






0、前言
0.1 课程链接:
《PyTorch深度学习实践》完结合集
有大佬已经写好了笔记:大佬的笔记
pytorch=0.4
0.2 课件下载地址:
链接:https://pan.baidu.com/s/1_J1f5VSyYl-Jj2qIuc1pXw
提取码:wyhu
1、多分类问题
输出
D:\Anaconda3\envs\env_pytorch04\python.exe "D:/3 刘二教程/第9节课 交叉熵损失做多分类.py"
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ../dataset/mnist/MNIST\raw\train-images-idx3-ubyte.gz
9913344it [00:06, 1589828.39it/s]
Extracting ../dataset/mnist/MNIST\raw\train-images-idx3-ubyte.gz to ../dataset/mnist/MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ../dataset/mnist/MNIST\raw\train-labels-idx1-ubyte.gz
29696it [00:00, 572730.77it/s]
Extracting ../dataset/mnist/MNIST\raw\train-labels-idx1-ubyte.gz to ../dataset/mnist/MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ../dataset/mnist/MNIST\raw\t10k-images-idx3-ubyte.gz
1649664it [00:01, 1061069.26it/s]
Extracting ../dataset/mnist/MNIST\raw\t10k-images-idx3-ubyte.gz to ../dataset/mnist/MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ../dataset/mnist/MNIST\raw\t10k-labels-idx1-ubyte.gz
5120it [00:00, 5120371.12it/s]
Extracting ../dataset/mnist/MNIST\raw\t10k-labels-idx1-ubyte.gz to ../dataset/mnist/MNIST\raw
本节使用softmax对minst数据集进行多分类
多分类的输出概率应该满足:
1、每个类别的概率≥0
2、加和=1
1.1 softmax的计算示例
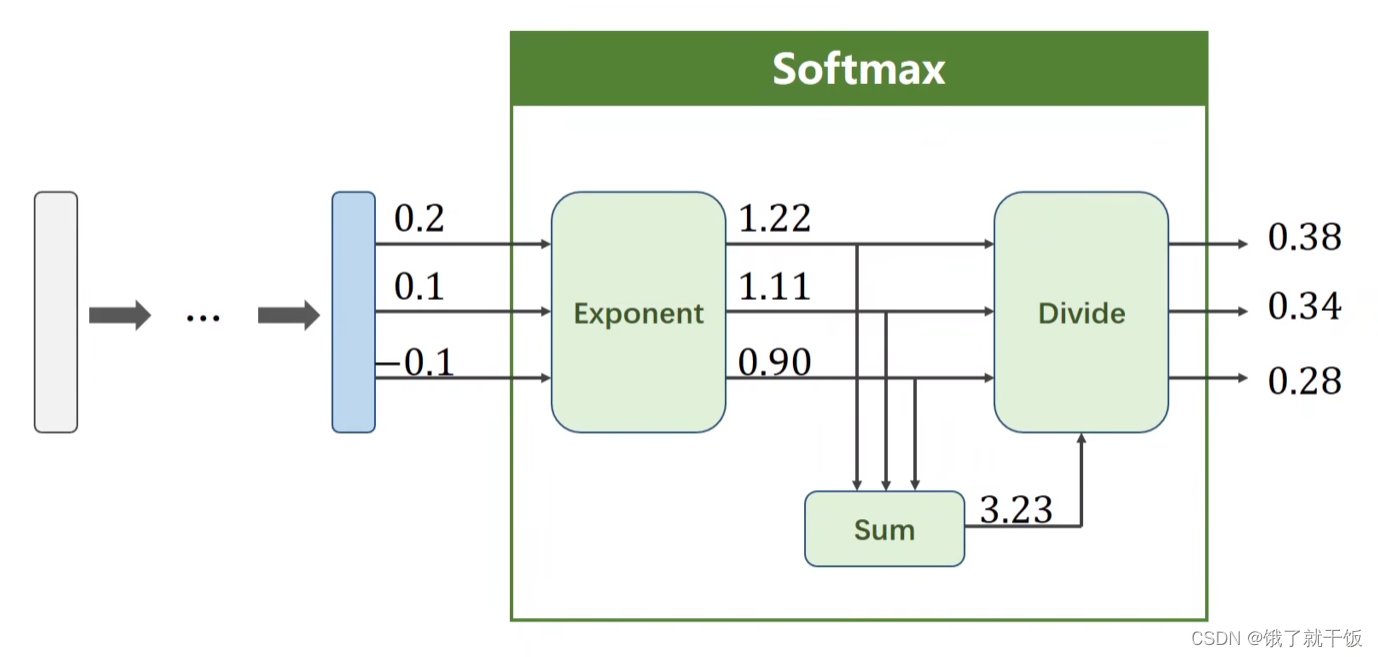
如果使用softmax之后损失函数如何定义?
如果是二分类,损失函数是:-(ylogy_hread+(1-y)log(1-y_head)),这个式子中只有一个是非零的,样本的标签是0,则第一项是0,如果标签是1,则第二项是0.
