







🐧大模型系列篇章
💖 多模态大模型 🔎 GroundingDINO 论文总结
💖 端到端目标检测 🔎 从DETR 到 GroundingDINO
💖 多模态大模型 👉 CLIP论文总结
💖 多模态大模型 👉 EVA-CLIP
💚 生成模型 👉 从 VAE 到 Diffusion Model (上)
💚 生成模型 👉 从 VAE 到 Diffusion Model (下)
💧 天气大模型
| 欢迎订阅专栏,第一时间掌握最新科技 专栏链接 |
文章目录
Graphcast
- 中长期天气预报。
- 在一个谷歌云TPU v4的设备上,一分钟内可以,精确预测未来10-day的天气,支持热带气旋路径、大气河流和极端温度。
- 相比于传统数值公式计算的方式,它可以依靠雷达图做 次季节热浪预报 和 临近降水预报。
- 最近的研究在一些特定的变量和七天内的预报时限下,已经取得了在1.0°和0.25°分辨率下与 IFS (全球最好的数值天气预报系统 IFS)相当甚至更好的性能。
- GraphCast 将地球天气的两个最新状态 (当前时间和六小时前)作为输入,并预测未来六小时的下一个天气状态
1. Input Data
模型的输入
- 天气的状态: 每一个格点代表了一组地表(surface) 和 **大气(atmospheric)**的变量。
- 0.25° 纬度-经度网格: 天气状态的空间分辨率为0.25°,在纬度和经度方向上相邻格点之间的距离是0.25°。
- 721 × 1440 格点: 网格的大小是721个纬度点和1440个经度点,总共有 721×1440=1,038,240 个格点。
- 黄色图层和蓝色图层: 在展开的弹出窗口中,黄色图层代表5个地表变量,而蓝色图层代表6个在37个压力层次上重复的大气变量。
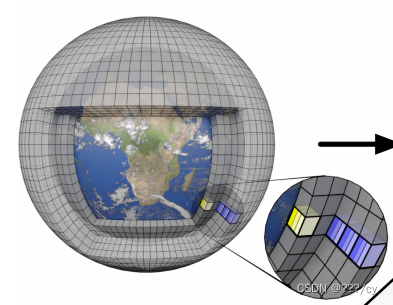
- 总变量数: 对于每个格点,有 5+6×37=227 个变量。这些变量的总数是 721×1440×227=235,680,480
这个表示方式描述了模型接收的天气状态数据的空间分辨率、网格大小、变量的类型和数量。 是输入数据规模和结构的说明。

- Several example datasets are available, varying across a few axes
- Source: fake, era5, hres
- Resolution: 0.25deg, 1deg, 6deg
- Levels: 13, 37
- Steps: How many timesteps are included
- Not all combinations are available.
- Higher resolution is only available for fewer steps due to the memory requirements of loading them.
- HRES is only available in 0.25 deg, with 13 pressure levels.

