






学习目标:3d目标检测结果可视化
服务器不能可视化结果,于是决定在服务器上跑完之后在本地可视化
学习内容:
我的模型用的是mm3d框架,数据集是KITTI的
mmdet3d中文手册:https://mmdetection3d.readthedocs.io/zh-cn/latest/
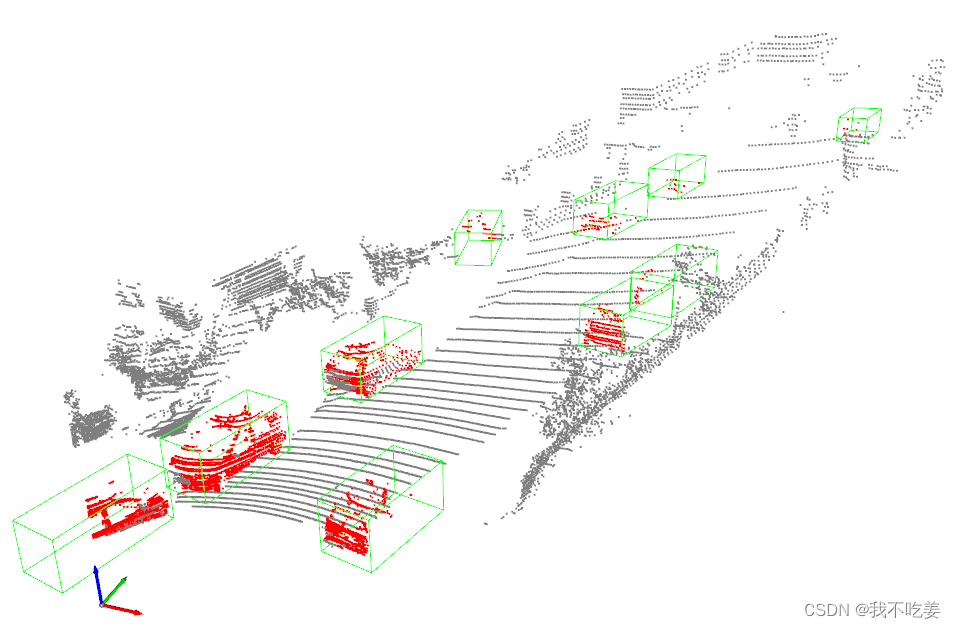
点云可视化代码:
import numpy as np
import mayavi.mlab
kitti_file = './velodyne_reduced/000008.bin'
pointcloud = np.fromfile(file=kitti_file, dtype=np.float32, count=-1).reshape([-1, 4])
x = pointcloud[:, 0] # x position of point
y = pointcloud[:, 1] # y position of point
z = pointcloud[:, 2] # z position of point
# r = pointcloud[:, 3] # reflectance value of point
d = np.sqrt(x ** 2 + y ** 2) # Map Distance from sensor
vals = 'height'
if vals == "height":
col = z
else:
col = d
# col = np.zeros_like(x) # 所有点的颜色都设置为黑色
fig = mayavi.mlab.figure(bgcolor=(0, 0, 0), size=(640, 500))
mayavi.mlab.points3d(x, y, z,
col, # Values used for Color
mode="point",
colormap='spectral', # 'bone', 'copper', 'gnuplot'
scale_factor=1,
figure=fig,
)
x = np.linspace(5, 5, 50)
y = np.linspace(0, 0, 50)
z = np.linspace(0, 5, 50)
