







小罗碎碎念
截至2024-12-21,剔除掉部分低质量文献后,2024年病理AI领域共发表1727篇文章。
为了尽可能包含与病理AI相关内容,我选出的1727篇文章中包含各种类别的文章,例如稍后推文中会涉及的综述、实验以及评论和观点类文章等。
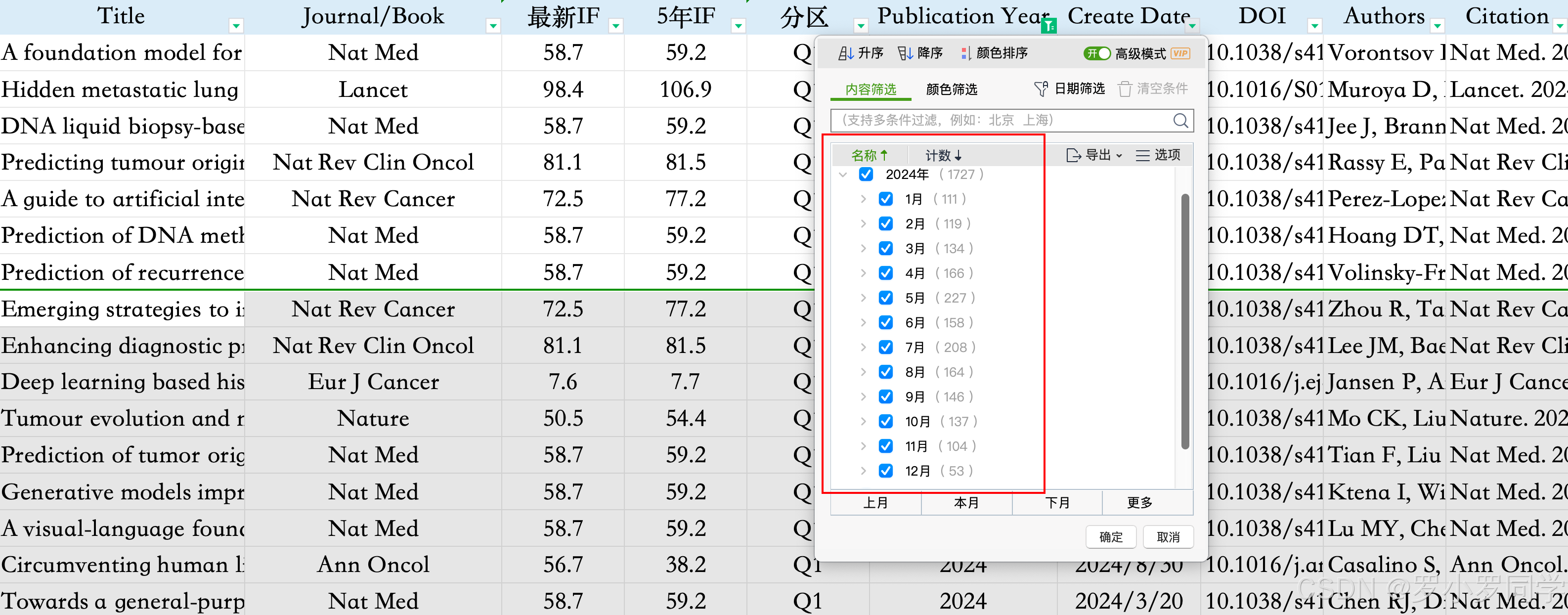
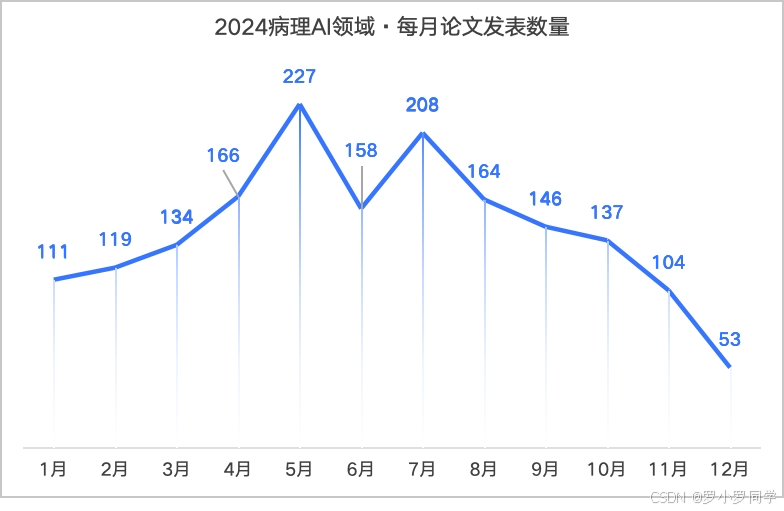
通过一个折线图直观的观察每月论文发表的趋势,我们会发现年中是发文的高峰期。
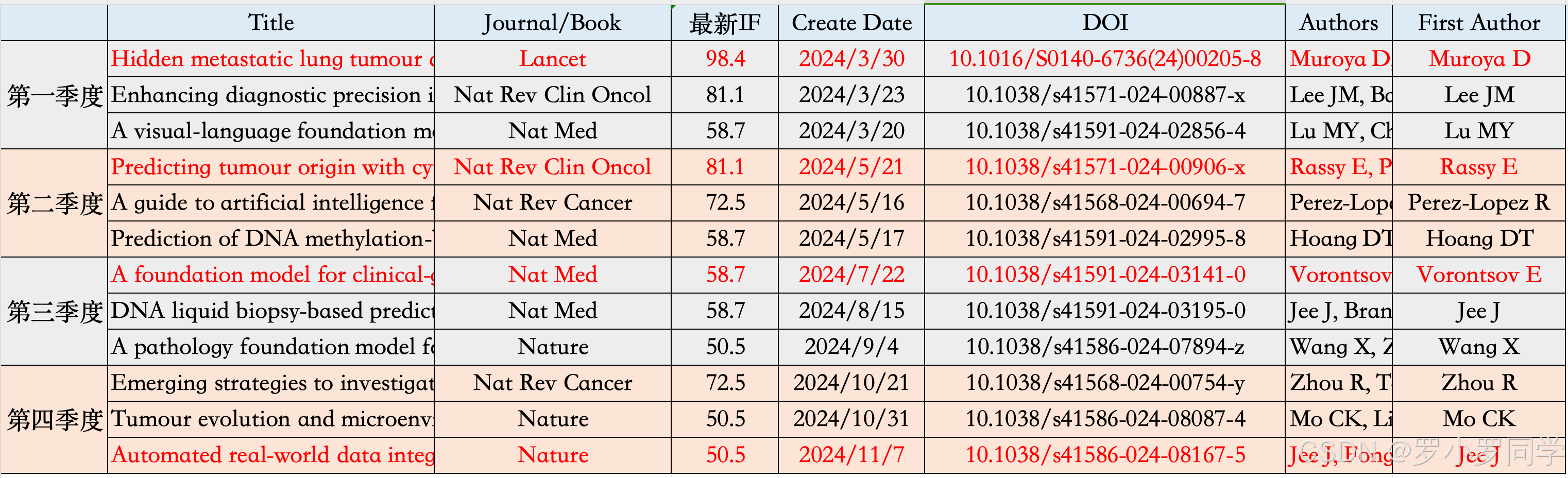
作为一篇年终总结性质的推送,我会按照四个季度划分,并在每个季度挑选三篇最高分的文章推荐给大家,和大家回顾一下这一年病理AI领域的发展情况。
第一季度
速览
第一篇文章介绍了一种名为CONCH的视觉语言基础模型,能够在多种病理学任务中实现最先进的性能,尤其是在零样本学习和跨模态检索方面。
第二篇文章介绍了LiAIDS,一个基于深度学习的全自动系统,它在提高肝脏病变诊断精确性方面展现出巨大潜力,但也面临临床应用的挑战。
第三篇文章是发表在《柳叶刀》杂志上的一篇临床病例报告,人工智能辅助诊断技术成功识别并治疗了一位75岁女性患者的隐匿性肺转移瘤。
CONCH模型:病理学中的先进视觉语言基础模型

一作&通讯
| 角色 | 姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Ming Y. Lu | 哈佛医学院布里格姆和妇女医院病理科 |
| 通讯作者 | Faisal Mahmood | 哈佛医学院布里格姆和妇女医院病理科 |
文章介绍了一种名为CONCH(CONtrastive learning from Captions for Histopathology)的视觉语言基础模型,该模型通过使用多样的组织病理学图像、生物医学文本以及超过117万张图像-标题对进行任务无关的预训练,以提高在各种病理学任务中的性能。
CONCH模型在14个不同的基准测试中进行了评估,包括组织学图像分类、分割、标题生成以及文本到图像和图像到文本的检索任务。研究结果表明,CONCH在组织学图像分类、分割、标题生成以及文本到图像和图像到文本检索方面均取得了最先进的性能。CONCH模型的预训练使其能够直接应用于多种下游任务,而无需进一步的监督微调。
文章还讨论了CONCH模型在零样本分类、少样本分类、跨模态检索和零样本分割等方面的应用,并展示了其在这些任务中的性能。此外,文章还探讨了CONCH模型在处理罕见疾病分类任务时的潜力,并提出了未来研究的方向,包括扩大预训练数据集的规模和质量,以及提高模型在面对大量类别和罕见疾病时的零样本识别能力。
深度学习系统LiAIDS:提升肝脏病变诊断准确性的新突破

一作&通讯
| 姓名 | 单位(中文) |
|---|---|
| Jeong Min Lee | 首尔国立大学医院放射科,首尔国立大学医学院放射科,首尔国立大学医学研究中心放射医学研究所 |
| Jae Seok Bae | 首尔国立大学医院放射科,首尔国立大学医学院放射科,首尔国立大学医学研究中心放射医学研究所 |
这篇文章讨论了一种名为Liver Artificial Intelligence Diagnosis System (LiAIDS)的深度学习系统在提高肝脏病变分析诊断精确性方面的潜力和挑战。
LiAIDS是一个全自动系统,它集成了深度学习技术,基于增强CT扫描和临床信息来诊断肝脏病变。
-
LiAIDS的开发与验证:LiAIDS通过集成三个独立的深度学习模块来检测和分类肝脏病变,这些模块分别负责病变检测、肝脏分割和基于图像特征及临床信息的病变分类。系统在中国18家医院的11956名患者数据上进行了训练和验证。
-
性能表现:LiAIDS在区分恶性和良性病变以及将病变分类为七种最常见的类型方面表现出色,其在五个验证队列中的宏平均AUC值在0.958到0.989之间。它不仅超过了初级放射科医生的预测性能,而且与高级放射科医生的性能相当。
