







小罗碎碎念
这篇文章综述了深度学习技术在生物样本虚拟组织染色领域的最新研究进展,探讨了其在提高病理诊断效率和降低成本方面的潜力。

| 作者角色 | 作者姓名 | 单位名称(英文) | 单位名称(中文) |
|---|---|---|---|
| 第一作者 | Bijie Bai | Electrical and Computer Engineering Department, University of California, Los Angeles, CA 90095, USA | 加利福尼亚大学洛杉矶分校电子与计算机工程系 |
| 第一作者 | Xilin Yang | Bioengineering Department, University of California, Los Angeles 90095, USA | 加利福尼亚大学洛杉矶分校生物工程系 |
| 通讯作者 | Aydogan Ozcan | Electrical and Computer Engineering Department, University of California, Los Angeles, CA 90095, USA | 加利福尼亚大学洛杉矶分校电子与计算机工程系 |
| 通讯作者 | Aydogan Ozcan | Bioengineering Department, University of California, Los Angeles 90095, USA | 加利福尼亚大学洛杉矶分校生物工程系 |
| 通讯作者 | Aydogan Ozcan | California NanoSystems Institute (CNSI), University of California, Los Angeles, CA, USA | 加利福尼亚大学洛杉矶分校加州纳米系统研究所 |
文献速览
在这篇综述文章中,作者们深入探讨了深度学习技术在生物样本分析中的一个创新应用:虚拟组织染色。
这一技术通过模拟传统组织染色的效果,使用深度学习算法处理生物样本的图像,从而无需实际使用化学染料,就能在数字层面上生成具有诊断价值的组织图像。
文章首先强调了传统组织染色技术的核心作用,它允许病理学家通过显微镜观察到的细胞和组织结构的颜色和形态变化来诊断疾病。尽管这一技术历史悠久、效果显著,但它的局限性也很明显:需要专业人员操作、耗时长、成本高,并且对于设备和环境的要求使得它在资源匮乏地区难以实施。
为了克服这些限制,研究人员开始探索深度学习在虚拟组织染色中的应用。通过训练神经网络识别和模拟特定染色效果,研究者们能够将未染色的生物样本图像转化为具有类似传统染色效果的图像。这种方法不仅速度快、成本低,而且可以减少对专业人员的依赖,使得病理诊断更加便捷和普及。
文章详细介绍了虚拟染色技术的工作流程,包括图像数据的收集、预处理、网络训练和验证。在监督学习场景中,需要精确匹配的输入图像和目标图像对来训练网络,以确保虚拟染色的准确性。而非监督学习则不需要成对的图像,而是通过循环一致性学习框架来训练网络,使其能够处理未配对的图像数据。
文章还讨论了虚拟染色技术的多种应用,包括从未染色的样本中生成各种类型的组织染色,以及将一种染色类型的图像转换为另一种类型的染色。这些技术不仅能够模仿传统的如苏木精-伊红(H&E)染色,还能模拟更复杂的免疫组化(IHC)染色,这对于疾病的诊断和研究具有重要意义。
作者们对虚拟染色技术的未来进行了展望,认为这一技术有望进一步发展,包括提高数据的一致性、增加染色的吞吐量、利用最新的深度学习技术来提升网络的泛化能力,以及建立更好的模型评估方法。这些进步将有助于虚拟染色技术在临床诊断中的广泛应用,并可能最终取代传统的化学染色方法。
总的来说,这篇文章为读者提供了深度学习在生物医学成像领域中应用的全面视角,展示了虚拟染色技术如何有潜力改变传统的病理诊断流程,使其更加高效、经济、易于获取。随着技术的不断进步,未来病理学的研究和实践可能会越来越多地依赖于这些先进的计算方法。
一、绪论
在过去的一个世纪里,组织学染色已成为疾病诊断和生命科学研究中进行组织检查的主要工具(参考文献1、2)。
通过基于生物化学性质,用特定标记对不同生物元素进行标记,组织学染色能够可视化组织和细胞结构,并在观察染色的样本时,评估病理生理学和疾病发展(参考文献3-5)。
在组织学实验室中,已开发出各种染色类型,并常规执行,以突出不同的生物学特征。例如,苏木精-伊红(H&E)染色在核和细胞外组织基质之间创造对比,是组织病理学中最常使用的染色方法(参考文献6);马松三色(MT)染色(参考文献7)和过碘酸-雪夫(PAS)染色(参考文献8)等特殊染色方法分别突出胶原纤维和糖蛋白,常用于心脏和肾脏病理学(参考文献4)。免疫组织化学(IHC)染色是一种更先进的分子染色技术,基于抗原-抗体结合突出特定表位的存在,在病理学中广泛使用(参考文献9、10)。