mayavi.mlab.xlabel('X')
mayavi.mlab.ylabel('Y')
mayavi.mlab.zlabel('Z')
mayavi.mlab.plot3d(x, y, z) # 可视化xyz坐标轴
mayavi.mlab.show()

点云可视化结果
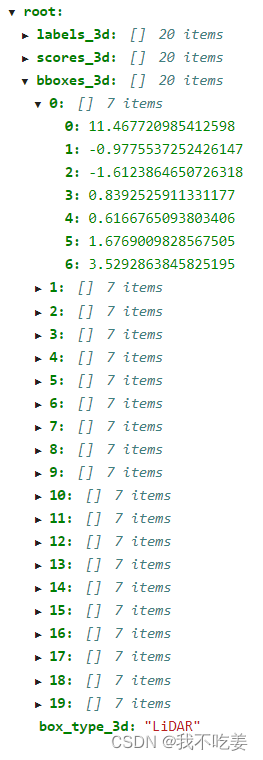
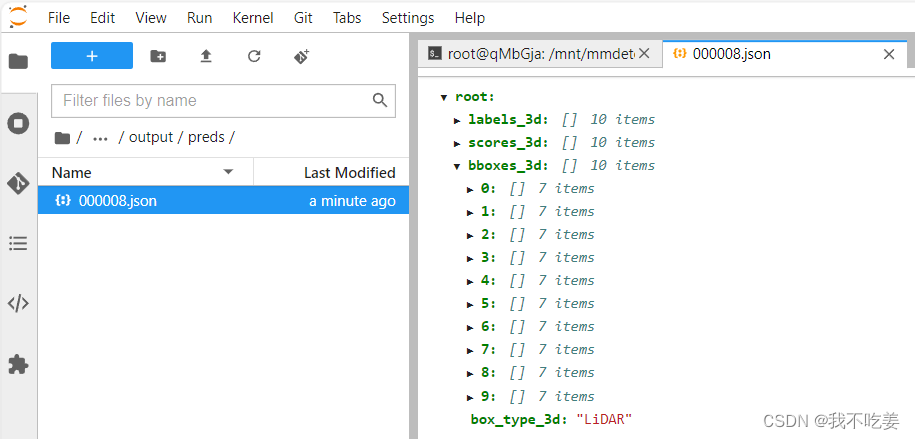
服务器中检测结果保存为json文件,labels是分类,scores是置信度,bboxes是三维框的坐标。
坐标内容为[x,y,z,dx,dy,dz,heading]
xyz是底部中心点,dxdydz是长宽高,heading是朝向
这张图是deom里的推理结果
官方给的检测结果可视化代码:
import torch
import numpy as np
from mmdet3d.visualization import Det3DLocalVisualizer
from mmdet3d.structures import LiDARInstance3DBoxes
points = np.fromfile('demo/data/kitti/000008.bin', dtype=np.float32)
points = points.reshape(-1, 4)
visualizer = Det3DLocalVisualizer()
# set point cloud in visualizer
visualizer.set_points(points)
bboxes_3d = LiDARInstance3DBoxes(
torch.tensor([[8.7314, -1.8559, -1.5997, 4.2000, 3.4800, 1.8900,
-1.5808]]))
# Draw 3D bboxes
visualizer.draw_bboxes_3d(bboxes_3d)
visualizer.show()
我随便试了一下
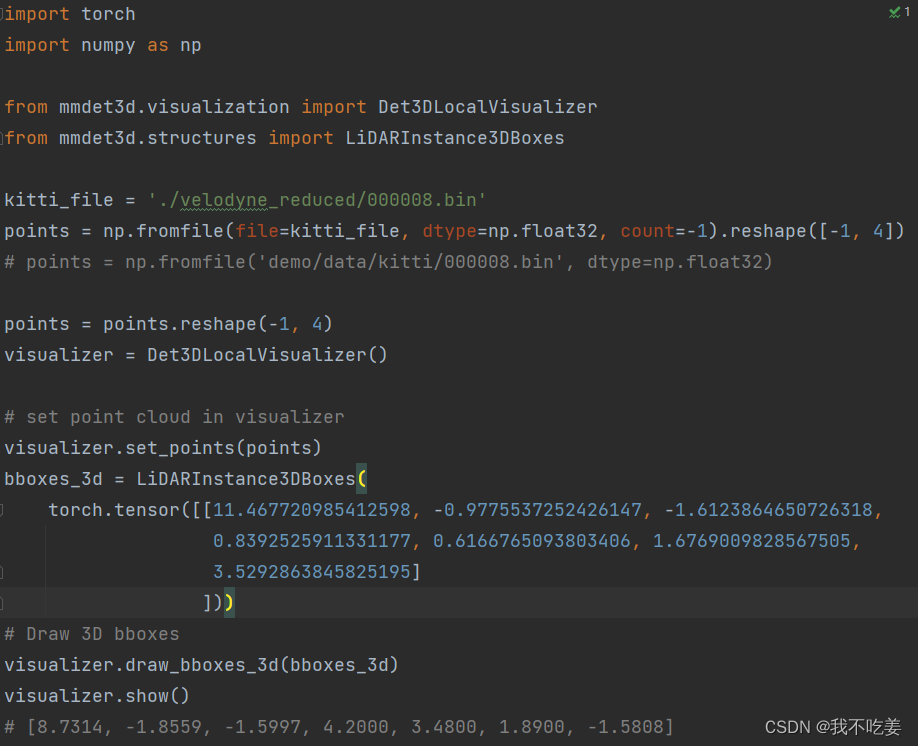

能跑,能显示,但是一个一个框敲上去能把人累死
