







使用pytorch自带的公开数据集训练一个结构简单的神经网络模型并保存,该模型用于识别MNIST数据集中的图像数字。
torchvision中datasets中所有封装的数据集都是torch.utils.data.Dataset的子类,它们都实现了__getitem__和__len__方法。因此,它们都可以用torch.utils.data.DataLoader进行数据加载。
数据集:
datasets.MNIST(“mnist-data”)下载mnist数据集之后生成的目录结构如下所示
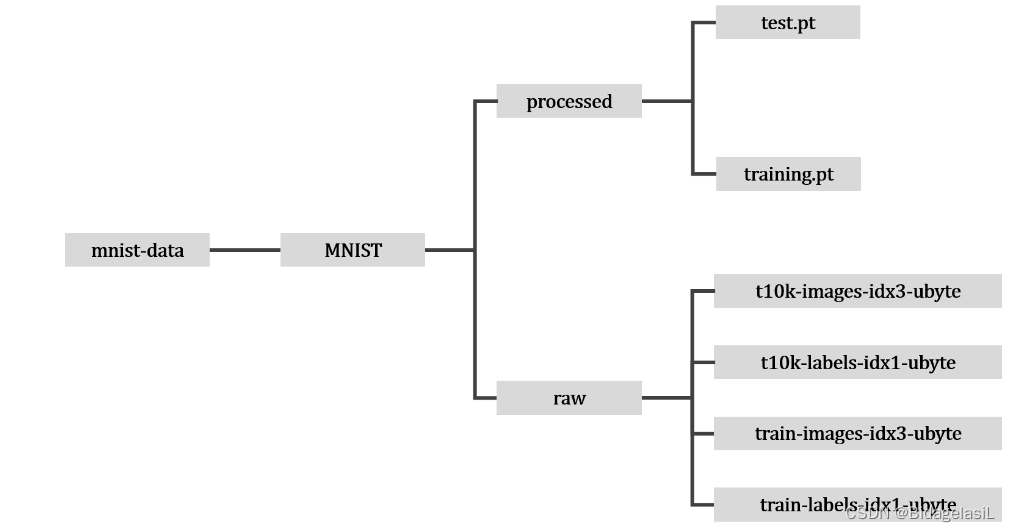
该数据集内共60000个数据,其中50000个为训练集,10000个为测试集。数据均为28*28的图像。
 代码实现如下:
代码实现如下:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
# 1- download dataset
# 2- create data loader
# 3- build model
# 4- train
# 5- save trained model
#包大小、训练周期、学习率
BATCH_SIZE = 128
EPOCHS = 10
LEARNING_RATE = 0.001
#网络模型类的定义,一般包含构造函数和前馈函数
class FeedForwardNet(nn.Module):
#构造函数用于初始化网络结构
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_layers = nn.Sequential(
nn.Linear(28 * 28, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
self.softmax = nn.Softmax(dim=1)
#前馈函数用于定义数据流向
def forward(self, input_data):
x = self.flatten(input_data)
logits = self.dense_layers(x)
predictions = self.softmax(logits)
return predictions
#加载数据集函数
def download_mnist_datasets():
train_data = datasets.MNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
validation_data = datasets.MNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
return train_data, validation_data
#定义数据集加载器
def create_data_loader(train_data, batch_size):
train_dataloader = DataLoader(train_data, batch_size=batch_size)
return train_dataloader
#定义训练函数
def train_single_epoch(model, data_loader, loss_fn, optimiser, device):
for input, target in data_loader:
input, target = input.to(device), target.to(device)
# calculate loss
prediction = model(input)
loss = loss_fn(prediction, target)
# backpropagate error and update weights
optimiser.zero_grad()
loss.backward()
optimiser.step()
print(f"loss: {loss.item()}")
#训练函数
def train(model, data_loader, loss_fn, optimiser, device, epochs):
for i in range(epochs):
print(f"Epoch {i+1}")
train_single_epoch(model, data_loader, loss_fn, optimiser, device)
print("---------------------------")
print("Finished training")
if __name__ == "__main__":
# download data and create data loader
train_data, _ = download_mnist_datasets()
train_dataloader = create_data_loader(train_data, BATCH_SIZE)
# construct model and assign it to device
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
print(f"Using {device}")
feed_forward_net = FeedForwardNet().to(device)
print(feed_forward_net)