多分类的损失函数使用的是交叉熵损失函数:
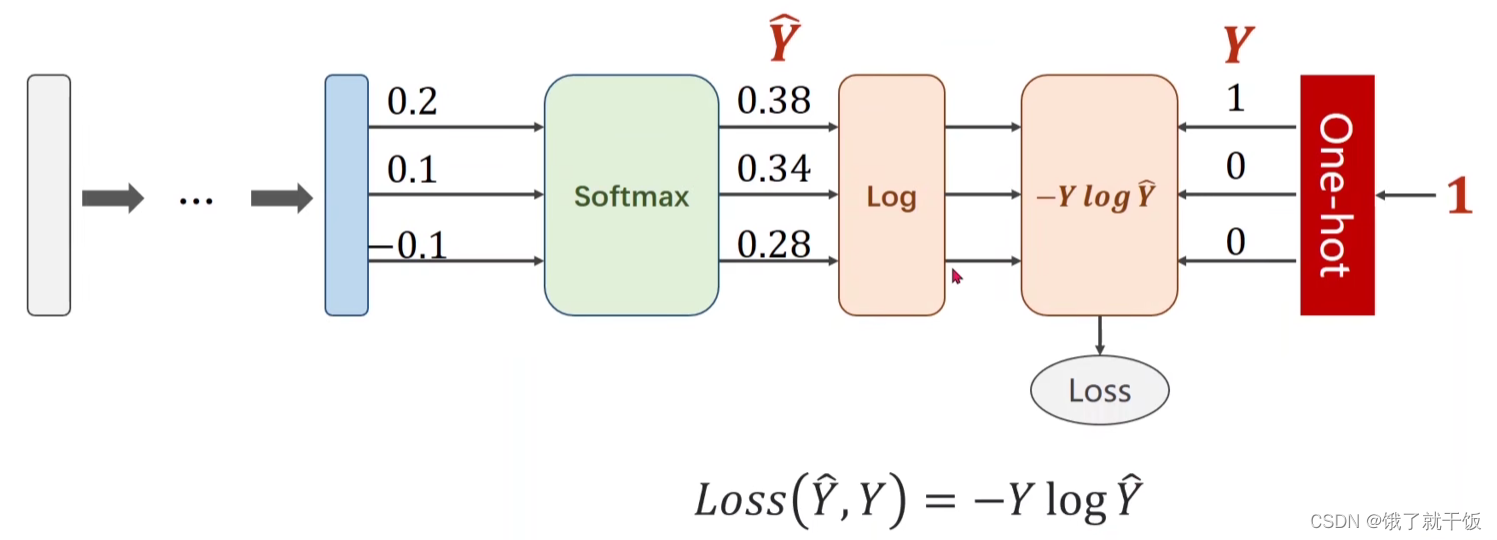
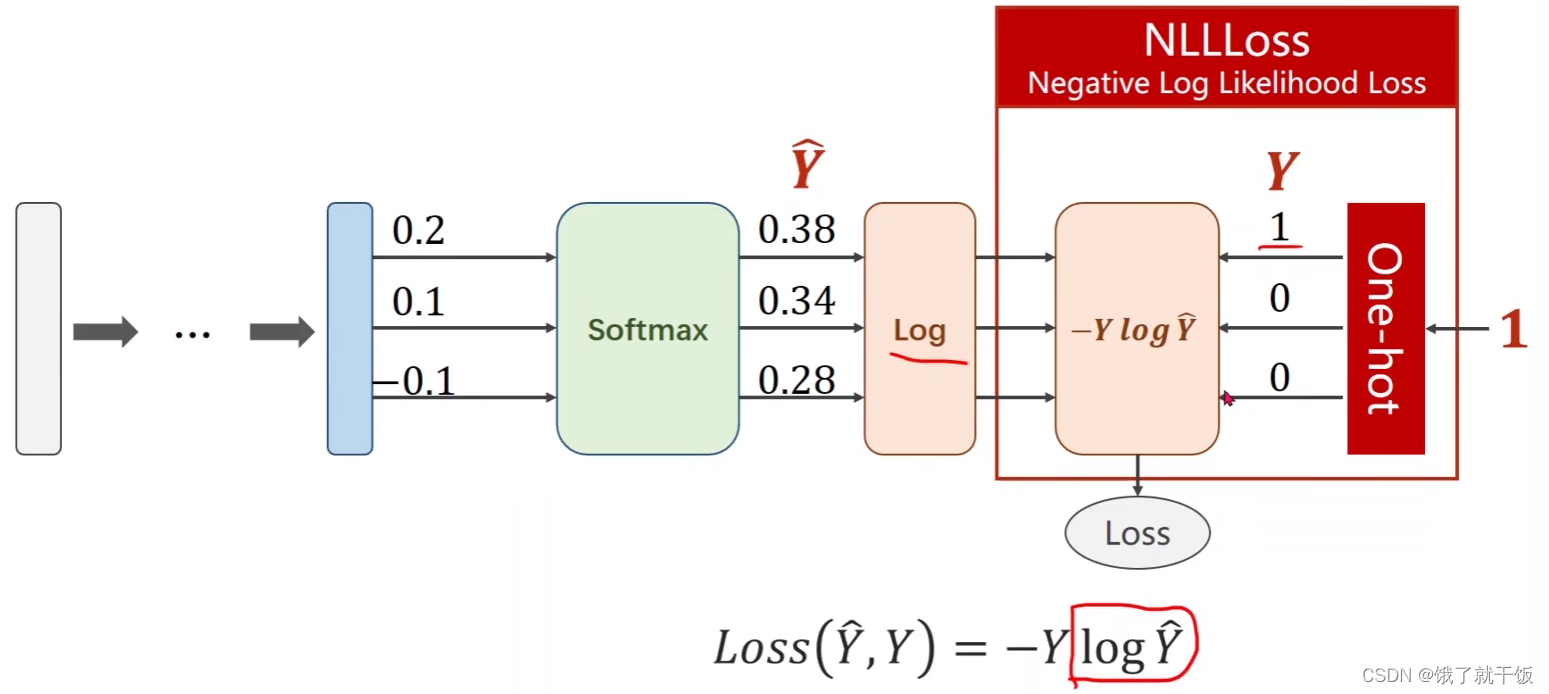
在pytorch中NLLLoss可以将损失和one-hot表示共同结合起来
使用交叉熵损失函数实现多分类的简单代码(未调包:Torch.nn.CrossEntropyLoss())
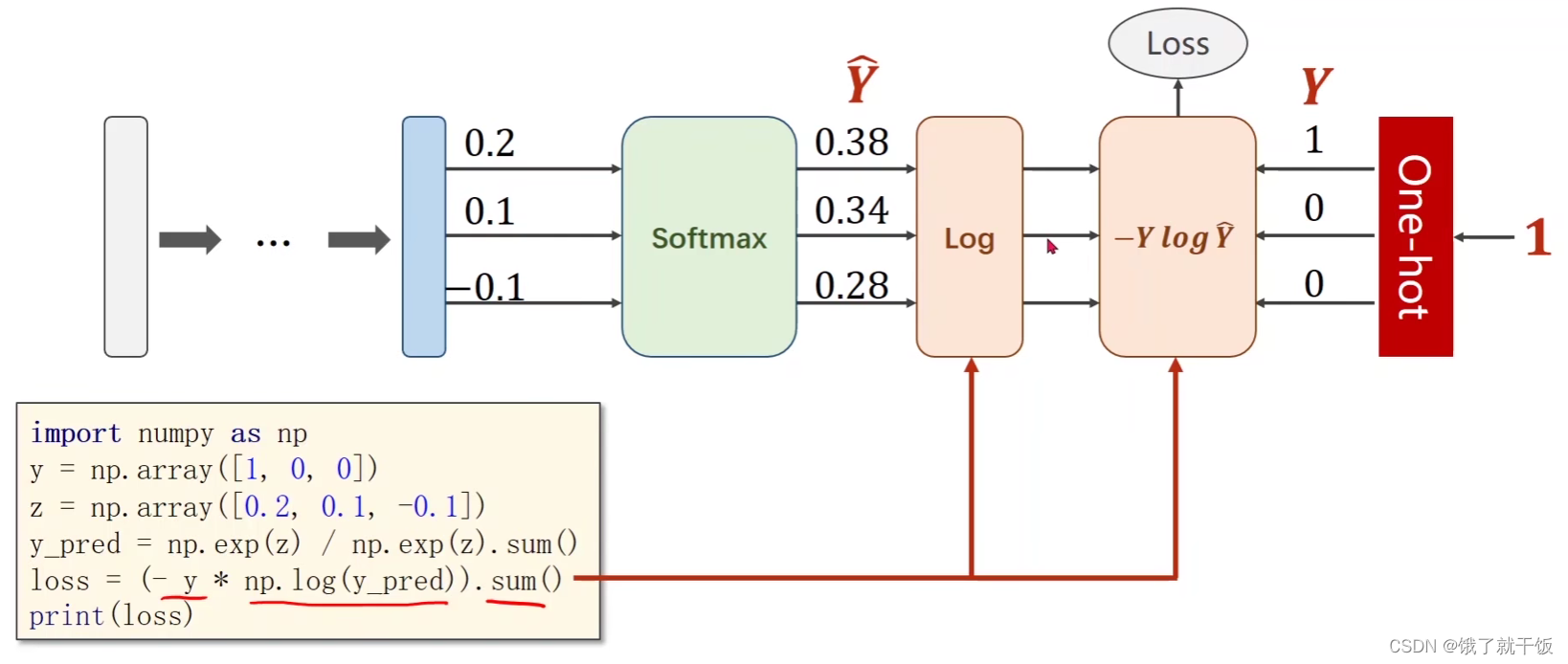