这些标准的组织学染色程序在病理实验室中按照数十年的工作流程例行进行,其中包括耗时的样本制备(如组织固定、包埋和切片)和费力的组织学染色步骤,之后样本才能在光学显微镜下检查(图1a)。
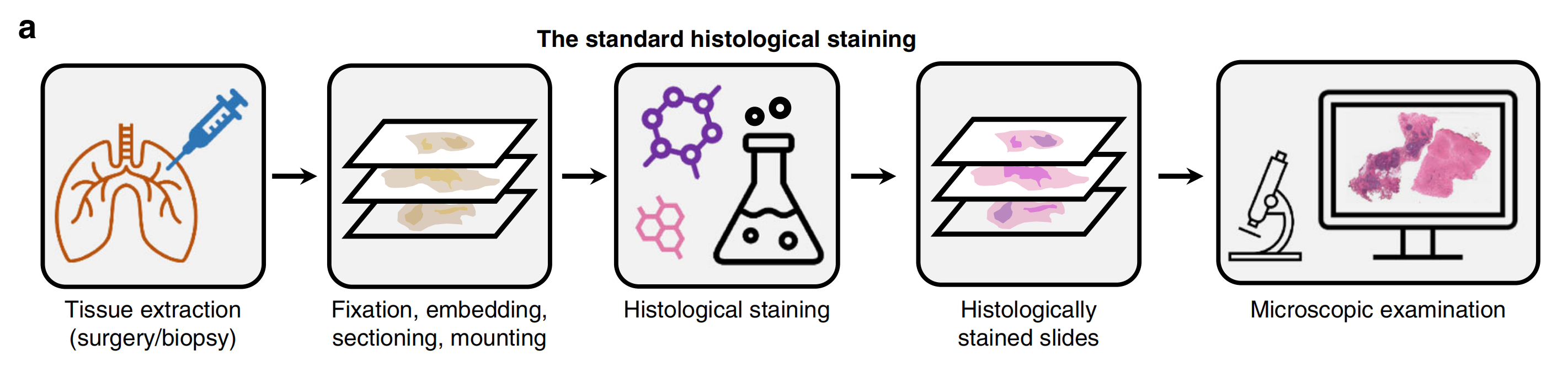
这种基于化学的染色程序需要指定的实验室基础设施和受过培训的组织技术员的手动监督,使得成本高昂且在资源有限的设置中无法使用。
多步骤的染色协议伴随着专家的费力手动监督,导致周转时间长(如几天到几周),从而延迟疾病诊断和治疗。此外,化学染色过程的破坏性特性禁止在同一切片上进行额外的染色和进一步的分子分析。
另一个缺点是,染色过程中涉及的有毒化学化合物产生了大量的废物,并每年在全球消耗超过100万升水。总的来说,强烈需要替代染色方法,以提供快速、成本效益高和准确的解决方案来克服这些限制。
近年来,使用自动化高通量幻灯片扫描仪和数字图像查看器的数字病理学实践(参考文献11、12)已广泛采用。
结合不断发展的深度学习技术,为这些数十年的染色方法革命创造了新机会。
基于深度学习的图像变换,从更快、更简单、更易获取的显微镜模式到更先进但难以获得的模式,已针对各种生物样本进行了广泛研究(参考文献13-17)。作为在组织病理学领域这一研究线的延伸,已开发出基于深度学习的方法,仅使用未标记样本的显微镜图像来虚拟复制化学染色切片的图像(参考文献18、19),从而消除了化学染色程序的需求(图1b)。
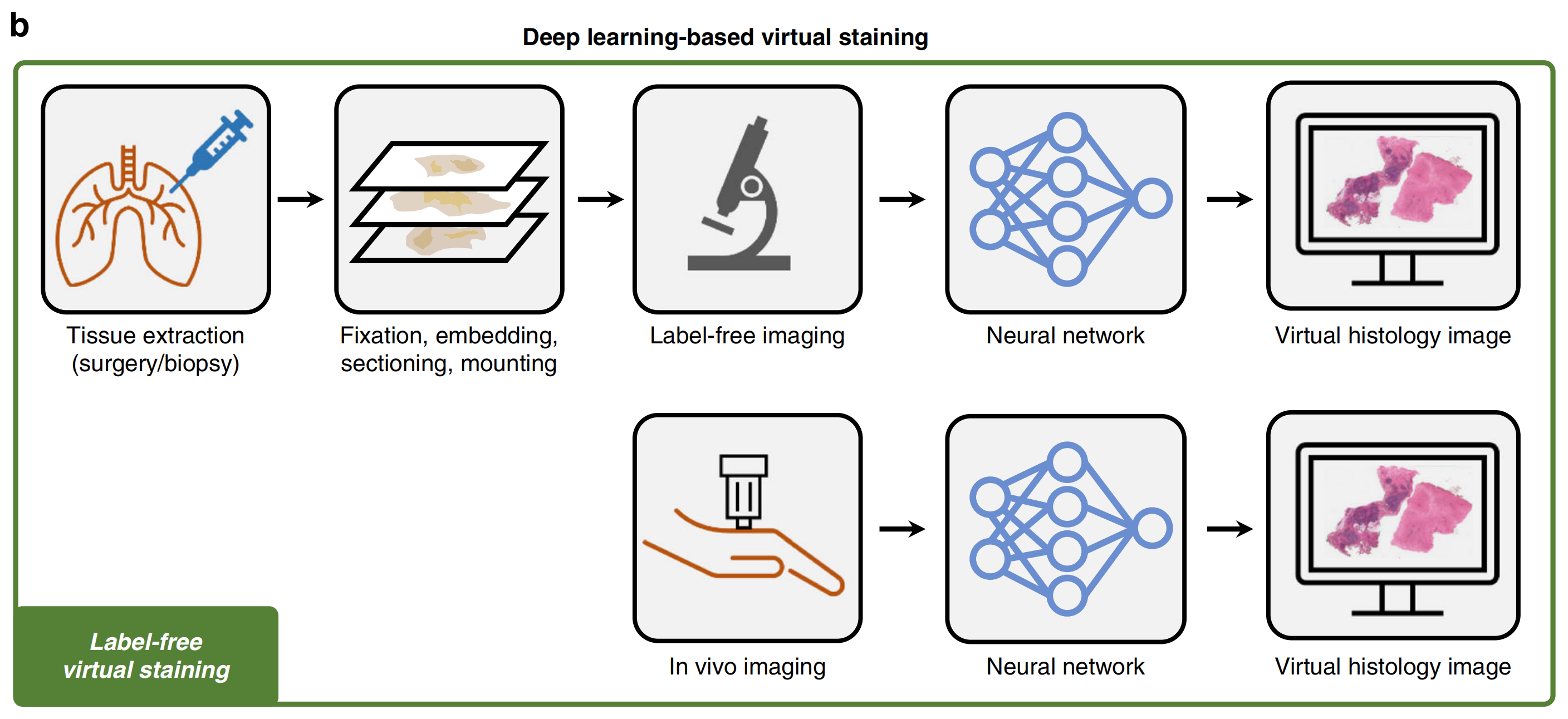
这些虚拟染色方法已证明能够成功生成不同类型的组织学染色,使用各种无标签成像模式,如自体荧光成像和定量相位成像(QPI)(参考文献18、20)。
使用深度学习进行图像变换以绕过传统组织学染色过程的主要理念,也使得可以从一种现有的染色类型转换到另一种(参考文献19、21)(图1b)。
染色到染色转换方法可以即时为病理学家提供额外的染色类型,而无需改变他们当前的工作流程。虚拟染色技术固有地生成数字病理学图像,因此属于并进一步扩展了数字病理学的范围,也赋予了算法下游分析方法权力。
这些新技术不仅降低了成本、劳动力和诊断延迟,还开启了新的染色多重化和体内染色的可能性(参考文献22、23),极大地扩展了组织病理学领域,超出了当前使用的传统化学染色范例的范围。
二、虚拟染色模型的开发流程
开发无标签虚拟染色或染色到染色转换模型的工作流程通常包括图像数据收集、图像预处理以及网络训练和验证,如图2-3所示。
根据用于创建虚拟染色模型的学习方案(例如,监督式或非监督式),相应的前端数据收集和预处理方法将有所不同。在监督式训练设置中,需要完全交叉注册的输入和真实图像对来训练图像变换虚拟染色网络。因此,通常需要多阶段图像注册(图2a)或预训练数据生成模型(图3a)来生成匹配良好的训练图像。
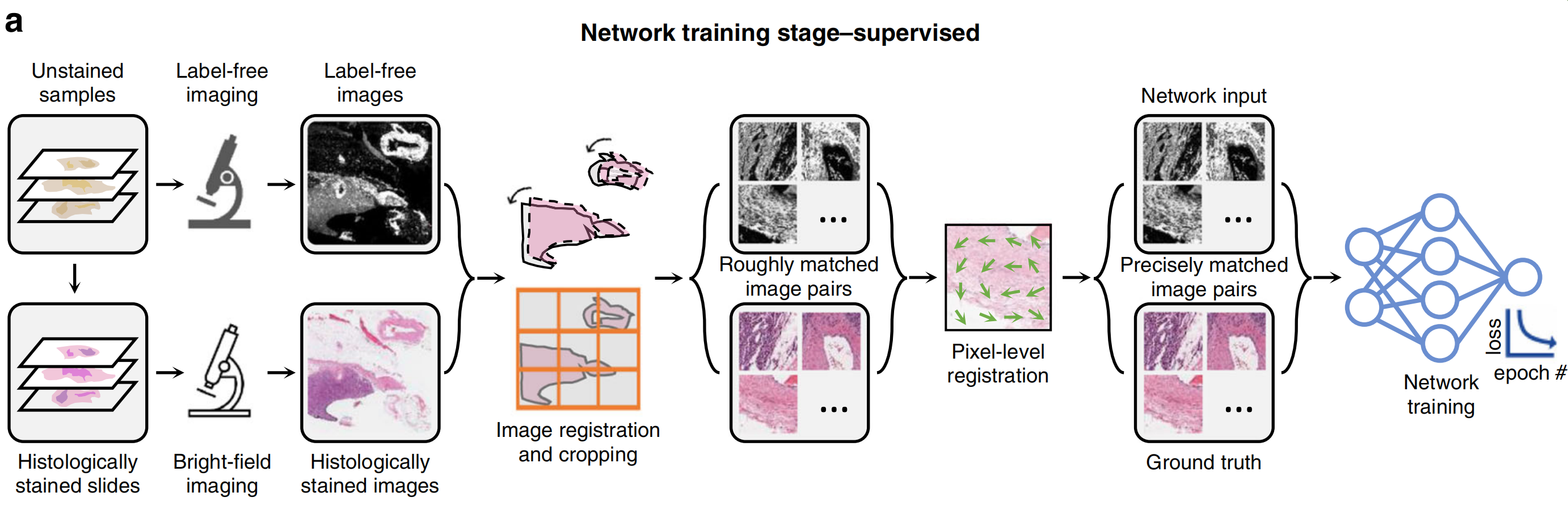
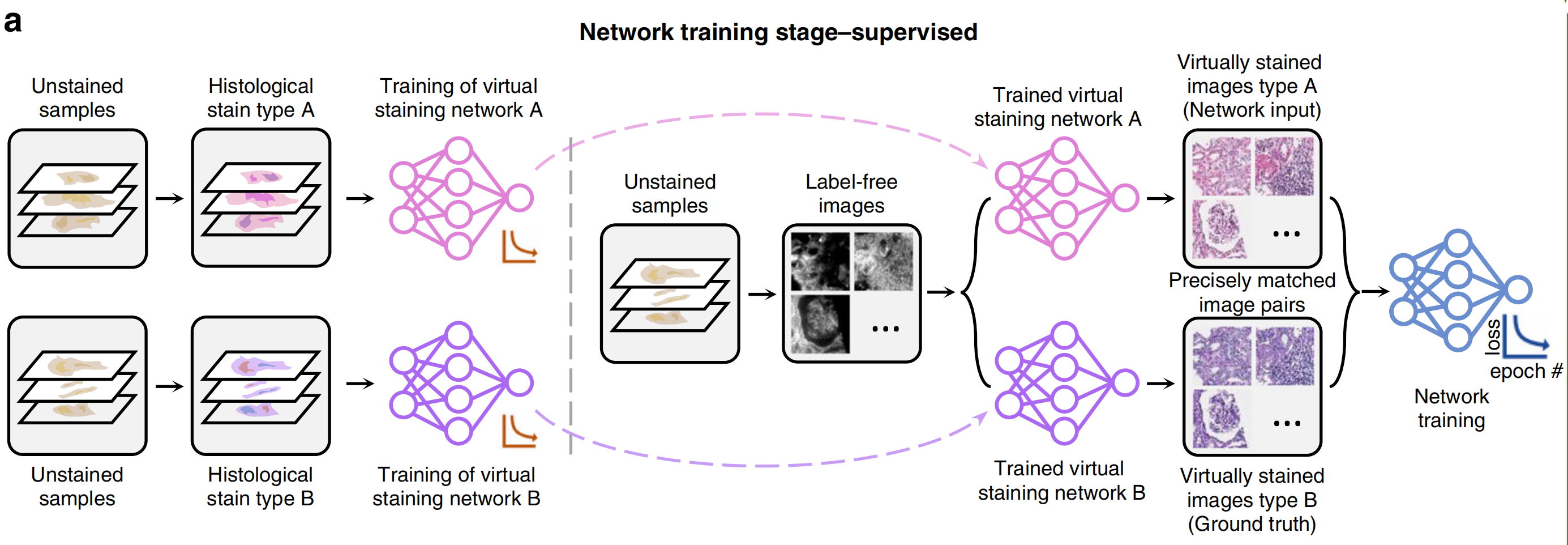
另一方面,在非监督式训练设置中,输入和真实域的图像不一定是成对的(见图2b和图3b)。
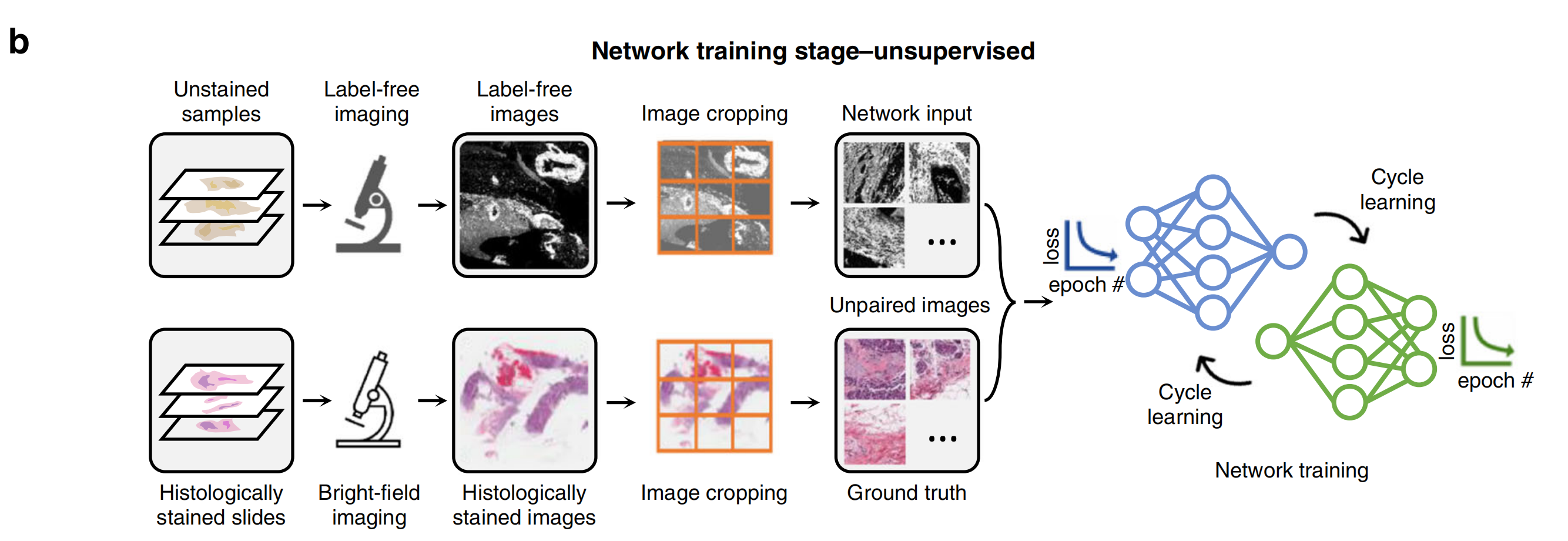
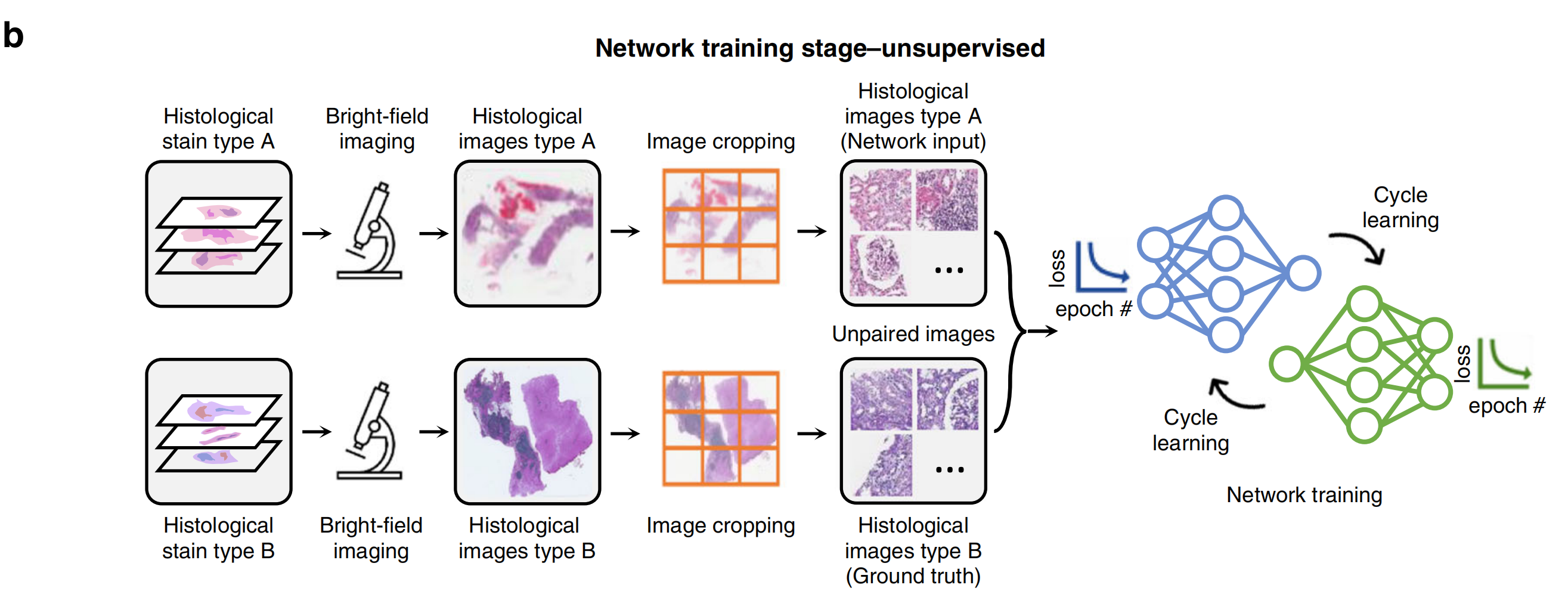
这节省了数据预处理的努力,然而,增加了网络架构和训练计划的复杂性。循环一致性基于学习框架(例如,CycleGANs24)常用于非监督式训练场景,其学习将输入图像的分布映射到真实域,匹配颜色和对比度。
对于这两种学习方案,开发一个可靠的虚拟染色模型通常涉及获取和处理大量数据以及精心设计和训练神经网络(见图2a、b和图3a、b),这可能需要大量的时间。
然而,这一模型开发阶段是一次性的过程;原则上,这与涉及各种化学优化步骤的组织化学染色工作流程的开发和微调非常相似,所有这些步骤也都构成了一次性的开发努力。一旦获得并验证了满意的虚拟染色模型,其盲推论是快速且可重复的(图2c和3c),只需使用标准计算机,无需等待任何化学染色程序完成,就可以在几分钟内创建一个组织切片的整张虚拟组织学图像。
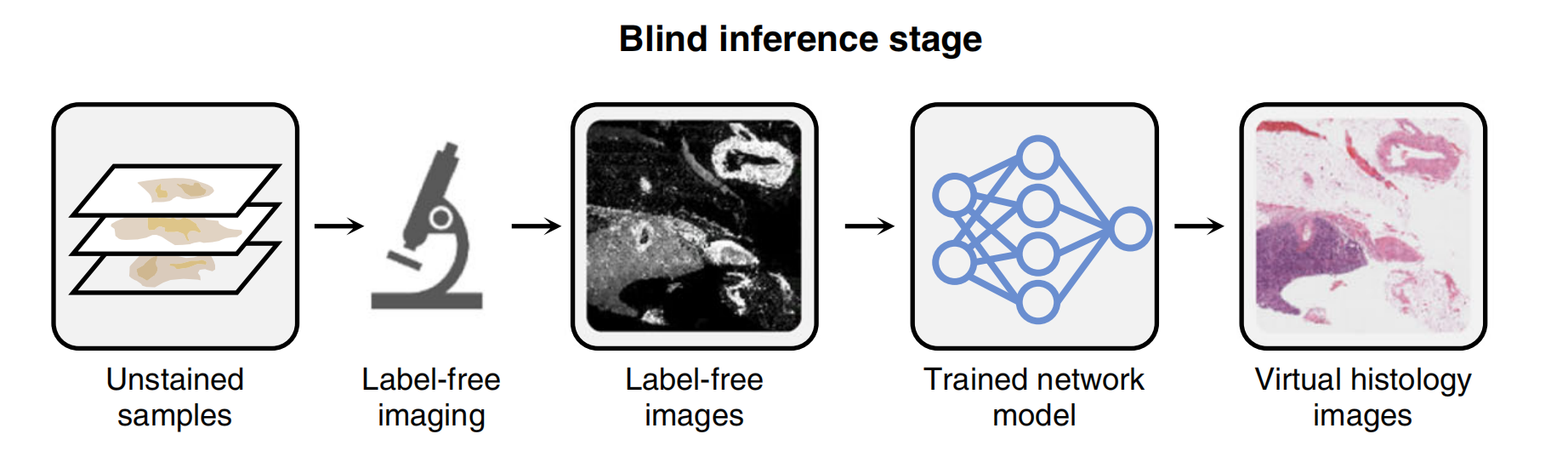
这一虚拟染色过程不仅节省了时间和劳动力,还消除了有毒染色化合物的使用,因此,对环境更加友好。
三、无标签虚拟染色
利用深度学习成功实现无标签组织样本的虚拟染色,使用自体荧光图像,由Rivenson等人展示18,25。
