









文章目录
HighLight
- 牛顿法将目标函数近似为二阶函数,沿着牛顿方向进行优化(包含了Hession矩阵与负梯度信息)。
- 阻尼牛顿法在更新参数之前进行了一维搜索确定步长,确保沿着下降的方向优化。
- 拟牛顿法用常数矩阵近似替代Hession矩阵或Hession矩阵的逆矩阵,不用求偏导与求逆,简化运算。
- 高斯牛顿法用于解决非线性最小二乘问题。
前言
牛顿法可以用于求解非线性方程的根(零点),也可以用于求函数的极值点。当问题是求非线性方程的根时,f(x)=0;当问题是求函数的极值点时,f(x)'=0,也就是我们常见的最优化问题。本文主要基于最优化问题对牛顿法进行介绍。仅供学习参考,请主要甄别。
1. 基本牛顿法


对于高维情况:
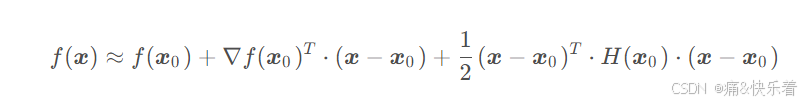
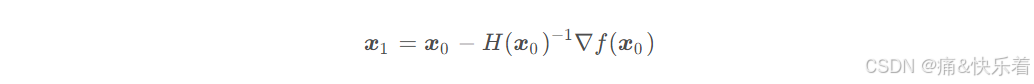
其中,H是海森矩阵:
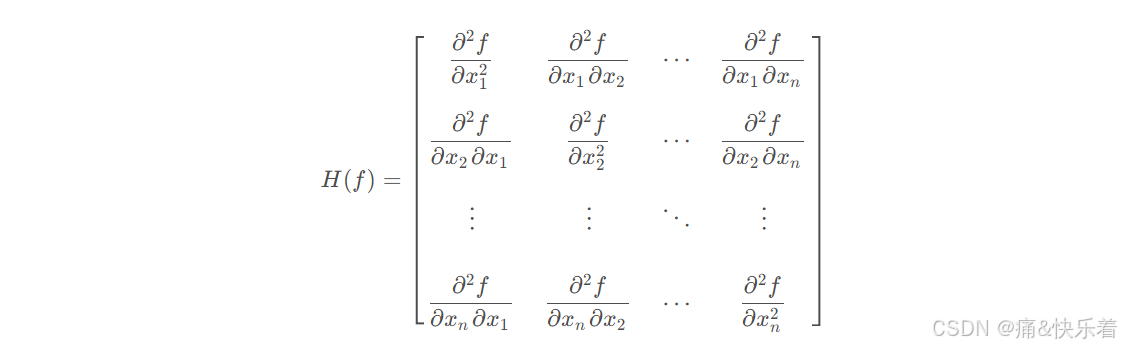