# initialise loss funtion + optimiser
loss_fn = nn.CrossEntropyLoss()
optimiser = torch.optim.Adam(feed_forward_net.parameters(),
lr=LEARNING_RATE)
# train model
train(feed_forward_net, train_dataloader, loss_fn, optimiser, device, EPOCHS)
# save model
torch.save(feed_forward_net.state_dict(), "feedforwardnet.pth")
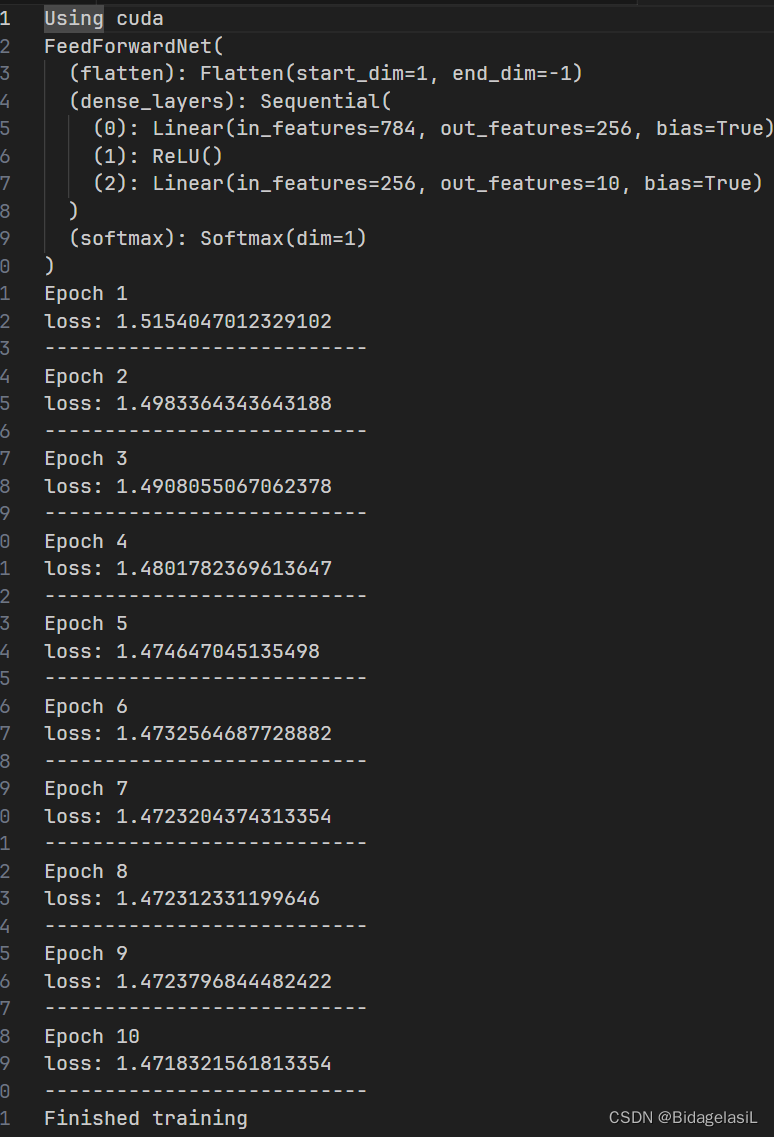
print("Trained feed forward net saved at feedforwardnet.pth")训练十个周期,用时两分钟,结果如下:
训练好的模型保存在工作目录下:
笔记:
定义神经网络类
构造函数:初始化网络结构
nn.Flatten() 扁平化
nn.Sequential() 允许将多个层打包在一起
nn.Linear() 线性层
nn.ReLU() 激活函数
nn.Softmax() 归一化 参数dim为维度
forward函数:定义pytorch按什么顺序处理数据
导入保存好的模型,使用验证集进行测试,打印出所有识别错误的图例和结果,代码实现如下:
import torch
from train import FeedForwardNet, download_mnist_datasets
class_mapping = [
"0",
"1",
"2",
"3",
"4",
"5",
"6",
"7",
"8",
"9"
]
def predict(model, input, target, class_mapping):
# 打开模型的评测模式
# model.eval() 作用等同于 self.train(False)
# 简而言之,就是评估模式。而非训练模式。
# 在评估模式下,batchNorm层,dropout层等用于优化训练而添加的网络层会被关闭,从而使得评估时不会发生偏移。
# 在对模型进行评估时,应该配合使用with torch.no_grad() 与 model.eval():
model.eval()
with torch.no_grad():
predictions = model(input)
# Tensor (1, 10) -> [ [0.1, 0.01, ..., 0.6] ]
predicted_index = predictions[0].argmax(0)
predicted = class_mapping[predicted_index]
expected = class_mapping[target]
return predicted, expected
if __name__ == "__main__":
# load back the model
feed_forward_net = FeedForwardNet()
state_dict = torch.load("feedforwardnet.pth")
feed_forward_net.load_state_dict(state_dict)
# load MNIST validation dataset
_, validation_data = download_mnist_datasets()
# get a sample from the validation dataset for inference
count = 0
error = 0
for i in range(10000):
input, target = validation_data[i][0], validation_data[i][1]
# make an inference
predicted, expected = predict(feed_forward_net, input, target,
class_mapping)
if predicted != expected:
print(f"Predicted: '{predicted}', expected: '{expected}'")
if predicted == expected:
count += 1
else:
error += 1
print(count)
print(error)
print(count/10000)
print(error/10000)
结果如下:
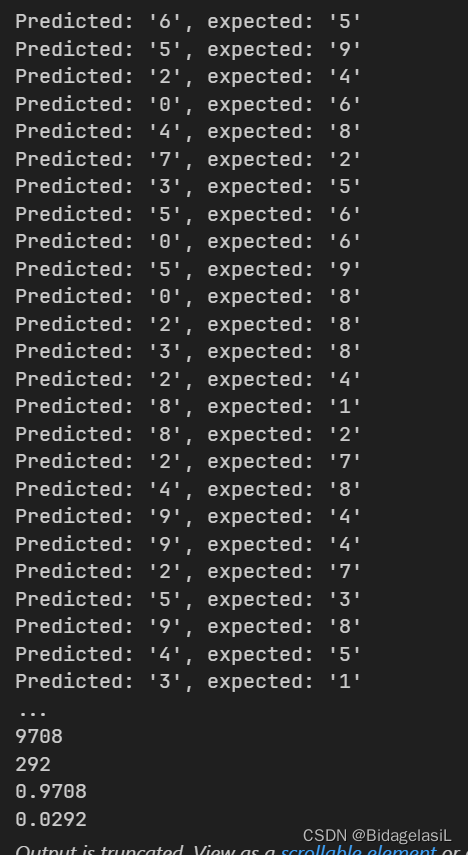
识别精准度大概在0.97。
参考链接:
dataset中获取图像的名字_python实现图像数据读取与数据扩增_码畜武哥的博客-CSDN博客
torchvision中datasets.MNIST介绍_鬼道2022的博客-CSDN博客
https://www.youtube.com/watch?v=4p0G6tgNLis&list=PL-wATfeyAMNoirN4idjev6aRu8ISZYVWm&index=2















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