在此研究中,深度神经网络被训练以转换各种未染色组织切片的图像,例如唾液腺、甲状腺、肝脏和肺部,使之呈现出多种组织学染色,包括H&E、MT和Jones银染色,与同一组织切片经过标准组织化学染色后的明场图像高度匹配(图4a)。
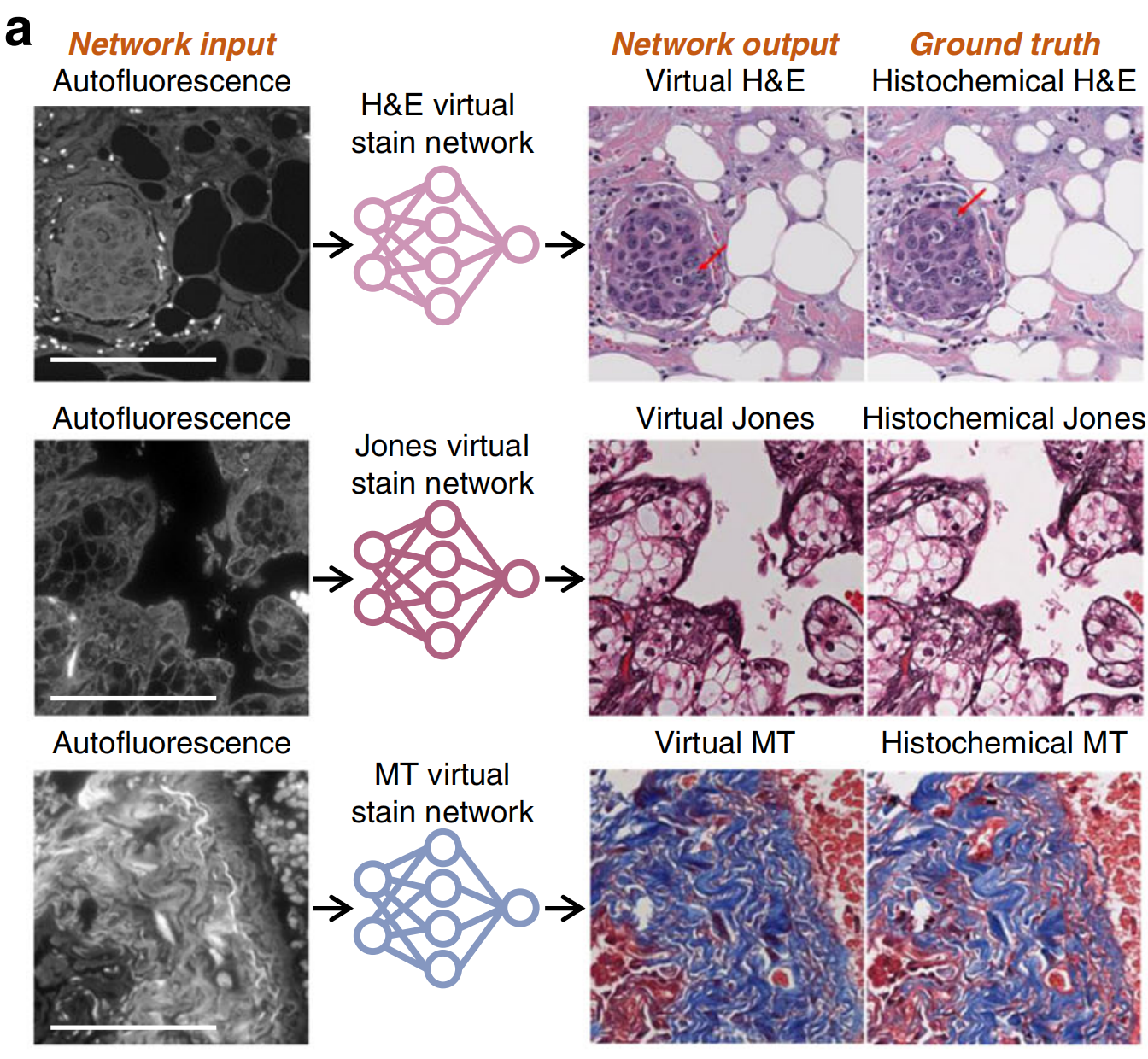
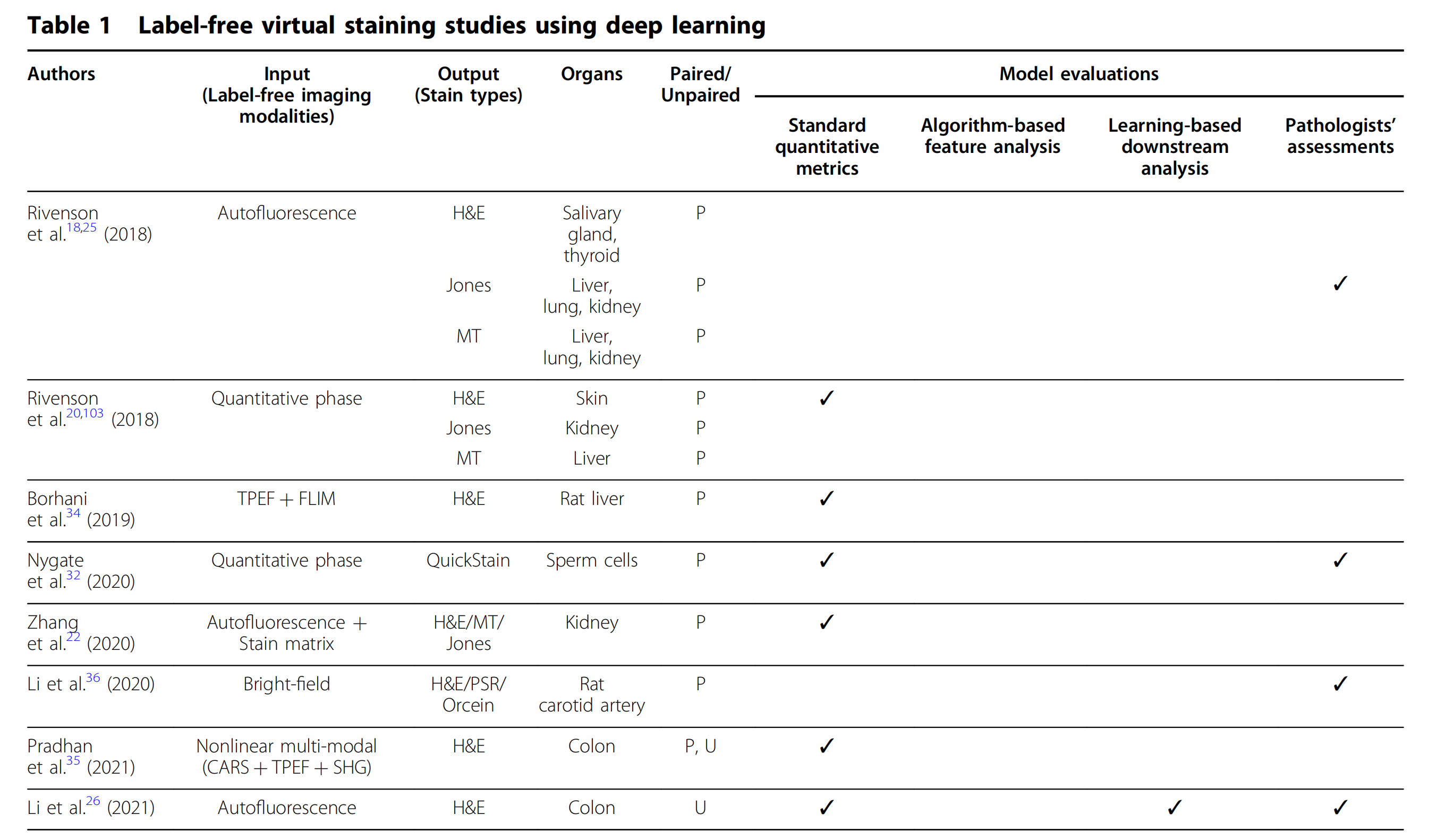
在过去的几年中,多项研究进一步扩展了这一无标签虚拟染色技术26-28。如表1和图4所示,通过不同的图像对比机制,成功复制了多种类型的组织学染色,极大地丰富了虚拟染色方法的应用领域。
表1列出了使用深度学习进行无标记虚拟染色研究的概述。
-
研究作者:列出了进行无标记虚拟染色研究的主要作者。
-
输入(无标记成像方式):展示了用于生成虚拟染色图像的原始成像技术。这些技术包括自发荧光(Autofluorescence)、定量相位成像(Quantitative phase)、二次谐波生成(SHG)、多光子激发荧光(TPEF)等。
-
输出(染色类型):列出了通过深度学习模型生成的虚拟染色类型。这些包括苏木精-伊红(H&E)、Masson三色(MT)、Jones银染、免疫组化(IHC)等。
-
器官:说明了研究中使用的生物样本类型,如唾液腺、甲状腺、皮肤、肝脏、肾脏、结肠、卵巢、乳腺、前列腺等。
-
配对/非配对:指出了研究中使用的图像数据是否为配对数据。配对数据意味着每个输入图像都有相对应的真实染色图像作为训练目标,而非配对数据则没有这样的对应关系。
-
模型评估:展示了用于评估虚拟染色模型性能的不同方法,包括标准定量指标、基于算法的特征分析、基于学习的下游分析和病理学家的评估。
-
标准定量指标:如结构相似性指数(SSIM)、峰值信噪比(PSNR)、平均绝对误差(MAE)等,用于量化评估虚拟染色图像与真实染色图像之间的相似度。
-
算法基于特征分析:通过提取图像特征并进行统计分析,来评估虚拟染色的有效性。
-
基于学习的下游分析:使用深度学习模型对虚拟染色图像进行进一步的病理分析,如肿瘤分级、细胞分割等。
-
病理学家评估:由认证病理学家对虚拟染色图像进行评估,以确定其在实际病理诊断中的有效性。
表1提供了一个全面的视角,展示了不同研究小组如何利用深度学习技术来模拟传统的组织染色过程,以及他们如何评估这些虚拟染色方法的有效性。这些研究为未来在资源有限的环境中提供快速、低成本的病理诊断工具提供了可能性。
此外,通过向自体荧光图像添加定制化的数字染色矩阵,并以其组合作为神经网络的输入,Zhang等人使用单一网络实现了微结构化和多重的组织学染色,这在传统的组织化学染色工作流程中是不可行的(图4b)。
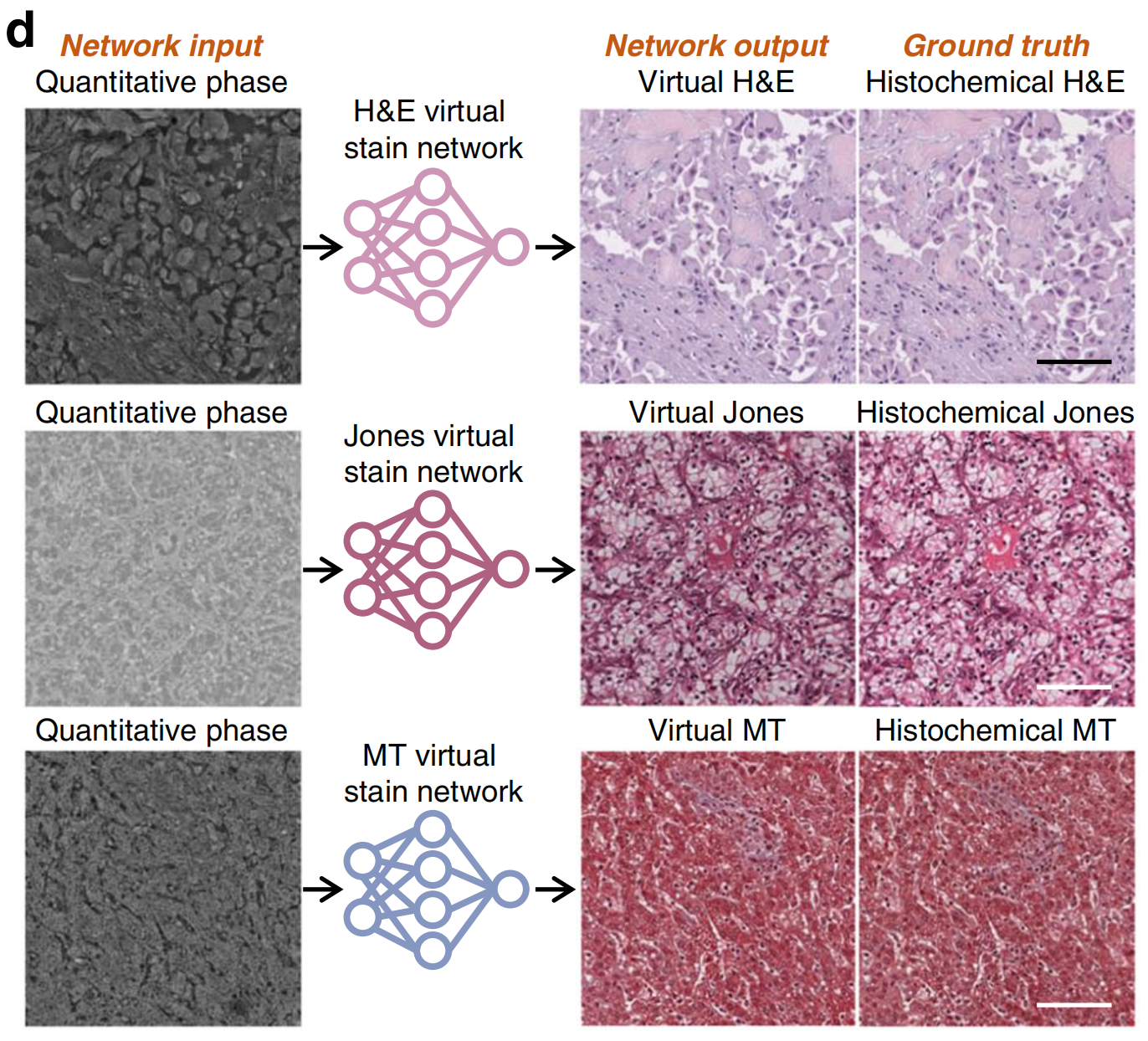
实际上,生物组织的自体荧光发射特征携带着其代谢状态和病理状况的复杂空间-光谱信息29,30。因此,除了标准的组织化学染色如H&E和MT外,无标签组织的自体荧光图像可用于生成更复杂的分子染色,例如突出特定蛋白表达,正如目前组织学实验室常用的传统IHC染色协议所做的那样。
例如,Bai等人成功展示了使用未标记的乳腺组织切片的自体荧光图像对人类表皮生长因子受体2(HER2)蛋白的虚拟IHC染色(图4c),显著扩展了通过无标签自体荧光成像进行虚拟组织染色的应用范围。
尽管自体荧光显微镜功能强大,但它并非唯一能使无标签虚拟染色成为可能的成像方式。
几种不同的成像方式,为无标签生物样本提供了对比度,已被探索用于虚拟染色。
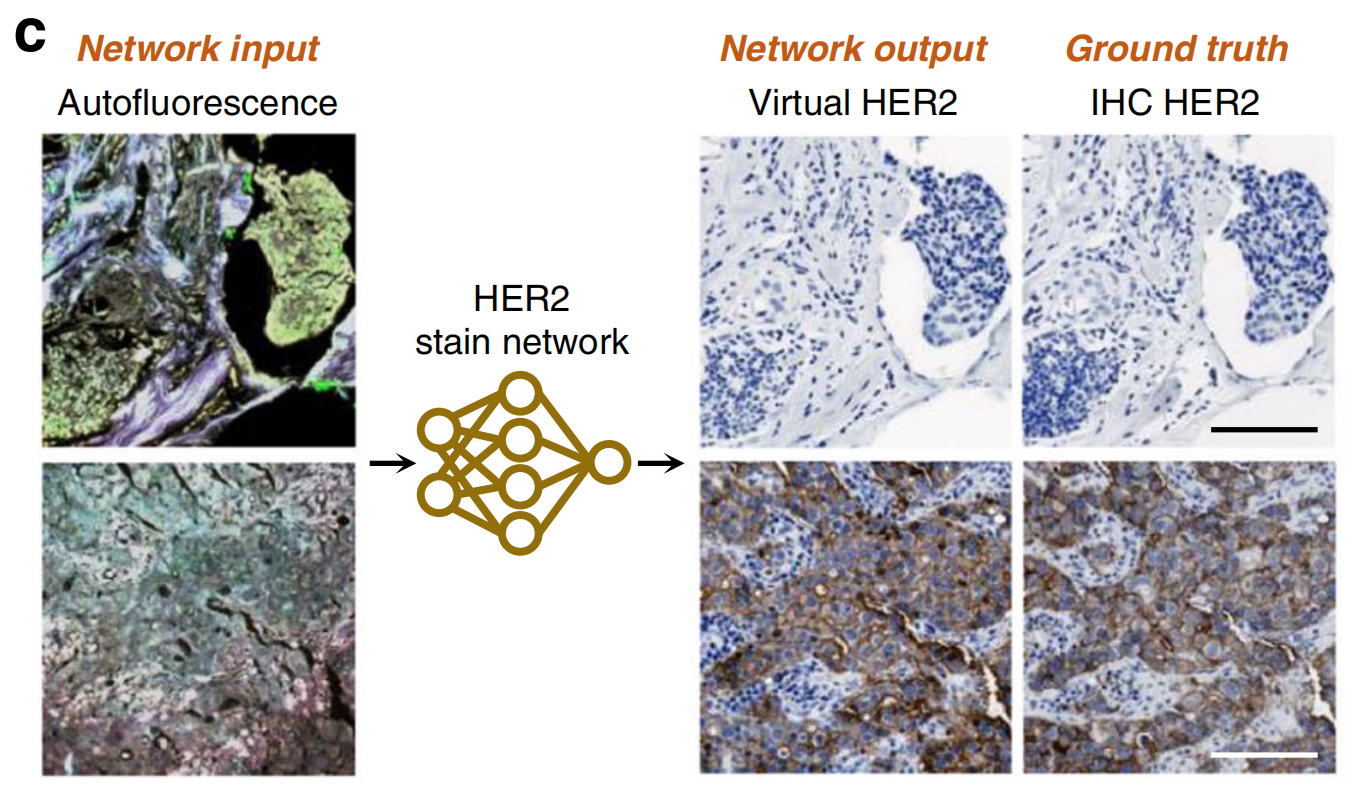
例如,基于未染色生物样本的折射率分布的定量相位成像(QPI),也被用于虚拟染色。Rivenson等人使用各种无标签组织切片的定量相位图像,并通过卷积神经网络将其转换为虚拟的H&E、Jones和MT染色,其染色质量与组织化学染色样本相匹配(图4d)。
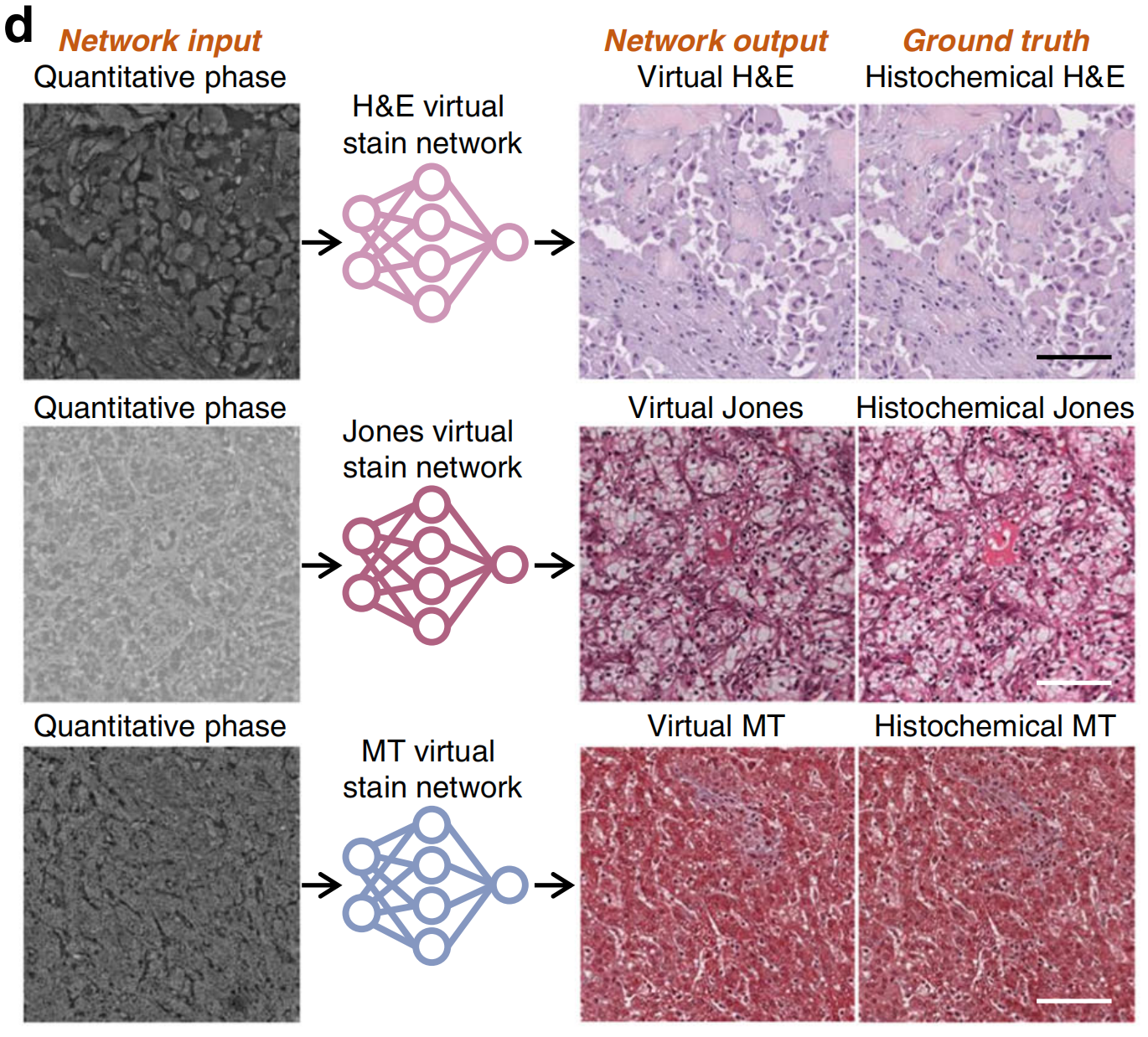
在另一项工作中,Nygate等人展示了使用QPI对人类精子细胞的虚拟染色,实现了实时生育能力评估。Abraham等人还利用斜向背光显微镜的QPI生成了厚且完整小鼠脑样本的虚拟H&E染色。
其他显微镜方法,如非线性光学成像,也已用于无标签虚拟染色。
Borhani等人结合双光子激发荧光(TPEF)和荧光寿命成像(FLIM)作为网络输入,对大鼠肝脏样本进行虚拟H&E染色34。Pradhan等人结合相干反斯托克斯拉曼散射(CARS)、二次谐波生成(SHG)显微镜和TPEF,在人类结肠样本上创造了虚拟H&E染色(图4e)。
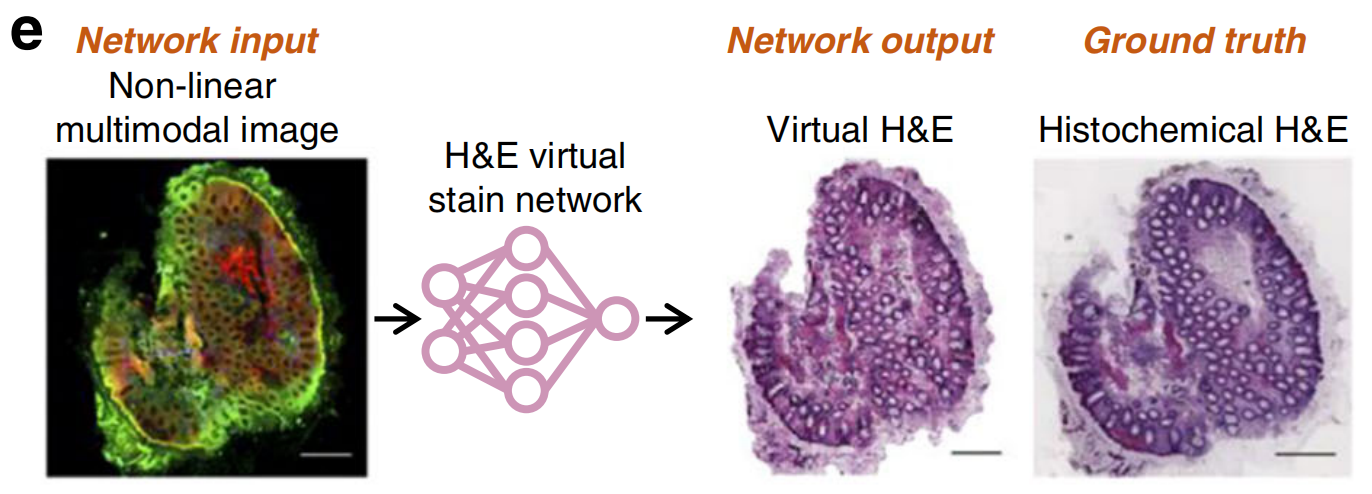
