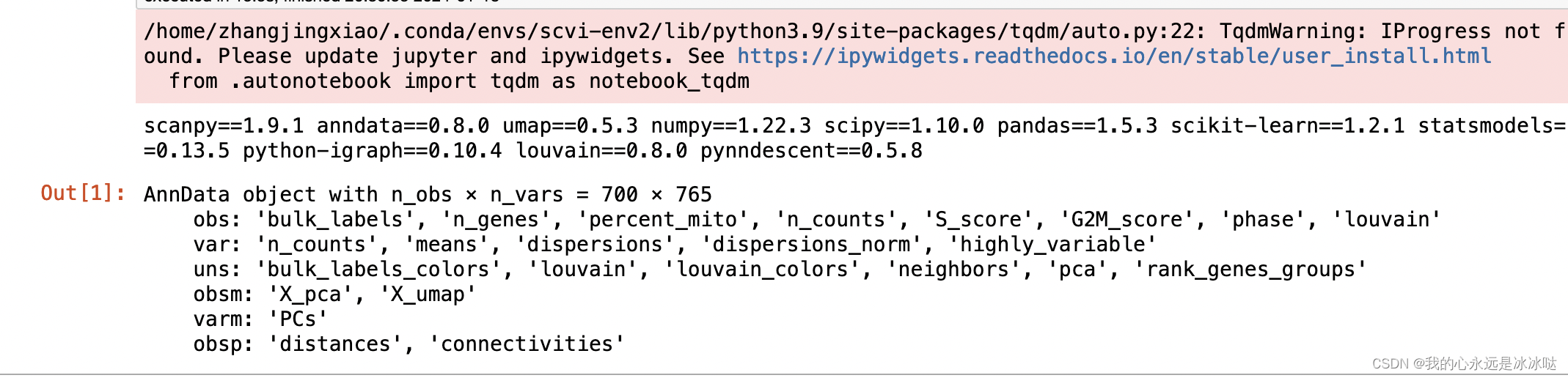
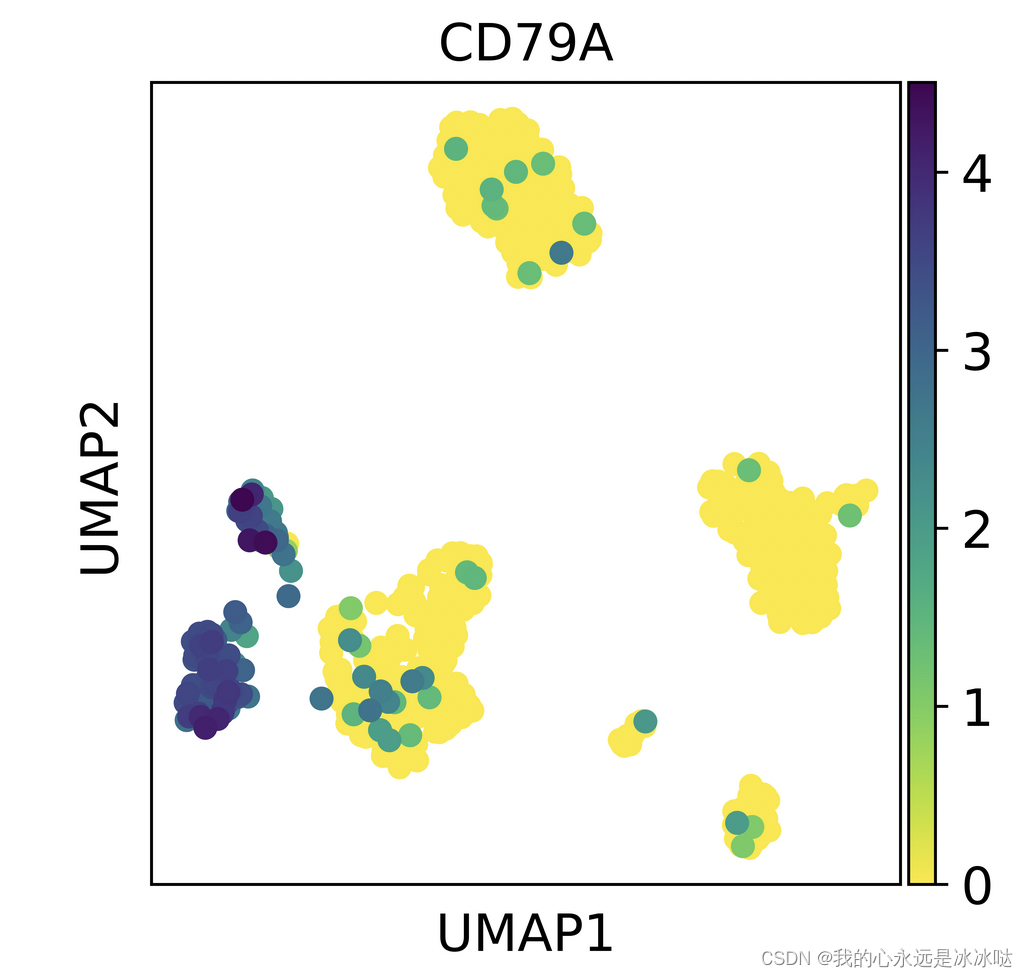
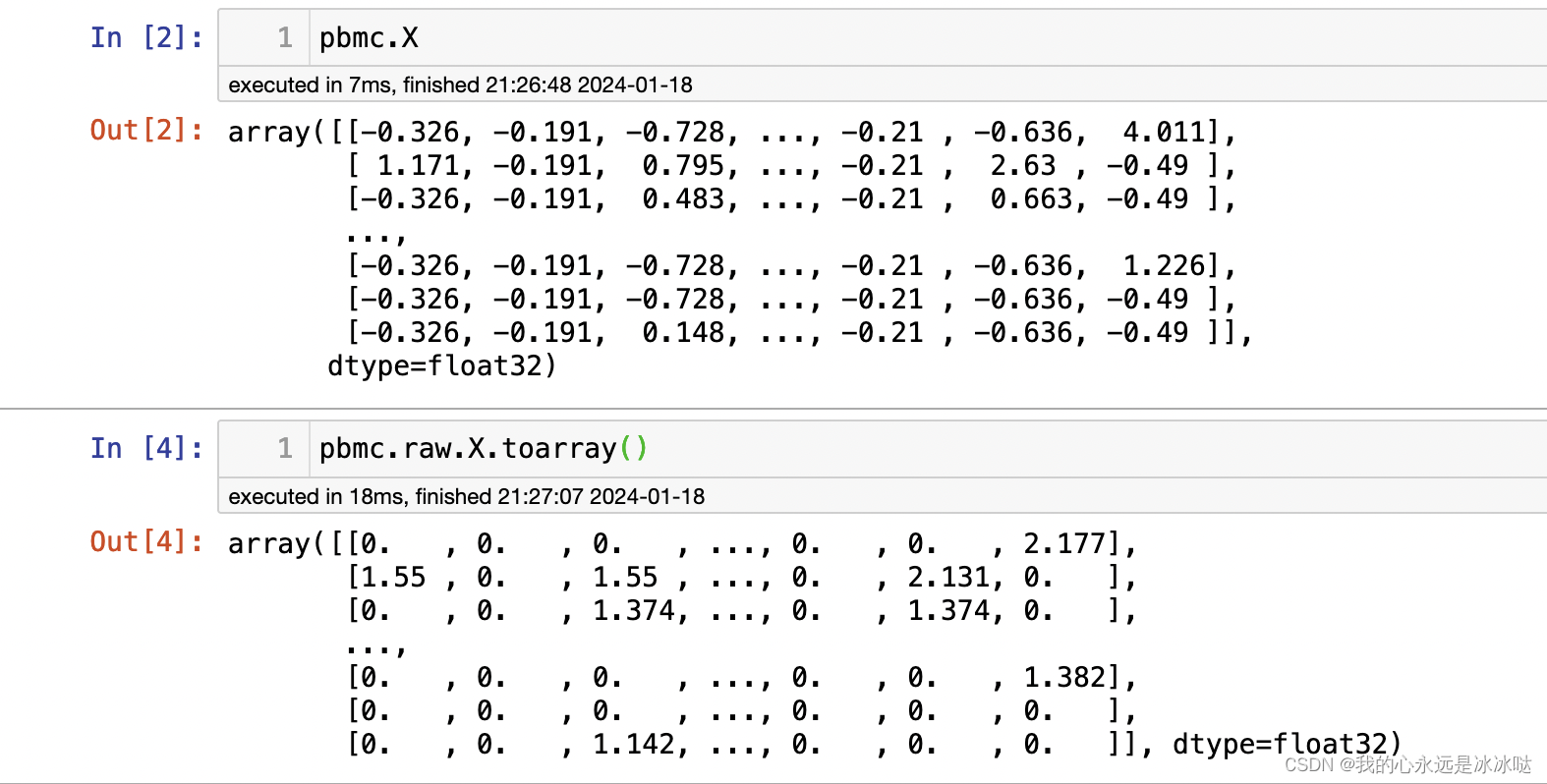
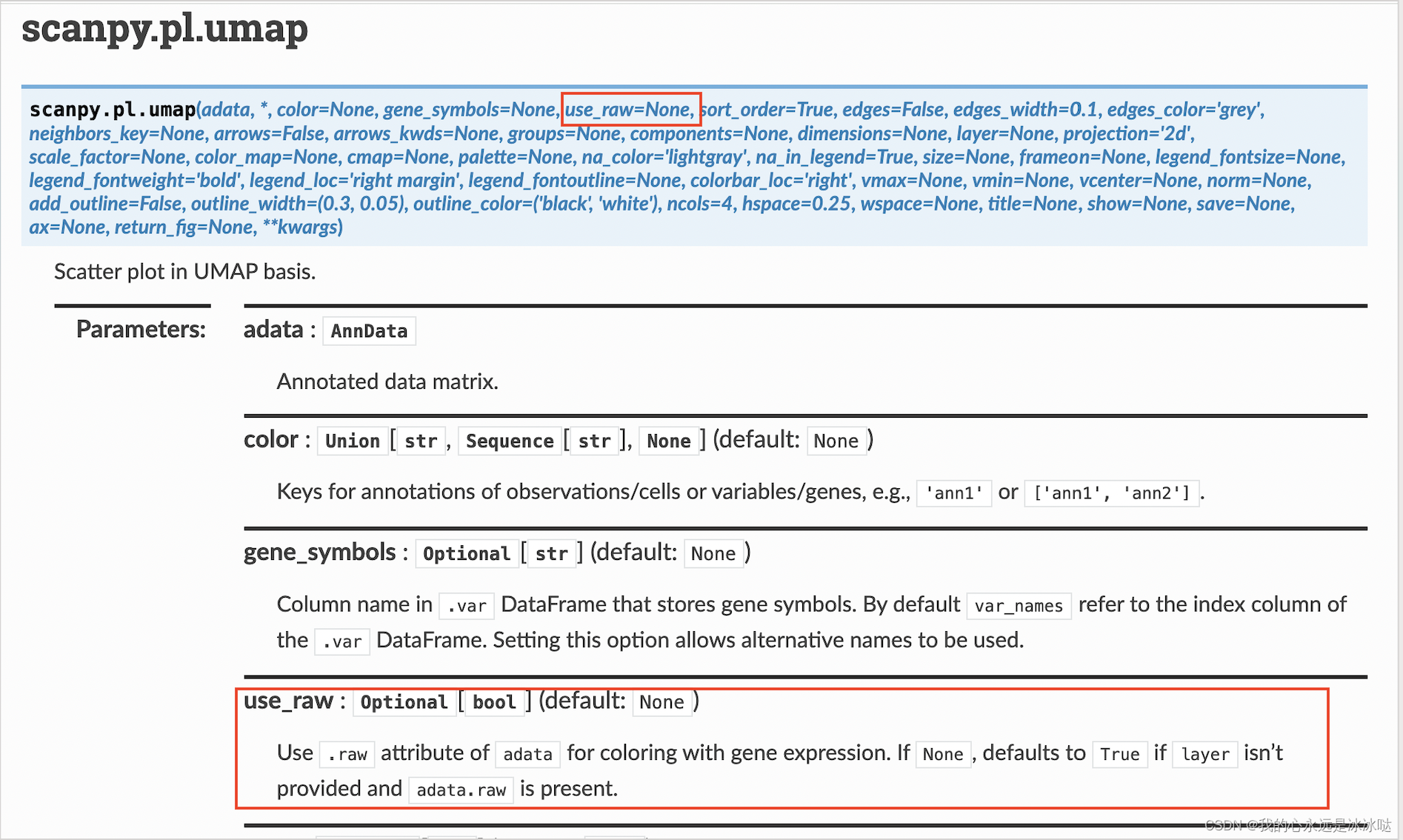
以下是 `umap.UMAP()` 函数的源代码:
```
class UMAP(BaseEstimator, TransformerMixin):
def __init__(
self,
n_neighbors=15,
n_components=2,
metric="euclidean",
metric_kwds=None,
output_metric="euclidean",
output_metric_kwds=None,
n_epochs=None,
learning_rate=1.0,
init="spectral",
min_dist=0.1,
spread=1.0,
low_memory=False,
set_op_mix_ratio=1.0,
local_connectivity=1.0,
repulsion_strength=1.0,
negative_sample_rate=5,
transform_queue_size=4.0,
a=None,
b=None,
random_state=None,
