







论文(ICCV,fackbook):Segment Anything
目录
四、Segment Anything Model(模型/方法)
4.3 Lightweight mask decoder(轻量掩码解码器)
4.4 Losses and training(损失和训练)
五、Zero-Shot Transfer Experiments(零样本迁移实验)
5.1 Zero-Shot Single Point Valid Mask Evaluation(零样本单点有效掩码评估)
5.2 Zero-Shot Edge Detection(零样本边缘检测)
5.3 Zero-Shot Object Proposals(零样本候选区域识别)
7.4 Zero-Shot Instance Segmentation(零样本实例分割)
一、摘要
本文介绍了“Segment Anything (SA)”项目:这是一个针对图像分割的新任务、模型和数据集。
研究成果:使用高效的模型构建了迄今为止最大的分割数据集(远远超过),在1100万张授权和尊重隐私的图像上有超过10亿个掩码。该模型被设计和训练为可提示的,因此可以在新的图像分布和任务之间进行零样本迁移。在多个任务上评估了其性能,发现其零样本表现令人印象深刻——通常与或优于先前完全监督的结果。
二、引言
背景(网络规模数据集和大语言模型简介 + 基础模型的缺陷)—> 动机:寻求开发一个可扩展的模型,并使用一个能够实现强大泛化的任务在广泛的数据集上对其进行预训练。—> 引出首要解决的研究问题:
- 1. 什么任务将实现零样本泛化?
- 2. 对应的模型架构是什么?
- 3. 什么数据可以支持这个任务和模型?
—> 分别给出本文的解答:
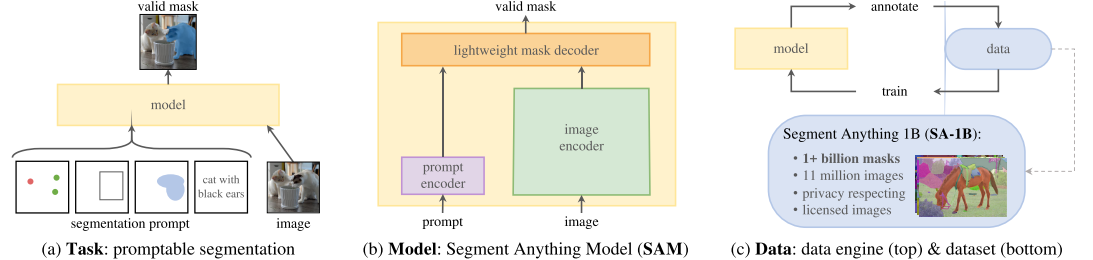
Task (§2). In NLP and more recently computer vision, foundation models are a promising development that can perform zero-shot and few-shot learning for new datasets and tasks often by using “prompting” techniques. Inspired by this line of work, we propose the promptable segmentation task, where the goal is to return a valid segmentation mask given any segmentation prompt (see Fig. 1a). A prompt simply specifies what to segment in an image, e.g., a prompt can include spatial or text information identifying an object. The requirement of a valid output mask means that even when a prompt is ambiguous and could refer to multiple objects (for example, a point on a shirt may indicate either the shirt or the person wearing it), the output should be a reasonable mask for at least one of those objects. We use the promptable segmentation task as both a pre-training objective and to solve general downstream segmentation tasks via prompt engineering.
任务 (§2)。在NLP和最近的计算机视觉中,基础模型是一个有希望的发展,可以通过使用"提示"技术对新数据集和任务进行零样本和少样本学习。受这一行工作的启发,本文提出了promptable分割任务,目标是在给定任何分割提示时返回有效的分割掩码(见图1a)。提示符只是指定要在图像中分割的内容,例如,提示符可以包括识别对象的空间或文本信息。有效输出掩码的要求意味着,即使提示是模糊的,并且可能指向多个对象(例如,衬衫上的一个点可能表示衬衫或穿着它的人),输出也应该是其中至少一个对象的合理掩码。将提示分割任务作为预训练目标,并通过提示工程解决一般的下游分割任务。
Model (§3). The promptable segmentation task and the goal of real-world use impose constraints on the model architecture. In particular, the model must support flexible prompts, needs to compute masks in amortized real-time to allow interactive use, and must be ambiguity-aware. Surprisingly, we find that a simple design satisfies all three constraints: a powerful image encoder computes an image embedding, a prompt encoder embeds prompts, and then the two information sources are combined in a lightweight mask decoder that predicts segmentation masks. We refer to this model as the Segment Anything Model, or SAM (see Fig. 1b). By separating SAM into an image encoder and a fast prompt encoder / mask decoder, the same image embedding can be reused (and its cost amortized) with different prompts. Given an image embedding, the prompt encoder and mask decoder predict a mask from a prompt in ∼50ms in a web browser. We focus on point, box, and mask prompts, and also present initial results with free-form text prompts. To make SAM ambiguity-aware, we design it to predict multiple masks for a single prompt allowing SAM to naturally handle ambiguity, such as the shirt vs. person example.