一些额外的无标签成像方法也被应用于基于深度学习的虚拟染色任务。例如,使用未染色的颈动脉切片的明场成像生成了多种类型的染色,如H&E和 Sirius红(PSR)(图4f)36,37;
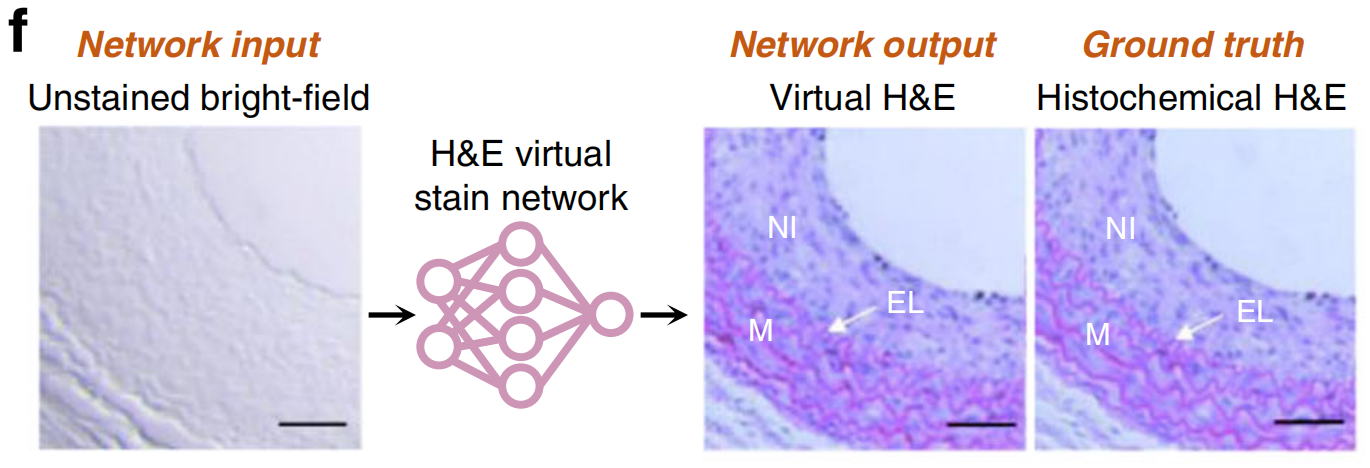
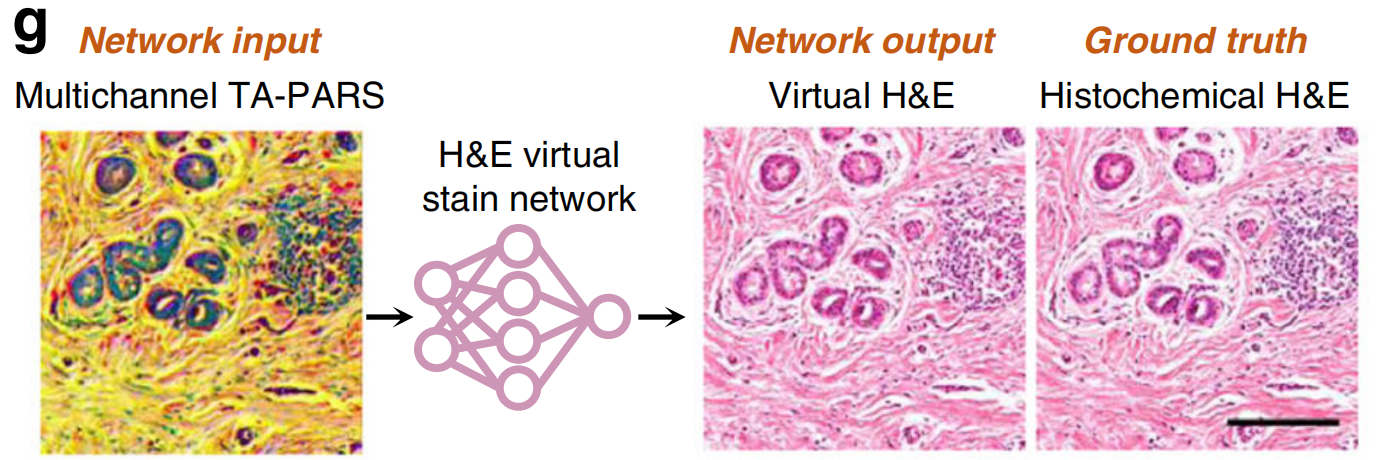
多通道总吸收光声远程感测(TA-PARS)被用于创建人类皮肤组织的虚拟H&E染色(图4g)38;
使用紫外显微镜获得的图像被计算转换成全血涂片的吉姆萨染色39,以及前列腺组织切片的H&E40和IHC41染色;光声显微镜也被展示能够实现小鼠大脑的虚拟H&E染色42和骨组织冰冻切片的染色43。
Mayerich等人开发了一个无隐藏层的浅层人工神经网络(ANN)模型,从傅里叶变换红外(FT-IR)光谱学学习像素到像素的映射,针对人类乳腺组织的多种染色44;然而,这种方法忽略了标签-free图像的2D空间信息,并且虚拟染色是使用每个像素单独的光谱进行的,即与其他像素分离。
由于缺乏处理组织结构2D纹理信息的更深卷积层,这种一维方法呈现出有限的染色性能和泛化能力44。在另一尝试中,使用超过130个光谱带的 hyperspectral 反射成像作为训练神经网络的输入,旨在实现虚拟H&E染色;然而,这种方法未能产生具有病理解释性的图像,其结构相似性指数测量(SSIM)仅达到约0.38745。
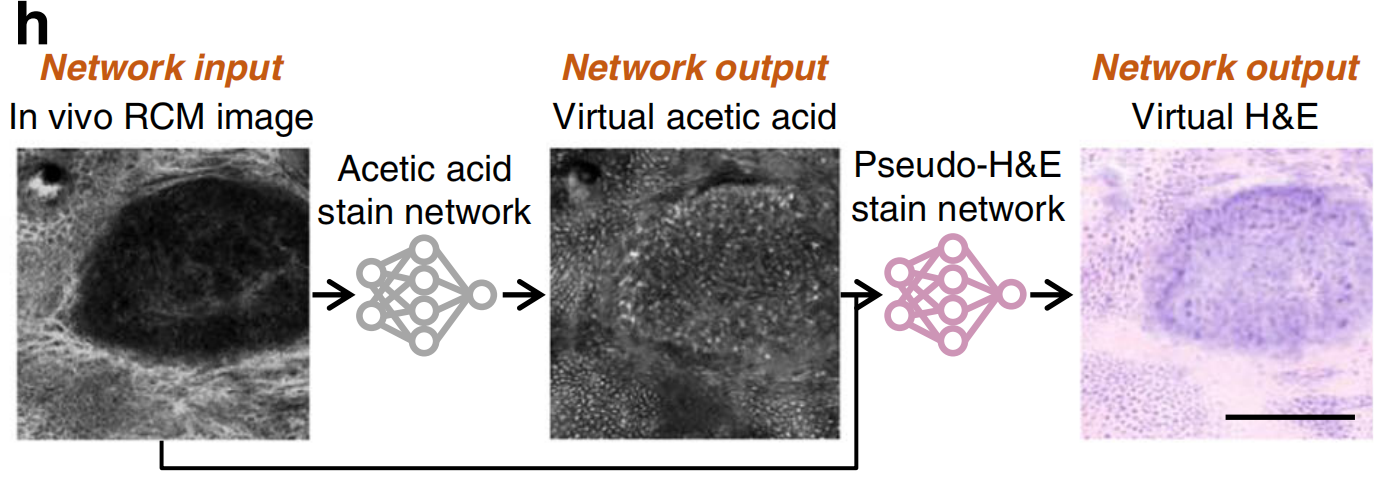
虚拟染色技术还可以与无创显微成像方式结合,实现无需活检的体内虚拟染色(即“虚拟活检”)。如Li等人所展示的23,使用反射共聚焦显微镜(RCM)的体内虚拟染色方法可以创建人类皮肤组织的虚拟H&E染色(图4h),这有可能用于快速诊断恶性皮肤肿瘤,同时消除了不必要的活检、疤痕以及繁琐的样本制备步骤。
四、染色到染色转换
深度学习还使已经染色的组织显微镜图像转换为其他类型的染色,为区分各种细胞结构等提供了额外的对比信息,有助于提高诊断的准确性。
例如,Gadermayr等人使用深度学习实现了染色到染色转换,实现了从PAS染色到酸性橘红G(AFOG)、CD31 IHC和胶原III(Col3)染色的图像转换46。这些染色到染色转换使他们能够比较同一视野(FOV)下不同染色类型对肾小球分割精度的差异,这在标准组织学中是不可能的,因为给定的组织切片通常只能用一种类型的染色。
在过去几年中,使用深度学习进行染色到染色转换的应用也得到了展示,如表2和图5所示。
染色到染色转换提供了一种高度方便和快速的方法,生成更难通过更常见且更便宜的染色(如H&E)获得的染色类型。
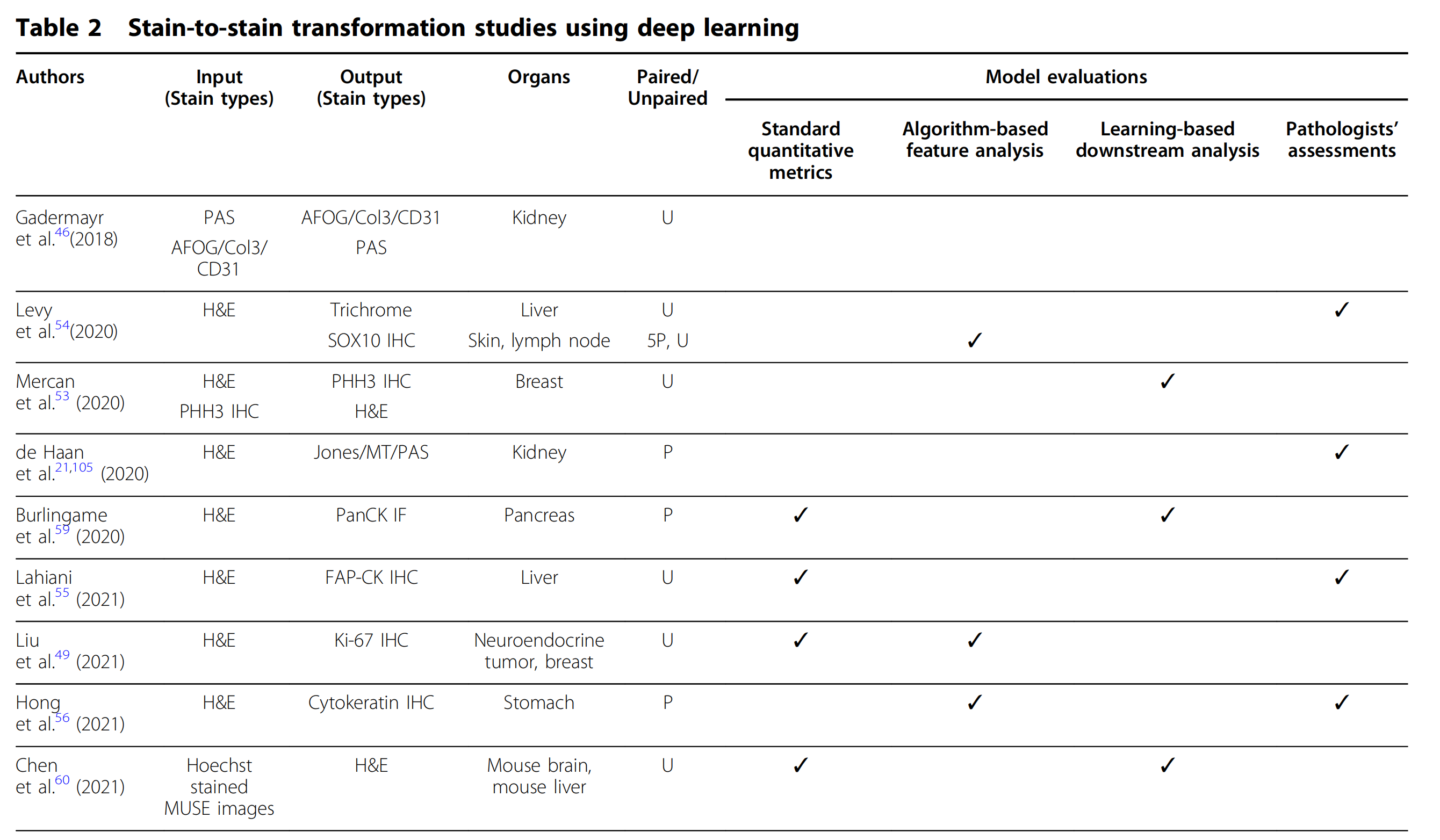
例如,染色到染色转换的默认“源”染色通常选择H&E染色,因为其广泛可获得性和成本效益6。将H&E染色转换为用于显示H&E染色未显示的特定组织结构的染色(例如Jones银、MT和PAS染色)已被多个研究小组所展示21,47-56。
在de Haan等人的工作中(图5a)21,深度神经网络被训练将H&E染色的肾组织样本转换为特殊染色,包括Jones银、MT和PAS染色。
染色到染色转换提高了盲法研究的诊断准确性,并将大大减少非肿瘤性肾活检检查的周转时间。作为另一个例子,Levy等人使用人肝组织样本的H&E染色生成了虚拟三色染色,以研究肝纤维化的分期47。此外,Lin等人展示了从H&E到PAS、MT和周期性Schiff-甲脒胺(PASM)染色的多重染色转移,应用于人肾组织样本48。
除了特殊染色外,还成功生成了使用H&E图像作为输入的不同IHC基染色。
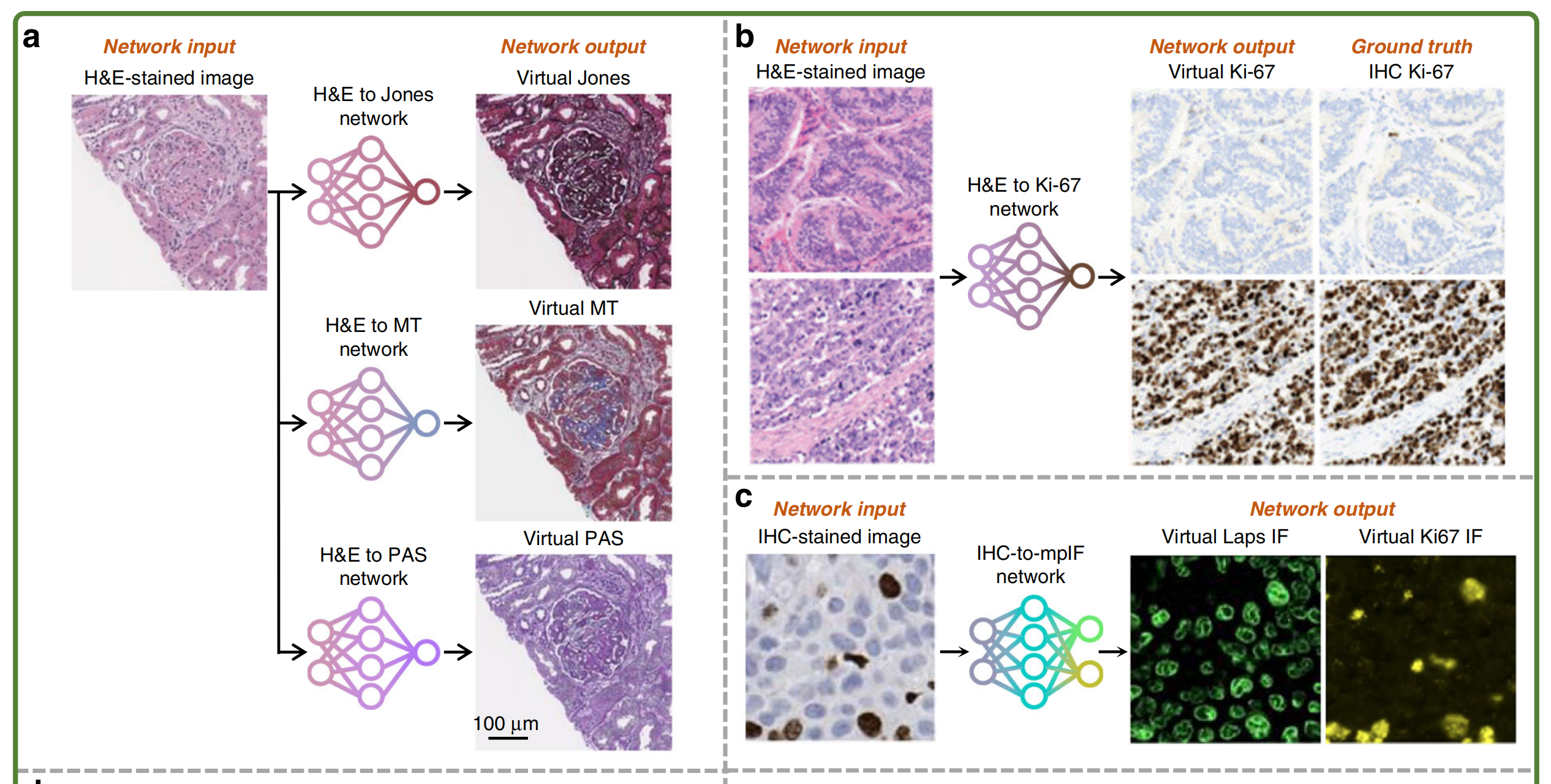
例如,Liu等人展示了从H&E到神经内分泌和乳腺组织样本的Ki-67 IHC染色的转换(图5b)49。
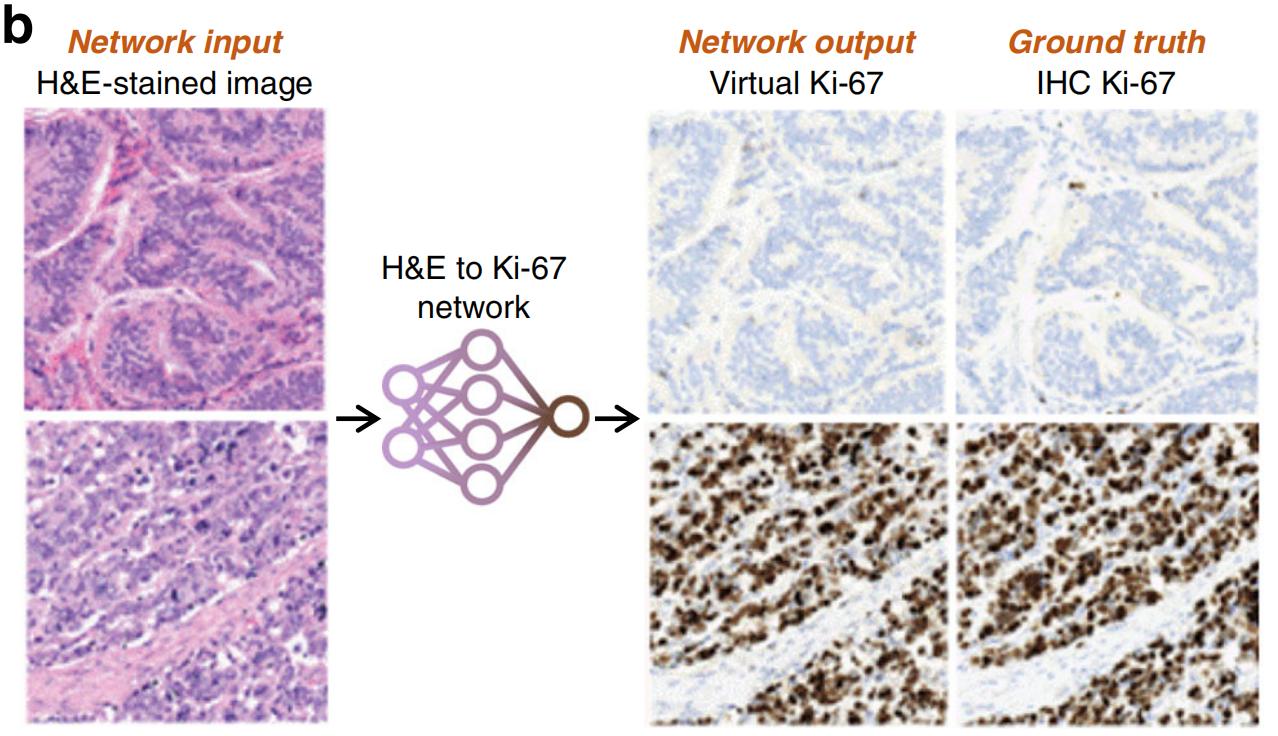
他们生成的虚拟IHC图像与真实IHC图像在Ki-67阳性细胞和Ki-67阴性细胞上的一致性很高。Xie等人从H&E染色的3D全前列腺活检样本中实现了对细胞角蛋白8(CK8)的虚拟IHC染色,这可能有助于改善前列腺癌的风险分层50。
其他从H&E生成的/转换的虚拟IHC染色包括HER251,52和磷酸化组蛋白H3(PHH3)53在乳腺样本上,SOX10在肝样本上54,以及肝55和胃56样本上的细胞角蛋白(CK)。
与使用色度标记突出特异性抗体与其目标配体结合的色度IHC染色相比,基于抗原识别元素的免疫荧光(IF)染色允许通过使用荧光标记进行改进的灵敏度和信号放大57。其他染色类型生成虚拟IF染色的报道也有所报道:Ghahremani等人使用Ki-67 IHC染色图像生成人类肺和膀胱样本上的多标记虚拟IF染色(图5c)58。