使用交叉熵损失函数实现多分类的简单代码(调包:Torch.nn.CrossEntropyLoss())
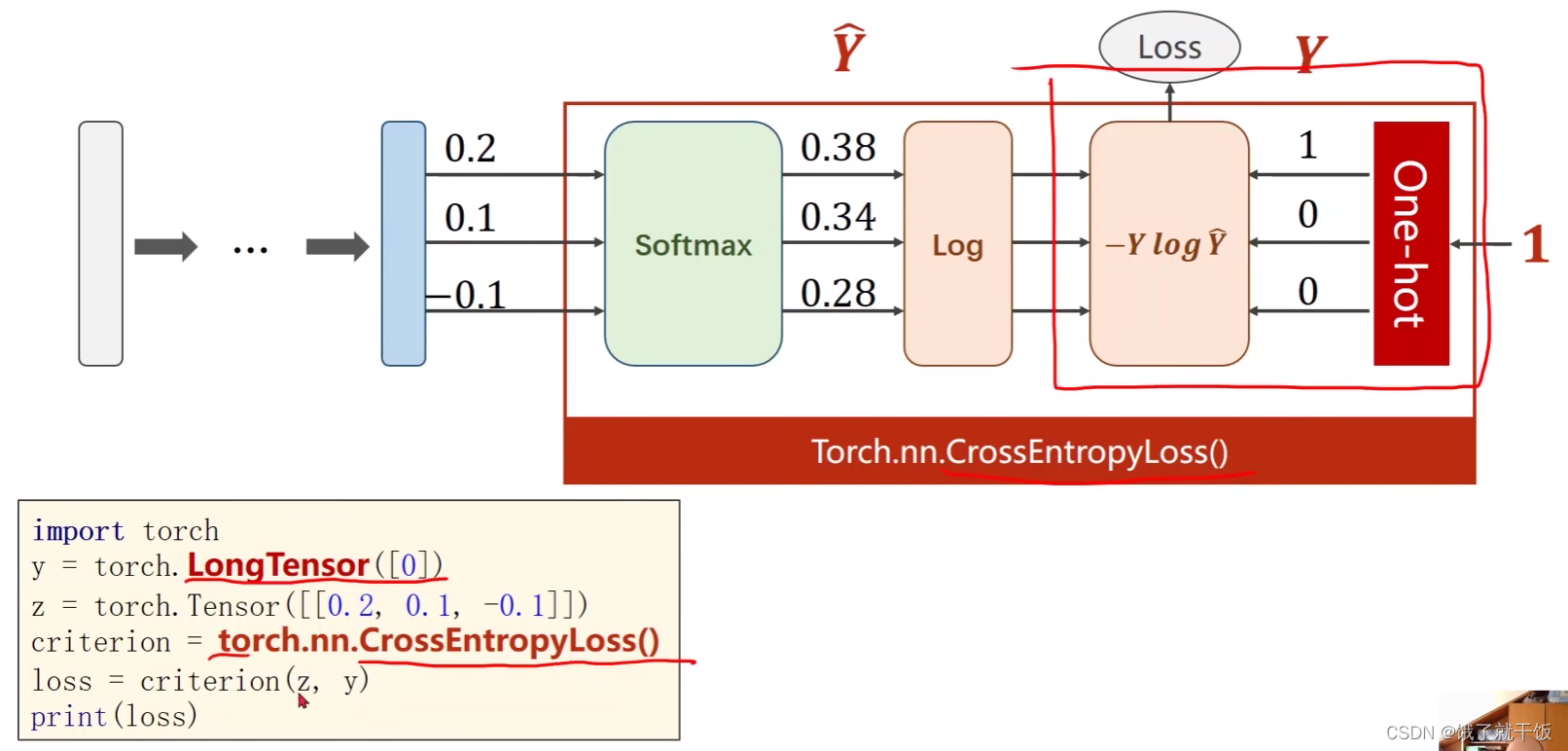
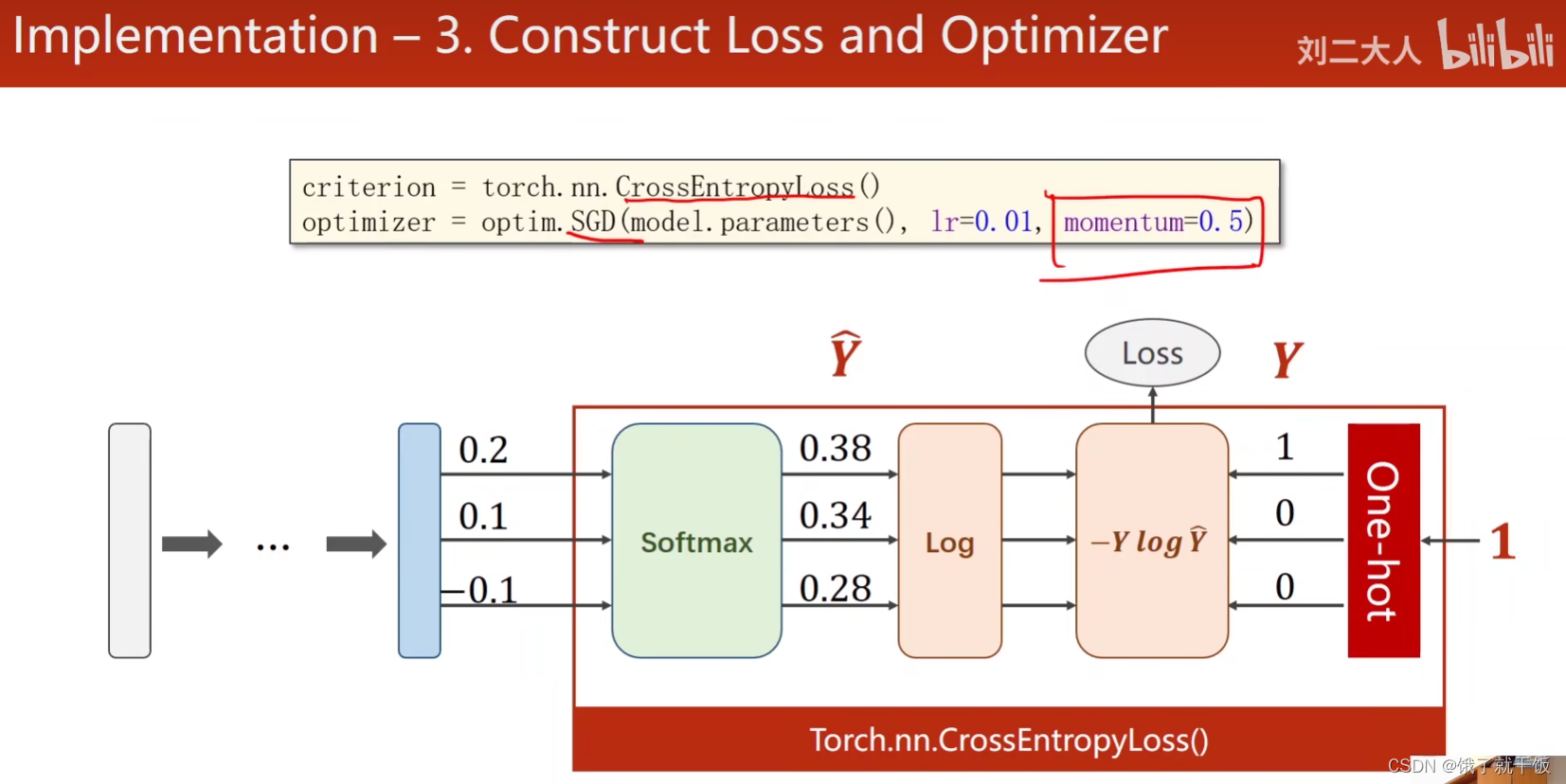
使用Torch.nn.CrossEntropyLoss()可以将sofotmax、log、损失函数、one-hot表示共同表示出来。
