









文章目录
- yolov7示例 | 如何写一个剪枝代码?
- 1. 剪枝的介绍 (Introduction to Pruning)
- 2. 选择剪枝的颗粒度 (Determine the Pruning Granularity)
- 3. 选择在哪里剪枝 (Determine the Pruning Criterion)
- 4. 确定剪枝比率(Determine the Pruning Ratio)
- 5. Fine-tune/Train Pruned Neural Network 微调训练
yolov7示例 | 如何写一个剪枝代码?
1. 剪枝的介绍 (Introduction to Pruning)
什么是剪枝 (What is pruning)?
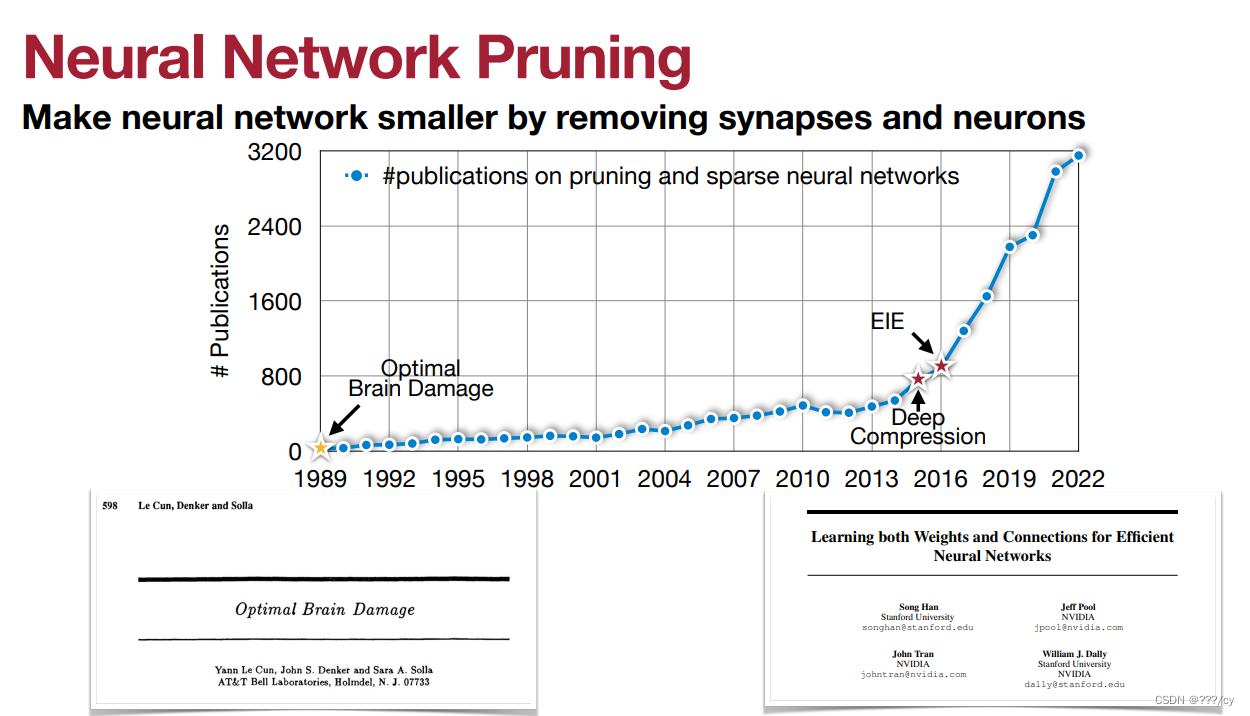
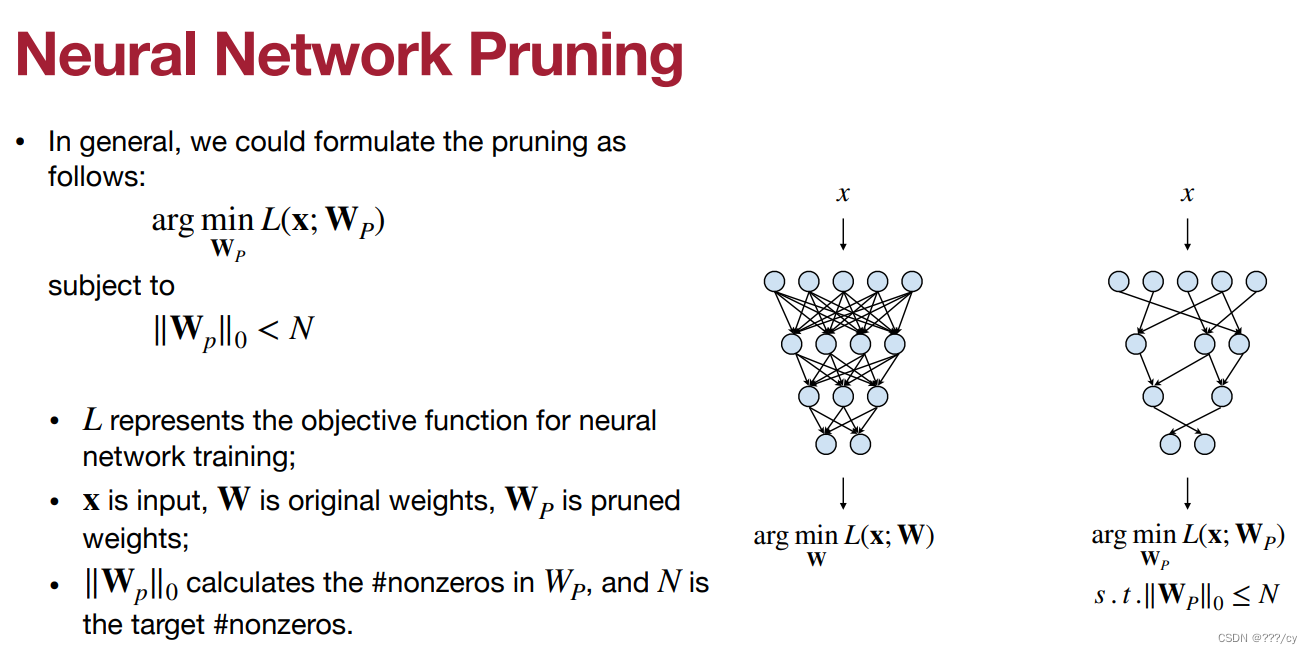
如何用公式定义剪枝 (How should we formulate pruning)?
