







 论文介绍了一种改进RAG模型的方法,通过在查询输入retriever前添加queryrewrite步骤,使用不可训练的LLM或可训练的LM。实验表明这种方法能提高效果。然而,研究仍面临下游任务的泛化与专业化的权衡以及训练效率的问题。
论文介绍了一种改进RAG模型的方法,通过在查询输入retriever前添加queryrewrite步骤,使用不可训练的LLM或可训练的LM。实验表明这种方法能提高效果。然而,研究仍面临下游任务的泛化与专业化的权衡以及训练效率的问题。
论文:Query Rewriting in Retrieval-Augmented Large Language Models
⭐⭐⭐⭐
EMNLP 2023
Code: github.com/xbmxb/RAG-query-rewriting
一、论文速读
如下是一个常见的 RAG pipeline:
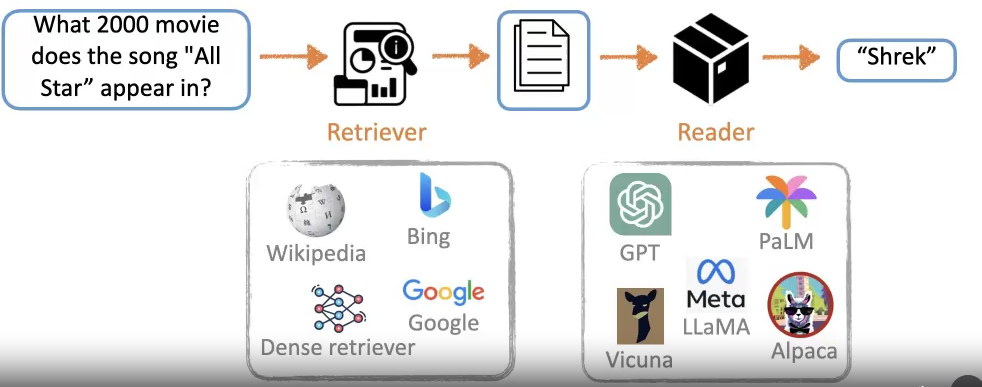
但这存在一个缺点:input text 和需要 query 的 knowledge 之间不可避免地会存在一个 gap。
本文提出:在将 query 输入给 retriever 之前,增加一个 query rewrite 步骤来弥补这个 gap:

这样,就把之前 RAG 的 retrieve-then-read 改为了 Rewrite-Retrieve-Read 的框架。
同时&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