优点:
二阶收敛:收敛速度快,尤其适用于初始猜测接近实际解的情况。
缺点:
计算复杂:每一步都需要求解目标函数的Hessian矩阵的逆矩阵。
局部收敛:当初始点选择不当时,可能导致不收敛。
条件苛刻:要求函数二阶连续可微,且Hessian矩阵可逆。
f=@(x1,x2) (x1-4)^2+(x2+2)^2+1;
[X,result]=Min_Newton(f,[-0.6 0.2],1e-6,100)
function [X,result]=Min_Newton(f,x0,eps,n)
TiDu=gradient(sym(f),symvar(sym(f)));% 计算出梯度表达式
Haisai=jacobian(TiDu,symvar(TiDu));%计算出海塞矩阵表达式
Var_Tidu=symvar(TiDu); %梯度表达式中变量的个数
Var_Haisai=symvar(Haisai); %海塞矩阵中变量的个数
Var_Num_Tidu=length(Var_Tidu); %梯度的维数
Var_Num_Haisai=length(Var_Haisai); %海塞矩阵的维数
TiDu=matlabFunction(TiDu);%将梯度表达式转换为匿名函数
flag = 0;
if Var_Num_Haisai == 0 %海塞矩阵变量的个数为零,也就是说海塞矩阵是常数
Haisai=double((Haisai));
flag=1; %海塞矩阵为常量的标志
end
%求当前点梯度与海赛矩阵的逆
f_cal='f(';
TiDu_cal='TiDu(';
Haisai_cal='Haisai(';
for k=1:length(x0) %求得初始变量的x0的元素个数
f_cal=[f_cal,'x0(',num2str(k),'),'];%组装f_cal=f(x0(k))求得该点函数值
for j=1: Var_Num_Tidu %求得梯度中的元素个数
if char(Var_Tidu(j)) == ['x',num2str(k)]
TiDu_cal=[TiDu_cal,'x0(',num2str(k),'),'];%组装TiDu_cal=TiDu_cal(x0(k)求得该点梯度值
end
end
for j=1:Var_Num_Haisai
if char(Var_Haisai(j)) == ['x',num2str(k)]
Haisai_cal=[Haisai_cal,'x0(',num2str(k),'),'];%组装Haisai_cal=Haisai_cal(x0(k)求得该点海塞矩阵的值
end
end
end
Haisai_cal(end)=')'; %完成海塞矩阵封装
TiDu_cal(end)=')';%完成梯度封装
f_cal(end)=')';%完成函数封装
switch flag %根据标志位判断海塞矩阵表达式中是否有参数
case 0 %有参数
Haisai=matlabFunction(Haisai);
dk='-eval(Haisai_cal)^(-1)*eval(TiDu_cal)';
case 1 %无参数
dk='-Haisai^(-1)*eval(TiDu_cal)';
Haisai_cal='Haisai';
end
i=1;
while i < n %设置最大迭代次数n
if rcond(eval(Haisai_cal)) < 1e-6 %计算海塞矩阵的条件数 条件数越大,逆阵结果越不稳定
disp('海赛矩阵病态!'); %条件数超出范围,示为病态矩阵
break;
end
x0=x0(:)+eval(dk); %eval函数将字符串转换为指令
if norm(eval(TiDu_cal)) < eps
X=x0;
result=eval(f_cal);
return;
end
i=i+1;
end
disp('无法收敛!'); %超出迭代范围
X=[];
result=[];
end
2. 阻尼牛顿法
该方法在基本牛顿法的基础上进行了改进,通过加入线搜索技术来确定步长。在确定了迭代方向后,阻尼牛顿法会在该方向上进行一维搜索,以找到使得函数值在该方向上最小的迭代步长。
当初始点距离最优解较远时,Hession矩阵不一定正定,迭代不一定收敛,因此引入了步长因子α
带步长因子的牛顿法,即阻尼牛顿法,迭代步骤如下:

优点: 这种改进确保了迭代过程沿着下降的方向进行优化,从而提高了算法的收敛性和稳定性。当Hessian矩阵均为正定时,阻尼牛顿法可以得到整体收敛性。
2.1 MATLAB实现
function [x_min, f_min] = NewtonMethod_Damping(f,x0,eps,N)
if nargin<2, x0 = [0,0]; end
if nargin<3, eps=1e-4; end
if nargin<4, N=100; end
syms x1 x2 a
f_fun = matlabFunction(f);
k = 0;
fprintf('阻尼牛顿法迭代开始(采用牛顿法进行一维搜索步长alpha):\n')
fprintf('函数f(x) = %s迭代开始:\n',f)
while true
k = k + 1;
hs = hessian(f); % 海塞矩阵
hs_x0 = double(subs(hs,[x1,x2],x0));
df = [diff(f,1,x1),diff(f,1,x2)]; % 梯度
df_x0 = subs(df,[x1,x2],x0);
dk = double(vpa(df_x0))/hs_x0;
x = x0 - a * dk;
% 求迭代步长
fa = f_fun(x(1),x(2));
a_value = Newton_minValue(fa); % 使用一维牛顿法求解最优迭代步长
x = subs(x,a,a_value);
fprintf('k=%2.d, x_k=[%7.4f, %7.4f]^T, x_k+1=[%7.4f, %7.4f]^T, alpha=%7.4f\n',...
k,x0(1),x0(2),x(1),x(2),a_value);
if norm(abs(x -x0),2) < eps
x_min = x;
f_min = f_fun(x(1),x(2));
fprintf(['已收敛!\nk=%2.d, x_k=[%7.4f, %7.4f]^T, x_min=x_k+1=[%7.4f, %7.4f]^T,' ...
' f_min=%8.4f\n'],k,x0(1),x0(2),x(1),x(2),f_min);
break
end
if k > N
x_min = x;
f_min = f_fun(x(1),x(2));
fprintf('超过最大迭代次数%N, 请调整容许误差或者最大迭代次数!\n',N)
break
end
x0 = x;
end
end
function [x_star,f_star] = Newton_minValue(f_sym,x0,eps,N)
% f_sym为所求函数, 符号函数
% x0为初始点,默认为0
% eps为允许误差, 默认为1e-4
% N为最大迭代次数, 默认为500
if nargin < 2, x0 = 0; end
if nargin < 3, eps = 1e-4; end
if nargin < 4, N = 1000; end
f = matlabFunction(f_sym);
df = matlabFunction(diff(f_sym));
ddf = matlabFunction(diff(f_sym,2));
k = 0;
% fprintf('函数f=%s迭代开始:\n',f_sym)
while true
k = k + 1;
x1 = x0 - df(x0)/(ddf(x0));
% fprintf('k=%2.d, x0=%.4f, df=%9.4f, ddf=%9.4f, x1=%.4f\n',k,x0,df(x0),ddf(x0),x1)
if norm(abs(x1-x0),'fro')<eps
% fprintf('已收敛!结果如下:\nk=%2.d, x0=%.4f, x1=%.4f, f=%.4f',k,x0,x1,f(x1));
x_star = x1;
f_star = f(x_star);
break
end
if k > N
x_star = x1;
f_star = f(x_star);
fprintf('已经超出最大迭代次数%d!\n',N)
break
end
x0 = x1;
end
end
2.2 Python实现
阻尼牛顿法:
from linear_search.wolfe import *
from linear_search.Function import *
from numpy import *
def newton(f, start):
fun = Function(f)
x = array(start)
g = fun.grad(x)
while fun.norm(x) > 0.01:
G = fun.hesse(x)
d = (-dot(linalg.inv(G), g)).tolist()[0]
alpha = wolfe(f, x, d)
x = x + alpha * array(d)
g = fun.grad(x)
return x
3. 修正牛顿法
在基本牛顿法的基础上进行了改进,如阻尼牛顿法通过一维搜索确定步长,确保每次迭代方向是下降的。
方法1:当Hess阵正定时,采用牛顿方向作为搜素方向;若不正定,则采用最速下降法,即负梯度方向作为搜索方向。
方法2:是用H+μE来代替H,因为只要μ充分大,就能保证H+μE正定。
算法流程如下:

优点: 提高了算法的收敛性和稳定性,适用于Hessian矩阵不正定或难以计算的情况。
缺点: 计算仍较复杂:虽然进行了修正,但计算量仍然较大。
4. 拟牛顿法


4.1 拟牛顿法 Hk 的确定
割线方程

曲率条件

4.2 SR1 方法(秩一更新)


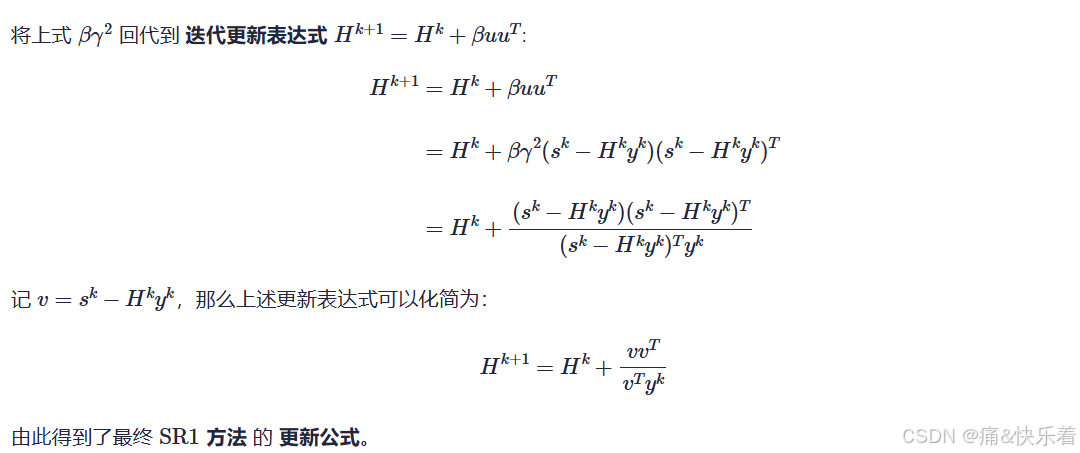
缺点:

4.3 BFGS 方法(秩二更新)
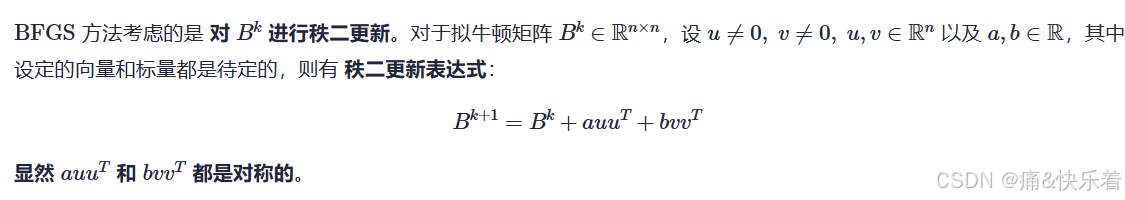

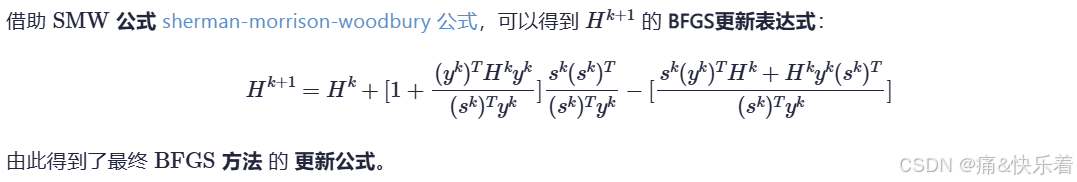
使用 SMW公式证明可以看这篇文章 Broyden类算法:BFGS算法的迭代公式推导(应用两次Sherman-Morrison公式)
BFGS的有效性

特点: 用近似Hessian矩阵或其逆矩阵代替精确的Hessian矩阵,简化了计算过程。
优势: 降低了运算复杂度,同时保持了超线性收敛性,适用于求解复杂的非线性方程。
缺点:可能产生死循环:需要通过特定方法克服可能出现的死循环问题。
4.4 python实现
拟牛顿法:
# coding=utf-8
from linear_search.wolfe import *
from linear_search.Function import *
from numpy import *
# 拟牛顿法
def simu_newton(f, start):
n=size(start)
fun = Function(f)
x = array(start)
g = fun.grad(x)
B=eye(n)
while fun.norm(x) > 0.01:
d = (-dot(linalg.inv(B), g)).tolist()
alpha = wolfe(f, x, d)
x_d=array([alpha * array(d)])
x = x + alpha * array(d)
g_d=array([fun.grad(x)-g])
g = fun.grad(x)
B_d=dot(B,x_d.T)
B=B+dot(g_d.T,g_d)/dot(g_d,x_d.T)-dot(B_d,B_d.T)/dot(x_d,B_d)
return x
5. 高斯-牛顿法(Gauss–Newton)
高斯-牛顿法(Gauss–Newton algorithm)是牛顿法的特例,它是牛顿法的修改版,用于寻找函数的最小值。
和牛顿法不一样,它只能用于解决最小二乘问题。
优点是,不需要二阶导数(二阶导数可能很难计算)。