2. 选择剪枝的颗粒度 (Determine the Pruning Granularity)
- 确定剪枝的标准。常见的标准包括基于权重大小的剪枝、基于重要性得分的剪枝(如梯度或二阶导数),或结构化剪枝(去除整个神经元或通道)。
- 考虑剪枝的具体目标,例如模型压缩、推理加速或内存减少。
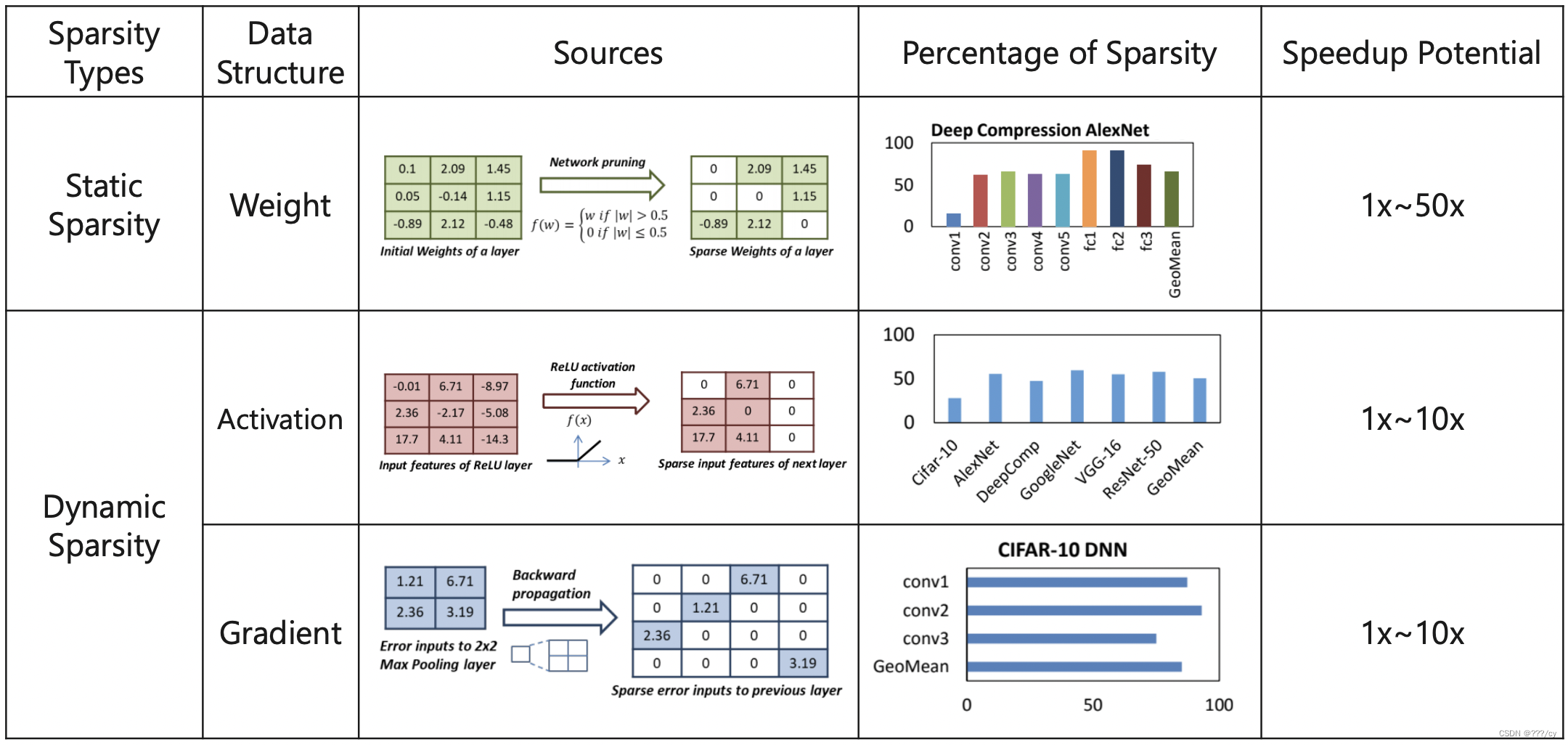
Pruning can be performed at different granularities, from structured to non-structured
- 剪枝 权重 的记住这张图
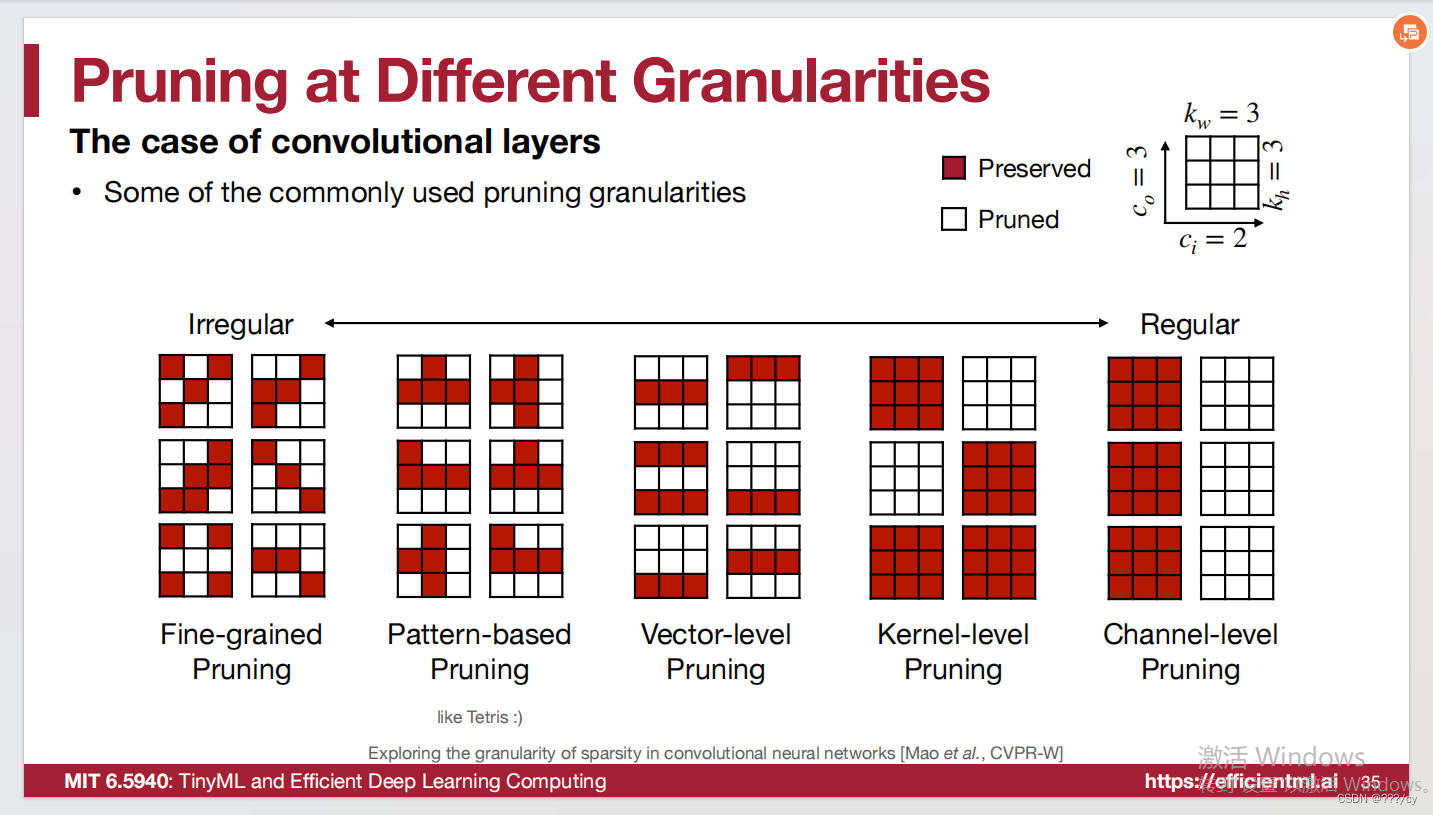
- 剪枝特征图的记住这张图
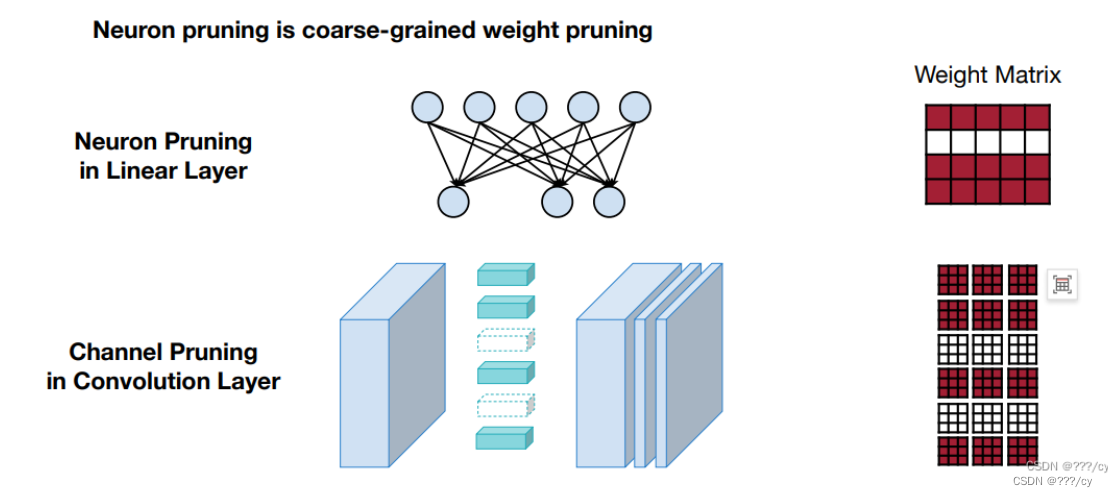
3. 选择在哪里剪枝 (Determine the Pruning Criterion)
- 应该剪枝哪个神经元或者突触呢? What synapses/neurons should we prune?
选择与标准相符的剪枝方法或算法。例如,可以使用L1或L2正则化进行基于权重大小的剪枝,也可以使用通道剪枝等技术进行结构化剪枝。