模型 (§3)。可提示的分割任务和现实世界使用的目标对模型架构施加了约束。特别是,该模型必须支持灵活的提示,需要实时摊销计算掩码以允许交互使用,并且必须能够感知歧义。一个简单的设计满足了所有三个约束:一个强大的图像编码器计算图像嵌入,一个提示编码器嵌入提示,然后将两个信息源组合在一个预测分割掩码的轻量级掩码解码器中 (SAM的三个组成结构)。我们把这个模型称为Segment Anything模型,简称SAM(见图1b)。通过将SAM分离为图像编码器和提示符快速编码器/掩码解码器,相同的图像嵌入可以在不同的提示符中重用(及其成本分摊)。给定图像嵌入,提示编码器和掩码解码器在web浏览器中从提示符预测掩码的时间为50ms。重点关注点、框和掩码提示,还用自由形式的文本提示呈现初步结果。为使SAM具有歧义性,设计了它来为单个提示预测多个 mask,使SAM能够自然地处理歧义,如衬衫和人的例子。
Data engine (§4). To achieve strong generalization to new data distributions, we found it necessary to train SAM on a large and diverse set of masks, beyond any segmentation dataset that already exists. While a typical approach for foundation models is to obtain data online [82], masks are not naturally abundant and thus we need an alternative strategy. Our solution is to build a “data engine”, i.e., we co-develop our model with model-in-the-loop dataset annotation (see Fig. 1c). Our data engine has three stages: assisted-manual, semi-automatic, and fully automatic. In the first stage, SAM assists annotators in annotating masks, similar to a classic interactive segmentation setup. In the second stage, SAM can automatically generate masks for a subset of objects by prompting it with likely object locations and annotators focus on annotating the remaining objects, helping increase mask diversity. In the final stage, we prompt SAM with a regular grid of foreground points, yielding on average ∼100 high-quality masks per image.
数据引擎(§4)。为了实现对新数据分布的强大泛化,我们发现有必要在一个庞大而多样化的掩码集上训练SAM,而不是现有的任何分割数据集。虽然基础模型的典型方法是在线获取数据,但掩码并不自然丰富,因此我们需要一种替代策略。我们的解决方案是建立一个“数据引擎”,即,本文协同开发模型与model-in-the-loop数据集注释(见图1c)。我们的数据引擎有三个阶段:辅助手动,半自动和全自动。在第一阶段,SAM协助注释者注释mask,类似于经典的交互式分割设置。在第二阶段,SAM可以通过提示可能的对象位置来自动生成对象子集的掩码,注释器专注于注释剩余的对象,帮助增加掩码多样性。在最后阶段,用前景点的规则网格提示SAM,平均每幅图像产生100个高质量的mask。(掩码半监督 —> 提示信息半监督 —> 前景点半监督)
—> 数据集SA-1B简介(包括来自11M授权和保护隐私图像的超过1B个掩码) —> 实验结果 (SAM从单个前景点产生高质量的掩模,通常仅略低于手动注释的ground truth)