-
临床应用:LiAIDS在前瞻性分流研究中自动将76.46%的患者归类为低风险(无病变或明确良性病变),并且具有99.0%的高阴性预测值。
-
AI在医学影像中的潜力:AI系统,特别是通过深度学习和卷积神经网络,为提高疾病检测和特征描述的自动化提供了解决方案,支持临床决策,扩展了医生的能力。
-
挑战与障碍:尽管AI系统在提高诊断准确性方面显示出潜力,但在临床整合方面仍面临挑战,包括对手动病变提取的依赖、数据隐私和安全、模型解释性、过拟合以及整合到标准临床工作流程中的问题。
-
可解释性和临床结果:提高LiAIDS决策过程的可解释性可能有助于其在临床决策中的接受度。此外,证明LiAIDS对临床结果的影响(包括患者负担、发病率和生存结果)对于确认其作为标准临床工具的效用至关重要。
-
结论:LiAIDS作为全自动深度学习方法在FLL诊断中提供了增强的准确性和对放射科医生的支持,尽管面临挑战,但解决这些问题对于充分发挥这一工具在改变肝病护理中的潜力至关重要。
文章强调了LiAIDS在提高诊断准确性、简化放射科医生工作流程和优化患者分流方面的潜力,同时也指出了其在推广和应用中需要克服的挑战。
人工智能助力诊断:75岁女性患者肺转移瘤的发现与治疗
这篇文章是发表在《柳叶刀》杂志上的一篇临床病例报告。
文章描述了一位75岁的女性患者,她在接受常规X光检查时被报告为没有异常。这位患者三年前因直肠和肛门癌接受了腹会阴切除手术。她的直肠癌被诊断为中度至良好分化的管状腺癌,大小为25毫米×20毫米,分期为pT2N0M0,属于I期;她的肛门癌被诊断为鳞状细胞癌,大小为5毫米×5毫米,分期为pTisN0M0,属于0期。
然而,当这位患者的X光片被一个基于人工智能(AI)的放射诊断软件包重新检查时,该软件包由富士胶片医疗公司开发,并在去年被医院用于所有胸部X光的常规检查,AI报告指出在左下肺叶有一个结节。尽管患者体格检查没有发现异常,实验室检查和肿瘤标志物也显示正常,但胸部CT扫描显示在心脏和降主动脉的背侧有一个10毫米的结节,这个结节在胸部X光上难以观察到。
患者随后接受了胸腔镜下的部分肺叶切除手术,术后没有并发症。手术中取出的12毫米×8毫米的组织样本的组织病理学检查显示为中度至良好分化的管状腺癌,确认了这是由直肠癌转移至肺部的转移瘤。
在3个月的随访中,放射科医生和AI软件包复查的胸部X光没有发现癌症复发的迹象,患者也没有呼吸症状。
文章还提到,近年来,使用机器学习和深度学习进行胸部X光自动诊断的尝试越来越多,计算机辅助诊断开始被纳入诊断过程,减轻了医生的工作量。基于AI的胸部X光的诊断性能已经达到了与放射科医生相同的准确性,在某些情况下甚至超过了它。
第二季度
速览
第一篇文章介绍了一个名为DEPLOY的深度学习模型,能够通过分析组织病理学图像预测CNS肿瘤的DNA甲基化状态并进行分类。
第二篇文章探讨了基于细胞学的深度学习工具TORCH在预测未知原发肿瘤起源中的潜力和挑战。
第三篇文章为癌症研究人员提供了一个关于如何利用人工智能工具的实用指南,涵盖了从深度学习原理到AI在生物医学图像分析、自然语言处理和药物发现等领域的应用。
DEPLOY模型:深度学习助力中枢神经系统肿瘤DNA甲基化分析

一作&通讯
| 角色 | 姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Danh-Tai Hoang | 国家癌症研究所(National Cancer Institute) |
| 通讯作者 | Eytan Ruppin | 国家癌症研究所(National Cancer Institute) |
| 通讯作者 | Kenneth Aldape | 国家癌症研究所(National Cancer Institute) |
研究团队开发了一个名为DEPLOY(Deep Learning from histoPathoLOgy and methYlation)的深度学习模型,该模型能够通过分析组织病理学图像来预测中枢神经系统(CNS)肿瘤的DNA甲基化状态,并将肿瘤分类为十大类别之一。