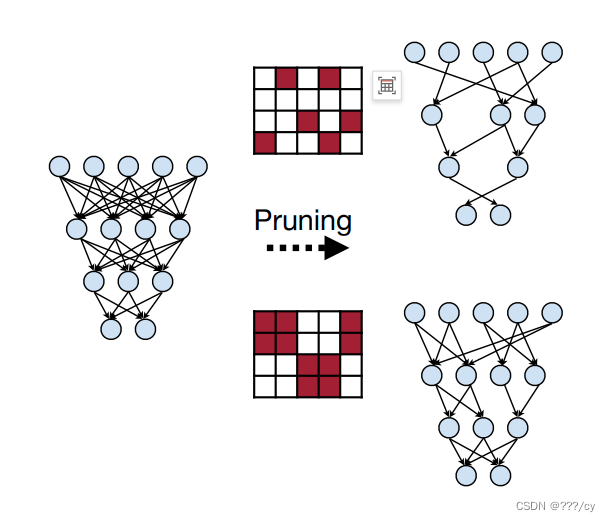
3.1 应该剪哪个突触呢? What sysnapses should we prune? (适合CNN)(权重剪枝)
3.1.1 基于权重大小的剪枝 (Magnitude-based pruning)
“Magnitude-based pruning” 它基于神经网络中的参数(通常是权重)的大小来确定哪些参数应该被剪枝,以减小模型的大小和复杂性。该技术的主要思想是去除那些绝对值较小的权重,因为它们对模型的贡献相对较小,而保留那些较大的权重,以维持模型性能。
下面是基于权重大小的剪枝的基本原理和步骤:
1. 按照权重排序(简单有效,在工业界广泛应用:高效和易于部署两者之间权衡): 首先,对神经网络中的所有权重进行排序,通常按绝对值大小进行排序,从最小到最大。
如何定义effectiveness:accuracy (performance) / complexity
- 在下图里,选择剪掉 0.1

- 再举一个例子
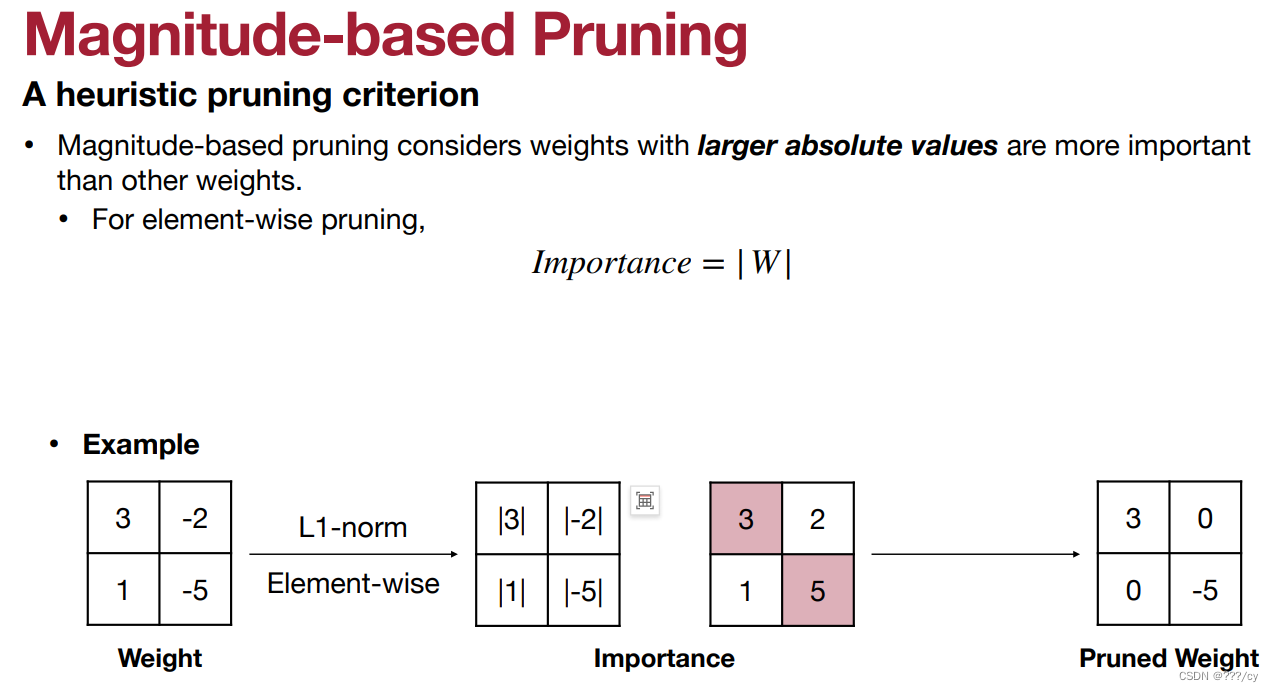
- 现在我们想剪整行,如何选择哪行去剪呢?