angular_rp_forest=False,
target_n_neighbors=-1,
target_metric="categorical",
target_metric_kwds=None,
target_weight=0.5,
transform_seed=42,
force_approximation_algorithm=False,
verbose=False,
):
self.n_neighbors = n_neighbors
self.n_components = n_components
self.metric = metric
self.metric_kwds = metric_kwds
self.output_metric = output_metric
self.output_metric_kwds = output_metric_kwds
self.n_epochs = n_epochs
self.learning_rate = learning_rate
self.init = init
self.min_dist = min_dist
self.spread = spread
self.low_memory = low_memory
self.set_op_mix_ratio = set_op_mix_ratio
self.local_connectivity = local_connectivity
self.repulsion_strength = repulsion_strength
self.negative_sample_rate = negative_sample_rate
self.transform_queue_size = transform_queue_size
self.a = a
self.b = b
self.random_state = random_state
self.angular_rp_forest = angular_rp_forest
self.target_n_neighbors = target_n_neighbors
self.target_metric = target_metric
self.target_metric_kwds = target_metric_kwds
self.target_weight = target_weight
self.transform_seed = transform_seed
self.force_approximation_algorithm = force_approximation_algorithm
self.verbose = verbose
def fit(self, X, y=None):
self.fit_transform(X, y)
return self
def transform(self, X):
if self.transform_mode_ == "embedding":
if sparse.issparse(X):
raise ValueError(
"Transform not available for sparse input in `" "transform_mode='embedding'`"
)
X = check_array(X, dtype=np.float32, accept_sparse="csr", order="C")
X -= self._a
X /= self._b
return self._transform(X)
elif self.transform_mode_ == "graph":
if not sparse.issparse(X):
raise ValueError(
"Transform not available for dense input in `" "transform_mode='graph'`"
)
return self.graph_transform(X)
else:
raise ValueError("Unknown transform mode '%s'" % self.transform_mode_)
def fit_transform(self, X, y=None):
if self.verbose:
print(str(datetime.now()), "Start fitting UMAP...")