研究的关键点包括:
-
精确诊断的重要性:CNS肿瘤类型的精确诊断对于治疗至关重要,DNA甲基化分析是一种提高诊断准确性的方法,但这种方法耗时且并不普遍可用。
-
DEPLOY模型的组成:DEPLOY模型包含三个部分:
- 直接模型(direct model):直接从组织切片图像分类CNS肿瘤。
- 间接模型(indirect model):首先预测DNA甲基化beta值,然后用于肿瘤分类。
- 人口统计模型(demographic model):利用患者的年龄、性别和活检位置信息直接分类肿瘤类型。
-
模型训练与验证:研究者使用内部数据集(1,796名患者)训练了一个十类模型,并在三个独立的外部测试数据集(共2,156名患者)上验证了模型的预测能力,整体准确率达到95%,平衡准确度达到91%。
-
深度学习技术:深度学习技术能够识别人类观察者可能无法轻易识别的特征,并在预测基因突变、mRNA表达等方面显示出潜力。
-
模型性能:DEPLOY模型在预测甲基化水平和分类CNS肿瘤类型方面表现出色,即使在资源有限的地区也能提供快速的诊断评估,有助于提高病理学家在诊断上的准确性。
-
临床相关性:研究还探讨了DEPLOY模型在临床实践中的潜在影响,包括对诊断困难病例的分类能力,以及模型预测与实际病理诊断之间的一致性。
-
未来应用:文章最后讨论了DEPLOY模型的未来应用,包括扩展到其他癌症类型的分类系统,并为全球病理学家提供人工智能辅助的“第二意见”。
这项研究展示了深度学习在提高CNS肿瘤诊断准确性方面的潜力,并为未来在资源有限地区提供快速、准确的肿瘤诊断提供了新的思路。
TORCH技术:精准医疗下的肿瘤起源预测工具
![https://doi.org/10.1038/s41571-024-00906-x]](https://i-blog.csdnimg.cn/direct/a0538a06b6614281a3c75709fbc95349.png)
一作&通讯
| 角色 | 姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Elie Rassy | 法国古斯塔夫·鲁西研究所医学肿瘤科 |
| 通讯作者 | Nicholas Pavlidis | 希腊约阿尼纳大学 |
这篇文章是关于使用基于细胞学的深度学习工具来预测未知原发肿瘤(CUP)的起源的研究。
-
背景:大多数未知原发肿瘤患者在接受经验性化疗时预后不佳。精准医疗的治疗策略包括组织不可知或特定部位的方法。
-
研究进展:Tian等人开发了TORCH,这是一种基于细胞学组织学图像的深度学习方法,用于在器官系统级别识别肿瘤起源。这项研究涉及了四种常见的转移至胸腔积液或腹水的器官系统癌症:消化系统、呼吸系统、女性生殖系统和血液或淋巴系统。
-
模型训练与验证:使用来自20,638名已知原发肿瘤类型的12种癌症患者的29,883张图像训练模型,该模型结合了临床数据和细胞学样本的影像分析。模型在内部(12,799个样本)和外部(14,538个样本)数据集上进行了验证,显示出0.953-0.991的癌症诊断曲线下面积(AUC)和0.953-0.979的肿瘤起源定位AUC。
-
模型表现:模型的预测准确性高于病理学家(诊断得分1.677对比1.265;P<0.001),并提高了初级病理学家(平均5年临床经验)的诊断准确性(使用TORCH时62.3%对比不使用时43.3%;P<0.001),使其与高级病理学家(平均16年临床经验)的准确性相当(不使用TORCH时63.3%;P=0.78)。
-
临床意义:在391名CUP患者中,那些初始治疗与预测起源一致的患者(276名)比那些接受不一致治疗的患者(17个月对比27个月;P=0.006)有更长的中位总生存期。
-
技术发展:过去二十年的研究集中在传统的免疫组化和分子分析上。生物技术的进步转向了更少侵入性的方法,如液体活检和放射组学,这些方法提高了识别原发部位的准确性。
-
局限性与挑战:尽管TORCH在识别细胞学是否良性(AUC 0.955)方面表现出色,但它不能识别具体的组织起源,这给临床治疗指导带来了不确定性。