- 方法一:L1-norm
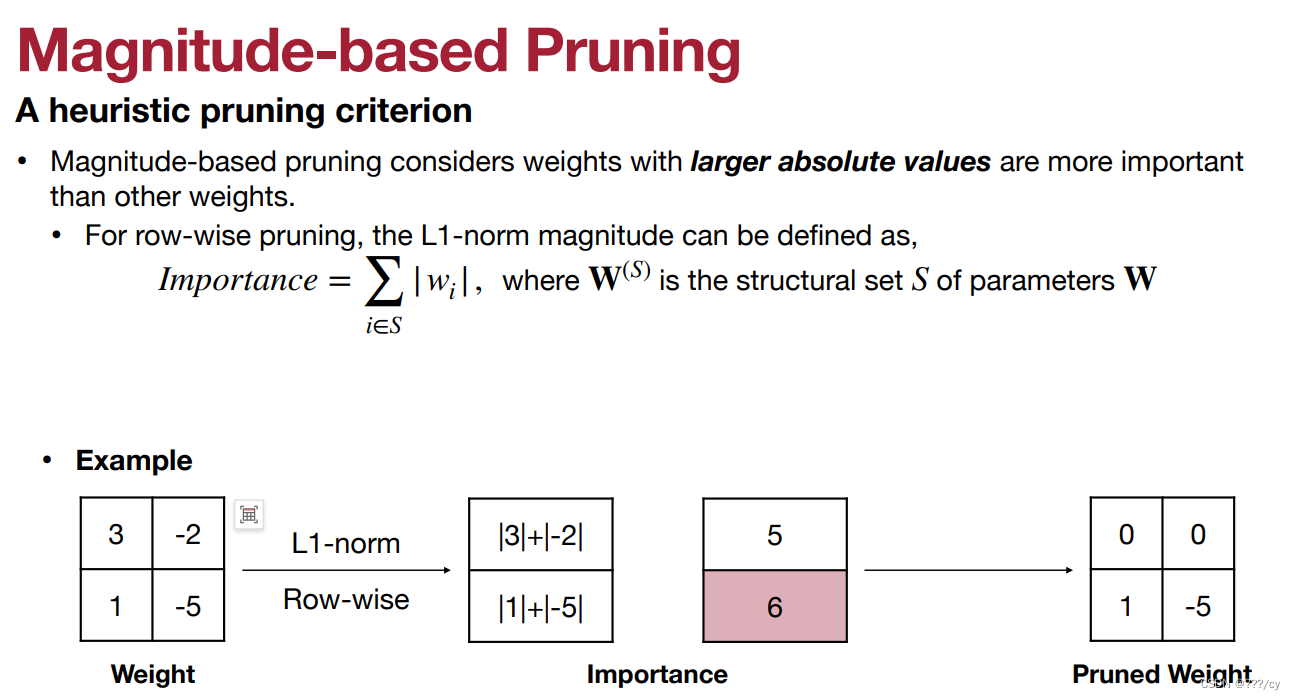
- 方法二:L2-norm
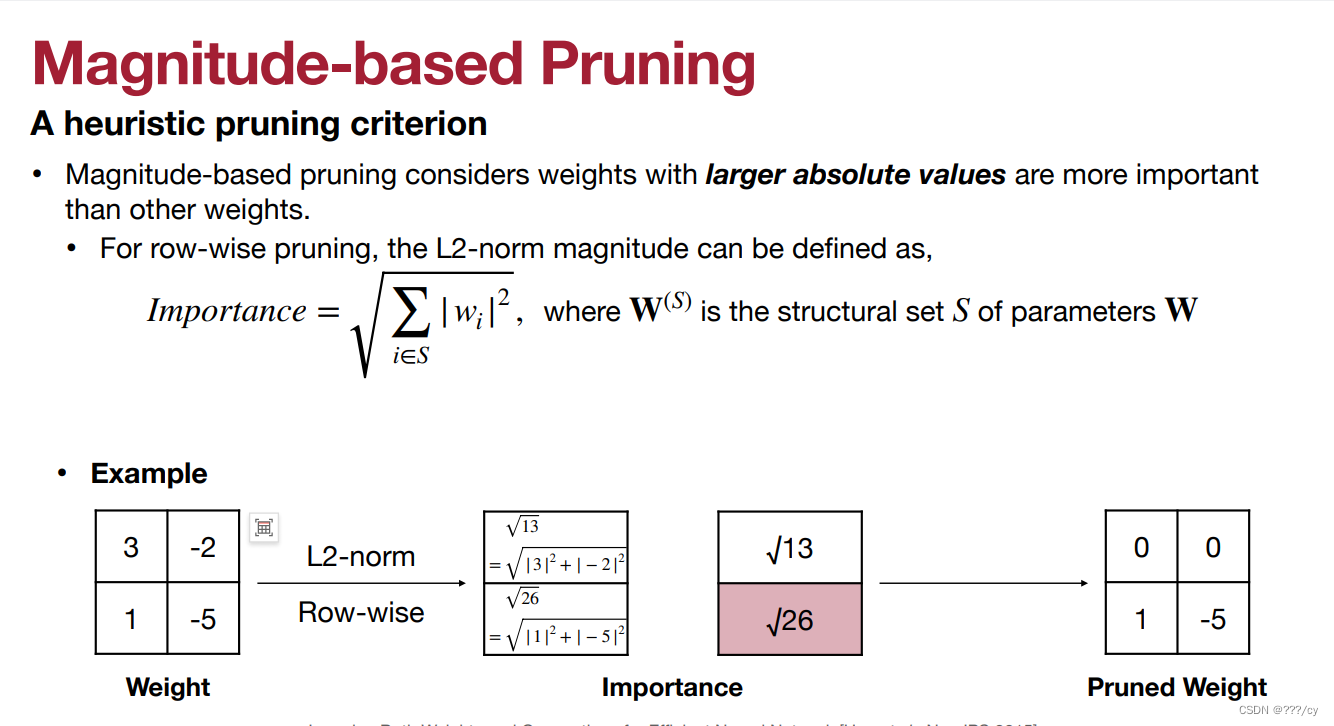
- 方法三:Lp-norm
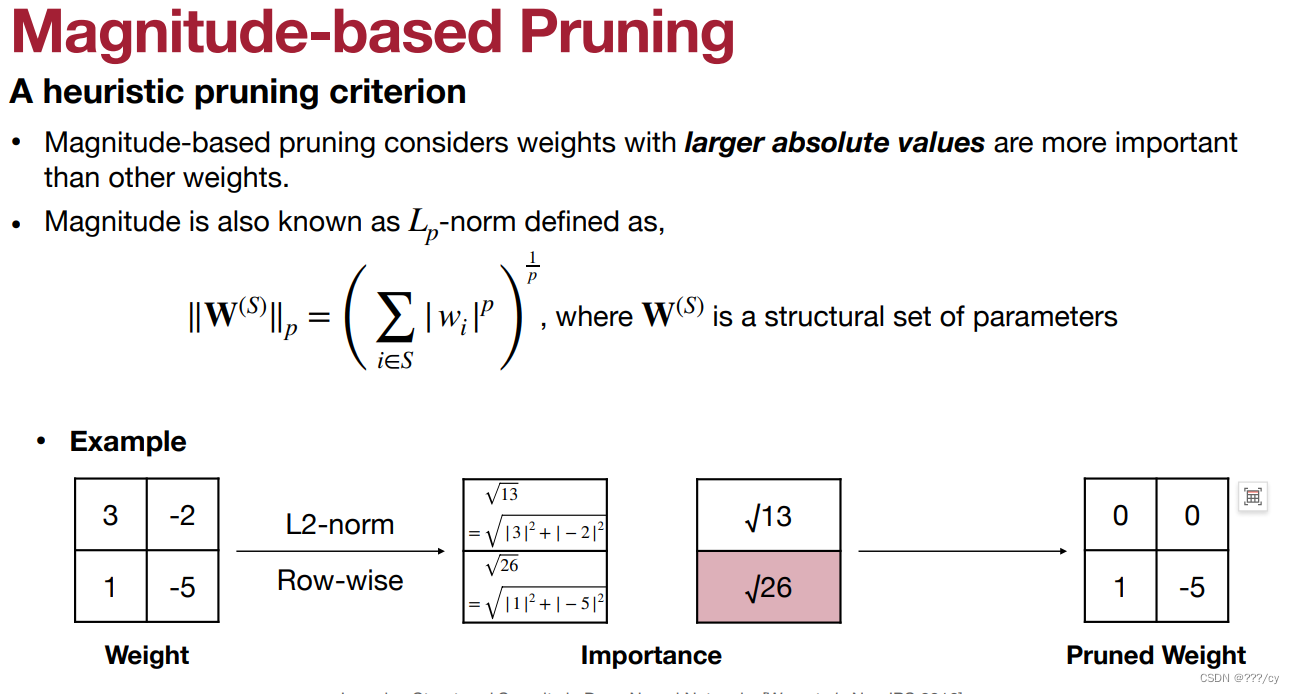
- 方法一:L1-norm
下面是基于权重大小的剪枝的基本原理和步骤:
-
权重排序: 首先,对神经网络中的所有权重进行排序,通常按绝对值大小进行排序,从最小到最大。
-
剪枝决策: 根据事先确定的剪枝比率或目标,选择要剪枝的权重。通常,可以通过设置一个剪枝比率来确定要保留的权重百分比。较小的权重将被标记为剪枝。
-
剪枝操作: 将被标记为剪枝的权重设置为零或删除它们,从而减小了模型的参数数量。这通常会导致模型稀疏化,即模型中许多权重为零。
-
微调和重训练: 通常需要对被剪枝的模型进行微调或重新训练,以部分恢复模型的性能。这可以通过在新的训练数据上进行额外的训练来实现。
- “Magnitude-based pruning” 的优点包括简单易行、有效减小模型大小、减少计算和内存需求。然而,它也可能导致较大的性能损失,因为一些绝对值较小但对模型泛化性能有一定贡献的权重也被剪枝了。因此,在实际应用中,通常需要进行谨慎的实验和调整,以平衡模型大小和性能之间的权衡。
此外,“Magnitude-based pruning” 通常结合其他剪枝技术,如结构化剪枝或重要性剪枝,以更好地保持模型性能。
对于CNN网络有没有更好的剪枝方法呢? 请看下面
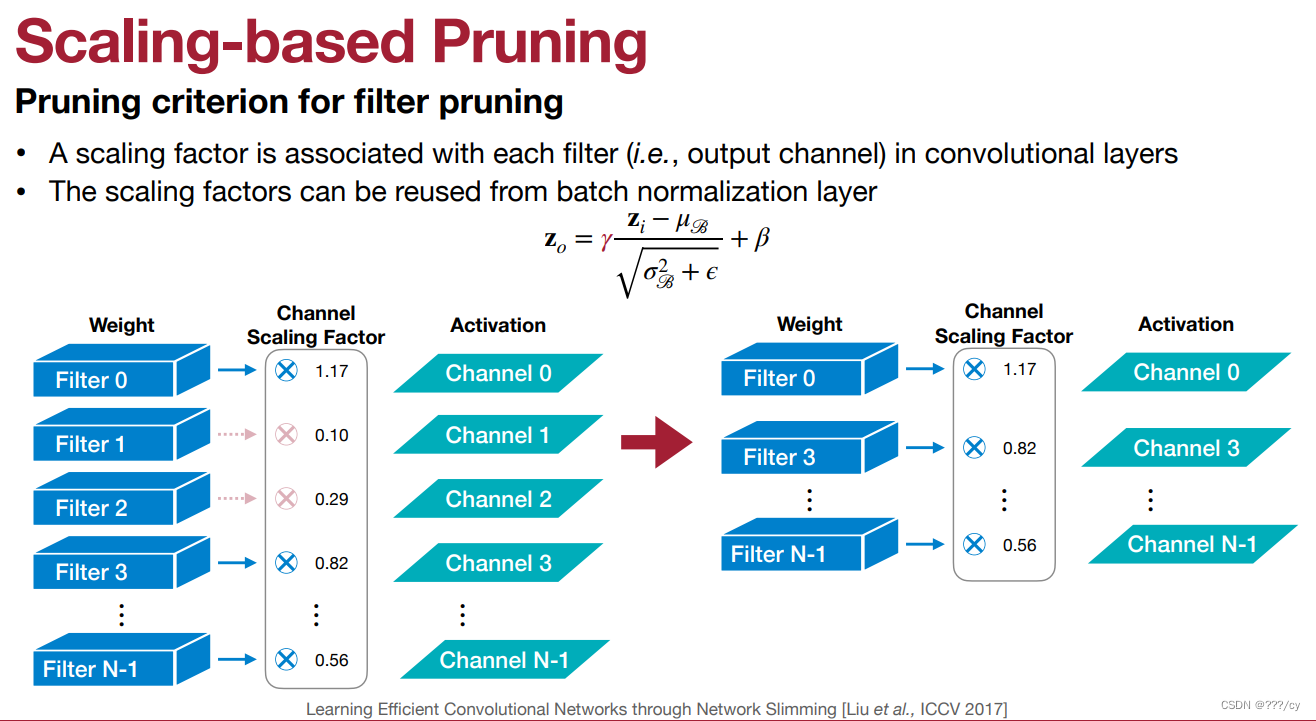