self.fit_data = X
if self.output_metric_kwds is None:
self.output_metric_kwds = {}
if self.metric_kwds is None:
self.metric_kwds = {}
if sparse.isspmatrix_csr(X) and _HAVE_PYNNDESCENT:
self._sparse_data = True
self._knn_index = make_nn_descent(
self.fit_data,
self.n_neighbors,
self.metric,
self.metric_kwds,
self.angular_rp_forest,
random_state=self.random_state,
low_memory=self.low_memory,
verbose=self.verbose,
)
else:
self._sparse_data = False
self._knn_index = make_nn_graph(
X,
n_neighbors=self.n_neighbors,
algorithm="auto",
metric=self.metric,
metric_kwds=self.metric_kwds,
angular=self.angular_rp_forest,
random_state=self.random_state,
verbose=self.verbose,
)
# Handle small cases efficiently by computing all distances
if X.shape[0] < self.n_neighbors:
self._raw_data = X
self.embedding_ = np.zeros((X.shape[0], self.n_components))
return self.embedding_
if self.verbose:
print(str(datetime.now()), "Construct fuzzy simplicial set...")
self.graph_ = fuzzy_simplicial_set(
X,
self.n_neighbors,
random_state=self.random_state,
metric=self.metric,
metric_kwds=self.metric_kwds,
knn_indices=self._knn_index,
angular=self.angular_rp_forest,
set_op_mix_ratio=self.set_op_mix_ratio,
local_connectivity=self.local_connectivity,
verbose=self.verbose,
)
if self.verbose:
print(str(datetime.now()), "Construct embedding...")
self._raw_data = X
if self.output_metric_kwds is None:
self.output_metric_kwds = {}
if self.target_n_neighbors == -1:
self.target_n_neighbors = self.n_neighbors
self.embedding_ = simplicial_set_embedding(
self._raw_data,
self.graph_,
self.n_components,
initial_alpha=self.learning_rate,
a=self.a,
b=self.b,
gamma=1.0,
negative_sample_rate=self.negative_sample_rate,
n_epochs=self.n_epochs,
init=self.init,
spread=self.spread,
min_dist=self.min_dist,
set_op_mix_ratio=self.set_op_mix_ratio,
local_connectivity=self.local_connectivity,
repulsion_strength=self.repulsion_strength,
metric=self.output_metric,
metric_kwds=self.output_metric_kwds,
verbose=self.verbose,
)
self.transform_mode_ = "embedding"
return self.embedding_
def graph_transform(self, X):
if not sparse.issparse(X):
raise ValueError(
"Input must be a sparse matrix for transform with `transform_mode='graph'`"
)
if self.verbose:
print(str(datetime.now()), "Transform graph...")
if self._sparse_data:
indices, indptr, data = _sparse_knn(self._knn_index, X.indices, X.indptr, X.data)
indptr = np.concatenate((indptr, [indices.shape[0]]))
knn_indices, knn_dists = indices, data
else:
knn_indices, knn_dists = query_pairs(
self._knn_index,
X,
self.n_neighbors,
return_distance=True,
metric=self.metric,
metric_kwds=self.metric_kwds,
angular=self.angular_rp_forest,
random_state=self.random_state,
verbose=self.verbose,
)
graph = fuzzy_simplicial_set(
X,
self.n_neighbors,
knn_indices=knn_indices,
knn_dists=knn_dists,
random_state=self.random_state,
metric=self.metric,
metric_kwds=self.metric_kwds,
angular=self.angular_rp_forest,
set_op_mix_ratio=self.set_op_mix_ratio,
local_connectivity=self.local_connectivity,
verbose=self.verbose,
)
self.transform_mode_ = "graph"
return graph
def _transform(self, X):
if self.verbose:
print(str(datetime.now()), "Transform embedding...")