-
未来方向:研究应该集中在准确识别组织起源和指导特定部位治疗的生物标志物上。对于CUP的治疗,精准医疗提供了新的治疗策略,包括基于分子特征的组织不可知治疗方法。
文章强调了基于细胞学的深度学习工具在识别未知原发肿瘤起源中的潜力,并讨论了其在临床实践中的潜在应用和挑战。
癌症研究中的人工智能应用指南

一作&通讯
以下是第一作者和通讯作者以及他们对应的单位的表格:
| 作者姓名 | 单位名称(中文) |
|---|---|
| Raquel Perez-Lopez | 瓦尔德赫布伦巴塞罗那医院校区肿瘤放射组(Radiomics Group) |
| Jakob Nikolas Kather | 德国德累斯顿工业大学数字健康中心(Else Kroener Fresenius Center for Digital Health) |
文章讨论了人工智能(AI)在癌症研究中的应用,并为非计算机专业的癌症研究人员提供了一个实用的指南,以理解AI工具如何帮助他们。文章强调了AI工具在提高日常工作效率和从现有数据中提取隐藏信息方面的潜力,这些工具可以帮助科学发现。
文章概述了深度学习的基本原理,包括监督学习、无监督学习和强化学习,并讨论了神经网络架构,如卷积神经网络(CNNs)和变换器(transformers)。文章还探讨了深度学习在癌症研究中的多种应用,包括生物医学图像分析、自然语言处理和药物发现。
在生物医学图像分析方面,文章讨论了深度学习在病理学图像分析中的应用,包括使用深度学习进行细胞和分子成像分析、组织病理学能力以及计算病理学。文章还提到了AI在放射学中的应用,包括临床放射学和AI在放射学中的关键考虑和方法。
文章还讨论了大型语言模型(LLMs)在自然语言处理(NLP)中的应用,这些模型基于变换器架构,已成为处理任何文本的最新方法。LLMs能够执行多种任务,包括文本重构、摘要、翻译和新文本合成。
最后,文章探讨了AI的新兴用途,包括多模态AI和视觉LLMs,以及AI在药物发现和临床试验优化中的应用。文章强调了AI在癌症研究中的潜力,并指出了实现这一潜力所需的关键挑战,包括数据集成、可解释AI模型的开发、数据共享和模型验证标准的建立,以及AI研究人员、癌症生物学家和临床医生之间的紧密合作。
文章的结论是,AI在癌症研究中的应用面临着挖掘肿瘤学中真实世界数据的潜力的挑战,包括电子健康记录、医学图像、肿瘤样本和血液测试。文章建议癌症研究人员熟悉这些工具,并了解当代AI的潜力和局限性,以便在一个AI工具无处不在的世界中导航。
第三季度
速览
第一篇文章介绍了一个名为CHIEF的新型病理学基础模型,它能够通过分析病理图像来诊断癌症和预测预后,表现出比现有方法更高的准确性和泛化能力。
第二篇文章研究了循环肿瘤DNA(ctDNA)液体活检在预测癌症患者静脉血栓栓塞(VTE)风险中的潜力,并发现其在风险分层上优于传统风险评分模型。
第三篇文章介绍了Virchow,一个用于计算病理学和罕见癌症检测的大规模基础模型,它在泛癌症检测和生物标志物预测方面展现出了卓越的性能和泛化能力。
癌症诊断与预后预测的新工具:CHIEF病理学基础模型

一作&通讯
| 作者角色 | 姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Xiyue Wang | 哈佛医学院生物医学信息学系,波士顿,美国马萨诸塞州 |
| 第一作者 | Junhan Zhao | 斯坦福大学医学院放射肿瘤学系,斯坦福,美国加利福尼亚州 |
| 通讯作者 | Sen Yang | 斯坦福大学 |
| 通讯作者 | Kun-Hsing Yu | 哈佛医学院,波士顿,美国马萨诸塞州 |
这篇文章是关于一种名为Clinical Histopathology Imaging Evaluation Foundation (CHIEF) 的病理学基础模型的研究,该模型用于癌症诊断和预后预测。
