






文章已发布于 B 乎。 如果再给我干成 V I P 文章,移步。
S B 系统直接未经允许默认把文章干成 V I P 文章
起因
事情的起因是这样的:有一个我关注的游戏(( ̄︶ ̄)↗日文黄油)发布了,在发布之前我一直以为是RPGmaker的,结果发布了下载下来才发现是UNITY引擎的。众所周知,翻译分为三步:提取文本,翻译文本,打包文本,而UNITY引擎的文本提取和打包难度极高,翻译难度难如登天。更尴尬的是,ai2moe倒了,连带着论坛上成堆的精品汉化教学贴也消失了。自己翻译只能一步一步的摸索。在经过把游戏的资源翻了一遍,调教AI帮忙写了一堆的代码之后,终于完成了翻译。
这个游戏使用的是mono,代表是游戏文件夹内有着MonoBleedingEdge文件夹。并且游戏的文件没有加密。如果游戏使用的是il2cpp,或者游戏的资产经过了加密,该记录不适用,请自行寻找对应的教程或者在参考下面的参考资料。
在文章开始之前,先放几个参考资料在这。本文可能会写成散文,不适合当教程,于是把参考资料放在这,可以先去试一试,不成再回来找解决方法。
- GitHub - mskgroup/Unity-Game-localization-tutorial-and-toolkit
- Unity引擎游戏汉化教程实录_哔哩哔哩_bilibili
- 【图片】【技术向】游戏本体字体替换与文本替换【时之书吧】_百度贴吧
- ilasm 和 ildasm编译和反编译工具介绍使用教程-CSDN博客
AI翻译文本
其实AI翻译文本这一步是最简单的。感谢AINiee,让AI翻译变得如此简单。
GitHub - NEKOparapa/AiNiee: 一款专注于Ai翻译的工具,可以用来一键自动翻译RPG SLG游戏,Epub TXT小说,Srt Lrc字幕等s
我采用的是Autodl部署SakuraLLM,教程可以看AiNiee和SakuraLLM的readme.md,里面很详细。
AiNiee最新版本的优化也可以作用在Autodl部署的模型上,但是稳定性较差,我尝试的时候有很多次线程报错502,云端进程卡住。但是也有几次优化成功,翻译速度大约为原来的两倍(4090),主要是多线程能够充分利用显卡,让显卡的占用率一直保持在0.75左右的高位,不会出现之前单线程的干五秒休息一秒的情况。
具体的优化步骤为:autodl的LLM版本选择0.9.3(sakura-14b-qwen2beta-v0.9.2-iq4xs),修改run文件的运行模型的代码为
llama.cpp/server -m ${MODEL}.gguf -cb -np 4 -c 10240 -ngl 999 -a ${MODEL} --port 6006但是还是有几率报错,需要自己调试。另外-c的代码会随着显存大小不同而不同,这个是对应24g显存的显卡(3090和4090),其他显卡需要自己根据脚本修改参数。