3.1.2 基于批量归一化中缩放因子的剪枝 (Scaling-based pruning) (network slimming)
-
A scaling factor is associated with each filter (i.e., output channel) in convolutional layers
• The scaling factor is multiplied to the output of that channel
• The scaling factors are trainable parameters -
“Scaling-based pruning”(基于缩放的剪枝),它基于权重的缩放因子来确定哪些权重应该被剪枝。通过考虑权重的相对重要性来减小模型的复杂性,同时最小化性能损失。基于缩放的剪枝通常与剪枝阈值结合使用,权重的缩放因子与阈值比较,如果权重的缩放因子低于阈值,则相应的权重将被剪枝。
下面是基于缩放的剪枝的基本原理和步骤:
1. Sparity Learning 的阶段: 用L1 / L2 正则化,目的是让 缩放因子 尽可能的接近零
2. Pruning: 剪掉缩放因子小的Filter

- 缩放因子是可以学习到的参数,也就是批量归一化中(Batch Normalization)可学习的那个参数。
- “Scaling-based pruning” 的优点是它可以更好地考虑权重的相对贡献,因此可以减小性能下降的风险。它在减小模型大小和复杂性方面也比一些其他简单的剪枝技术更有效。然而,选择适当的缩放因子和阈值仍然需要谨慎的调整和实验。
3.1.3 基于二阶导数的剪枝 (Second-Order-based Pruning)