三、Segment Anything Task(新任务)

每一列显示SAM从一个模糊点提示生成的3个有效掩码
本文从 NLP(自然语言处理)中获得灵感,将下一个token预测任务用于基础模型预训练,并通过提示工程解决各种下游任务。为了建立一个分割的基础模型,本文旨在定义一个具有类似能力的任务。
Task(任务)。首先,我们将提示的想法从NLP转换为分割,其中提示可以是一组前景/背景点,一个粗略的框或掩码,自由形式的文本,或者一般来说,任何表示图像中要分割的信息。因此,可提示的分割任务是在给出任何提示时返回一个有效的分割掩码。“有效”掩模的要求只是意味着,即使提示是模糊的,并且可能指向多个对象(例如,回想一下衬衫和人的例子,参见图3),输出也应该是这些对象中的至少一个的合理掩模。这个要求类似于期望语言模型对有歧义的提示输出连贯的响应。选择这项任务,是因为它带来了一种自然的预训练算法和一种通过提示将零样本迁移到下游分割任务的通用方法。
Pre-training(预训练)。提示分割任务提出了一种自然的预训练算法,该算法为每个训练样本模拟一系列提示(例如,点、框、掩码),并将模型的掩码预测与基本事实进行比较。本文从交互式分割中采用这种方法,尽管与交互式分割的目的是在足够的用户输入后最终预测有效掩码不同,本文的目标是始终为任何提示预测有效掩码,即使提示是模糊的。这确保了预训练模型在涉及歧义的用例中是有效的,包括我们的数据引擎要求的自动注释§4。我们注意到,在这项任务中表现良好具有挑战性,需要专门的建模和训练损失选择,我们在§3中讨论。
Zero-shot transfer(零样本迁移)。直观地说,我们的预训练任务赋予了模型在推理时对任何提示作出适当响应的能力,因此下游任务可以通过设计适当的提示来解决。例如,如果有一个猫的边界框检测器,则可以通过提供检测器的框输出作为我们模型的提示来解决猫实例分割。一般来说,一系列实际的分割任务都可以作为提示。除了自动数据集标注,在§7的实验中探索了五个不同的示例任务。
四、Segment Anything Model(模型/方法)
SAM有三个组件,如图所示:图像编码器,提示编码器 和 掩码解码器 。
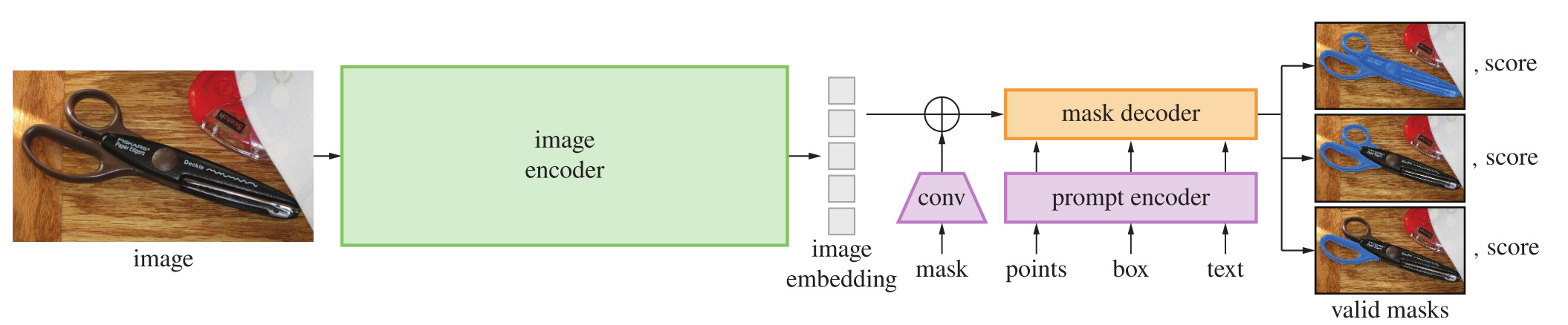
4.1 Image encoder(图像编码器)
结构:Image-Encoder是一个 Vision Transformer (Vision Transformer,ViT)结构,输入都是1024*1024分辨率的图像,最终输出 𝐶×𝑊×𝐻 维度的Embedding,ViT选择的是 MAE(Mixtures of Experts)预训练的结构。
过程:将图像缩放并对较短的一侧进行填充以获得分辨率为1024×1024的输入图像。(Embedding操作之后)因此,图像嵌入的大小为64×64。为了减少通道维度,先使用一个1×1卷积将通道数减少到256个,然后使用一个3×3卷积将通道数再次减少到256个。每个卷积操作之后都跟随一个批量归一化层。
部分代码:
class ImageEncoderViT(nn.Module):
def __init__(
self,
img_size: int = 1024,
patch_size: int = 16,
in_chans: int = 3,
embed_dim: int = 768,
depth: int = 12,
num_heads: int = 12,
mlp_ratio: float = 4.0,
out_chans: int = 256,
qkv_bias: bool = True,
norm_layer: Type[nn.Module] = nn.LayerNorm,
act_layer: Type[nn.Module] = nn.GELU,
use_abs_pos: bool = True,
use_rel_pos: bool = False,
rel_pos_zero_init: bool = True,
window_size: int = 0,
global_attn_indexes: Tuple[int, ...] = (),
) -> None:
"""
Args:
img_size (int): Input image size.