CHIEF是一个通用的弱监督机器学习框架,能够从病理图像中提取特征,用于系统的癌症评估。这个模型利用两种互补的预训练方法来提取多样的病理表示:无监督预训练用于识别瓷砖级别的特征,弱监督预训练用于识别整个切片的模式。CHIEF在60,530张涵盖19个解剖部位的全切片图像上进行了开发,通过预训练在44TB的高分辨率病理成像数据集上,提取了对癌细胞检测、肿瘤起源识别、分子档案表征和预后预测有用的微观表示。
在来自24家医院和国际队列的32个独立切片集上的19,491张全切片图像上成功验证了CHIEF,总体上,CHIEF的性能超过了最先进的深度学习方法高达36.1%,显示出它能够解决来自不同人群样本和不同切片准备方法的领域偏移问题。CHIEF为癌症患者的高效数字病理评估提供了一个可泛化的基础。
文章还详细介绍了CHIEF在癌症细胞检测、肿瘤起源识别、基因组档案预测和预后预测等方面的应用,并与其他几种方法进行了比较,展示了CHIEF在这些任务中的优越性能。此外,文章还讨论了CHIEF的模型架构、预训练细节、评估方法以及模型的可解释性。最后,文章讨论了CHIEF的局限性和未来可能的研究方向。
基于ctDNA的机器学习模型改善癌症患者VTE风险预测

一作&通讯
| 角色 | 姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Justin Jee | 纪念斯隆凯特琳癌症中心(Memorial Sloan Kettering Cancer Center) |
| 通讯作者 | Simon Mantha | 纪念斯隆凯特琳癌症中心(Memorial Sloan Kettering Cancer Center) |
研究的主要目的是探讨循环肿瘤DNA(ctDNA)测序(液体活检)在预测癌症患者VTE风险方面的应用。
-
背景:癌症相关的静脉血栓栓塞(VTE)是癌症患者中导致医疗成本、发病率和死亡率的主要原因。目前,识别高风险患者以进行预防性抗凝治疗具有挑战性,并且增加了临床医生的负担。
-
研究设计:研究分析了三个血浆测序队列,包括泛癌种发现队列(4,141名患者),前瞻性验证队列(1,426名患者),以及国际泛化队列(463名晚期非小细胞肺癌患者)。研究发现,ctDNA检测与VTE风险相关,且独立于临床和影像学特征。
-
主要发现:
- ctDNA检测与VTE风险的增加相关。
- 基于液体活检数据的机器学习模型在预测VTE风险方面优于现有的风险评分(如Khorana评分)。
- 在真实世界数据中,如果检测到ctDNA,使用抗凝治疗与较低的VTE率相关;而未检测到ctDNA的患者(ctDNA阴性)并未从抗凝治疗中获益。
-
结论:这些结果为液体活检可能改善VTE风险分层提供了初步证据,除了临床参数外。需要进行干预性、随机的前瞻性研究来确认液体活检在指导癌症患者抗凝治疗中的临床应用。
-
研究意义:这项研究提供了一个基于ctDNA的VTE风险分层系统,可能有助于识别哪些患者会从预防性抗凝治疗中受益,或者可以减少抗凝治疗的需要。
-
局限性:尽管液体活检在临床中越来越被广泛使用,但它们主要用于某些癌症类型的靶向治疗匹配,限制了VTE预测方法的立即普遍适用性。此外,研究的人群代表性不足,需要进一步研究以确定结果的普遍性。
-
未来方向:需要进一步的研究来整合ctDNA、cfDNA浓度、KS、化疗接受情况和疾病部位等变量,以确定最佳的癌症患者VTE风险模型。
文章强调了液体活检在癌症患者VTE风险评估中的潜力,并指出了未来研究的方向。
泛癌症检测突破:Virchow基础模型的临床应用与潜力

一作&通讯
| 角色 | 姓名 | 单位 |
|---|---|---|
| 第一作者 | Eugene Vorontsov | Paige, New York, NY, US. |
| 第一作者 | Alican Bozkurt | Paige, New York, NY, US. |
| 第一作者 | Adam Casson | Paige, New York, NY, US. |
| 第一作者 | George Shaikovski | Paige, New York, NY, US. |