观察上图可知神经网络最后的一部分输出就不需要激活了,也就是直接输出0.2,0.1,-0.1。
上面写有one-hot的红色方框的意思是根据类别,one-hot方法会将该类别表示为one-hot表示。
代码中注意:y需要是长整型的张量。损失直接写成Torch.nn.CrossEntropyLoss()即可。
交叉熵损失做多分类的具体例子(调用Torch.nn.CrossEntropyLoss()):
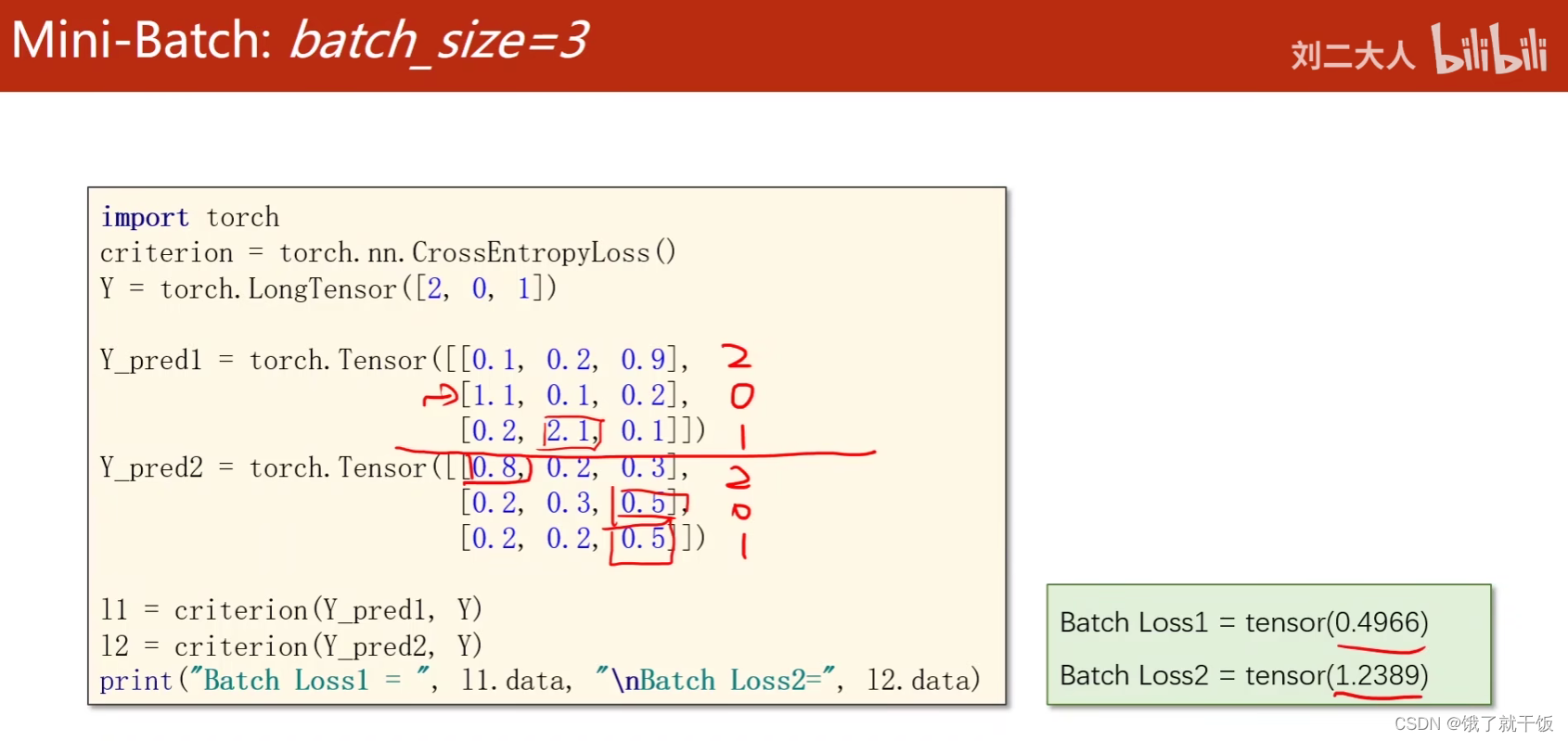
这个例子想说明啥?