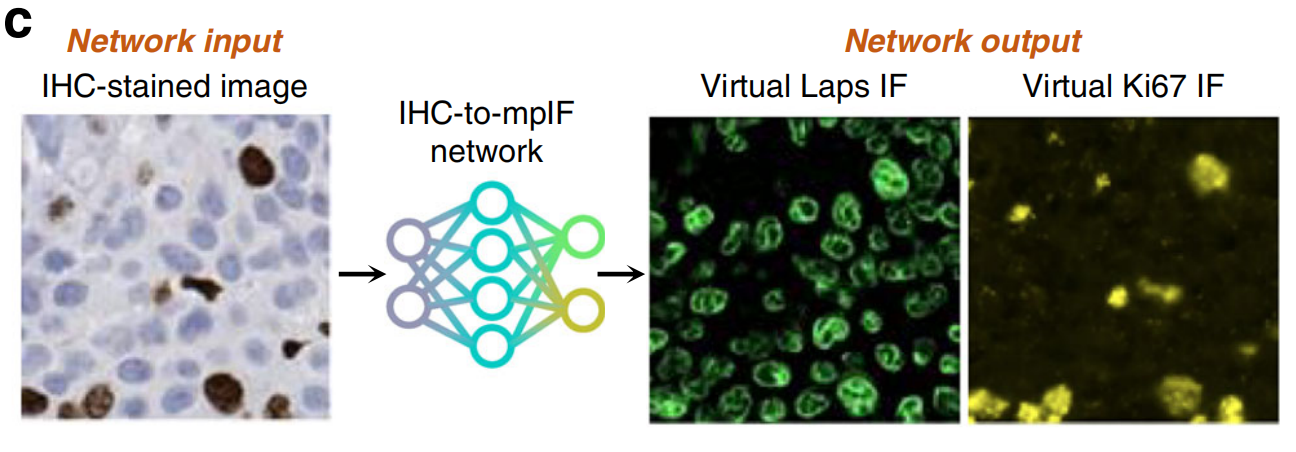
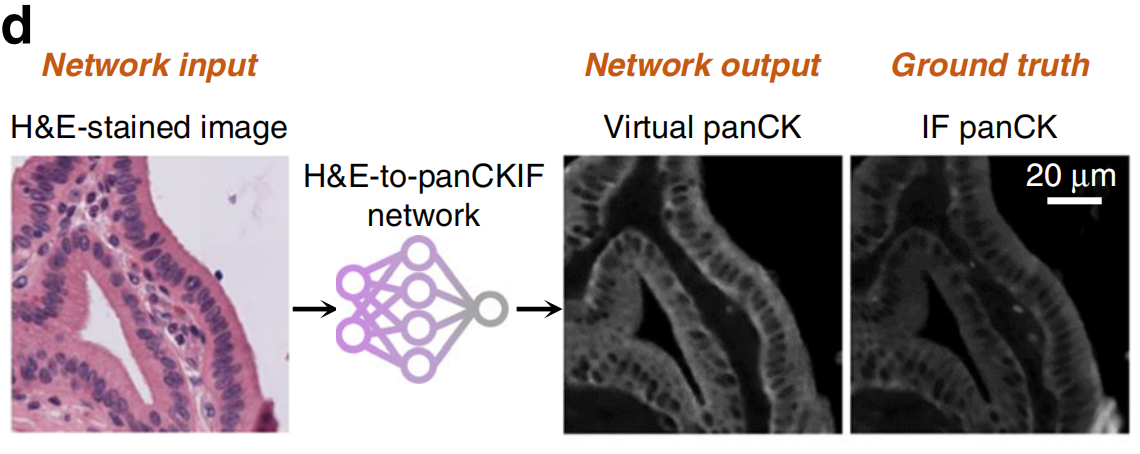
Burlingame等人实现了从H&E染色图像到人胰腺癌样本上泛细胞角蛋白(panCK)生物标志物的虚拟IF染色(图5d)。
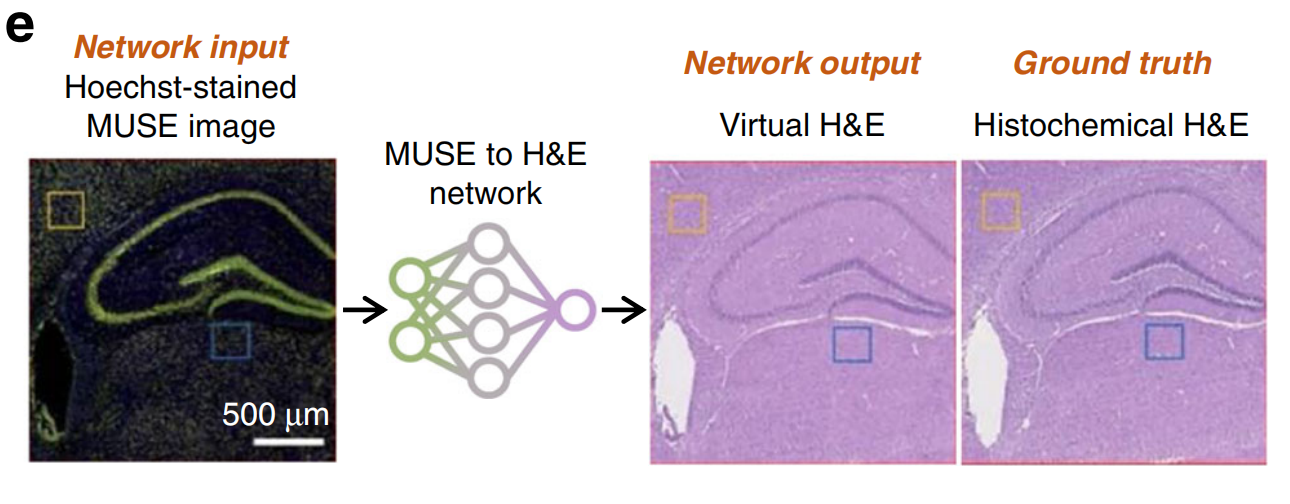
除了使用福尔马林固定、石蜡包埋(FFPE)的组织切片进行染色到染色转换外,还报道了从Hoechst染色的紫外表面激发显微镜(MUSE)图像生成H&E染色作为另一种形式的染色到染色转换,其额外优势在于Hoechst染色非常快且相对简单(图5e)60。
五、训练数据准备
上述虚拟染色模型的训练通常需要从输入域和目标(真实)域收集图像数据,以便模型能够被训练来利用和转换输入域到目标域的信息。
从原始图像数据的收集到虚拟染色模型的训练,需要进行图像预处理步骤,以便为成功学习图像转换准备数据集。这些数据预处理步骤主要关注于对齐输入和目标图像对,这对于监督学习框架至关重要,并消除意外的异常值,例如错位的图像对和染色伪影18。
数据预处理的另一个目标是解决域移问题61,这指的是模型训练数据集内或训练数据集与测试期间遇到的任何数据集之间的统计分布偏差。这种偏差可能源于多种来源,例如图像采集设置的变化以及基于化学的组织染色工作流程中染色变化的自然属性。通过适当的数据标准化方法,图像之间的这种偏差可以最小化,使得图像数据的统计分布限制在一定范围/域内,以促进虚拟染色任务的可学性62,63。
输入和目标图像对的交叉注册通常在监督学习框架中采用。例如,Rivenson等人关于虚拟染色自体荧光图像的工作报道了一个多模型图像注册算法,如图6所示。
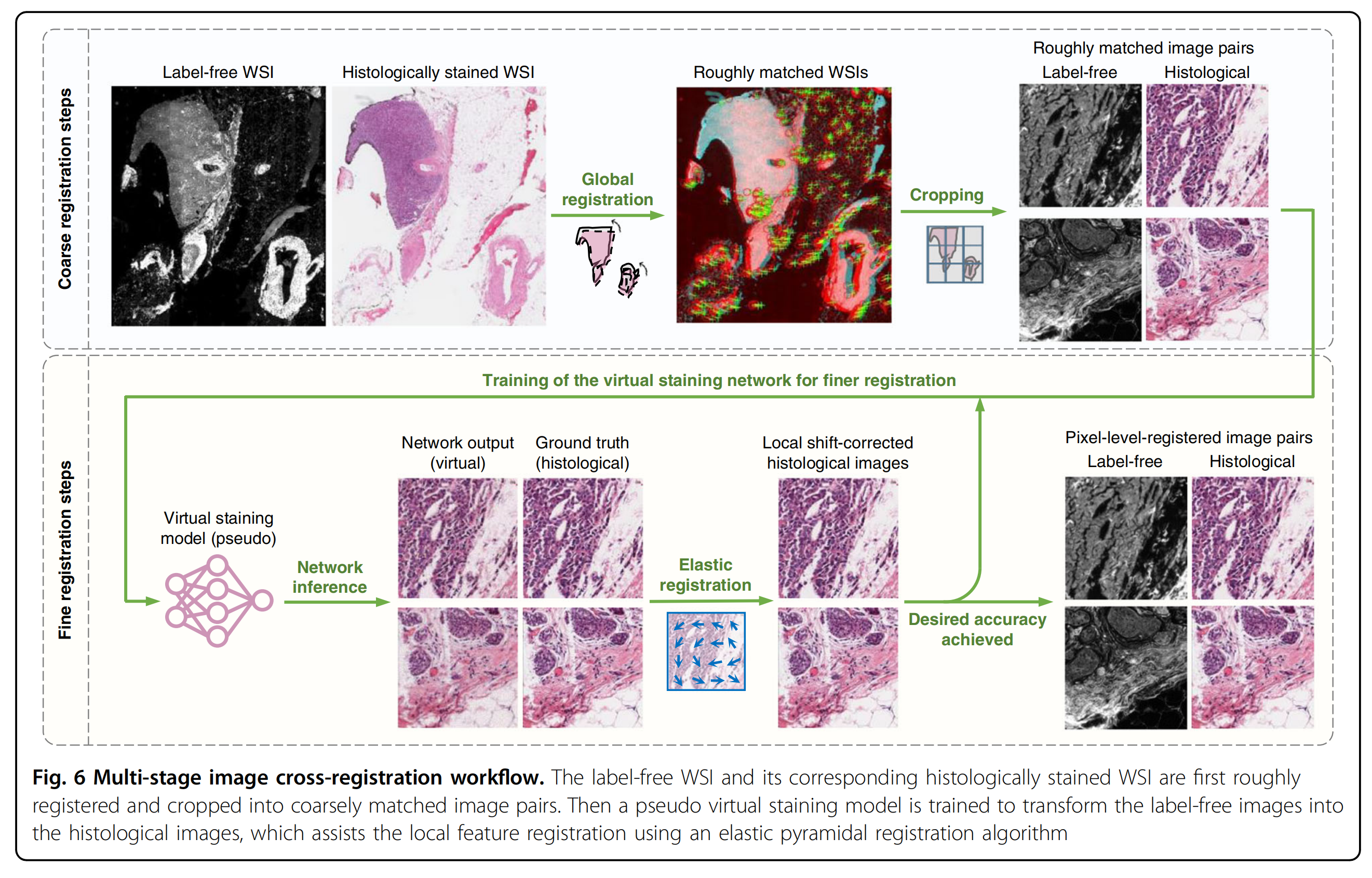
该算法从与相应组织化学染色过程完成后相同组织切片的自体荧光图像与明场图像的粗略配准开始,通过搜索最高交叉相关得分来提取两种成像模式的大致匹配的视野(FOV)。然后通过匹配提取的组织化学染色图像和自体荧光图像之间的特征向量(描述符)估计仿射变换,并将其应用于染色图像以纠正任何缩放或旋转的变化。
最后,在更精细的图像注册步骤中,首先使用少量迭代次数训练与大致匹配的图像匹配的虚拟染色网络,以学习颜色映射。然后将训练好的伪模型应用于自体荧光图像,使用弹性金字塔注册算法协助局部特征注册,帮助实现无标记组织切片(输入图像)的自体荧光图像与其相应组织化学染色真实图像之间的像素级配准精度。类似的多阶段图像注册算法也被用于其他基于监督学习的虚拟染色方法20-23,31。
对于无标记显微镜图像,域移问题通常表现为在不同实验条件下出现的成像变化。
这可能由不同的成像硬件/设置、不一致的图像采集环境以及样本特征或样本制备协议的变化引起。为了解决这个问题,通常会在将无标记图像输入到虚拟染色神经网络之前对图像进行标准化。
例如,为了避免自体荧光成像中潜在的光漂白引起的强度变化,Rivenson等人通过在整个组织切片上减去像素值的平均值并将结果除以像素值的标准差来标准化输入的自体荧光图像18。或者,为了减轻这些变化并增强图像对比度,一些工作饱和了像素值的前1%和后1%38,39。
Pradhan等人还报告说,将无标记的非线性多模态(NLM)图像标准化到像素值范围-1到1可以避免在训练过程中进行大量乘法运算,有助于更好地网络收敛35。除了可以通过适当的标准化来减轻的变化之外,有时捕获的显微镜图像可能会受到失焦、运动模糊和读出错误等问题的影响。
例如,Zhang等人提出了一种使用失焦自体荧光图像作为输入的虚拟染色框架,其中首先训练了一个自动对焦网络,将随机失焦(非理想)的图像聚焦,然后由联合训练的虚拟染色网络生成聚焦的虚拟染色组织图像;这可以显著加快整个切片成像,因为在这种情况下不需要在组织扫描过程中进行精细对焦。同样,输入端的其它非理想成像条件也可以通过预训练的神经网络来减轻70,71。
在组织化学染色图像中,域移问题也存在,通常表现为由于化学染色变化(从实验室到实验室或组织技术员到组织技术员)导致的极大的不一致颜色和对比度。
消除训练数据集中此类变化的常用方法是使用染色分离和颜色标准化算法。传统上,这些方法通过颜色去卷积和光学密度映射来实现72-74。
例如,Burlingame等人使用Macenko方法标准化了H&E图像,以减轻样本间染色变化59。最近,基于深度学习的染色标准化也已被使用,因为其能够考虑组织结构的空域特征,避免了传统算法染色标准化方法中可能产生的不适当的染色75,76。