2. Model Param
-
Mesh Size 地球的内部图形表示。Smaller meshes 运行速度更快,但输出较差。mesh size 不影响模型的参数数量。
-
分辨率(resolution)和压力级别的数量(number of pressure levels)必须与数据匹配。
- 较低的分辨率和较少的级别会运行得更快一些。
- 数据分辨率仅影响编码器/解码器。
3. Architecture
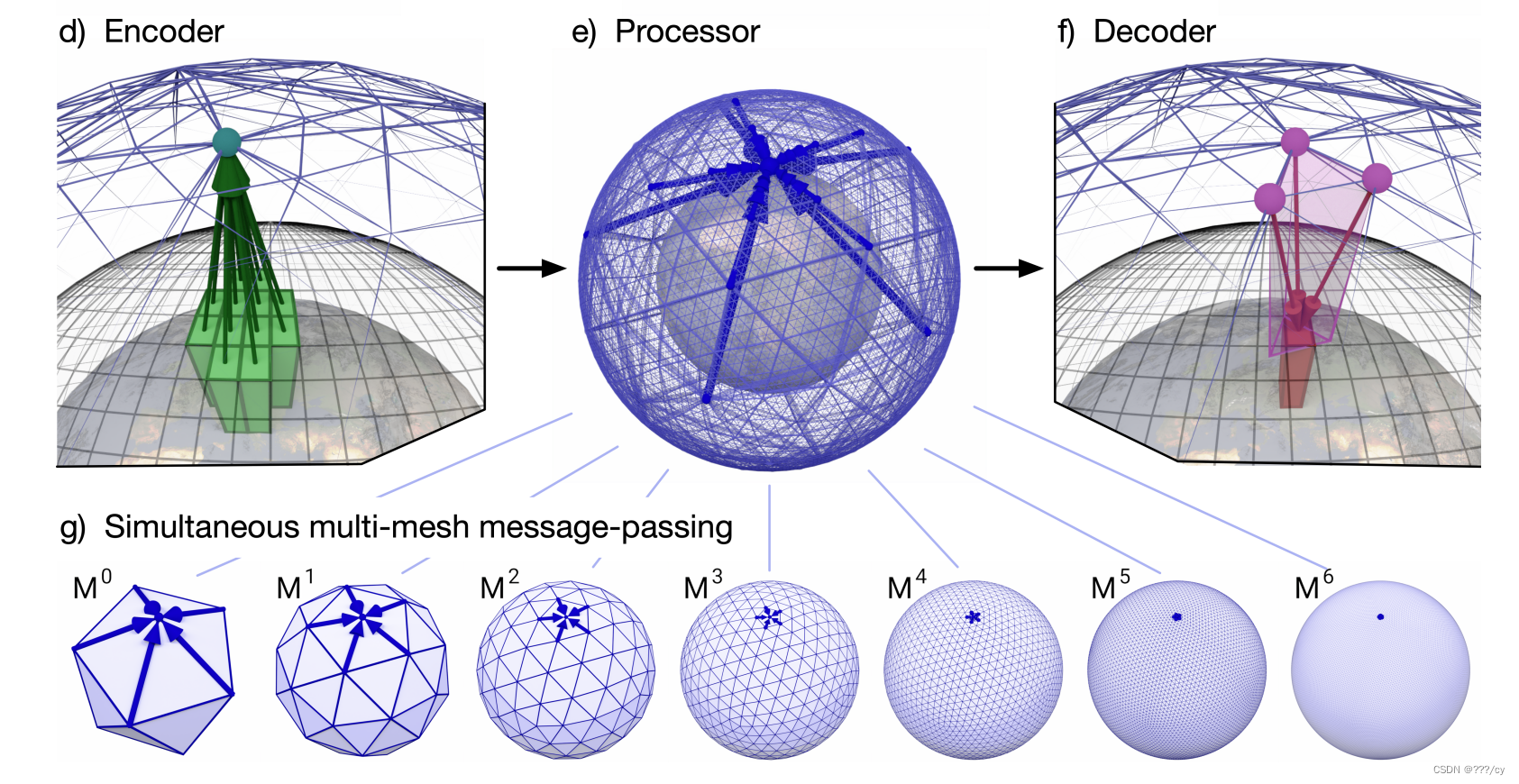
GNN (encoder - process - decode)
1. Encoder: 用single GNN把input grid 映射成 multi-mesh graph representation 上的节点。为的是让该变量进入processor去学习internal “multi-mesh” 上的节点属性。
2. Processor: 使用 16 个非共享参数的 GNN 层 去学习,该Processor使用图神经网络层进行学习的消息传递,以在多网格上有效地传播信息。 通过学习到的知识来更新当前encodered的节点。 模型在不同分辨率的网格上进行消息传递的过程是并行的,而不是按顺序进行的。模型具有在多个空间尺度上捕获特征的能力。
每个节点都与不同分辨率的网格相对应,并通过其与该节点相连接的所有边同时进行消息传递。 这种并行处理确保了在多重网格结构中,每个节点都能够获得来自所有分辨率的信息,而不需要等待一个分辨率的消息传递完成后再进行下一个。
3. Decoder: 使用单个 GNN 层,将来自最终Processor层的学习特征从多重网格表示映射回到纬度-经度网格。该输出为对最近输入状态的残差更新,也就是模型尝试预测当前时刻的输出与最近一时刻输入的差异。
4. Train
-
训练数据: 模型开发过程中使用了来自欧洲中期天气预报中心 (ECMWF )ERA5 重分析存档的39年(1979年至2017年)历史数据。
-
目标函数: 均方误差(MSE)的加权平均 作为训练目标,其中权重考虑了垂直层级。
- 在GraphCast的预测状态与相应的ERA5状态之间,通过 𝑁 个自回归步骤计算的。这里的 𝑁 从1递增到12(即 6 小时到 3 天),代表着预测未来时刻的范围。
-
𝑁个自回归步骤 意味着模型被要求预测未来多个时间步长,这个范围从六小时到三天。
-
对于每个时间步长,模型通过GraphCast进行预测,并将其与ERA5数据进行比较。然后,通过计算预测值和实际值之间的平方差,得到均方误差。这是因为均方误差对差异的平方进行了求和和平均,用于表示模型的预测性能。
-
这个均方误差是在垂直层级上加权平均的,说明在考虑不同层级的情况下,对误差的处理更加细致。通过调整 𝑁 的值,可以评估模型在不同时间范围内的预测性能,因为 𝑁 控制了自回归模型的步长。
-
- 在GraphCast的预测状态与相应的ERA5状态之间,通过 𝑁 个自回归步骤计算的。这里的 𝑁 从1递增到12(即 6 小时到 3 天),代表着预测未来时刻的范围。