“Second-Order-based Pruning” 方法会计算每个权重的梯度和二阶导数,通常使用海森矩阵(Hessian matrix)或近似方法来估计二阶导数。根据这些信息确定哪些权重应该被剪枝。通常情况下,梯度和二阶导数的绝对值越大,说明权重对于模型的贡献越大,因此更不容易被剪枝。
下面是基于二阶导数的剪枝的基本原理和步骤:


- 二阶导难以计算

1. 设置剪枝阈值: 确定一个剪枝阈值,该阈值决定了哪些参数应该被剪枝。通常,二阶导数的绝对值与阈值进行比较。
2. 剪枝决策: 对于每个参数,将其二阶导数的绝对值与剪枝阈值进行比较。如果二阶导数的绝对值低于阈值,则将该参数标记为要被剪枝。
3. 剪枝操作: 将被标记为剪枝的参数设置为零或删除它们,减小了模型的参数数量。
4. 微调和重训练: 通常需要对被剪枝的模型进行微调或重新训练,以部分恢复模型的性能。这可以通过在新的训练数据上进行额外的训练来实现。“Second-Order-based Pruning” 的优点在于它更精确地考虑了参数对模型的影响,因此可以减小性能下降的风险。它通常用于需要高度精细化剪枝的应用中,如在资源受限的环境中,需要最大程度地减小模型复杂性而又不损害性能。
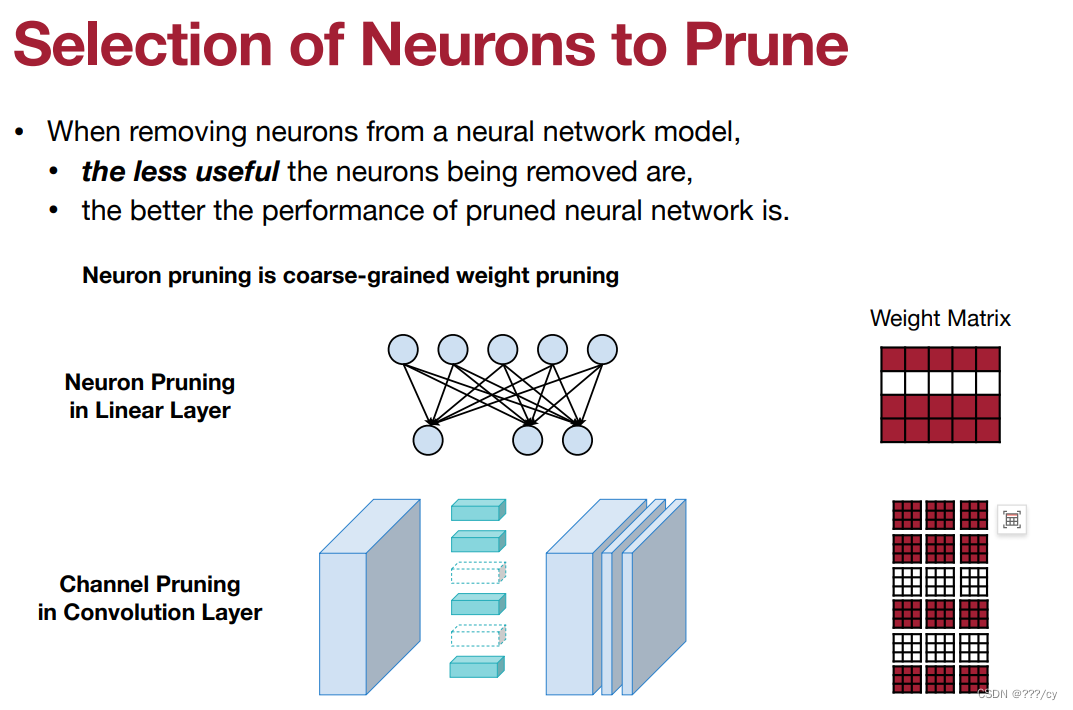
3.2 选择剪哪个神经元呢?( Selection of Neurons to Prune)(特征图剪枝:结构化剪枝)
- 比如在CNN中,Channel Pruning(通道剪枝):
- 通道剪枝是指移除卷积层中的某些通道(channel),从而减少特征图的维度。
- 通道剪枝通常会在训练期间根据某些准则(如特征图的重要性、特征图的稀疏性等)动态地选择要移除的通道。
- 如果某个特征图被剪枝了,那么与该特征图相关联的输入通道也会被剪枝,这样就会导致相应的卷积核的权重参数被置零或移除。