| 第一作者 | Michal Zelechowski | Paige, New York, NY, US. |
| 第一作者 | Kristen Severson | Memorial Sloan Kettering Cancer Center, New York, NY, US. |
| 第一作者 | Eric Zimmermann | Microsoft Research, Cambridge, MA, US. |
| 通讯作者 | Siqi Liu | Paige, New York, NY, US. |
| 通讯作者 | Thomas J. Fuchs | Memorial Sloan Kettering Cancer Center, New York, NY, US. |
Virchow模型通过分析病理组织图像,旨在支持临床决策辅助系统和精准医疗。
该模型不仅能够预测生物标志物和识别细胞,还能进行泛癌症检测,包括九种常见和七种罕见癌症,其在标本级别的检测准确率(以接收者操作特征曲线下面积表示)达到了0.95。
文章强调了基础模型在泛癌症检测中的价值,尤其是在训练数据有限的情况下。Virchow模型在处理罕见癌症变体时,甚至能够超越一些特定组织的临床级模型。研究还展示了Virchow模型在预测生物标志物方面的能力,这可能减少对额外测试的需要,并加快为患者提供治疗决策所需的数据。
此外,文章还讨论了Virchow模型在不同组织类型和机构提交的切片中的泛癌症预测能力,包括罕见组织类型和罕见癌症。研究结果表明,Virchow模型在多种癌症类型和罕见数据上都表现出良好的泛化能力。
最后,文章讨论了Virchow模型的潜在临床影响,包括减少诊断周转时间、开发针对罕见癌症的临床级产品,以及使用常规H&E染色的WSI进行生物标志物预测,以增加筛查率并减少侵入性测试。尽管Virchow模型在性能上取得了显著进展,但文章也指出了其发展的一些局限性和未来改进的方向。
第四季度
速览
第一篇文章通过结合自然语言处理和多模态数据,创建了一个丰富的肿瘤真实世界数据集MSK-CHORD,以提高癌症预后的预测能力。
第二篇文章综述了新兴的策略和技术,用于研究早期癌症的生物学特性,以改善患者生存率。
第三篇文章通过空间转录组学技术研究了肿瘤微区域和亚克隆在不同癌症类型中的结构、遗传变异和与微环境的相互作用,揭示了肿瘤在二维和三维空间中的立体进化特征。
自然语言处理与多模态数据融合:提升癌症预后预测

一作&通讯
| 角色 | 姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Justin Jee | 纪念斯隆凯特琳癌症中心(Memorial Sloan Kettering Cancer Center) |
| 第一作者 | Christopher Fong | 纪念斯隆凯特琳癌症中心(Memorial Sloan Kettering Cancer Center) |
| 第一作者 | Karl Pichotta | 纪念斯隆凯特琳癌症中心(Memorial Sloan Kettering Cancer Center) |
| 第一作者 | Thinh Ngoc Tran | 纪念斯隆凯特琳癌症中心(Memorial Sloan Kettering Cancer Center) |
| 第一作者 | Anisha Luthra | 纪念斯隆凯特琳癌症中心(Memorial Sloan Kettering Cancer Center) |
| 通讯作者 | Nikolaus Schultz | 纪念斯隆凯特琳癌症中心(Memorial Sloan Kettering Cancer Center) |
文献概述
-
研究背景:随着健康记录的数字化和肿瘤DNA测序的普及,研究者有机会以前所未有的丰富度研究癌症结果的决定因素。患者数据通常存储在非结构化文本和孤立的数据集中。
-