想说明:对于预测正确的数据,那么交叉熵损失值小,预测错误的数据,对应的交叉熵损失值大。
图片中第一个批次的数据,3个数据的类别都预测正确了,第2个批次的数据,3个数据的类别都预测错误了,两个batch对应的损失值第1个小,损失值第2个大。
2、练习题9-1:看pytorch官方文档,了解NLLLoss与交叉熵损失之间的区别

练习的目的:读一下这个文档,看看NLLLoss与交叉熵损失到底有什么区别,一定把他们之间的计算关系给弄清楚了
3、MNIST数据集

图片作为输入:颜色越深,像素数值越小,将下面的图像的像素值[0,255]映射到[0,1]区间中,会得到下面的图像

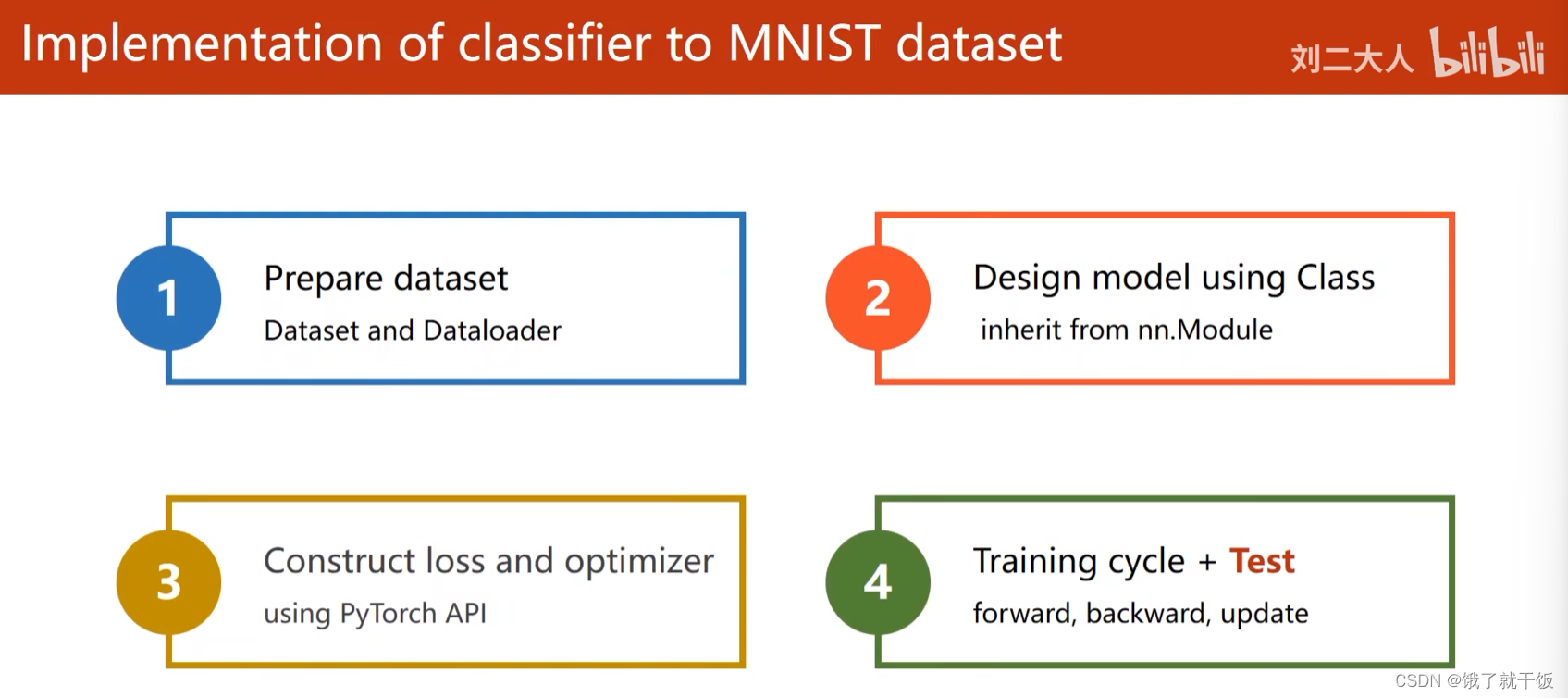
3.1 在MNIST上做多分类的步骤描述
总体步骤还是那4个步骤:
(1)准备数据集
(2)设计相应模型
(3)构造损失函数和优化器
(4)做一个训练循环
本次在MNIST上做多分类,会在最后训练的时候加上测试的步骤,
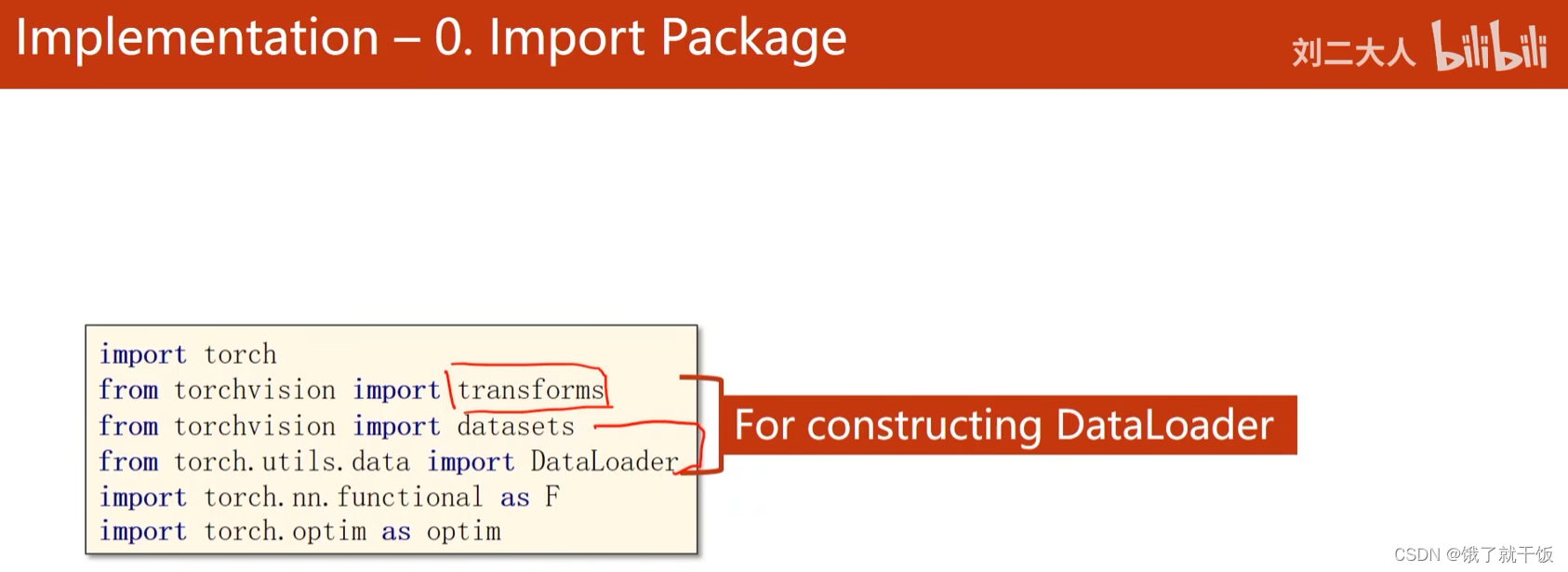
和数据集相关的包是datasets和dataloader,transforms是torchision中的包,它的主要作用是对图像数据进行各种各样的处理。