提取asset文件(level文件)内的文本
其实这两个教程的第一步都是让我去解包Assembly-CSharp.dll,但是我第一遍其实没有找到Assembly-CSharp里面的文本,于是直接跳到了提取level文件里面的文本了。使用到的工具主要是UABEA,AssetStudio,SExtractor。
- GitHub - aopkcn/UABEA-Chinese: c# Unity资产编辑器中文版
- https://github.com/Perfare/AssetStudio
- https://github.com/satan53x/SExtractor
主要参考的是[Unity3D-游戏汉化教程]第3期:MonoBehaviour_哔哩哔哩_bilibili视频。
首先需要找到文本数据到底存储在哪。这个部分建议使用AssetStudio,因为它的筛选和预览都相对更加成熟。在AssetStudio中,在File导入游戏的data文件夹即可看到游戏的所有资产。游戏的文本就在这些资产当中。游戏的文本可能会出现在TextAsset,MonoBehaviour和Texture2D这三个中,最后一个大多为图片数据,不好翻译,于是我只考虑前两个。资产类型可以使用Filter Type筛选。并且在这个游戏的资产中,相同作用的资产一般名称都极为相似,因此可以根据首字母排序,找到对应的文本存储的变量名称。比如我翻译的里面,文本就存储在类型为MonoBehaviour的TextMeshProUGUI,NPC_Conversation和CubismDisplayInfoPartName里面。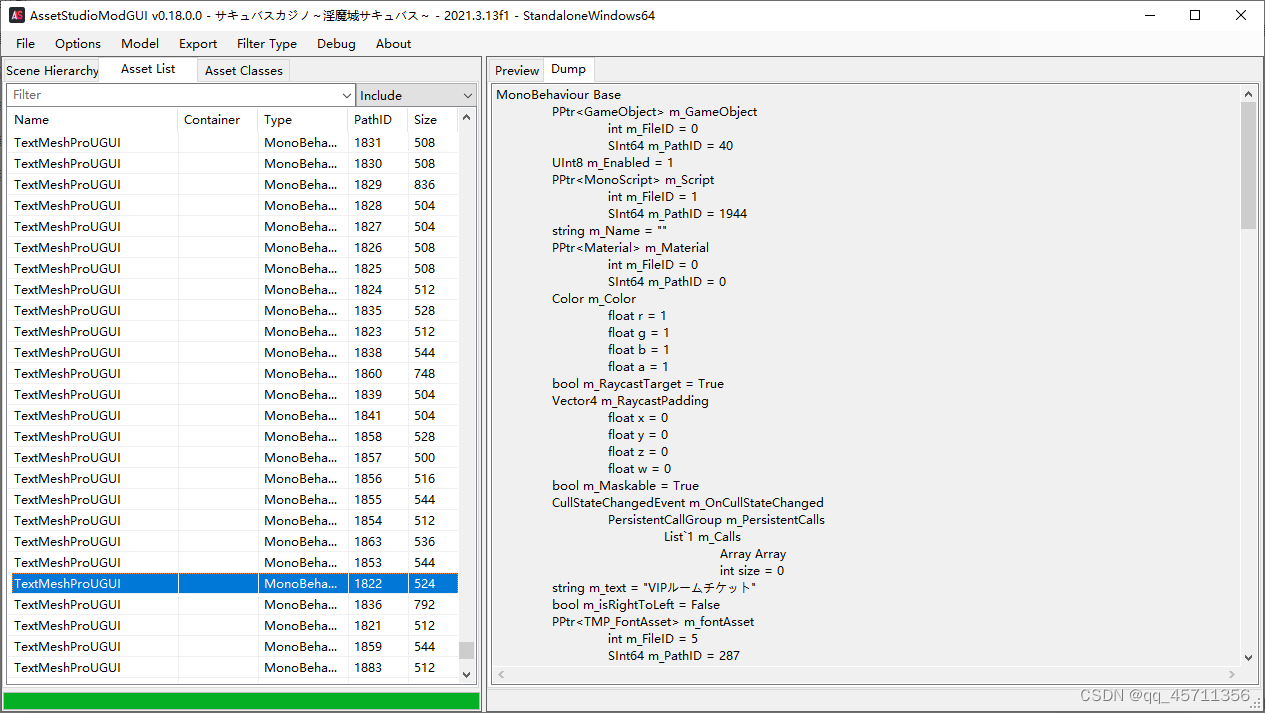
在找到对应的资产名称之后,就可以使用UABEA导出了。打开UABEA,选中data文件夹内所有的asset文件和level文件,拖动到UABEA上,就可以打开所有的资源文件了。之后找到所有的文本资产,选择导出Dump,导出成TXT格式的代码,之后就可以进行翻译了。
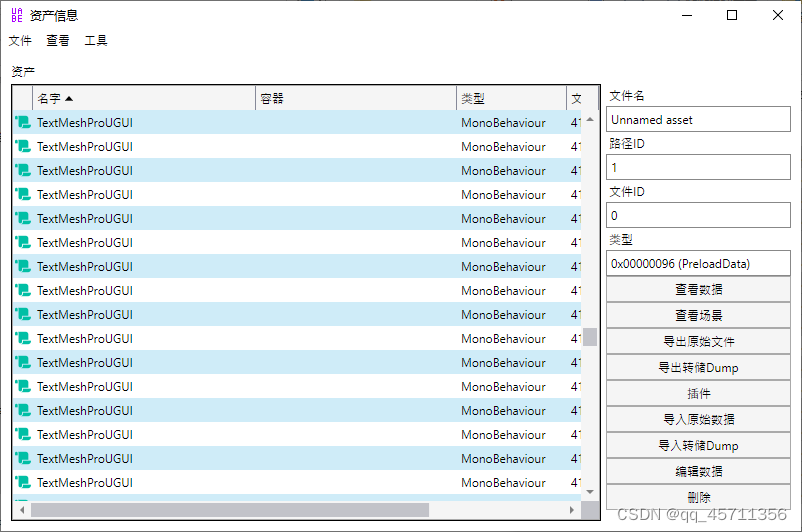
翻译导出文本可以使用SExtractor,选择引擎为TXT,导出为json,单文本,设置好导出的dump的目录,设定好正则表达式,就可以导出了。我使用的正则表达式是下面的,似乎是匹配括号内的存在非ASCII字符的字符串。也可以使用其他的正则表达式。最后会导出transDic.output.json。之后就可以使用AiNiee,选择MTool导出文件模式翻译这个文件了。
22_search="((?:[^\x00-\x7F]|\\")*)"
writeOffset=1翻译好了之后将翻译完成的文件重命名为transDic.json,将其和transDic.output.json放在一起,使用SExtractor就可以导出翻译好的TXT文件了,此时transDic.output.json的值也会变成翻译好的transDic.json的值。