patch_size (int): Patch size.
in_chans (int): Number of input image channels.
embed_dim (int): Patch embedding dimension.
depth (int): Depth of ViT.
num_heads (int): Number of attention heads in each ViT block.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
norm_layer (nn.Module): Normalization layer.
act_layer (nn.Module): Activation layer.
use_abs_pos (bool): If True, use absolute positional embeddings.
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
window_size (int): Window size for window attention blocks.
global_attn_indexes (list): Indexes for blocks using global attention.
"""
super().__init__()
self.img_size = img_size
self.patch_embed = PatchEmbed(
kernel_size=(patch_size, patch_size),
stride=(patch_size, patch_size),
in_chans=in_chans,
embed_dim=embed_dim,
)
self.pos_embed: Optional[nn.Parameter] = None
if use_abs_pos:
# Initialize absolute positional embedding with pretrain image size.
self.pos_embed = nn.Parameter(
torch.zeros(1, img_size // patch_size, img_size // patch_size, embed_dim)
)
self.blocks = nn.ModuleList()
for i in range(depth):
block = Block(
dim=embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
norm_layer=norm_layer,
act_layer=act_layer,
use_rel_pos=use_rel_pos,
rel_pos_zero_init=rel_pos_zero_init,
window_size=window_size if i not in global_attn_indexes else 0,
input_size=(img_size // patch_size, img_size // patch_size),
)
self.blocks.append(block)
self.neck = nn.Sequential(
nn.Conv2d(
embed_dim,
out_chans,
kernel_size=1,
bias=False,
),
LayerNorm2d(out_chans),
nn.Conv2d(
out_chans,
out_chans,
kernel_size=3,
padding=1,
bias=False,
),
LayerNorm2d(out_chans),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.patch_embed(x)
if self.pos_embed is not None:
x = x + self.pos_embed
for blk in self.blocks:
x = blk(x)
x = self.neck(x.permute(0, 3, 1, 2))
return x
class Block(nn.Module):
"""Transformer blocks with support of window attention and residual propagation blocks"""
def __init__(
self,
dim: int,
num_heads: int,
mlp_ratio: float = 4.0,
qkv_bias: bool = True,
norm_layer: Type[nn.Module] = nn.LayerNorm,
act_layer: Type[nn.Module] = nn.GELU,
use_rel_pos: bool = False,
rel_pos_zero_init: bool = True,
window_size: int = 0,
input_size: Optional[Tuple[int, int]] = None,
) -> None:
"""
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads in each ViT block.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
norm_layer (nn.Module): Normalization layer.
act_layer (nn.Module): Activation layer.
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
window_size (int): Window size for window attention blocks. If it equals 0, then
use global attention.
input_size (tuple(int, int) or None): Input resolution for calculating the relative
positional parameter size.