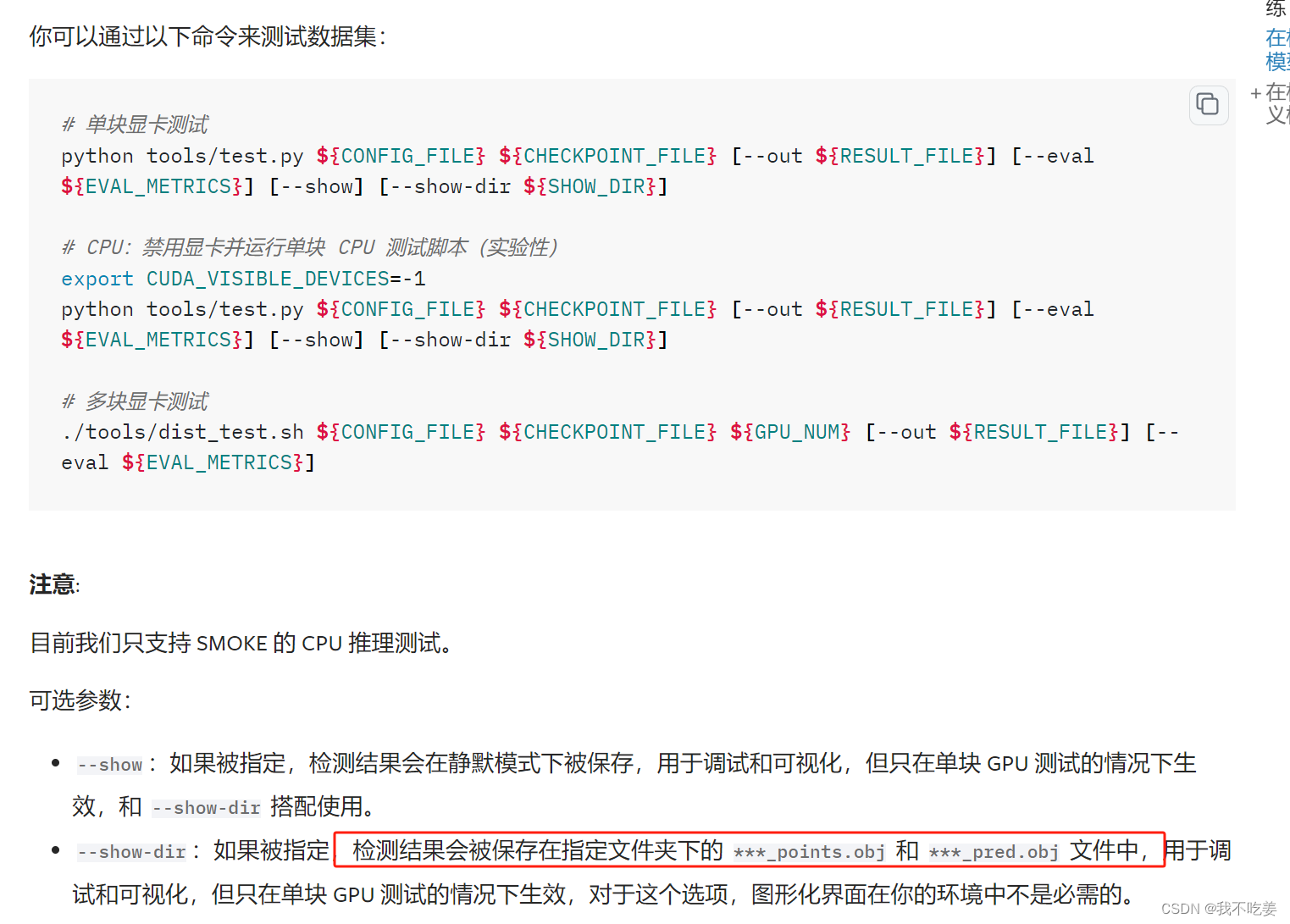
想试试批量化显示,在手册里找到了这个指令:
python tools/test.py ${CONFIG_FILE} ${CKPT_PATH} --show --show-dir ${SHOW_DIR}
介绍是这个:

但是在服务器上会报错:
Traceback (most recent call last):
File "tools/test.py", line 149, in <module>
main()
File "tools/test.py", line 145, in main
runner.test()
File "/root/miniconda3/envs/myconda/lib/python3.8/site-packages/mmengine/runner/runner.py", line 1823, in test
metrics = self.test_loop.run() # type: ignore
File "/root/miniconda3/envs/myconda/lib/python3.8/site-packages/mmengine/runner/loops.py", line 435, in run
self.run_iter(idx, data_batch)
File "/root/miniconda3/envs/myconda/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/root/miniconda3/envs/myconda/lib/python3.8/site-packages/mmengine/runner/loops.py", line 456, in run_iter
self.runner.call_hook(
File "/root/miniconda3/envs/myconda/lib/python3.8/site-packages/mmengine/runner/runner.py", line 1839, in call_hook
getattr(hook, fn_name)(self, **kwargs)