最后使用UABEA导入。打开UABEA,选中data文件夹内所有的asset文件和level文件,拖动到UABEA上,就可以打开所有的资源文件了。之后选中所有的文本资产,选择导入Dump,选择翻译好的txt文件所在文件夹,就可以导入了。这一步会耗时很长时间,UABEA可能会卡死,需要耐心等待。如果嫌弃UABEA导入慢,可以一次选择一个文件导入翻译文件,虽然麻烦但是不会长时间卡死。最后在UABEA内选择保存或者另存为就可以了。
由于会翻译部分的非中文代码,这样导出的翻译文件会导致程序不稳定,如果程游戏出现闪退或者卡死,需要逐一翻译排查文件是否导致报错。
提取assemblyCsharp.dll内的文本
在完成asset文件的翻译,排查导致卡死的文件之后,我进入游戏,发现只翻译完成了场景对话,却没有翻译事件对话。于是我开始排查其他文件,终于在Assembly-CSharp.dll里面发现了事件对话文本。之后我通过dnSpy解包之后再编译,最后因为变量名出错以及2000+个UnityEngine.Object和System.object混淆的报错知难而退,选择死磕IL代码中的hex编码字符串。
dnSpy解包(失败尝试)
虽然dnSpy解包之后再编译会报错,但是dnSpy能够很方便的查看文件里是否有文本数据。具体方法是打开dnspy,导入assemblyCsharp.dll,在{}类中挨个寻找是否有文本数据。
dnspy的解包方法参考参考资料,上面讲的很详细。导出文本可以通过调教AI帮忙写python代码,我。但是,在翻译之前记得先编译,看看能否成功编译成DLL,不然翻译完了之后还得进行编码保存之后才能用在IL代码上
导出IL代码并搜索
导出IL代码以及编译成DLL可以参考参考资料的教程,可以在翻译之前看一下能否正确编译IL文件,因为翻译只会修改IL文件里面的字符串变量。重点是如何从IL代码内导入和导出文本。
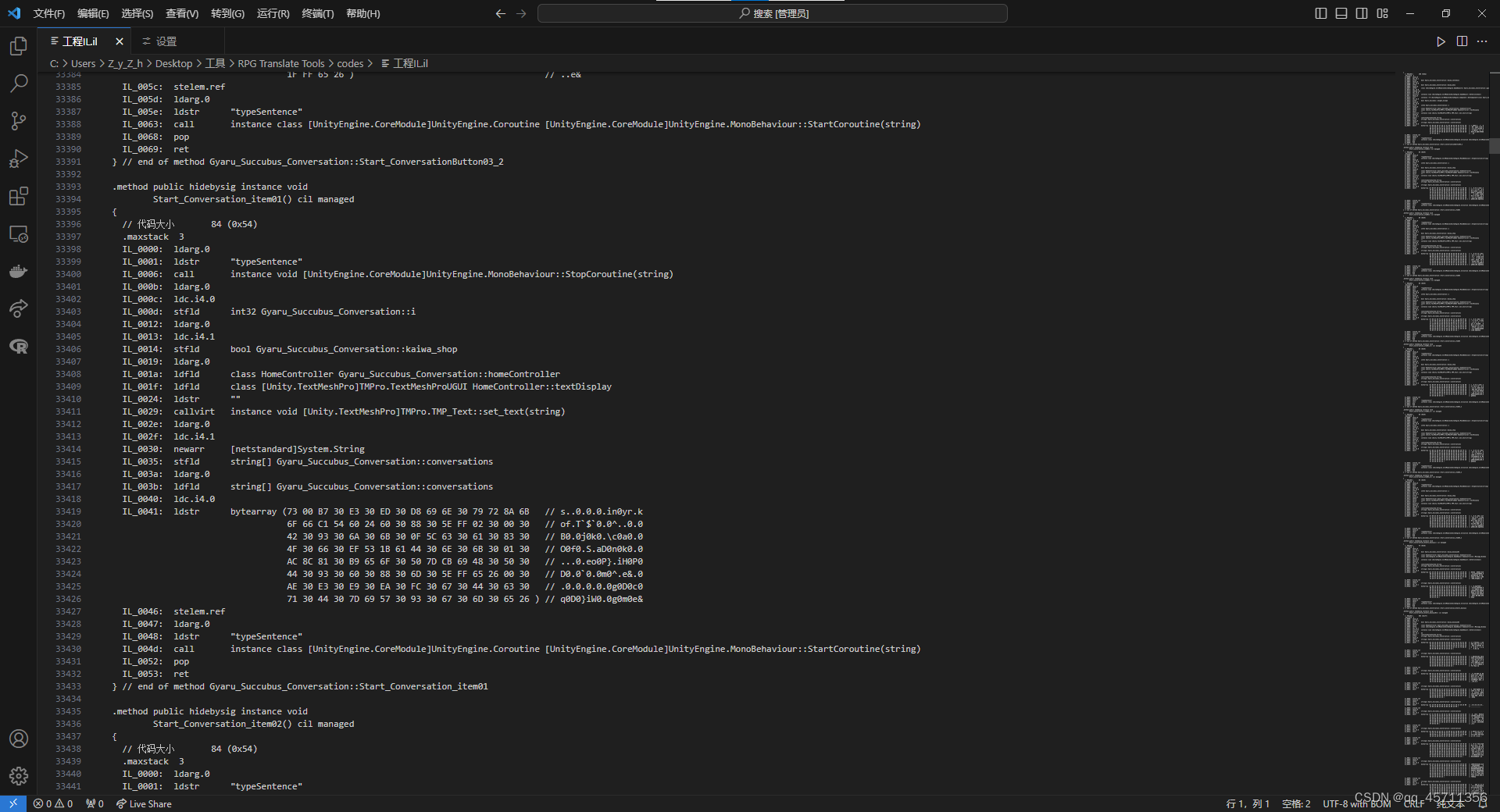
在IL代码内,字符串是通过bytearray保存的,bytearray为字符串经过utf-16le编码之后保存为16进制数字得来的,因此需要写程序进行查询,导出以及替换。
注意到conversations的bytearray都符合以下格式: IL...::conversations\n...IL...ldc...\n...IL...: ldstr bytearray ( 含注释的字符串 ) ...\n...IL ,也即::conversations后接换行符,后接一行含ldc的IL代码,后接ldstr bytearray 。且反括号下一行为IL代码,其中含IL字符串。我们可以以此构建re正则表达式,匹配conversations内的含注释的字符串,且不受注释内部的反括号的干扰。