MSK-CHORD数据集:研究者结合自然语言处理(NLP)注释和结构化的药物、患者报告的人口统计、肿瘤登记和肿瘤基因组数据,从Memorial Sloan Kettering癌症中心的24,950名患者中生成了一个临床基因组、协调的肿瘤真实世界数据集(MSK-CHORD)。这个数据集包括非小细胞肺癌、乳腺癌、结直肠癌、前列腺癌和胰腺癌的数据,使得研究者能够发现在较小数据集中不明显的临床基因组关系。
-
机器学习模型:利用MSK-CHORD训练的机器学习模型预测总体生存率,发现包含自然语言处理衍生特征(如疾病部位)的模型比仅基于基因组数据或阶段的模型表现更好。
-
放射学报告注释:通过注释705,241份放射学报告,MSK-CHORD还揭示了特定器官部位转移的预测因子,包括SETD2突变与免疫治疗肺腺癌中较低转移潜力之间的关系,这在独立数据集中得到了证实。
-
电子健康记录的普遍性:提供了一个未被充分利用的数据基质,用于转化医学。尽管从自由文本患者访问、放射学、组织病理学和程序笔记中抽象关键元素的传统限制了分析,但自然语言处理(NLP)现在允许自动注释这些特征。
-
研究结果:研究结果表明,结合多个数据流(包括NLP衍生变量)的模型在预测癌症死亡率方面具有优越的区分能力。MSK-CHORD可以作为一个核心数据集,其他许多变量可以被添加到其中进行生存分析。
-
基因组预测转移部位:研究者使用NLP注释了所有705,241份放射学报告中疾病转移部位的存在或缺失,并研究了特定基因的致癌改变与未来器官转移率之间的关联。
-
SETD2与免疫治疗在肺腺癌中的关系:在肺腺癌患者中,SETD2驱动突变与更长的总体生存率相关,并且与较低的中枢神经系统转移率相关。
-
讨论:文章讨论了真实世界数据(RWD)如何帮助科学家和临床医生更好地理解疾病,如癌症。NLP工具可以实时更新,相对于手动整理成本较低。研究还探讨了将神经网络应用于笔记以预测结果的效用。
文章最后强调了MSK-CHORD数据集的重要性,它作为一个公共资源,有助于发现临床基因组关系,并希望它能够推动癌症中真实世界基因型-表型关系的研究。
探索癌症早期发展:模型、技术和生物标志物

一作&通讯
| 作者角色 | 姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Ran Zhou | 四川大学华西医院神经外科、生物治疗与国家重点实验室 |
| 通讯作者 | Yuan Wang | 四川大学华西医院神经外科、生物治疗与国家重点实验室 |
这篇文章是一篇关于早期癌症研究策略的综述文章。
-
早期癌症的检测与干预:早期发现和干预癌症或癌前病变对于提高患者生存率具有重要意义。然而,由于早期临床样本稀缺和缺乏合适的模型,癌症的起始过程和从正常组织到癌前再到癌症的进展过程仍不甚了解。
-
临床样本和模型系统:文章介绍了用于研究早期癌症发展的临床样本和模型系统,如自发性小鼠模型和类器官或干细胞衍生模型,这些模型允许对早期癌症发展进行纵向分析。
-
新兴技术和计算工具:介绍了增强我们对癌症起始和早期进展理解的新兴技术和计算工具,包括直接成像、谱系追踪、单细胞和空间多组学,以及人工智能模型。
-
早期恶性转化级联的全面理解:这些模型和技术有助于更全面地理解早期恶性转化级联,揭示癌症发展的关键驱动因素和早期生物标志物。
-
新的见解转化为早期癌症检测和预防策略:讨论了如何将这些新见解转化为基于机制的早期癌症检测和预防策略。
-
临床样本的理解:对于某些癌症类型,可以在临床环境中对早期疾病阶段或甚至癌前病变进行采样,这些样本对于研究早期癌症非常有价值。
-
单细胞和空间组学:单细胞基因组学、转录组学和空间转录组学的出现极大地提高了揭示癌症发展早期步骤的分子特征的空间分辨率。
-
人工智能模型预测癌症进展:利用临床样本中不断增加的数据,训练人工智能模型来预测早期癌症,即使在没有癌前病变的情况下。
-
临床样本的限制:尽管早期临床样本对早期癌症研究非常有价值,但它们也有重要的局限性,例如许多癌症类型在没有癌前病变的临床证据的情况下被诊断出来。
-
自发性小鼠模型:包括基因工程小鼠模型(GEMMs)和致癌物诱导模型,用于分析整个致癌过程。
-