File "/root/miniconda3/envs/myconda/lib/python3.8/site-packages/mmdet3d/engine/hooks/visualization_hook.py", line 228, in after_test_iter
self._visualizer.add_datasample(
File "/root/miniconda3/envs/myconda/lib/python3.8/site-packages/mmengine/dist/utils.py", line 418, in wrapper
return func(*args, **kwargs)
File "/root/miniconda3/envs/myconda/lib/python3.8/site-packages/mmdet3d/visualization/local_visualizer.py", line 1082, in add_datasample
self.show(
File "/root/miniconda3/envs/myconda/lib/python3.8/site-packages/mmengine/dist/utils.py", line 418, in wrapper
return func(*args, **kwargs)
File "/root/miniconda3/envs/myconda/lib/python3.8/site-packages/mmdet3d/visualization/local_visualizer.py", line 868, in show
self.view_control.convert_to_pinhole_camera_parameters() # noqa: E501
AttributeError: 'Det3DLocalVisualizer' object has no attribute 'view_control'
这个是因为服务器没有gui界面,所以无法可视化,但是把–show删了能保存下来在图像上的3d框。
使用:
python tools/test.py configs/mvxnet/mvxnet_fpn_dv_second_secfpn_8xb2-80e_kitti-3d-3class.py work_dirs/mvxnet-pseudo/epoch_60.pth --work-dir result/save --show-dir result/show_result --task 'multi-modality_det'
过程:(open3d警告不影响)
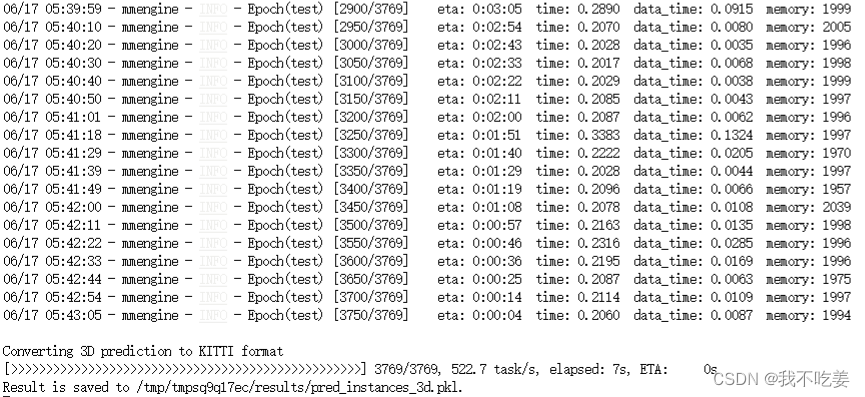
所有测试的图片结果都被保存下来了:
保存下来的结果图是这样的:

保存的结果是:

但是根本没有***_points.obj 和 ***_pred.obj 文件,test.py里也没有–out {RESULT_FILE}选项。
而且我想要的是检测结果在点云上的可视乎,而不是在图像上的,无奈了。
所以准备用第二种离线可视乎的方法。
使用 Open3D 后端离线可视化结果,你可以运行如下指令:
python tools/misc/visualize_results.py ${CONFIG_FILE} --result ${RESULTS_PATH} --show-dir ${SHOW_DIR}
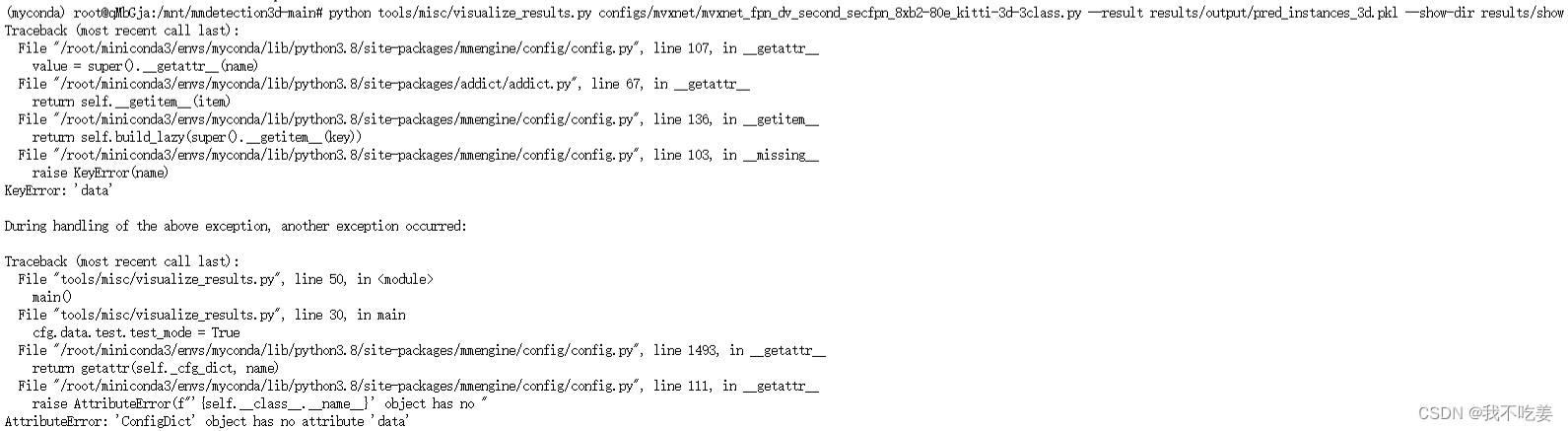
不过我当时就在疑惑,为啥只要CONFIG_FILE,不要CKPT_PATH呢,然后跑了一下发现问题了
(myconda) root@qMbGja:/mnt/mmdetection3d-main# python tools/misc/visualize_results.py configs/mvxnet/mvxnet_fpn_dv_second_secfpn_8xb2-80e_kitti-3d-3class.py --result result/output/ --show-dir result/output/show
Traceback (most recent call last):
File "tools/misc/visualize_results.py", line 50, in <module>
main()
File "tools/misc/visualize_results.py", line 27, in main
raise ValueError('The results file must be a pkl file.')