"""
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
use_rel_pos=use_rel_pos,
rel_pos_zero_init=rel_pos_zero_init,
input_size=input_size if window_size == 0 else (window_size, window_size),
)
self.norm2 = norm_layer(dim)
self.mlp = MLPBlock(embedding_dim=dim, mlp_dim=int(dim * mlp_ratio), act=act_layer)
self.window_size = window_size
def forward(self, x: torch.Tensor) -> torch.Tensor:
shortcut = x
x = self.norm1(x)
# Window partition
if self.window_size > 0:
H, W = x.shape[1], x.shape[2]
x, pad_hw = window_partition(x, self.window_size)
x = self.attn(x)
# Reverse window partition
if self.window_size > 0:
x = window_unpartition(x, self.window_size, pad_hw, (H, W))
x = shortcut + x
x = x + self.mlp(self.norm2(x))
return x
4.2 Prompt encoder(提示编码器)
提示类别:稀疏(点、框、文本)和 密集(掩码)。
稀疏提示(稀疏提示被映射为256维的向量嵌入):
- 点:提示 “点” 被表示为位置编码和两个学习嵌入中的一个的总和,这两个嵌入表明该点是在前景还是背景中。
- 框(用一个嵌入对来表示一个提示 “框”):
- (1)其左上角的位置编码用表示“左上角”的学习嵌入求和。
- (2)相同的结构,但使用表示“右下角”的学习嵌入。
- 文本:最后,为了表示自由格式的提示 “文本” ,本文使用 CLIP 中的文本编码器。
密集提示(掩码 ):首先,输入分辨率比图像低4倍的掩码,然后使用两个2×2,步长为2,输出通道分别为4和16的卷积缩小额外的4倍。最后的1×1卷积将通道维度映射到256。(每一层由GELU激活和归一化分开。然后按元素添加掩模和图像嵌入。如果没有掩码提示,则将表示 “无掩码” 的学习嵌入添加到每个图像嵌入位置。)
代码:
(示例代码中并没有关于文本提示的处理过程)
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import numpy as np
import torch
from torch import nn
from typing import Any, Optional, Tuple, Type
from .common import LayerNorm2d
class PromptEncoder(nn.Module):
def __init__(
self,
embed_dim: int,
image_embedding_size: Tuple[int, int],
input_image_size: Tuple[int, int],
mask_in_chans: int,
activation: Type[nn.Module] = nn.GELU,
) -> None:
"""
Encodes prompts for input to SAM's mask decoder.
Arguments:
embed_dim (int): The prompts' embedding dimension
image_embedding_size (tuple(int, int)): The spatial size of the
image embedding, as (H, W).
input_image_size (int): The padded size of the image as input
to the image encoder, as (H, W).
mask_in_chans (int): The number of hidden channels used for
encoding input masks.
activation (nn.Module): The activation to use when encoding
input masks.
"""
super().__init__()
self.embed_dim = embed_dim
self.input_image_size = input_image_size
self.image_embedding_size = image_embedding_size
self.pe_layer = PositionEmbeddingRandom(embed_dim // 2)
self.num_point_embeddings: int = 4 # pos/neg point + 2 box corners
point_embeddings = [nn.Embedding(1, embed_dim) for i in range(self.num_point_embeddings)]
self.point_embeddings = nn.ModuleList(point_embeddings)
self.not_a_point_embed = nn.Embedding(1, embed_dim)
self.mask_input_size = (4 * image_embedding_size[0], 4 * image_embedding_size[1])
self.mask_downscaling = nn.Sequential(
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans // 4),
activation(),
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans),
activation(),
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
)
self.no_mask_embed = nn.Embedding(1, embed_dim)
def get_dense_pe(self) -> torch.Tensor:
"""
Returns the positional encoding used to encode point prompts,
applied to a dense set of points the shape of the image encoding.
Returns:
torch.Tensor: Positional encoding with shape
1x(embed_dim)x(embedding_h)x(embedding_w)
"""
return self.pe_layer(self.image_embedding_size).unsqueeze(0)
def _embed_points(
self,
points: torch.Tensor,
labels: torch.Tensor,
pad: bool,
) -> torch.Tensor:
"""Embeds point prompts."""
points = points + 0.5 # Shift to center of pixel
if pad:
padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device)
padding_label = -torch.ones((labels.shape[0], 1), device=labels.device)
points = torch.cat([points, padding_point], dim=1)
labels = torch.cat([labels, padding_label], dim=1)
point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size)
point_embedding[labels == -1] = 0.0
point_embedding[labels == -1] += self.not_a_point_embed.weight
point_embedding[labels == 0] += self.point_embeddings[0].weight
point_embedding[labels == 1] += self.point_embeddings[1].weight
return point_embedding
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
"""Embeds box prompts."""