除了使用标准化方法统一化学染色图像的颜色和对比度之外,另一种减轻真实域中此类域移问题的方法是将这些变化融入训练数据集。例如,de Haan等人使用预训练的风格转换网络将H&E染色图像转换为不同的风格,用于训练染色到染色转换网络21,确保该方法在各种H&E染色组织样品风格下有效,不受技术人员、实验室或设备变化的影响除了图像注册和标准化之外,算法或手动数据清理也是常见的过程,以去除可能误导网络训练的不良数据,例如变形的组织切片或包含非组织污染物(例如灰尘或气泡)的图像。
这些步骤对于确保训练数据的质量和一致性至关重要,因为不准确或损坏的数据可能会影响深度学习模型的性能和准确性。通过仔细准备和清洗数据,可以提高模型的泛化能力和预测性能,从而在实际应用中提供更加可靠和准确的结果。
总的来说,训练数据的准备是深度学习模型开发中的关键步骤,它直接影响到模型的性能和可扩展性。通过精心设计的数据收集、预处理和清洗流程,可以有效地减少数据中的噪声和不一致性,从而提高深度学习模型的训练效率和最终性能。
六、网络架构和训练策略
在虚拟染色领域,已报道了多种网络结构,其中生成对抗网络(GAN)是最常用和广泛使用的框架之一,因为它具有强大的表示能力18,20-23,31,32,36-38,48,51,56,59,78,79。
与非GAN基的推理模型相比,GAN可以生成相对较高分辨率和感知上更真实的图像13,14,59。由于GAN在现有虚拟染色研究中的主导地位和广泛采用,我们主要关注基于GAN的框架的网络架构。
在GAN框架中,两个深度神经网络,生成器(Generator)和判别器(Discriminator),以同步和竞争的方式进行优化80。生成器网络学习执行从输入域到目标域的图像转换,通常采用U-Net架构或其变体。
另一方面,判别器网络是一个分类器,学习区分由生成器生成的虚拟染色图像和目标组织化学染色图像。在训练过程中,判别器查看虚拟染色图像并返回对抗损失给生成器,帮助生成器生成判别器无法区分的图像。当训练进入平衡状态时,生成器能够创建判别器无法区分的虚拟染色图像。
然而,在标准的GAN框架中,生成器仅通过对抗损失进行优化,导致生成的生成器仅模仿目标图像的颜色和图案,而没有学习输入和目标图像之间的潜在对应关系,导致在微观尺度上产生严重的幻觉19。
为了克服这种幻觉问题,将各种其他像素级损失函数,如均方绝对误差(MAE)18,21,22,32,36,37,51,56,59、均方误差(MSE)18,79、结构相似性指数(SSIM)31,82、Huber损失31、反转Huber损失23以及颜色距离度量56等纳入生成器损失项(除了判别器损失),以正则化GAN训练;
这些附加的损失项使用虚拟生成的图像及其相应的真实图像(组织化学染色图像)进行计算。此外,一些工作还利用了图像正则化项,如总变差83,以消除或抑制生成器产生的不同类型的图像伪影18,20-22,31。
七、虚拟染色模型评估
在虚拟染色模型训练完成后,需要对其进行全面的定性分析和定量分析(图8)。
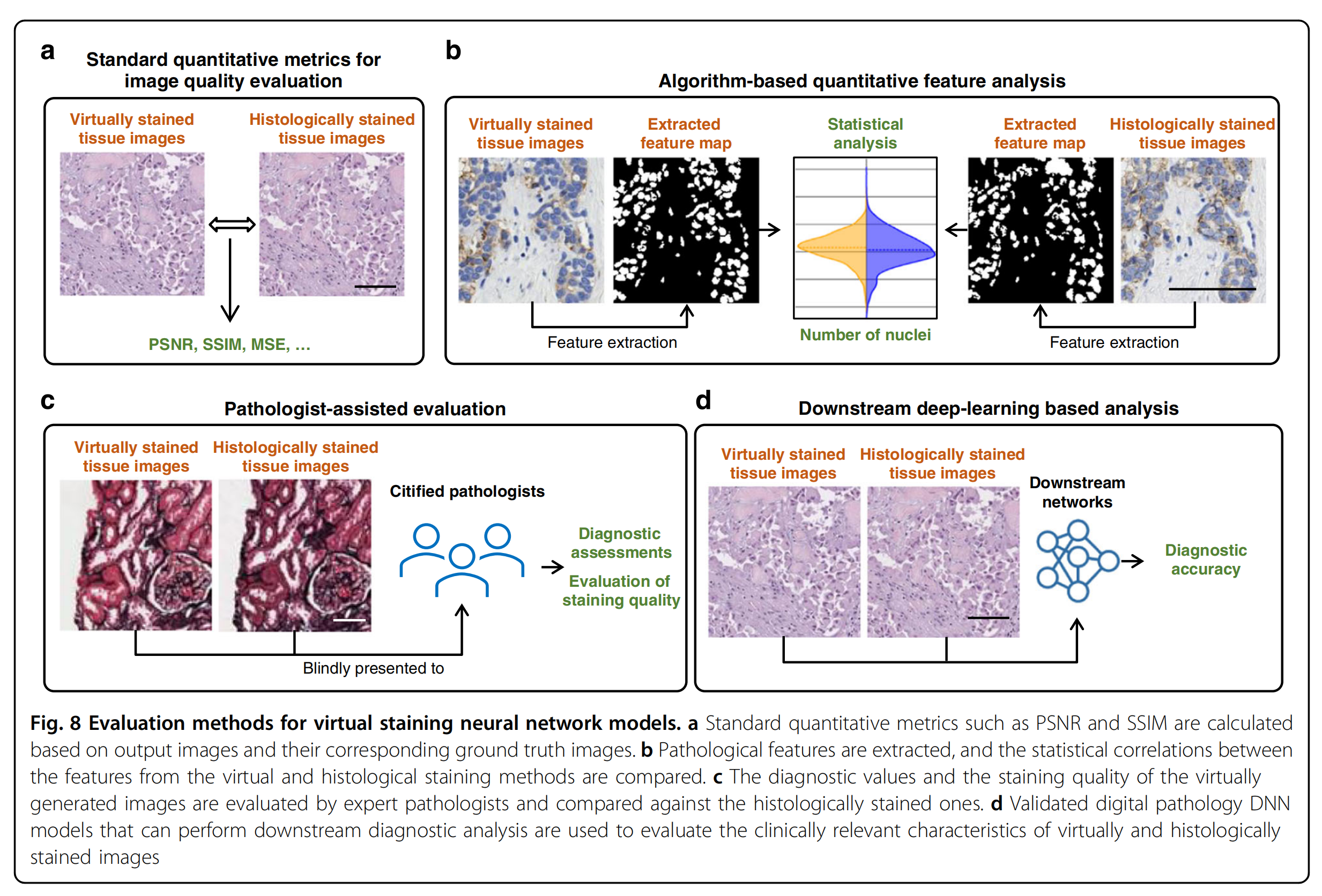
一种基本且直接的评估方法是直接使用标准定量指标(图8a)测量虚拟生成的组织学图像与其化学染色对应物(真实图像)之间的匹配程度。当有成对的输入和真实图像时,通常使用像素级评估指标,如SSIM82、峰值信噪比(PSNR)84、多尺度结构相似性指数测量(MS-SSIM)85、均方误差(MSE)和均方绝对误差(MAE)。
当输入和真实图像不成对时,可以使用参考自由指标,如弗雷歇特 inception 距离(FID)86和 inception 分数(IS)87,通过比较使用训练网络提取的高级特征来评估生成模型的性能。大多数文献中开发的虚拟染色网络都使用这些标准定量指标之一或多个来评估网络推断的图像质量(见表1和表2)。
为了更好地评估模型在组织学背景下的性能,下一步是从虚拟染色图像和其真实图像中提取关键细胞特征,然后评估这些提取特征之间的相关性,以统计上揭示组织学等效性水平(图8b)。
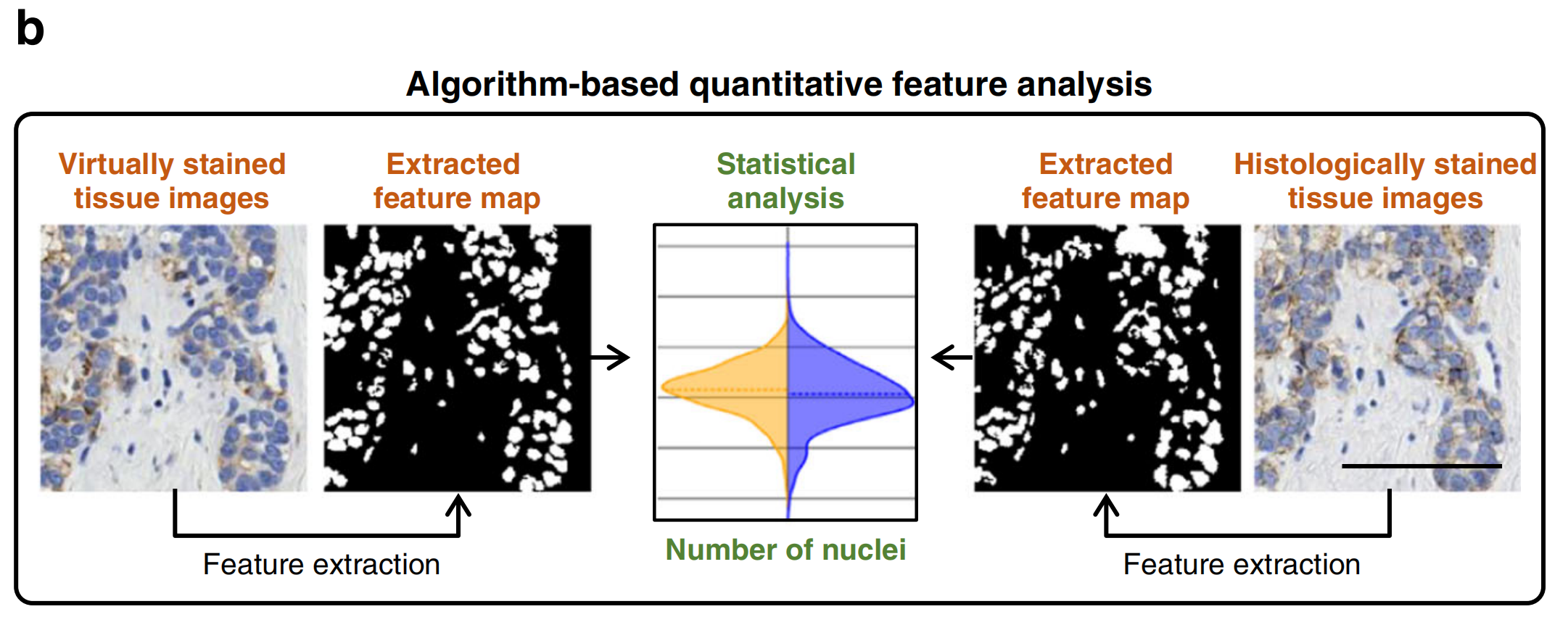
例如,Bai等人进行了颜色去卷积并分离了不同的HER2染色通道,以提取核和膜特征,基于此发现虚拟染色输出与真实图像之间的统计特征签名具有良好的一致性31。
同样,对分割的Ki-67阳性染色区域49、分割的细胞质和细胞核54、分割的上皮和腔50、分割的肿瘤和间质区域56进行基于特征的定量分析,报告称这些分析验证了训练的网络模型在虚拟染色方面的效果。
尽管使用了各种图像质量指标和特征分析工具,算法分数并不能总是准确反映虚拟组织学图像的诊断价值,因为病理上有意义的特征复杂且无法总是通过简单的数值规则明确描述。在部署之前,至关重要的是验证虚拟染色图像传达的诊断相关信息与传统组织化学染色切片相同。