本次多分类任务将添加ReLU函数作为激活函数

torch.optim是优化器
3.2 第一步:准备数据集
准备数据集这一步骤比以往多了一个batchsize的设置,
另外还多了一个在数据集处理时候加上Transform的操作
在pytorch中读取图像的时候使用的是python的一个标准库PIL,现在基本上使用的是PIL的另一个实现Pillow来读取图像
神经网络有一个特点:希望输入进来的数据值比较小一点,最好数值为位于-1和1之间,并且满足正态分布。这样的数据对神经网络的训练是最有帮助的。因此需要一个工具将PIL读取的数据进行转换成神经网络比较舒服的数据方式。
3.2.1 灰度图和彩色图的区别、单通道与多通道的区别
PIL、OPenCV读进来的图像张量一般多是按照W*H*C的顺序
Pytorch是按照C*W*H的方式读取图片的
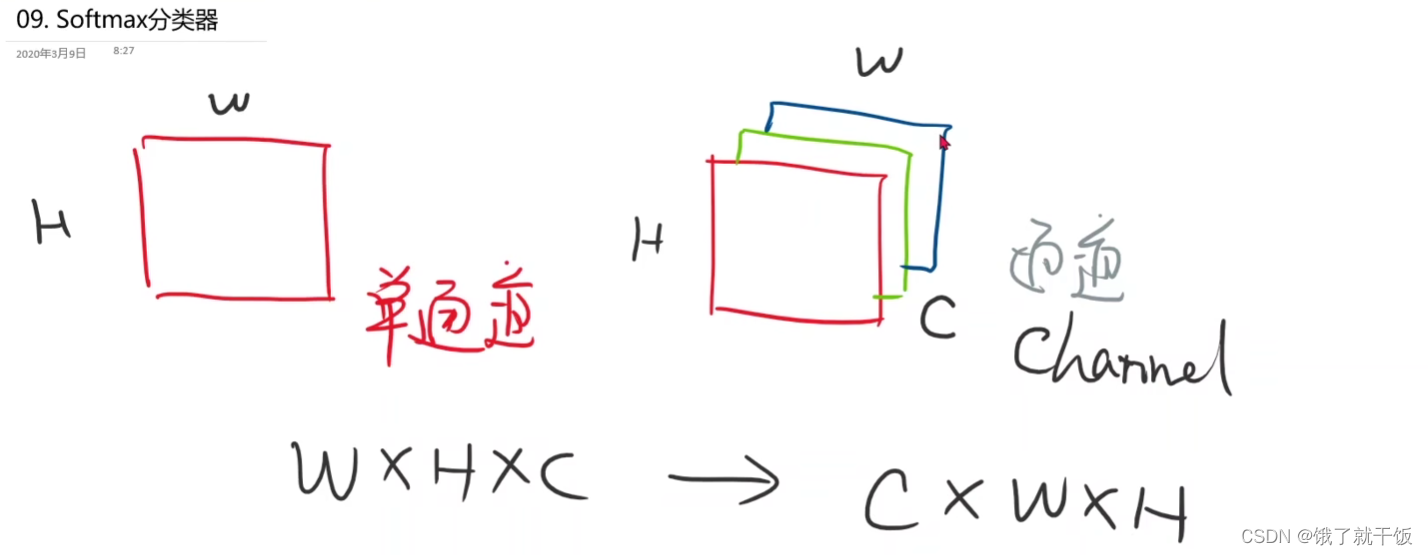
Transform中的ToTensor两个作用:
1、像素的数值压缩映射
2、单通道变成多通道,体现在维度多了个1维
就可以将2828的,像素值是{0,…,255}整数数值的图像转换成pytroch可以读取的张量的形式,转换后的张量的是128*28的,对应的像素值转换为介于[0,1]中间的浮点数