在得到字符串之后,可以使用spilt操作,通过注释的标识//,将注释删除,再将字符串转化为bytes变量进行解码,导出原文进行翻译。
在翻译完了之后进行替换时,由于有括号标识数组范围,并且不用注释,替换时可以放飞自我。最后就可以编译dll了。
更改字体
在完成以上的翻译步骤的时候,游戏已经完成了80%的翻译,剩下的我实在不想找了。但是进入游戏之后却发现字体出错,出现了中文变成方块以及中文显示出错的情况,需要修改字体。这个游戏使用的是TMP字体,因为我在AssetStudio里面找到了一堆含有SDF的资产。其他游戏需要判断是哪种字体。
修改字体的操作参考参考资料的贴吧,上面比我的详细多了。下面就只提一下注意事项和踩的坑。
查询unity版本可以使用AssetStudio,也可以随便使用文本编辑器打开一个level文件,开头能显示的就是使用的unity版本。
找SDF文件的时候可以使用AssetStudio,找较大的Texture2D图片,一般日文游戏的字体的Texture2D图片上都写满了日文和繁体汉字。字体需要使用能够显示全部中文和日文的字体,因为有些日文没有翻译。我选择的是思源黑体(中文)(https://github.com/adobe-fonts/source-han-sans/tree/release),反正不是商用,应该不用关心字体收费问题(有偿汉化或者放在营利性论坛或者网盘的可以注意一下)。字表我用的是中文常见3500字和日文常用字(https://gist.github.com/kgsi/ed2f1c5696a2211c1fd1e1e198c96ee4#file-japanese_full-txt)合在一起的结果。在UNITY导出的时候可能没有一起导出字体文件,此时可以在text里面选择我们自定义的字体,之后就一定会导出自定义的TMP字体。最后替换字体的时候可以多试几次,因为可能会有很多个SDF字体。
结尾
在体验了RPGmaker的傻瓜式内嵌汉化之后,UNITY汉化是真的反人类。在汉化的过程中,我也踩了很多坑,比如导出MonoBehaviour的时候全部导出了,于是把部分代码也汉化了,导致游戏报错。以及导出MonoBehaviour的时候是逐个读取level文件并导出的,操作麻烦,也导出了很多个重复的文件。现在把这些总结出来,希望之后会有更多人能够自己翻译喜欢的unity游戏,并且把自己的补丁共享出来。我反正是不想再碰unity的翻译了。
补丁会丢在2dfan上,使用的代码可能会丢在我的github上,但是最近比较忙(懒),放不放上去看心情吧。

















 2117
2117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









