







MedSegDiff-V2: Diffusion based Medical Image Segmentation with Transformer
摘要
- 提出了一种新的基于transformer的conditional UNet框架
- 一种新的Spectrum-Space
Transformer(SSFormer)来建模噪声和语义特征之间的交互
引言
将基于transformer的UNet(如TransUNet)与DPM结合起来的策略导致了欠佳的表现
- transformer-abstracted的条件特征与主干的特征不兼容
- transformer从原始图像中学习深层语义特征,而扩散主干从损坏的、有噪声的掩模中抽象特征
- transformer的动态和全局特性使其比cnn更敏感
- 在MedSegDiff中使用自适应条件策略会导致变压器设置中输出的较大差异
本文提出的解决方法:
- 锚定条件:将条件分割特征集成到扩散模型编码器中以减小扩散方差(采用高斯空间注意力)
- 语义条件,将条件分割嵌入整合到扩散嵌入中(SS-Former)
为了有效地弥合扩散噪声嵌入和条件语义特征之间的差距,提出了一种新的transformer机制,称为频谱空间变压器(SS-Former),学习它们之间的相互作用。这使得模型具有更小的扩散方差,同时还受益于transformer提供的全局和动态表示能力。
方法
整体结构
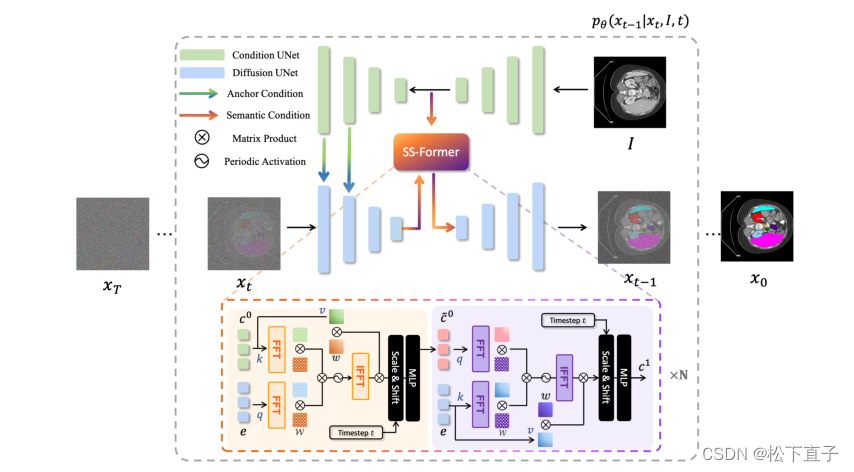
- 锚定条件首先施加在扩散模型的编码器上,即条件模型的解码器分割特征,集成到扩散模型的编码特征中
- 将条件模型的语义分割嵌入集成到扩散模型的嵌入,由SS-Former实现
损失函数:
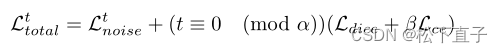
噪声加上有监督锚点的损失
高斯空间注意力的锚定条件
高斯空间注意可以表示为:
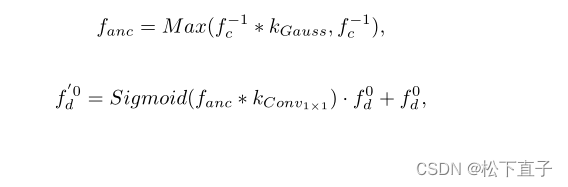
- *表示滑动窗口内核操作
- 在fc上应用高斯核kG来平滑激活
- kG的均值和方差是可学习的
- 选择平滑映射与原始特征映射之间的最大值
- 将fanc集成到fd中
- 类似于空间注意力的实现
SS-Former语义条件
- 由共享相同体系结构的几个块组成
- 每个块由两个交叉注意模块组成
第一个模块将扩散噪声嵌入编码为条件语义嵌入,第二个模块将混合噪声的语义嵌入编码为扩散噪声嵌入。这使得模型能够学习噪声和语义特征之间的交互,并实现更强的表示。
- 由于扩散模型预测了噪声掩码输入中的冗余噪声,其嵌入与条件分割语义嵌入之间存在域差距
- 提出了一种新的光谱空间注意机制
- 将语义信息和噪声信息合并到傅里叶空间
- 不同频谱中基于频率亲和性的组件分离和混合
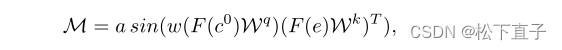
c0为条件模型的最深特征嵌入,e为扩散模型的最深特征嵌入
首先将c0和e转移到傅里叶空间
然后我们以e为q,c0为k,计算傅里叶空间上的权值映射
使用快速傅里叶反变换(IFFT)将映射转移回欧几里得空间,并应用于值中的条件特征
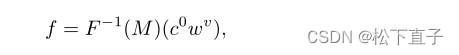
将时间嵌入应用于经典扩散实现之后的AdaIN归一化
从时间嵌入中学习到的缩放和移位参数扩展
实验结果
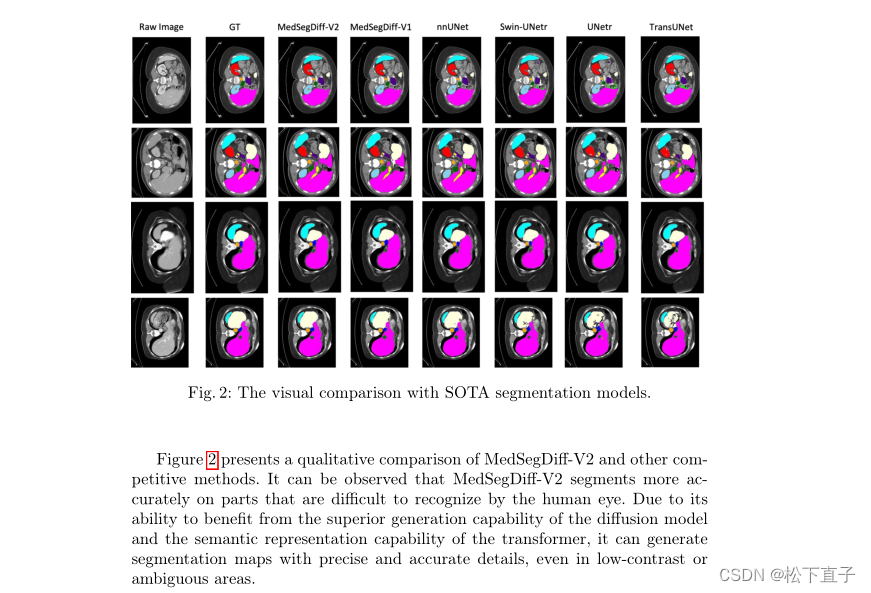
消融实验
 Anc.Cond. 代表 锚点调节
Anc.Cond. 代表 锚点调节


















 2740
2740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