compose([每个元素])是一个类,这个类里面的中括号表示可以将括号里面一系列的对象构成一个类似于pipeline一样的处理,即如果读取了一张图片,先使用ToTensor将图片进行压缩映射变成一个张量,第二步是Transform.Normaliza归一化,0.1307是均值,0.3081是标准差。这两个数值是根据MNIST数据集的所有图像做了均值和标准差得来的。

3.2 第二步:设计模型
首先将(N12828)的张量转换成一个N-1*784矩阵,-1的意思在这里理解为一个自适应得到的一个数字。view是将改变张量的形状。
第一个线性层:input784维,output512维
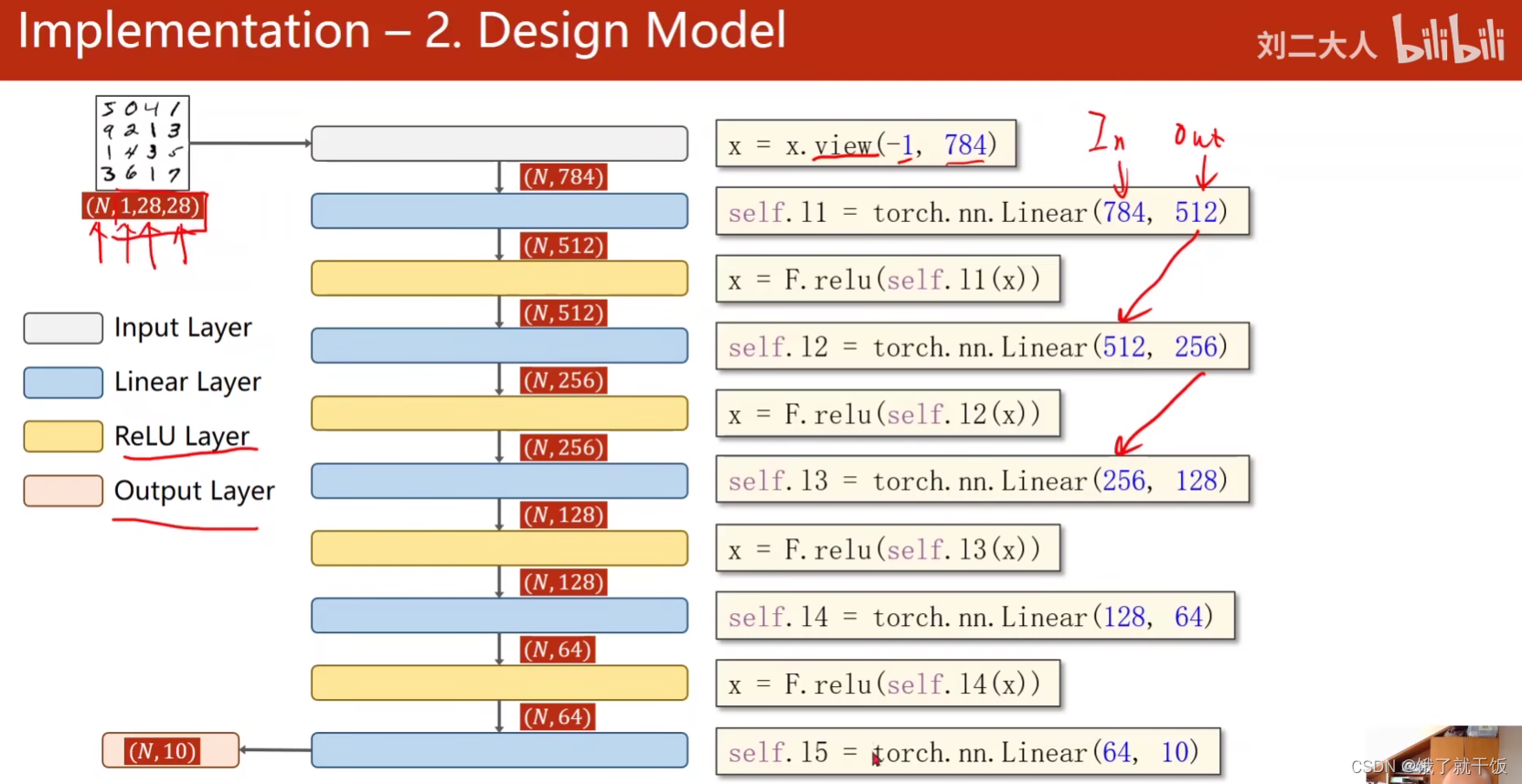
代码:

3.3 第三步:构建损失函数和优化器
优化器是带有冲量的SGD,冲量值为0.5
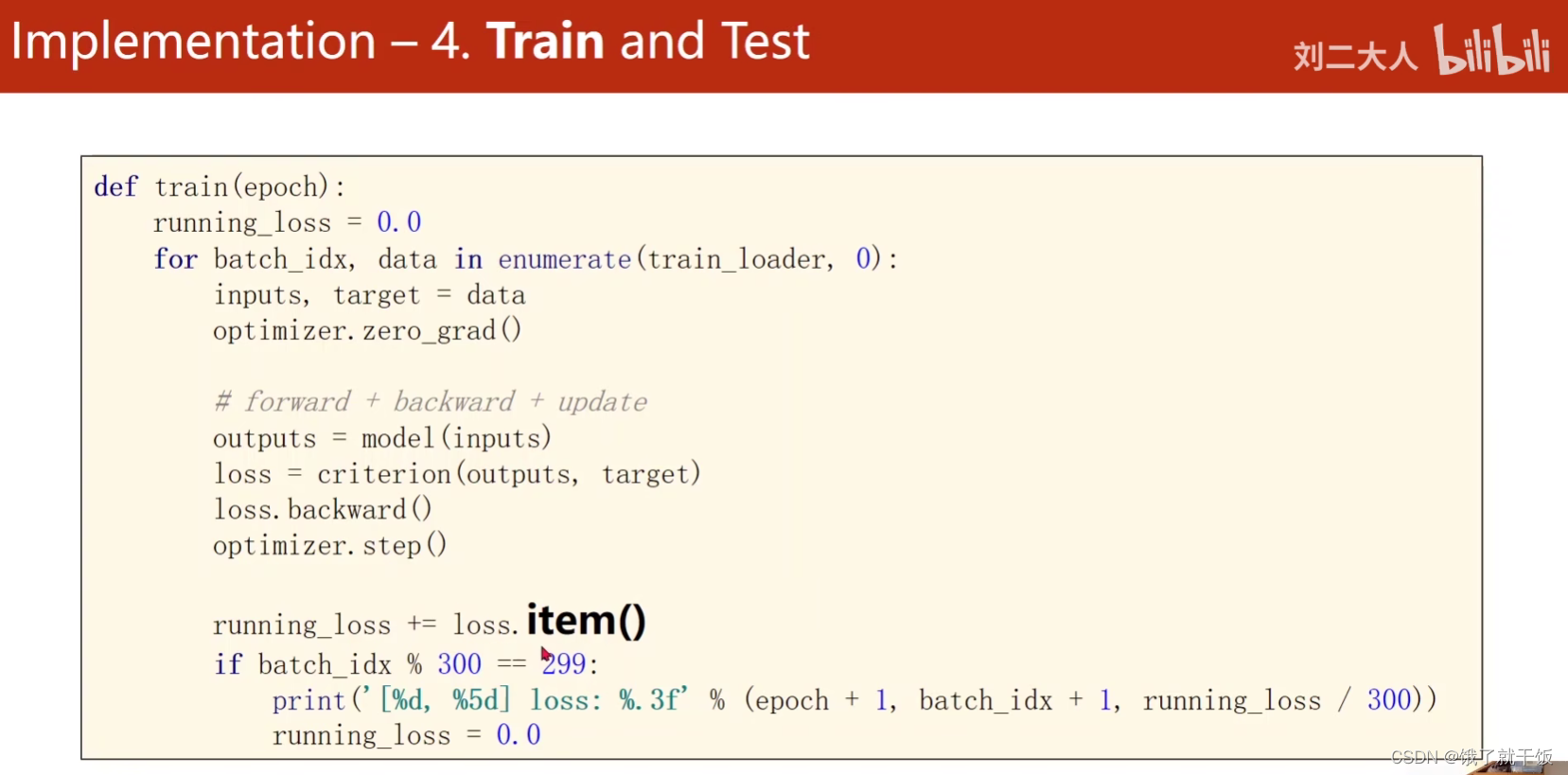
3.4 第四步:训练和测试
将一轮循环的训练写成函数
将一轮循环的测试也写成函数,test中不需要反向传播。
correct表示正确的有多少,total表示总数有多少
使用with torch.no_grad():这个代码,执行完该代码,那么这个代码块儿里面的代码就不会计算梯度。
