







用于目标检测的视觉-语言数据
1、"image-level data"(图像级数据)
在机器学习和计算机视觉领域中通常指的是与整张图像相关的标签或数据,而不是图像中单个对象或像素的详细标注。简单来说就是一张图片会有一点文字描述
流行的数据集有
2、"object-level data"(对象级数据)
是指与单个对象或实体相关的数据集合,这些数据可以是图像、视频、文本或其他类型的数据,它们描述了对象的属性、特征和行为。有一张图片,以及图片中物体的框,每个框都会有一段文字的解释
流行的数据集有

3、将image转换为object
方法1:离线转换
先使用object-level data的数据训练一个检测器,然后将image-level data的数据送入检测器得到检测结果,将检测结果作为标注与object-level data重新生成一批新的或者说为原有的image-level data图片打标签
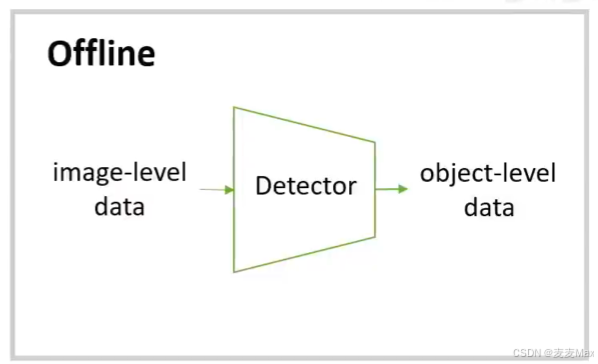
方法2:在线检测
直接从image-level data中学到一个object language对其的方法(开放词汇式目标检测(open-vocabulary object detection))
有一张图片和一些文本描述,用分词器将文本中的名词提取出来,然后将图片的region提取出来,接下来的任务就是将region和名词配对正确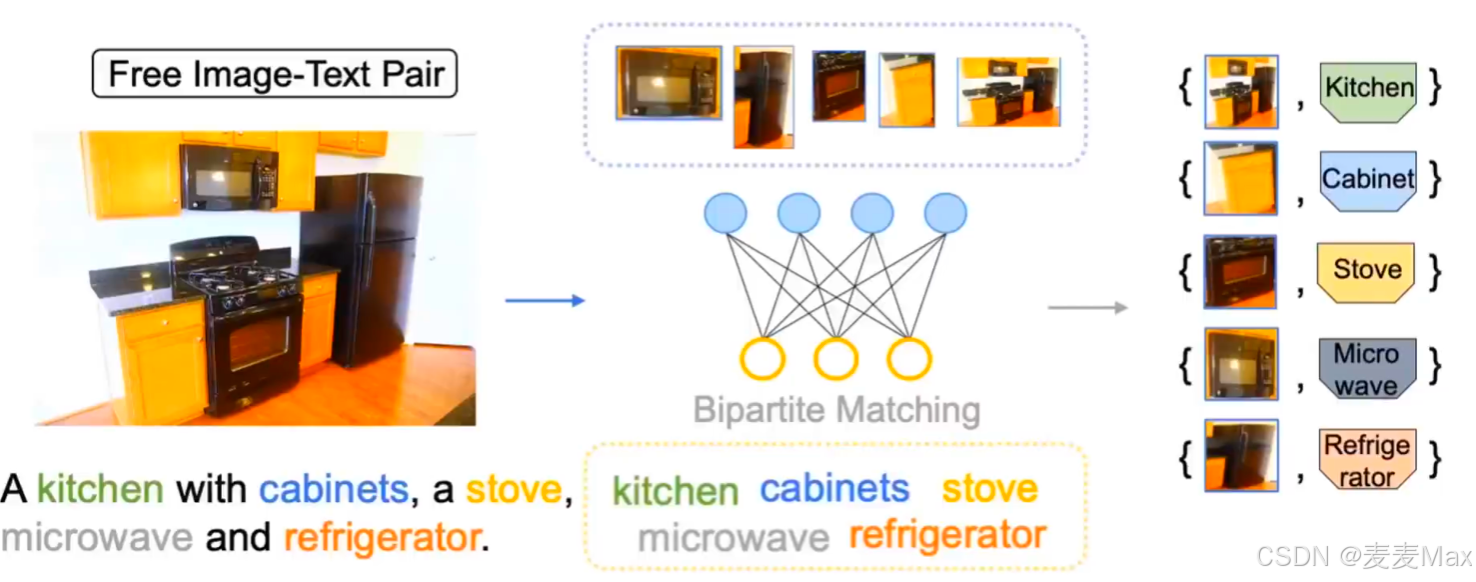
匹配方法:二分匹配(Bipartite Ma
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2030
2030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