if self.transform_seed is None:
self.transform_seed_ = np.zeros(self.embedding_.shape[1])
else:
self.transform_seed_ = self.embedding_[self.transform_seed, :].mean(axis=0)
dists = pairwise_distances(
X, Y=self.embedding_, metric=self.output_metric, **self.output_metric_kwds
)
rng_state = np.random.RandomState(self.transform_seed_)
# TODO: make binary search optional
adjusted_local_connectivity = max(self.local_connectivity - 1.0, 1e-12)
inv_dist = 1.0 / dists
inv_dist = make_heap(inv_dist)
sigmas, rhos = smooth_knn_dist(
inv_dist, self.n_neighbors, local_connectivity=adjusted_local_connectivity
)
rows, cols, vals = compute_membership_strengths(
inv_dist, sigmas, rhos, self.negative_sample_rate, rng_state
)
graph = SparseGraph(
X.shape[0],
self.embedding_.shape[0],
rows,
cols,
vals,
self.transform_queue_size * X.shape[0],
np.random.RandomState(self.transform_seed_),
self.metric,
self.output_metric_kwds,
self.angular_rp_forest,
self.verbose,
)
graph.compute_transition_matrix(self.repulsion_strength, self.epsilon)
embedding = graph.compute_embedding(
self.embedding_,
self.learning_rate,
self.n_epochs,
self.min_dist,
self.spread,
self.init,
self.set_op_mix_ratio,
self._a,
self._b,
self.gamma,
self.rp_tree_init,
self.rp_tree_init_eps,
self.metric,
self.output_metric_kwds,
self.random_state,
self.verbose,
)
return embedding
def set_op_mix_ratio(self, mix_ratio):
self.set_op_mix_ratio = mix_ratio
def fuzzy_simplicial_set(
X,
n_neighbors,
metric="euclidean",
metric_kwds=None,
random_state=None,
knn_indices=None,
angular=False,
set_op_mix_ratio=1.0,
local_connectivity=1.0,
verbose=False,
):
return fuzzy_simplicial_set(
X,
n_neighbors,
metric=metric,
metric_kwds=metric_kwds,
random_state=random_state,
knn_indices=knn_indices,
angular=angular,
set_op_mix_ratio=set_op_mix_ratio,
local_connectivity=local_connectivity,
verbose=verbose,
)
def simplicial_set_embedding(
data,
graph,
n_components,
initial_alpha=1.0,
a=None,
b=None,
gamma=1.0,
negative_sample_rate=5,
n_epochs=None,
init="spectral",
spread=1.0,
min_dist=0.1,
set_op_mix_ratio=1.0,
local_connectivity=1.0,
repulsion_strength=1.0,
metric="euclidean",
metric_kwds=None,
verbose=False,
):
return simplicial_set_embedding(
data,
graph,
n_components,
initial_alpha=initial_alpha,
a=a,
b=b,
gamma=gamma,
negative_sample_rate=negative_sample_rate,
n_epochs=n_epochs,
init=init,
spread=spread,
min_dist=min_dist,
set_op_mix_ratio=set_op_mix_ratio,
local_connectivity=local_connectivity,
repulsion_strength=repulsion_strength,
metric=metric,
metric_kwds=metric_kwds,
verbose=verbose,
)
```
该函数实现了UMAP算法,是非常复杂的代码。简单来说,它实现了以下步骤:
- 初始化UMAP对象的各种参数。
- 根据输入数据计算k近邻图,这一步可以使用pyNNDescent或BallTree算法。
- 构建模糊单纯形集,用于表示原始数据的流形结构。
- 计算新的嵌入空间,用于将原始数据降维到低维空间。
- 支持transform方法,以便在已经学习了嵌入空间之后将新的数据映射到该空间中。
- 支持fuzzy_simplicial_set和simplicial_set_embedding方法,以便使用UMAP算法的不同组件。
























 3537
3537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









