








 超级会员免费看
超级会员免费看


 本文介绍了如何在YOLOv5中应用SimAM注意力机制来增强模型性能。SimAM在小网络和大网络中都表现出优越性,且不增加额外参数。文章详细阐述了SimAM的原理,并提供了从代码实现到模型训练的完整步骤,包括在yolo.py的配置、SimAM.yaml的设置以及模型验证和训练过程。
本文介绍了如何在YOLOv5中应用SimAM注意力机制来增强模型性能。SimAM在小网络和大网络中都表现出优越性,且不增加额外参数。文章详细阐述了SimAM的原理,并提供了从代码实现到模型训练的完整步骤,包括在yolo.py的配置、SimAM.yaml的设置以及模型验证和训练过程。

🚀🚀 前言 🚀🚀
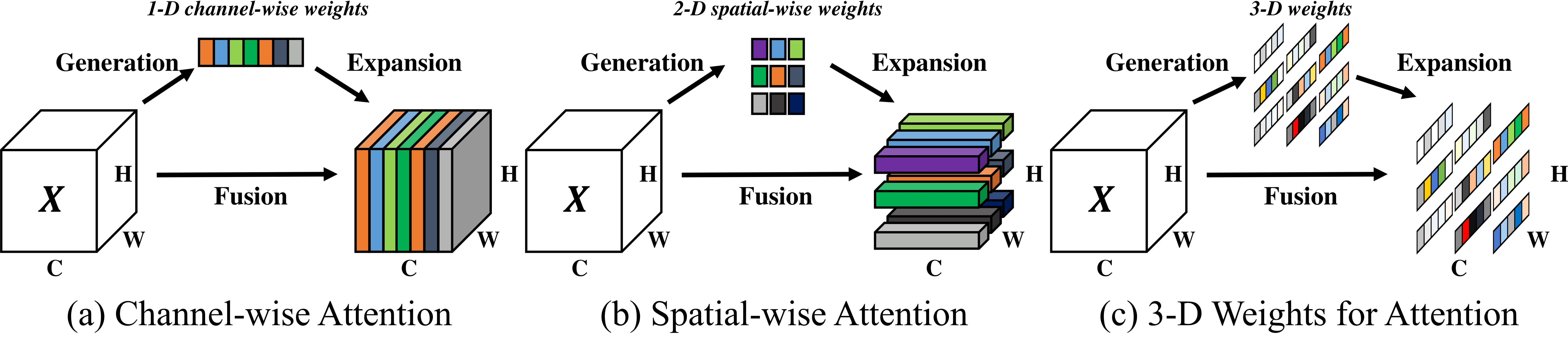
计算机视觉中的注意力机制的基本思想是让模型学会专注,把注意力集中在重要的信息上而忽视不重要的信息。Attention机制的本质就是利用相关特征图学习权重分布,再用学出来的权重施加在原特征图之上最后进行加权求和。不过施加权重的方式略有差别,大致总结为如下四点:
- 这个加权可以是保留所有分量均做加权(即soft attention);也可以是在分布中以某种采样策略选取部分分量(即hard attention),此时常用RL来做。
- 加权可以作用在空间尺度上,给不同空间区域加权;
- 加权可以作用在Channel尺度上,给不同通道特征加权;
- 加权可以作用在不同时刻历史特征上,结合循环结构添加权重,例如机器翻译,或者视频相关的工作。
🔥🔥 YOLOv5改进注意力机制系列:
YOLOv5改进实战 | 添加注意力机制(一)之SimAM篇
YOLOv5改进实战 | 添加注意力机制(二)之CoordAttention篇
YOLOv5改进实战 | 添加注意力机制(三)之CBAM篇
YOLOv5改进实战 | 添加注意力机制(四)之ACmix篇
一、SimAM
源代码仓库:Github: ZjjConan/SimAM
相比其他注意力机制,所提SimAM取得了最佳性能:
- 在小网络方面,PreResNet56在CIFAR10数据集上取得了最佳性能(92.47/69.13),显著优于其他注意力;
- 在大网络方面,所提SimAM同样优于SE与CBAM等注意力机制;
- 值得一提的是,所提SimAM并不会引入额外的参数;
上述实验结果均表明:所提无参注意力SimAM是一种通用注意力机制,并不局限于特定网络
二、代码实现
2.1 添加SimAM
在models文件下新建SimAM.py文件,并增加以下代码:
import torch
import torch.nn as nn
class SimAM(nn.Module):
def __init__(self, e_lambda=1e-4):
super(SimAM, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def __repr__(self):
s = self.__class__.__name__ + '('
s += ('lambda=%f)' % self.e_lambda)
return s
@staticmethod
def get_module_name():
return "simam"
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)) + 0.5
return x * self.activaton(y)
2.2 yolo.py配置
from models.SimAM import SimAM
在 models/yolo.py 文件中找到 parse_model 函数,并将新增以下代码:
elif m is SimAM:
args = [*args[:]]
2.3 SimAM.yaml配置
在 models 文件夹下新建 yolov5s_SimAM.yaml 文件,并添加以下配置
# YOLOv5 🚀 by YOLOAir, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOAir v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, SimAM, [1e-4]], # args 不需要改变
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, SimAM, [1e-4]], # args 不需要改变
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 25 (P5/32-large)
[-1, 1, SimAM, [1e-4]], # args 不需要改变
[[18, 22, 26], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
2.4 模型验证
在yolo.py里面,改为自定义的yaml,并运行yolo.py文件
parser.add_argument('--cfg', type=str, default='yolov5s_SimAM.yaml', help='model.yaml')
2.5 模型训练
python train.py --cfg models/yolov5s_SimAM.yaml --name yolov5s_SimAM
三、总结
- 在网络结构中加入注意力机制是会有提点的效果,但这并不是绝对的,需要结合自己的数据集,当然加入注意力机制的操作并不难,但需要我们耐心地尝试不同注意力机制、不同位置以及不同数量,有时多并不代表好。
- 模型的训练具有很大的随机性,您可能需要点运气和更多的训练次数才能达到最高的 mAP。



















 1225
1225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