3.2.1 基于参数中的零值的比例的剪枝(Percentage-of-Zero-Based Pruning)(激活稀疏)
- 计算batch中,channle为0的占比,0占比多的channle就意味着这个filter没用,那就可以剪掉这个channle,剪掉这个filter了
- 有一种,利用output channle检测 Filter学习能力的感觉。
- output channle 学到了太多0 就意味着 这个filter 不行。
这种剪枝方法根据参数中的零值(或接近零值)的比例来决定哪些参数应该被剪枝。
以下是 “Percentage-of-Zero-Based Pruning” 的基本原理和步骤:
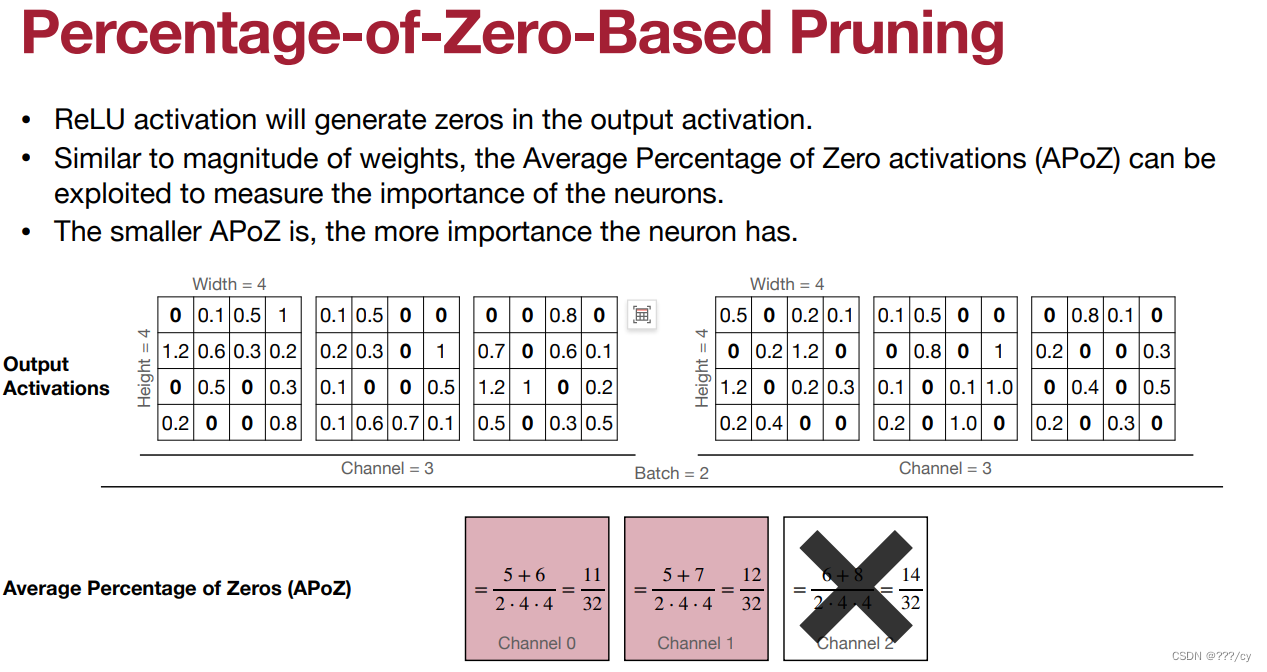
1. 计算零值比例: 对神经网络中的每个参数(通常是权重)计算零值或接近零值的比例。这可以通过将参数与一个接近零的阈值进行比较来实现,通常使用很小的阈值。
2. 设置剪枝比例阈值: 确定一个剪枝比例阈值,该阈值决定了哪些参数应该被剪枝。通常,参数的零值比例与阈值进行比较。
3. 剪枝决策: 对于每个参数,将其零值比例与剪枝比例阈值进行比较。如果零值比例高于阈值,说明该参数足够稀疏,将被标记为要被剪枝。
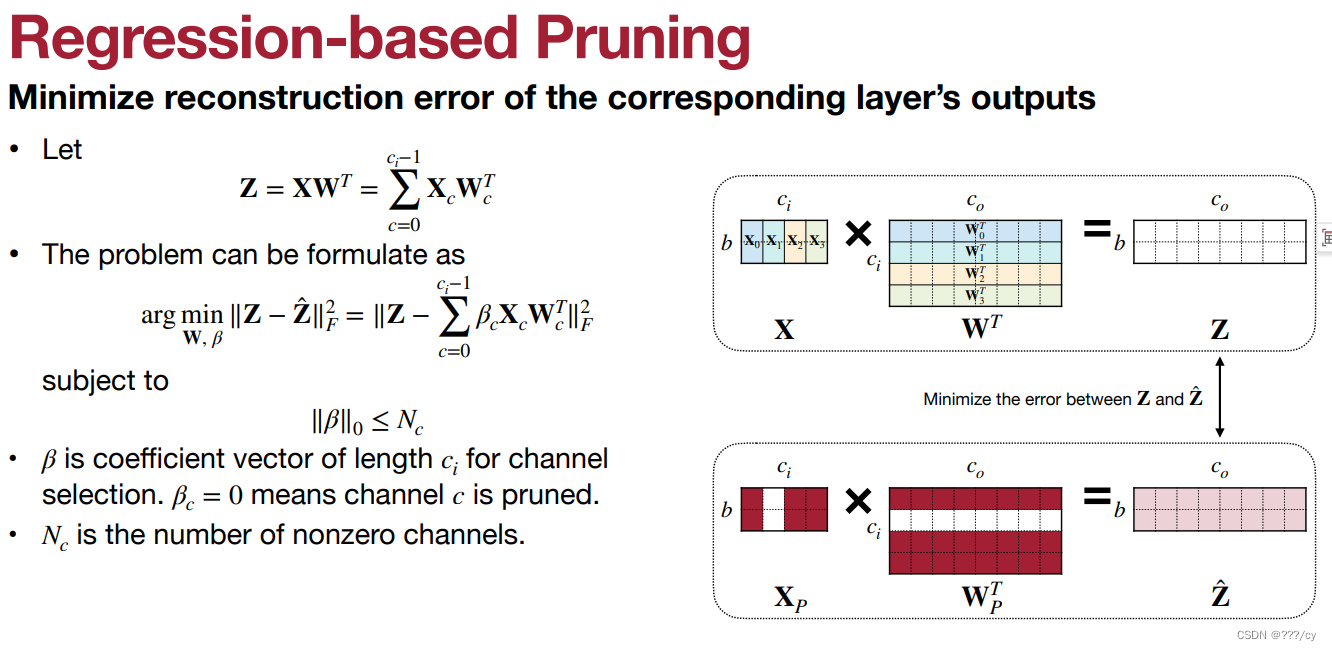
3.2.2 基于回归的剪枝 (Regression-based Pruning)
目标:减少Z, Z`之间的差距
3.3 小总结
4. 确定剪枝比率(Determine the Pruning Ratio)
如何确定每一层layer的剪枝比例呢?(How should we find per-layer pruning ratios?)