-
训练耗时: 使用批量并行性在 32 个 Cloud TPU v4 设备上训练 GraphCast 大约花费了四个星期。(TPU v4 性能比 A100强了1.7)
-
验证集: 2018 之后的数据
NowcastNet
1. 简介
-
这是一个用于预测极端降水的模型,模型对于由小到大的降雨率提供了有效的预报,尤其是对于伴随着前向或对流过程的极端降水事件的有效预报。
-
用于降水的“临近预报”,NowcastNet 利用雷达观测提前三个小时准确预测了 2,048 公里 × 2,048 公里区域的降水量。
-
使用生成模型来预测天气
-
NowcastNet 模型的设计目标是将物理演变(physical-evolution schemes ) 和 条件学习(conditional learning methods)相结合,通过神经网络进行端到端的学习,以最优化预测误差,从而提高对极端降水的预测性能。
-
模型的训练和评估基于来自美国和中国的 雷达观测数据 。雷达数据通常用于监测降水和大气过程。
-
该模型在 71%的案例中排名第一,超过了其他主要方法。
2. Architecture
-
NowcastNet: 它是一个基于物理条件的深度生成模型(physics-conditional deep generative model)。通过深度生成模型,结合了物理条件(基于雷达的表面降水估计与流体动力学定律相结合),以预测未来的雷达场。
-
NowcastNet包括一个随机生成网络(Stochastic Generative Network)和一个确定性演变网络(Deterministic Evolution Network)
- 首先设计了演变网络(Evolution network),用以建模平流运动等物理性质更显著的中尺度降水过程,并基于物质连续性方程(即质量守恒定律)设计了神经演变算子,端到端模拟降水过程中的十公里尺度运动,并通过反向传播最小化预报累积误差。
- 演变网络(Evolution network) 遵循物理降水规律,获得合理的物理预测
- 其次,提出了平流尺度生成网络,以演变网络预测结果为条件,将 过去的雷达观测值 和演变网络的 预测结果 作为输入,并根据隐式的随机向量z, 生成了更加精细的范围在1-2km的、包含对流特征的预测。
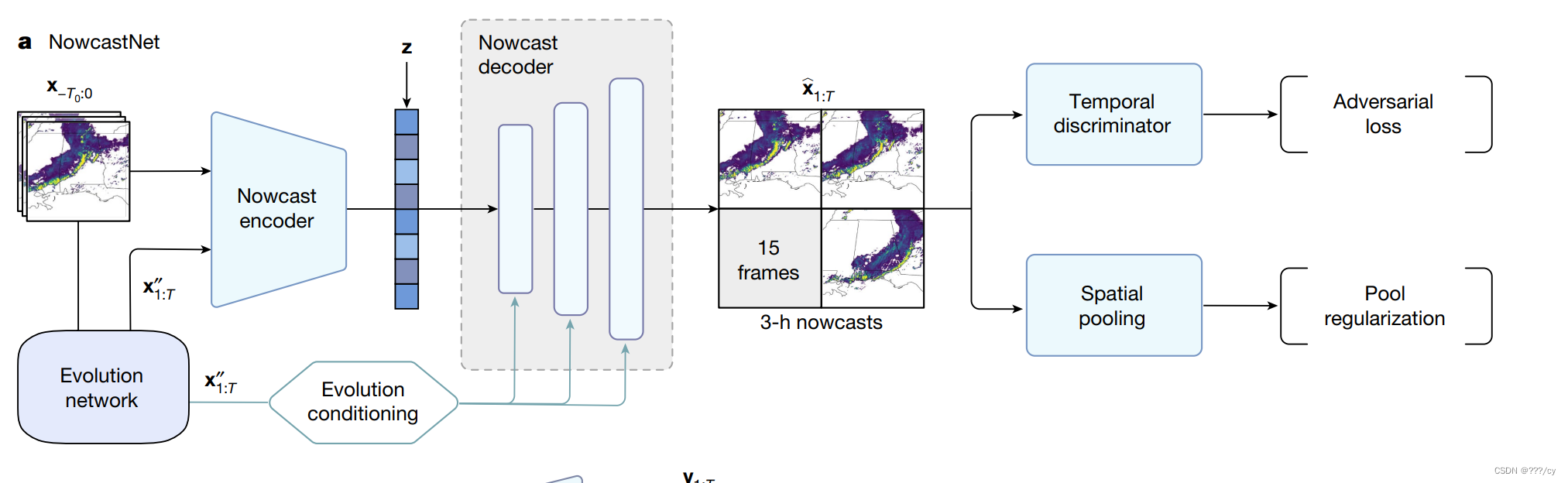
- 首先设计了演变网络(Evolution network),用以建模平流运动等物理性质更显著的中尺度降水过程,并基于物质连续性方程(即质量守恒定律)设计了神经演变算子,端到端模拟降水过程中的十公里尺度运动,并通过反向传播最小化预报累积误差。
3. Train
Datasets:
- 美国数据集
- 由 MRMS 系统在美国上空收集的雷达观测数据组成。 雷达合成覆盖南北方向北纬20°至55°、东西方向西经130°至60°的区域。
- 空间网格的组成为3,500 × 7,000,每个网格的分辨率为0.01°。
- 数据集中缺失的值被指定为负值,这可以 在评估过程中掩盖不相关的位置
