







论文:Corrective Retrieval Augmented Generation
⭐⭐⭐⭐
Code: github.com/HuskyInSalt/CRAG
arxiv:2401.15884
文章目录
论文速读
CRAG(Corrective RAG)相比于以往的 RAG,增加了一个用于矫正检索到的文档和 user query 之间知识相关性的模块。
CARG 的整个架构以及 inference 运行流程如下:
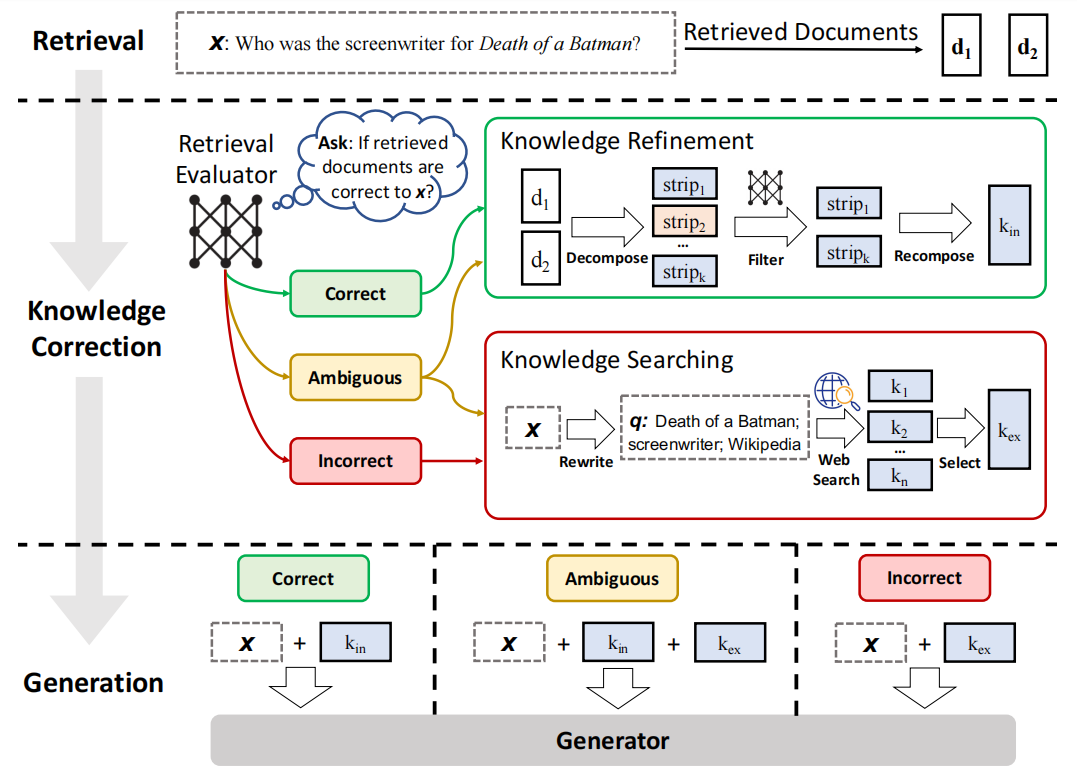
- Retrieval 阶段:retriever 先根据 user query 检索到相关的 docs
- Knowledge Correction 阶段:这里引入了一个轻量级的 Retrieval Evaluator 来评估检索到的 docs 与 user query 之间的相关性分数,并根据这个相关性分数,触发三种 action —— Correct、Incorrect 和 Ambiguous:
- Correct:表示检索到的 doc 是有一定相关性的,但尽管一个 doc 被认为是相关的,该 doc 其中仍会存在噪音信息,因此需要进一步地 refine,所以这里将 docs 做 de-compose 得到多个 knowledge strips,然后从中过滤出有用的 strip 并 re-compose,得到矫正后的 doc。
- Incorrect:表示可以认为说检索到的 docs 对 query 没有帮助,因此需要寻找新的知识源,这里引入 web searcher 来从 Internet 上进行检索,并从中选出有用的知识,得到矫正后的 doc。
- Ambiguous:表示 retrieval evaluator 也没有信心说 docs 是否与 query 有关了,这个时候会同时做 Correct 和 Incorrect 时的动作,从而提高系统的鲁棒性和可靠性。
- Generation 阶段:将矫正后的 doc 与 user query 进行拼接,交给 LLM Generator 来完成问题的回答。
实现细节
1. Retrieval Evaluator 模块
论文这里使用了微调后的 T5-Large 来作为 retrieval evaluator,从代码上来看,应该就是直接使用 “T5 For Sequence Classification” 来实现的,并根据其输出得到一个 relevance score,并进而根据这个 score 来决定接下来触发的 action。
如何根据 score 来决定接下来触发哪个 action 呢?原论文是设置了 upper threshold 和 lower threshold,并根据这两个指标来判断。不同的场景下设置的 threshold 也不同。
2. Knowledge Refinement
当检索到 docs,CRAG 会对该 docs 做进一步的 refinement:
- 对于 Internal Knowledge:先根据固定的大小将一个 doc 分成多个 strip,然后再使用 evaluator 进一步过滤,选出其中相关的 strips
- 对于 External Knowledge:使用 Google Search API 来检索相关 URL,并优先选取 Wikipedia 的 pages。web page 往往是 HTML 文件的形式,这里根据特殊 HTML 标签,如
<p>和</p>,解析出 web page 的内容,然后使用 evaluator 选出有用的段落。
实验
论文做了很多实验,还是挺有价值的。如下是实验结果:
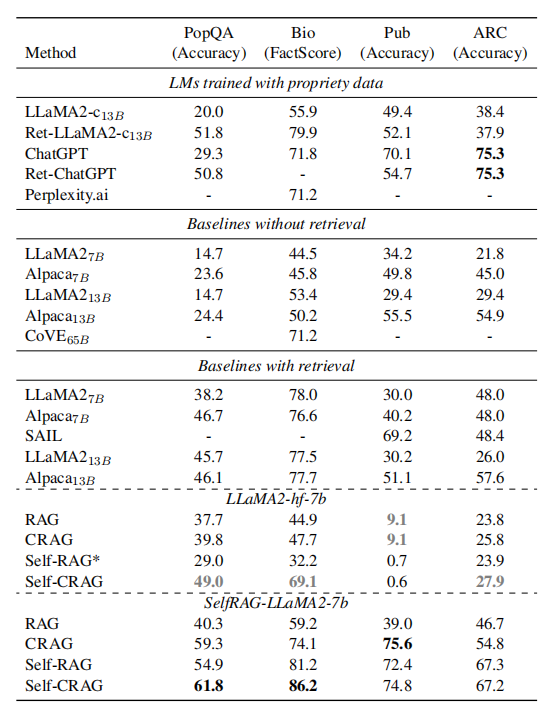
上面的 Self-CRAG 表示将本论文提出的 CRAG 框架适配到 Self-RAG 模型上的结果。
可以看到,CRAG 确实带来了不少的效果提升,而且在多个跨领域的数据集上进行了测试,体现了 CRAG 跨领域的泛用性。
此外,正如原论文多次提到的,CRAG 是一个 plug-and-play 的方法,在实验中也可以看到,无论将 CRAG 的方法插入到以往的 RAG 还是插入到 Self-RAG 中,模型的效果都会有提升。
CRAG 相比于 Self-RAG 的一个更加明显的优势是:CRAG 对于底层的 LLM 的选用非常灵活。Self-RAG 使用的是人类指令微调后的 LLM,而 CRAG 则不需要对原生 LLM 进行微调,这样 CRAG 就可以快速用上当前最先进的 LLM 模型。
消融实验
论文做了多个消融实验,总结如下:
- triggered action 的影响:论文发现,无论去掉哪个可触发的 action,都会让模型的表现变差,证明了这里每一个 action 都是有作用的
- 每个 knowledge utilization operation 的影响:CRAG 做了很多对已检索到的 doc 做进一步 knowledge refinement 的操作,实验也证实了每一种利用知识的操作都是有用的。
关于 Retrieval Evaluator
论文提到,retrieval evaluator 的质量显著决定了整个系统的表现。
下面是使用不同 evaluator 的效果:

可以看到,使用不同的 evaluator 可以明显影响 accuracy。并且基于 T5 会明显好于基于 ChatGPT。
关于 Retrieval 的鲁棒性
论文做了一下实验,如果故意随机删除一部分检索到的准确文档,会怎样影响整个系统。下图展示了,随着了 retrieval 的性能的降低,generation 的性能也随之降低:
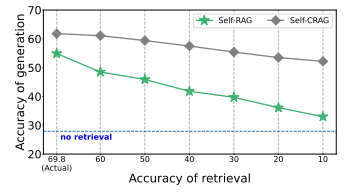
这表明:生成器的效果在很大程度上依赖于检索器的质量。
总结
CRAG 被提出用于提高 generation 的鲁棒性。特别是:
- 借助一个轻量级的 retrieval evaluator 来有区分地做知识检索
- 利用 web search 和对知识地利用,提高了对检索到地文档地自我修正和更有效率地知识利用。这个发现也说明了,对已有知识做 refinement 是一件很重要的事情。
多个实验也表明了,CRAG 具备跨领域跨任务的通用性,在短文本和长文本生成任务上都有着不错的表现。另外,CRAG 是 plug-and-play 的,即插即用,可以与现有的 RAG 方法进行融合,并且可以利用上当前最先进的 LLM 模型。
参考文章:

















 731
731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