ValueError: The results file must be a pkl file.
这里缺少了pkl文件。
在上面的介绍里提到了:你可以从远程服务器中下载 results.pkl,并在本地机器上离线可视化预测结果。
然后我就去找这个results.pkl应该在哪啊,我记得好像之前在哪见过,最后在test.py的时候找到了这句话:
但是我根据这个目录找不到这个pkl文件
不过在手册里找到了这个

我靠,如果不指定的话,结果是不会保存的,不保存提醒我干嘛!气死了!
于是又测试了一遍:
python tools/test.py configs/mvxnet/mvxnet_fpn_dv_second_secfpn_8xb2-80e_kitti-3d-3class.py work_dirs/mvxnet-pseudo/epoch_60.pth --cfg-options 'test_evaluator.pklfile_prefix=results/output' 'submission_prefix=results/output'
果然找到了:

这回再试试可视化
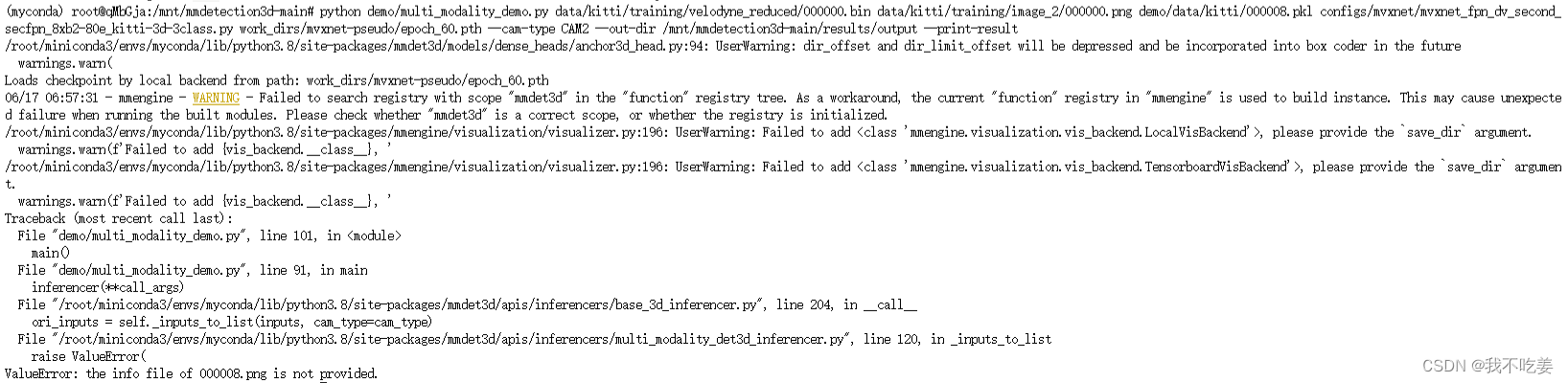
结果还是不行,报错:
故,放弃
最后,还是决定用推理,一个一个推
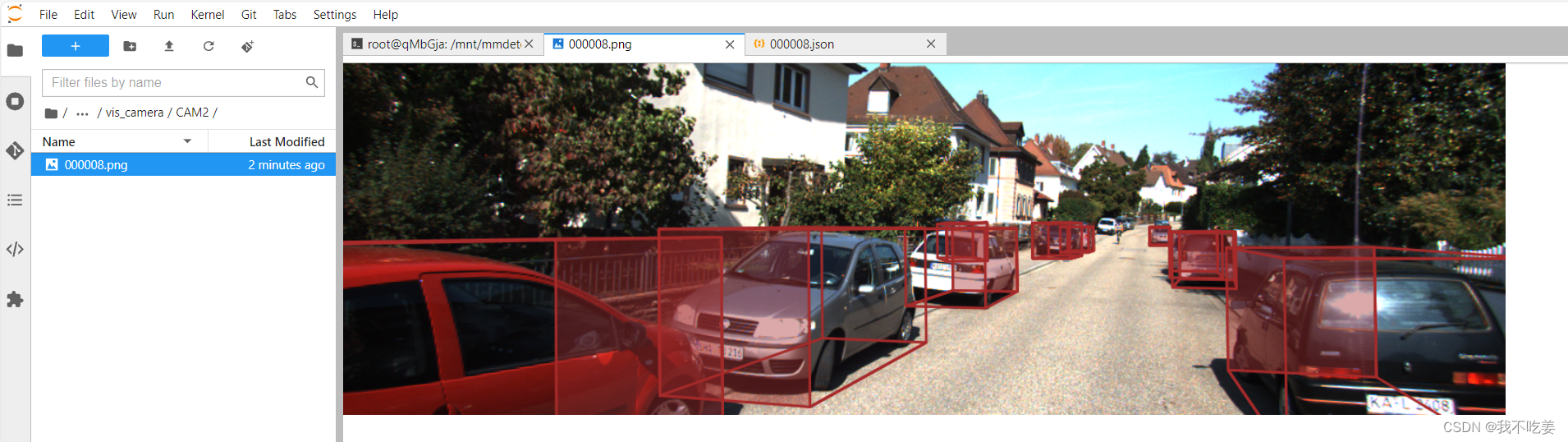
python demo/multi_modality_demo.py data/kitti/training/velodyne_reduced/000008.bin data/kitti/training/image_2/000008.png demo/data/kitti/000008.pkl configs/mvxnet/mvxnet_fpn_dv_second_secfpn_8xb2-80e_kitti-3d-3class.py work_dirs/mvxnet-pseudo/epoch_60.pth --cam-type CAM2 --out-dir /mnt/mmdetection3d-main/results/output --print-result
(那个pkl是通用的,但是里面把000008这个文件名写死了,文件是通过pkl去找图片和点云的。想推理其他图片和点云的话,把要推理的文件改成000008这个名字就行,位置无所谓,不改名字会报错)
正确结果:

最终代码:(需要点云文件和推理出来的json文件)
import torch
import numpy as np
from mmdet3d.visualization import Det3DLocalVisualizer
from mmdet3d.structures import LiDARInstance3DBoxes
import json
kitti_file = './velodyne_reduced/000008.bin'
json_file = '000008.json'
points = np.fromfile(file=kitti_file, dtype=np.float32, count=-1).reshape([-1, 4])
# points = np.fromfile('demo/data/kitti/000008.bin', dtype=np.float32)
with open(json_file, 'r', encoding='utf-8') as file:
# 使用json.load()方法解析JSON数据
data = json.load(file)
bboxes = data['bboxes_3d']
points = points.reshape(-1, 4)
visualizer = Det3DLocalVisualizer()
# set point cloud in visualizer
visualizer.set_points(points)
bboxes_3d = LiDARInstance3DBoxes(torch.tensor(bboxes))
# Draw 3D bboxes
visualizer.draw_bboxes_3d(bboxes_3d)
visualizer.show()


















 8442
8442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