直接成像:使用荧光或生物发光转基因报告基因的自发性小鼠模型可以在癌症发展的早期阶段进行直接成像。
-
单细胞转录组学:通过单细胞RNA测序(scRNA-seq)可以在单细胞分辨率下直接研究发展出癌前病变的各种自发性小鼠模型。
-
谱系追踪:在临床前癌症模型中,谱系追踪涉及标记和监测细胞及其随后的后代,提供对癌症起始细胞和癌症进化过程中克隆动态的重要见解。
-
精准早期癌症检测和预防:目前,大多数癌症类型尚无法进行早期检测和预防。文章讨论了基于对早期癌症的整合分析,开发创新的精准早期检测和治疗策略的迫切需求。
文章最后总结了,通过提高临床前模型的疾病相关性,可以生成可以在临床环境中验证的假设,并提供更相关的平台来评估早期干预策略。预计随着技术的进步,我们将能够更精确地识别、监测、表征和靶向最终发展为癌症的细胞,从而实现从对抗晚期癌症到预防癌症发生的目标。
三维空间中的肿瘤进化:结构、遗传与微环境

一作&通讯
| 作者类型 | 姓名 | 单位名称 |
|---|---|---|
| 第一作者 | Chia-Kuei Mo | 圣路易斯华盛顿大学医学院 |
| 第一作者 | Jingxian Liu | 圣路易斯华盛顿大学医学院 |
| 通讯作者 | William E. Gillanders | 圣路易斯华盛顿大学医学院 |
| 通讯作者 | Ryan C. Fields | 圣路易斯华盛顿大学医学院 |
| 通讯作者 | Benjamin J. Raphael | 普林斯顿大学 |
| 通讯作者 | Feng Chen | 圣路易斯华盛顿大学医学院 |
| 通讯作者 | Li Ding | 圣路易斯华盛顿大学医学院 |
这篇文章是关于肿瘤进化和微环境相互作用在二维和三维空间中的最新研究。
研究团队通过空间转录组学(ST)技术检查了78个病例中的131个肿瘤切片,涵盖了6种癌症类型,并结合了48个匹配的单核RNA测序样本和22个匹配的CODEX样本。研究定义了“肿瘤微区域”为由基质成分分隔的空间上不同的癌细胞簇,并发现这些微区域在大小和密度上因癌症类型而异,转移样本中观察到最大的微区域。研究进一步将具有共享遗传变异的微区域分组为“空间亚克隆”。
通过分析,研究团队发现具有不同拷贝数变异和突变的空间亚克隆显示出不同的致癌活性。此外,研究还观察到微区域中心的代谢活性增加,以及微区域前沿的抗原呈递增加,同时发现T细胞在微区域内的浸润不同,巨噬细胞主要位于肿瘤边界。通过共注册48个连续的ST切片,重建了3D肿瘤结构,提供了肿瘤的空间组织和异质性的见解。
使用无监督深度学习算法整合ST和CODEX数据,研究识别了免疫热点和冷点区域,并在3D亚克隆周围增强了免疫耗竭标记。这些发现有助于理解肿瘤通过与局部微环境的相互作用在二维和三维空间中的立体进化,为肿瘤生物学提供了宝贵的见解。
文章还讨论了治疗抵抗亚克隆在癌症中的产生,以及肿瘤微环境(TME)如何通过多种机制推动抗性。
研究指出,传统的bulk和单细胞技术无法保留理解这些动态所需的空间信息,但ST技术可以解析肿瘤亚结构。研究还探讨了克隆进化问题,即肿瘤对环境和治疗刺激的空间和时间适应。
研究结果表明,通过应用多种技术到大型、跨癌症队列中,可以更深入地研究这些现象。研究综合了ST、CODEX和bulk测序数据以及匹配样本的单细胞测序数据,对空间上不同的肿瘤区域进行了分析,这些区域被基质成分分隔,称为“肿瘤微区域”。
研究显示,这些微区域内存在具有特定拷贝数变异和在致癌途径中差异活性的遗传克隆,特别是在MYC途径中。研究还强调了原发性和转移性肿瘤之间的不同特征,包括肿瘤生长模式和转录组轮廓的差异。通过CODEX和多模态3D重建工具,研究进一步支持了TME中特定空间肿瘤区域周围的免疫群体的存在,这些重建突出了肿瘤-免疫界面生态位和相互作用。
总体而言,这种空间组学方法为理解克隆进化和微区域差异提供了更深入的见解,为癌症治疗抗性的机制理解铺平了道路。


















 1065
1065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