1. 分析每一层的敏感性 (Analyze the sensitivity of each layer)(Design by MIT Han)
We can perform sensitivity analysis to determine the per-layer pruning ratio
- 全连接层可以多剪枝,他并不敏感,剪枝多一些也不会影响他的accuracy
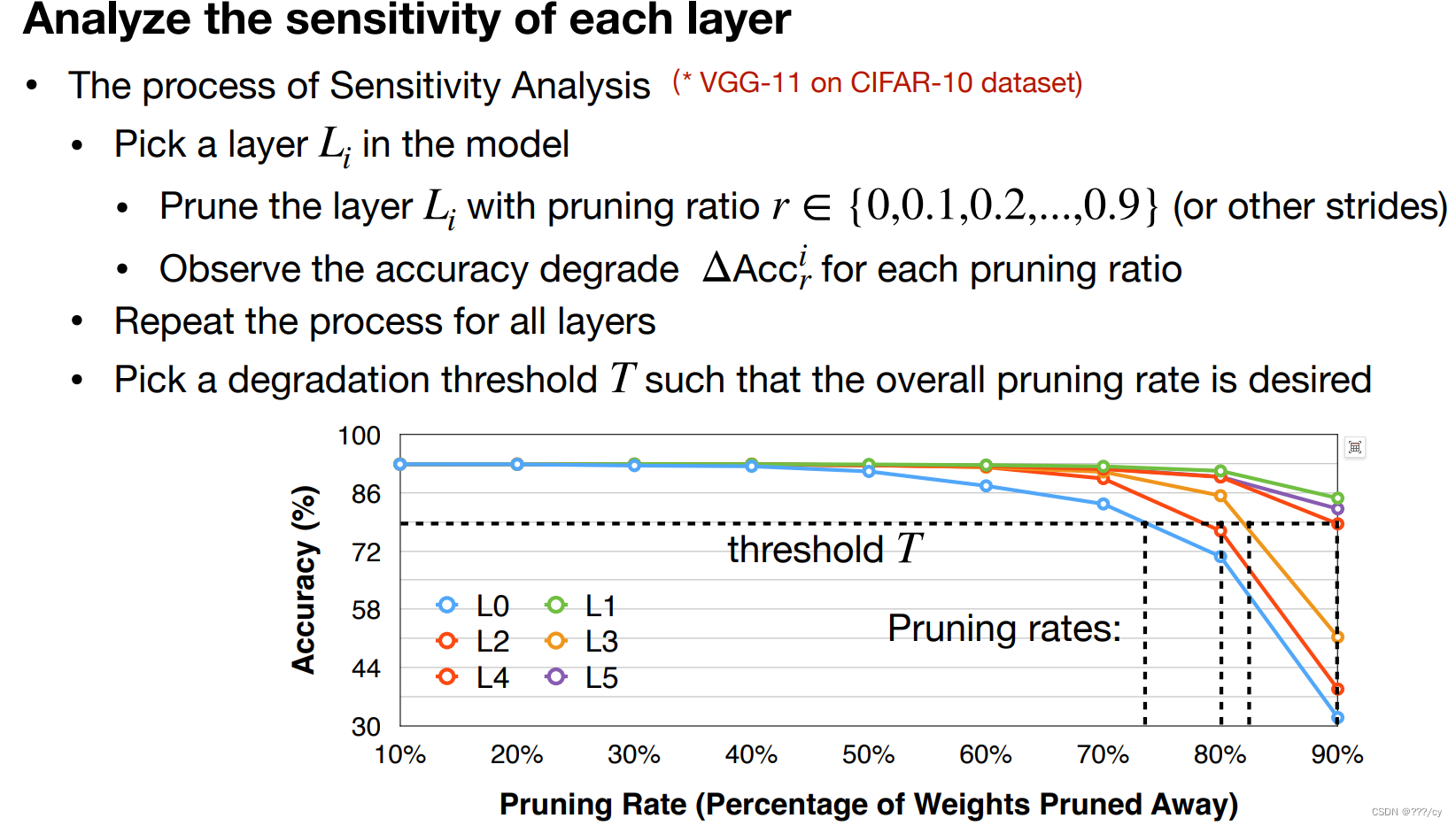
- 不是最优解,没有考虑到不同层之间的相互影响
2. AutoML(让强化学习模型去决定每一层压缩多少)
- 一种强化学习的方式,给一个总体的压缩量,让他去决定每一层压缩多少

3. NetAdapt(给一个全局的资源限制,例如latency,自动去找每一层剪枝的比例)
The goal of NetAdapt is to find a per-layer pruning ratio to meet a global resource constraint (e.g., latency, energy, …)
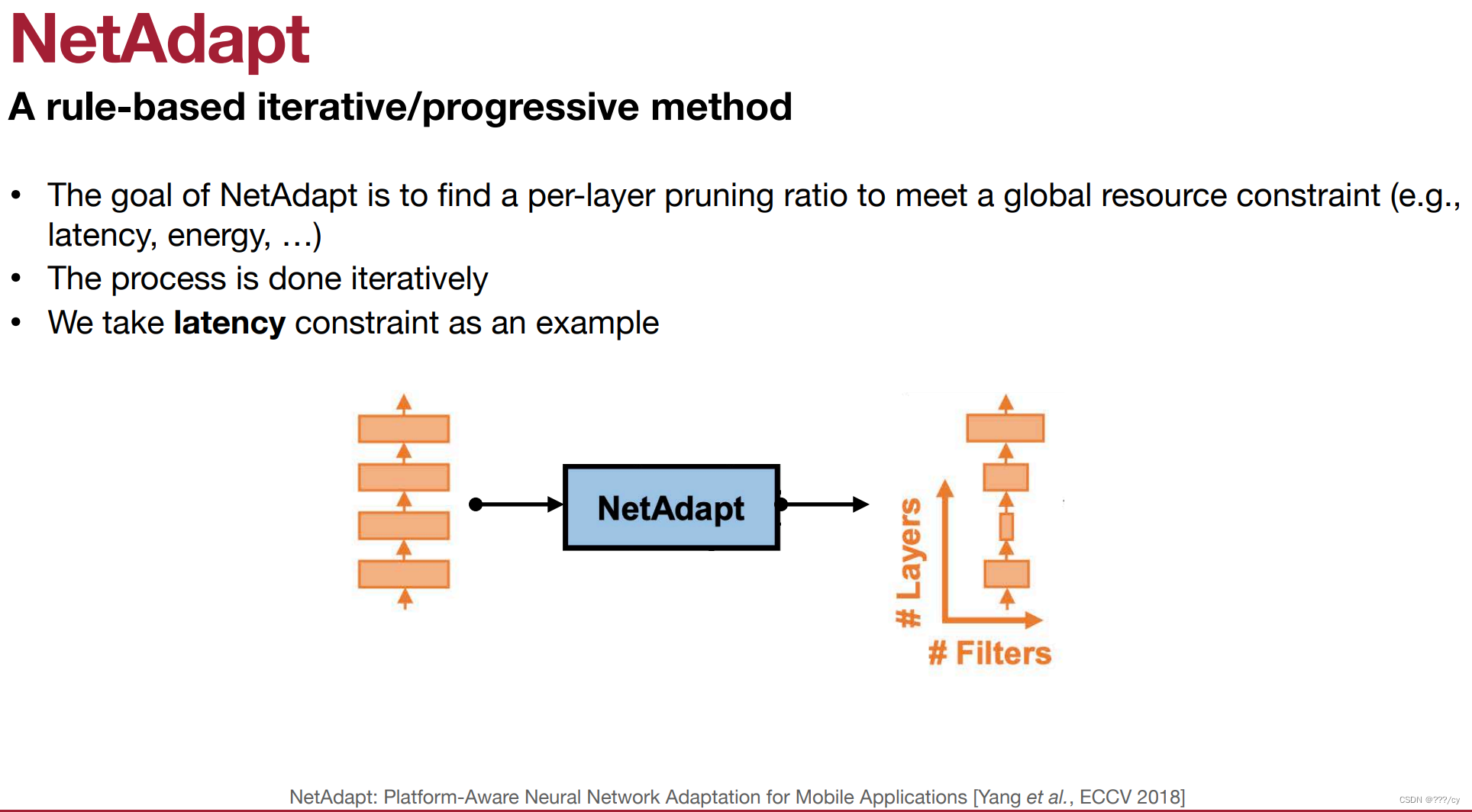
What should target sparsity be for each layer?
决定剪枝比率,即要剪掉的参数百分比。这是一个关键的超参数,平衡了模型大小的减小和性能保持。
探索不同的剪枝比率以及它们对模型性能的影响,以找到合适的权衡点。
5. Fine-tune/Train Pruned Neural Network 微调训练
How should we improve performance of pruned models?
在剪枝后,对模型进行微调或重新训练,以恢复性能的部分损失。
根据需要调整学习速率和其他超参数。用原学习率的1/10 ~ 1/100

















 1314
1314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