代入牛顿迭代格式得:
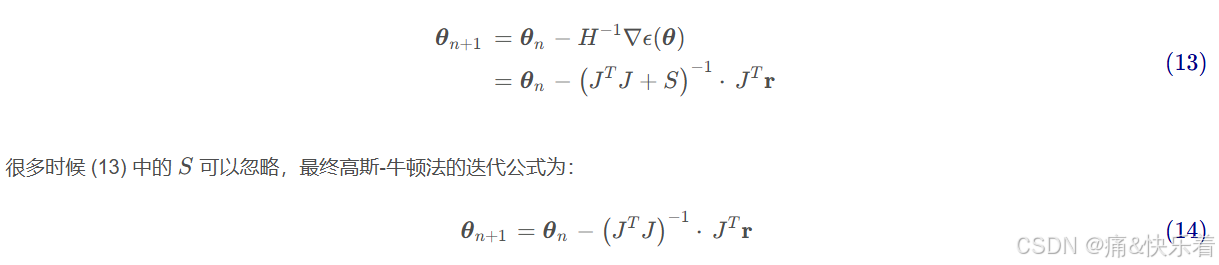
来自这篇文章的C++实现,以备不时之需。
// A simple demo of Gauss-Newton algorithm on a user defined function
#include <cstdio>
#include <vector>
#include <opencv2/core/core.hpp>
using namespace std;
using namespace cv;
const double DERIV_STEP = 1e-5;
const int MAX_ITER = 100;
void GaussNewton(double(*Func)(const Mat &input, const Mat ¶ms), // function pointer
const Mat &inputs, const Mat &outputs, Mat ¶ms);
double Deriv(double(*Func)(const Mat &input, const Mat ¶ms), // function pointer
const Mat &input, const Mat ¶ms, int n);
// The user defines their function here
double Func(const Mat &input, const Mat ¶ms);
int main()
{
// For this demo we're going to try and fit to the function
// F = A*exp(t*B)
// There are 2 parameters: A B
int num_params = 2;
// Generate random data using these parameters
int total_data = 8;
Mat inputs(total_data, 1, CV_64F);
Mat outputs(total_data, 1, CV_64F);
//load observation data
for(int i=0; i < total_data; i++) {
inputs.at<double>(i,0) = i+1; //load year
}
//load America population
outputs.at<double>(0,0)= 8.3;
outputs.at<double>(1,0)= 11.0;
outputs.at<double>(2,0)= 14.7;
outputs.at<double>(3,0)= 19.7;
outputs.at<double>(4,0)= 26.7;
outputs.at<double>(5,0)= 35.2;
outputs.at<double>(6,0)= 44.4;
outputs.at<double>(7,0)= 55.9;
// Guess the parameters, it should be close to the true value, else it can fail for very sensitive functions!
Mat params(num_params, 1, CV_64F);
//init guess
params.at<double>(0,0) = 6;
params.at<double>(1,0) = 0.3;
GaussNewton(Func, inputs, outputs, params);
printf("Parameters from GaussNewton: %f %f\n", params.at<double>(0,0), params.at<double>(1,0));
return 0;
}
double Func(const Mat &input, const Mat ¶ms)
{
// Assumes input is a single row matrix
// Assumes params is a column matrix
double A = params.at<double>(0,0);
double B = params.at<double>(1,0);
double x = input.at<double>(0,0);
return A*exp(x*B);
}
//calc the n-th params' partial derivation , the params are our final target
double Deriv(double(*Func)(const Mat &input, const Mat ¶ms), const Mat &input, const Mat ¶ms, int n)
{
// Assumes input is a single row matrix
// Returns the derivative of the nth parameter
Mat params1 = params.clone();
Mat params2 = params.clone();
// Use central difference to get derivative
params1.at<double>(n,0) -= DERIV_STEP;
params2.at<double>(n,0) += DERIV_STEP;
double p1 = Func(input, params1);
double p2 = Func(input, params2);
double d = (p2 - p1) / (2*DERIV_STEP);
return d;
}
void GaussNewton(double(*Func)(const Mat &input, const Mat ¶ms),
const Mat &inputs, const Mat &outputs, Mat ¶ms)
{
int m = inputs.rows;
int n = inputs.cols;
int num_params = params.rows;
Mat r(m, 1, CV_64F); // residual matrix
Mat Jf(m, num_params, CV_64F); // Jacobian of Func()
Mat input(1, n, CV_64F); // single row input
double last_mse = 0;
for(int i=0; i < MAX_ITER; i++) {
double mse = 0;
for(int j=0; j < m; j++) {
for(int k=0; k < n; k++) {//copy Independent variable vector, the year
input.at<double>(0,k) = inputs.at<double>(j,k);
}
r.at<double>(j,0) = outputs.at<double>(j,0) - Func(input, params);//diff between estimate and observation population
mse += r.at<double>(j,0)*r.at<double>(j,0);
for(int k=0; k < num_params; k++) {
Jf.at<double>(j,k) = Deriv(Func, input, params, k);
}
}
mse /= m;
// The difference in mse is very small, so quit
if(fabs(mse - last_mse) < 1e-8) {
break;
}
Mat delta = ((Jf.t()*Jf)).inv() * Jf.t()*r;
params += delta;
//printf("%d: mse=%f\n", i, mse);
printf("%d %f\n", i, mse);
last_mse = mse;
}
}
小结
本文主要介绍了牛顿法、阻尼牛顿法、修正牛顿法以及拟牛顿法,并给出各种方法的MATLAB及Python实现。
对于牛顿法,当初始点距离最优解较远时,Gk不一定正定,迭代不一定收敛,因此引入了步长因子α带步长因子的牛顿法,即阻尼牛顿法。另外,牛顿法的关键是计算Hesse矩阵,但对于一般的函数Hesse矩阵不容易计算,为克服这个缺陷,提出了拟牛顿法和修正牛顿法
修正牛顿法的思想是用G+μI来代替G,因为只要μ充分大,就能保证G+μI正定,拟牛顿法与牛顿法的区别在于用Hesse矩阵的近似B来代替G,其中B是对称正定的。其中,拟牛顿法一般常用的方法是BFGS,因为它保证了Bk的正定。
参考文献
数值分析:非线性方程组求解
各种牛顿法、拟牛顿法
拟牛顿法 http://faculty.bicmr.pku.edu.cn/~wenzw/optbook/lect/12-lect-QN.pdf
牛顿法MATLAB 最优化抄书笔记:牛顿法
写的很好的,不错的理论推导 拟牛顿法
牛顿法、拟牛顿法、阻尼牛顿法、修正牛顿法
MATLAB学习笔记】数值方法——多维阻尼牛顿法(求极小值)
牛顿法,高斯-牛顿法
Gauss-Newton算法学习
常见的几种最优化方法(梯度下降法、牛顿法、拟牛顿法、共轭梯度法等)

















 1042
1042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