因此,在评估过程中包括认证病理学家对虚拟生成图像进行案例研究,评估重要的病理特征并做出诊断决策,是一个重要的部分(图8c)。
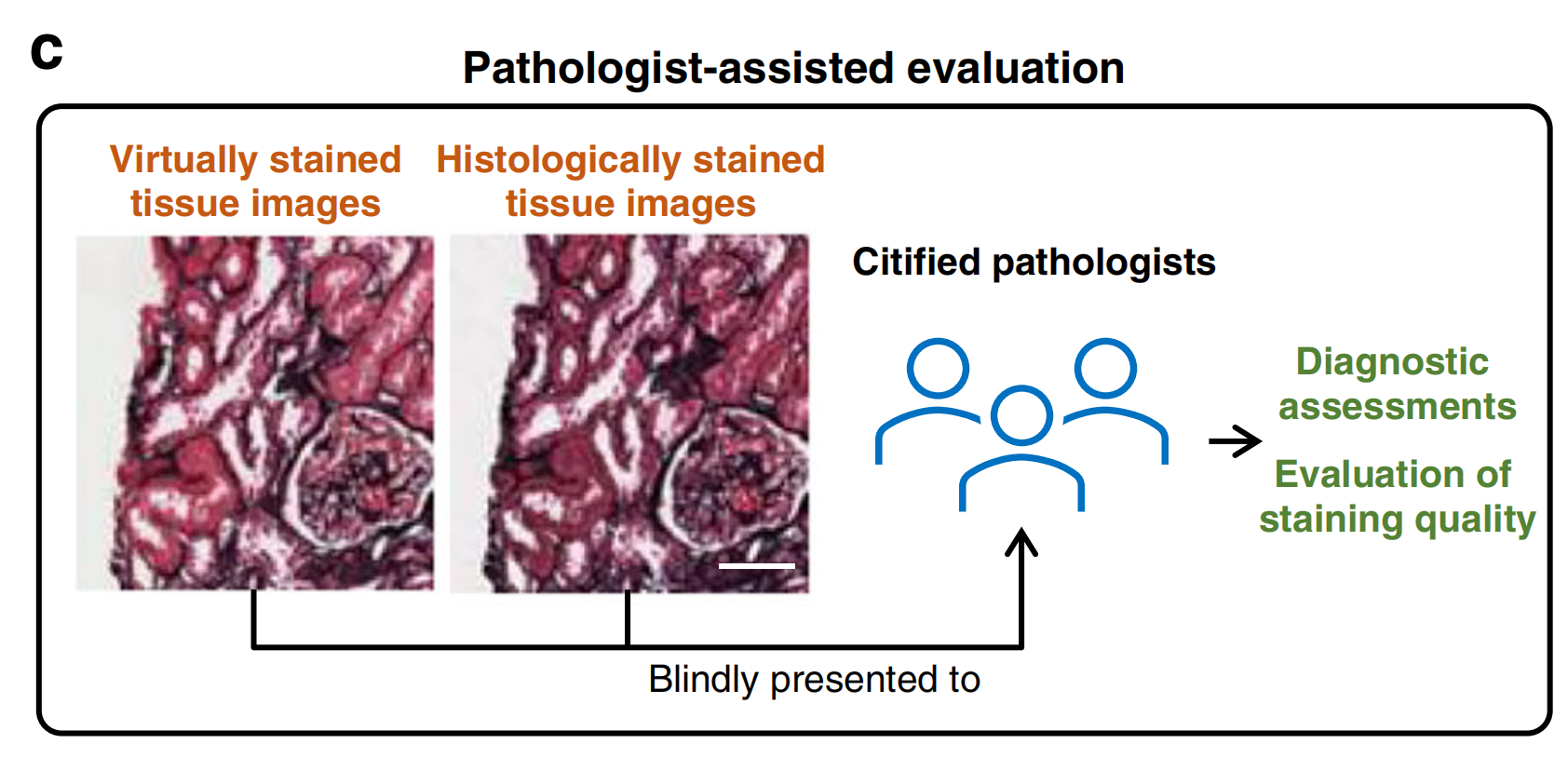
例如,在de Haan等人的工作中21,三位肾病学家确认从现有H&E图像生成额外的虚拟特殊染色有助于提高肾脏疾病的诊断;同样,Bai等人31也包括了三位认证的乳腺病理学家来验证虚拟生成的HER2图像的诊断准确性和染色质量。作为另一个例子,Lahiani等人55在其研究中包括了两位病理学家,以验证虚拟染色图像与相应组织化学染色图像之间的高度一致性。
类似于让人类病理学家评估虚拟染色图像的案例研究,数字病理学深度神经网络(DNN)模型也可以训练执行多种下游诊断分析,如癌症阶段分级89(图8d)。
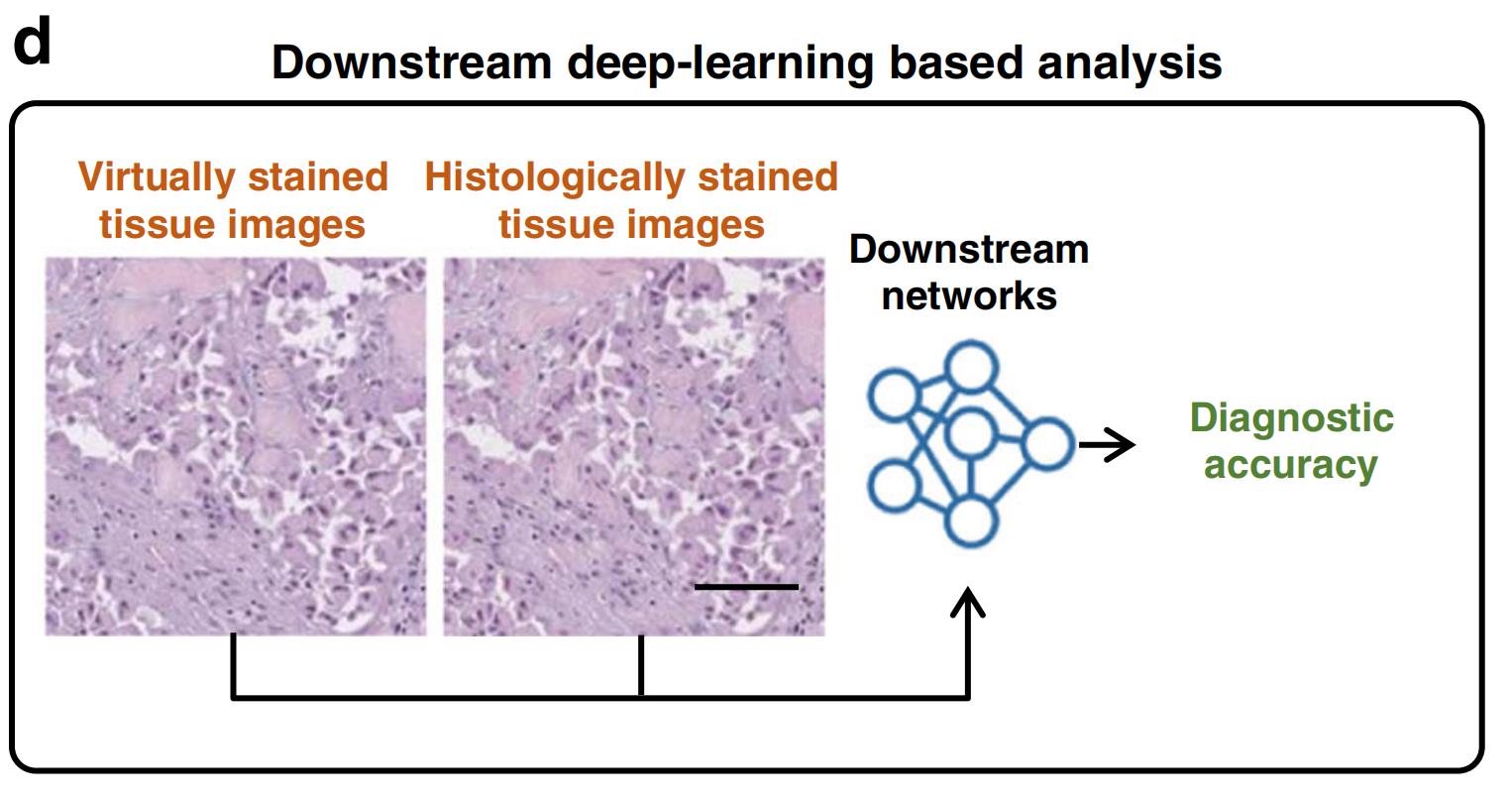
这些数字病理学模型可以创建有效的评估工具,在比较虚拟和化学染色图像的临床相关特征的案例研究中使用。更重要的是,这些自动化的图像比较和评估工具完全可扩展,可用于大规模研究, potentially 消除由于病理学家数量有限而造成的瓶颈。
例如,Kaza等人39训练了一个分类模型来区分死亡和存活的细胞及其亚型,该模型用于验证虚拟染色模型的性能。同样,Li等人26训练了一个用于结肠腺体分割的下游卷积神经网络,以证明虚拟染色图像保留了与组织化学染色相同的丰富组织病理学信息。
八、讨论与未来展望
基于深度学习的虚拟染色技术已使快速、成本效益高且无化学物质的病理学成为可能,为开发了一个世纪的传统组织学染色方法提供了强大的替代方案。
大多数虚拟染色技术仅消除了完整组织学程序中的染色步骤,而保留了样本预处理和准备步骤不变,使其与现有临床工作流程兼容。病理学中的样本周转时间(TAT)被美国病理学家学院定义为“从样本在实验室接收的那天到最终报告签出的那天”90。
即使虚拟染色在病理学家进行显微镜检查之前仅适度缩短了样本制备时间,也可能在一天结束之前和之后的工作日之间产生差异(导致TAT至少相差一天)。此外,由于虚拟染色在载玻片之间的染色质量变异较小,因此可以减少技术上失败的染色载玻片的数量,这也有助于减少TAT。
此外,重要的是要强调,化学染色过程往往是病理学实验室的主要负担,它需要使用、存储和处理多种类型的试剂和抗体,其中一些是高度昂贵或有毒的。
化学染色中的另一个主要问题是基础化学品的质量保证,这些化学品容易受到供应链问题影响,如大多数病理学实验室在最近的COVID大流行期间所经历的那样。涉及训练有素的组织技术人员执行多种染色协议的染色程序也是病理学中最耗时和劳动密集的步骤之一。
因此,消除化学染色过程将大大减轻实验室基础设施和人员培训的需求,节省宝贵的实验室资源,并允许在相同的实验室容量下处理更多的样本。
作为一个通用框架,虚拟染色方法可以广泛适应各种样本制备程序,如冷冻切片、新鲜切割的组织块或人体器官的活体成像。
随着无标记成像/显微镜技术的发展,传统的样本制备过程可能会被取代,从而进一步加速整个组织学工作流程。除了节省时间、成本和劳动力外,虚拟染色还固有地具有多重染色的能力。
可以在同一组织横截面上同时生成不同类型的染色,使用单个(或多个)虚拟染色模型提供额外的组织学信息,有助于诊断评估21。这种额外的组织学信息也被证明可以改善数字病理学中其他下游机器视觉任务的表现,如病理特征的检测或分割27,50,53,55,58以及恶性肿瘤的分类32,39,91。
允许在同一组织切片中进行不同染色,将为诊断困难的病例保留更多的组织,以便进行辅助测试(例如DNA/RNA测序),这些测试可能需要才能得出诊断。
随着这一新兴技术的发展,需要进一步的努力来加速虚拟染色应用的开发和采用。
此类努力将包括促进数据一致性、提高染色通量、整合最新的深度学习进展以提高虚拟染色网络的泛化能力,以及建立/验证更好的模型表征方法,这些方法将在以下部分进一步讨论。
与大多数基于数据的深度学习技术一样,获取大量高质量数据是成功训练虚拟染色模型的关键。
然而,创建虚拟染色数据集面临独特的挑战,因为生成一致的组织学真实图像的技术限制。染色结果受到实验室之间和历史技术人员之间变化的困扰,这部分可以归因于病理学实验室中协议和实践的变化92。
在WSI数字化过程中,不同品牌的全切片扫描仪使用的不同图像传感器、物镜和图像预处理管道(例如,图像锐化、自动对焦和颜色校正)使这种变化更加严重。此外,标准组织化学染色程序还会引入严重的机械变形甚至对组织切片造成损害,导致在监督学习中进行图像注册的困难。
例如,在Bai等人的虚拟HER2染色工作中,大约30%的组织化学染色样本由于组织丢失或化学染色失败而被丢弃31。综上所述,获取高质量的真实图像可能会非常缓慢和昂贵。