- 使用2016年至2021年6年时间范围内收集的雷达观测数据,其中训练集涵盖2016年至2020年,测试集涵盖2021年。
- 为了权衡计算成本和预测能力,我们将时间分辨率设置为 10 分钟,并将雷达域的空间尺寸缩小到原始宽度和高度的一半,这将保留大部分对流尺度细节。
- 在模型中,对于每小时的雨量,设定了一个上限值。这个上限值被设置为每小时128毫米。
- 中国数据集
- 中国气象局在中国收集的雷达观测数据,雷达混合覆盖南北方向北纬17°至53°,东西方向东经96°至132°,覆盖我国中东部地区。
- 与美国数据集类似,缺失值被负值替换。
- 使用了 2019年9月1日至2021年6月30日 近两年时间范围内收集的雷达观测数据。以2019年9月1日至2021年3月31日的数据作为训练集,而以2021年4月1日至2021年6月30日的数据作为测试集。
Data preparation
在训练过程中采用了分层采样方法
- 首先将全尺寸的序列裁剪成更小的时空大小。
- 训练集:将数据序列切割成空间大小为 256 × 256** 、时间大小为 270 分钟的小块,并且在垂直和水平方向上的偏移为 32。
- 测试集: 将数据序列切割成空间大小为 512× 512 、时间大小为 270 分钟的小块,并且在垂直和水平方向上的偏移为 32。
- 每一个切块计算接受概率 ( acceptance probability): sum of radar fields for all grids and all time steps on this
crop, and ϵ is a small constant;这个雷达域切块上所有的网格和时间步长的和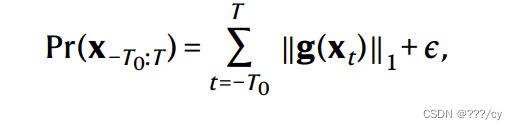
- 在训练中,对于每一个网格设定 g(x) = 1 - e^(-x), 当该网格信息缺失时 设定g(x) = 0
- 在评估不同模型对极端降雨的预测能力时,定义测试集中 g(x) = x
- 支持本研究结果的处理后雷达数据可在清华云上获取 清华云 code
Hyperparameter Tuning
CSI用于衡量预报的位置准确性;PSD用于衡量预报的频谱特征与雷达观测的降水变化性之间的比较。
- 在调整超参数的时候使用了使用了 CSI 邻域的均值(CSIN)。这是通过计算在降雨水平为 16 mm h⁻¹、32 mm h⁻¹ 和 64 mm h⁻¹ 时,所有预测时间步上的 CSI 邻域的均值来进行的。
- 当调整生成模型的超参数时,使用 CSI 邻域 和 PSD 来作为两个主要的评价指标
- 不同超参数的模型中进行超参数调整的步骤
- 首先,确保模型的PSD不劣于 pySTEPS模型(pySTEPS是一种基于平流的方法) 。这一步是为了确保模型在频谱上的表现至少与基准模型 pySTEPS 相当。
- 使用CSI邻域均值来作为超参数选择的最终指标。

















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









