成:边界框的坐标(通常是左上角和右下角的坐标)、检测得分和类别概率 |
| 2.按照得分排序 | 检测结果按照其检测得分进行降序排列 |
| 3.选择最高得分的边界框 | 排好序的检测结果中选择得分最高的边界框,并将其添加到最终输出列表中 |
| 4.计算重叠区域的交并比(IoU) | 对于剩余的边界框,计算它们与已选边界框的重叠程度,通常使用交并比(IoU)进行衡量 |
| 5.移除重叠边界框 | 若某个边界框与已选边界框的IoU值大于预先设定的阈值(通常是0.5) |
| 6.重复步骤3至5 | 重复进行这些步骤,直到所有的边界框都被处理 |
| 7.输出 | 最终输出的是经过非极大值抑制处理后的边界框列表 |















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