_, predicted = torch.max(outputs.data,dim=1)
表示沿着第一个维度找最大值的索引,返回值有两个:1、每一行最大值 2、每一行最大值的索引
total += labels.size(0)
labels的size是N*1,这里N是样本的数量,label的每一行的值就是类别的标签
lables.size(0)就是取第0个元素
这一行代码我也有点看不懂,之后再细看吧
测试代码


为什么精度上不去?
1、全连接神经网络忽略对局部元素的关注,权重不够多
2、高抽象的特征关注不到
特征提取的方法如:FFT(傅里叶变换):对整张图像的特征提取
但是这种方法还是属于人工提取,接下来介绍的是自动提取特征的方法:CNN
4、练习9-2:实现一个kaggle上图像的多分类分类器
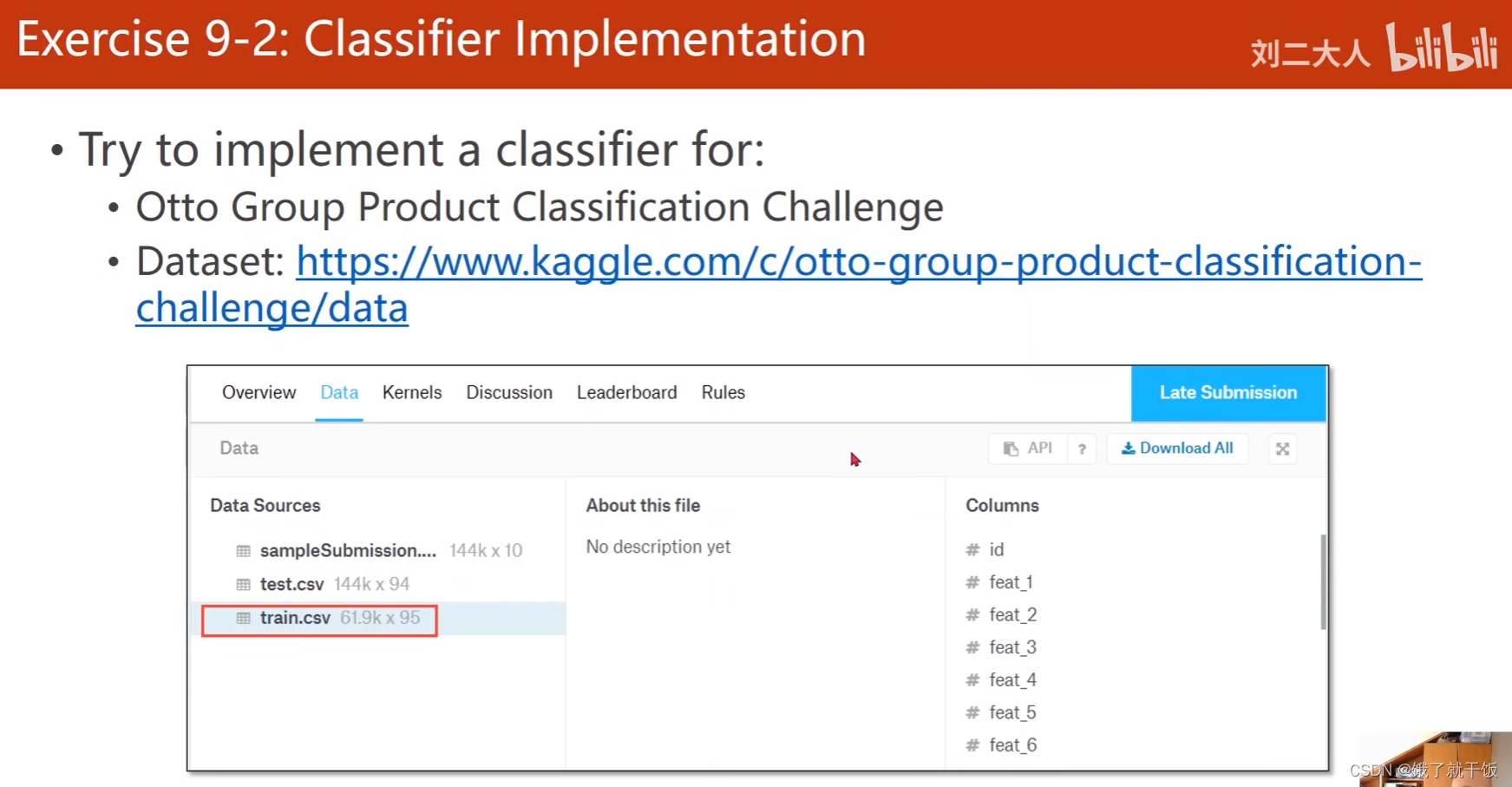
还是对图像的一个多分类任务。尝试使用softmax和交叉熵损失函数来进行分类。任务介绍和数据集在kaggle。

















 4471
4471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