除了获取高质量的组织学图像的困难外,获取大规模的无标记图像也面临与样本之间变化相关的挑战。
样本制备协议、无标记成像硬件(例如,光源、物镜和图像传感器)、图像采集配置(例如,积分时间和自动对焦)以及图像预处理管道等差异都会导致输入图像的变化,这可能会对无标记虚拟染色模型造成重大挑战,即使使用了适当的图像标准化方法。
因此,创建大规模、标准化和公开可用的数据集,供该领域的研究人员使用,将提供各种新兴方法的标准化测试平台。一个相关的工作是癌症基因组图谱(TCGA)93,它包括来自9000多个病例的超过30,000个全病理切片图像,用于癌症研究。
此外,近年来,已发表了许多用于病理图像分析的数据集,例如CAMEL-YON17挑战94、前列腺癌分级评估(PANDA)挑战95、Mitosis Domain Generalization(MIDOG)挑战96等。
然而,尽管这些数据集对于虚拟染色模型的预训练和开发下游分析工具非常有价值,但仍然缺乏一个专门为虚拟组织染色设计的全局数据库。
创建这样的虚拟染色数据集将需要从不同的解剖部位收集样本,并对来自不同医疗中心/实验室的这些组织样本进行准备、染色和数字化,使用标准化和广泛可用的图像采集和处理管道。
另一个未来的研究方向可能是提高虚拟染色方法的通量。
经过数十年的工业发展,标准组织学染色和图像数字化过程已通过自动化批量染色和扫描WSI设备大大加速,达到满足临床需求的高通量。另一方面,一些无标记的虚拟染色方法,虽然跳过了化学染色程序,但使用了相对较慢的成像模式,如FLIM34。
需要专门的技术努力来优化成像硬件和协议,以实现高通量的虚拟染色方法,这些方法可以广泛替代标准组织学方法;为此,无标记成像模式需要能够定期扫描/数字化整个载玻片图像(具有几平方厘米的组织区域),只需几分钟。
此外,进一步的努力可以将这一虚拟染色技术提升到超越标准组织学染色的性能,并可能用于虚拟染色当前方法未能突出的细胞元素,例如被严重遮蔽的抗原、表达水平低的蛋白质,甚至可能有助于检测需要昂贵辅助测试才能检测到的基因组异常(例如原癌基因放大、缺失和融合),这些测试在许多病理学实验室中不可用。
此外,开发用于非固定新鲜组织样本的快速稳定无标记成像系统,并在其上实施虚拟染色,也将是一个有影响力的研究方向,这可能会消除某些解剖部位的活检需求,并在手术操作期间提供有价值的术中咨询。
我们预期,虚拟染色技术将继续通过利用不断发展的最先进深度学习技术得到改进,这些技术具有更多样化的网络架构、新的特定任务损失函数和更有效的训练策略。
例如,作为深度学习任务的新兴主干,变压器在各种计算机视觉任务上表现优于卷积神经网络97-99,这可能也为虚拟染色网络提供有前景的改进,可能提供更高的图像分辨率和染色精度。
此外,在训练阶段可以引入针对病理图像使用手工制作的专业特征或预训练特征提取器的损失函数,作为特定领域的惩罚项,这可能会提高虚拟染色网络的泛化能力。其他新兴的训练策略,如学习率调度、大规模并行训练和不同的标准化方案,也将是进一步推动虚拟染色网络能力的关键。
尽管本综述中总结的技术可行性和概念验证演示令人鼓舞,但虚拟染色技术在临床环境中用于主要诊断用途的实施尚未到来(这需要通过FDA的III类批准过程)。为此,虚拟染色技术的准确性和可靠性需要由不同医疗机构使用大量不同病理的患者的广泛分布的组织样本进行全面表征/验证。
为了减轻对虚拟染色网络幻觉的潜在担忧,已开发了各种定量指标(见前面讨论的模型评估部分),这些指标可用于评估模型的有效性和虚拟染色结果的图像质量。基于这些现有指标,需要建立一个定量基准,以反映由于化学染色和观察者间变异导致的诊断错误或不确定性,为所有虚拟染色研究提供比较和指导适当设计的案例研究的参考。
此外,虚拟染色技术的发展和进步阶段需要快速和定量的反馈,以在迭代开发过程中收敛到可在临床环境中测试的竞争模型。该领域的研究人员已经开发了用户友好的评估软件/工具,用于测试不同的模型和评估组织学特征;例如,DeepImageJ100、CellProfiler101、QuPath102等。
还可以进一步开发自动化和可靠的评估工具(例如一组特定任务的神经网络),在研究和开发阶段部分替代人类诊断医生或病理学家,这将大大加快虚拟染色研究的进展,因为大规模、多机构验证努力中可用训练有素的病理学家可能会带来挑战。
快速发展的计算病理诊断框架也可以为虚拟染色模型与标准组织化学对应物之间的性能比较提供强大的工具。这样的自动化和可重复的图像质量评估工具也将对促进全球范围内大规模案例验证研究的设计非常有价值,并有助于加速虚拟染色技术的临床接受。


















 2367
2367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