boxes = boxes + 0.5 # Shift to center of pixel
coords = boxes.reshape(-1, 2, 2)
corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size)
corner_embedding[:, 0, :] += self.point_embeddings[2].weight
corner_embedding[:, 1, :] += self.point_embeddings[3].weight
return corner_embedding
def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:
"""Embeds mask inputs."""
mask_embedding = self.mask_downscaling(masks)
return mask_embedding
def _get_batch_size(
self,
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
boxes: Optional[torch.Tensor],
masks: Optional[torch.Tensor],
) -> int:
"""
Gets the batch size of the output given the batch size of the input prompts.
"""
if points is not None:
return points[0].shape[0]
elif boxes is not None:
return boxes.shape[0]
elif masks is not None:
return masks.shape[0]
else:
return 1
def _get_device(self) -> torch.device:
return self.point_embeddings[0].weight.device
def forward(
self,
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
boxes: Optional[torch.Tensor],
masks: Optional[torch.Tensor],
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Embeds different types of prompts, returning both sparse and dense
embeddings.
Arguments:
points (tuple(torch.Tensor, torch.Tensor) or none): point coordinates
and labels to embed.
boxes (torch.Tensor or none): boxes to embed
masks (torch.Tensor or none): masks to embed
Returns:
torch.Tensor: sparse embeddings for the points and boxes, with shape
BxNx(embed_dim), where N is determined by the number of input points
and boxes.
torch.Tensor: dense embeddings for the masks, in the shape
Bx(embed_dim)x(embed_H)x(embed_W)
"""
bs = self._get_batch_size(points, boxes, masks)
sparse_embeddings = torch.empty((bs, 0, self.embed_dim), device=self._get_device())
if points is not None:
coords, labels = points
point_embeddings = self._embed_points(coords, labels, pad=(boxes is None))
sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1)
if boxes is not None:
box_embeddings = self._embed_boxes(boxes)
sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1)
if masks is not None:
dense_embeddings = self._embed_masks(masks)
else:
dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand(
bs, -1, self.image_embedding_size[0], self.image_embedding_size[1]
)
return sparse_embeddings, dense_embeddings
class PositionEmbeddingRandom(nn.Module):
"""
Positional encoding using random spatial frequencies.
"""
def __init__(self, num_pos_feats: int = 64, scale: Optional[float] = None) -> None:
super().__init__()
if scale is None or scale <= 0.0:
scale = 1.0
self.register_buffer(
"positional_encoding_gaussian_matrix",
scale * torch.randn((2, num_pos_feats)),
)
def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor:
"""Positionally encode points that are normalized to [0,1]."""
# assuming coords are in [0, 1]^2 square and have d_1 x ... x d_n x 2 shape
coords = 2 * coords - 1
coords = coords @ self.positional_encoding_gaussian_matrix
coords = 2 * np.pi * coords
# outputs d_1 x ... x d_n x C shape
return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1)
def forward(self, size: Tuple[int, int]) -> torch.Tensor:
"""Generate positional encoding for a grid of the specified size."""
h, w = size
device: Any = self.positional_encoding_gaussian_matrix.device
grid = torch.ones((h, w), device=device, dtype=torch.float32)
y_embed = grid.cumsum(dim=0) - 0.5
x_embed = grid.cumsum(dim=1) - 0.5
y_embed = y_embed / h
x_embed = x_embed / w
pe = self._pe_encoding(torch.stack([x_embed, y_embed], dim=-1))
return pe.permute(2, 0, 1) # C x H x W
def forward_with_coords(
self, coords_input: torch.Tensor, image_size: Tuple[int, int]
) -> torch.Tensor:
"""Positionally encode points that are not normalized to [0,1]."""
coords = coords_input.clone()
coords[:, :, 0] = coords[:, :, 0] / image_size[1]
coords[:, :, 1] = coords[:, :, 1] / image_size[0]
return self._pe_encoding(coords.to(torch.float)) # B x N x C4.3 Lightweight mask decoder(轻量掩码解码器)
本文采用双层解码器(图左部分),下一个解码器层从上一层获取更新的token和更新的图像嵌入。(原文提到,整个解码器是一个改进的transformer)
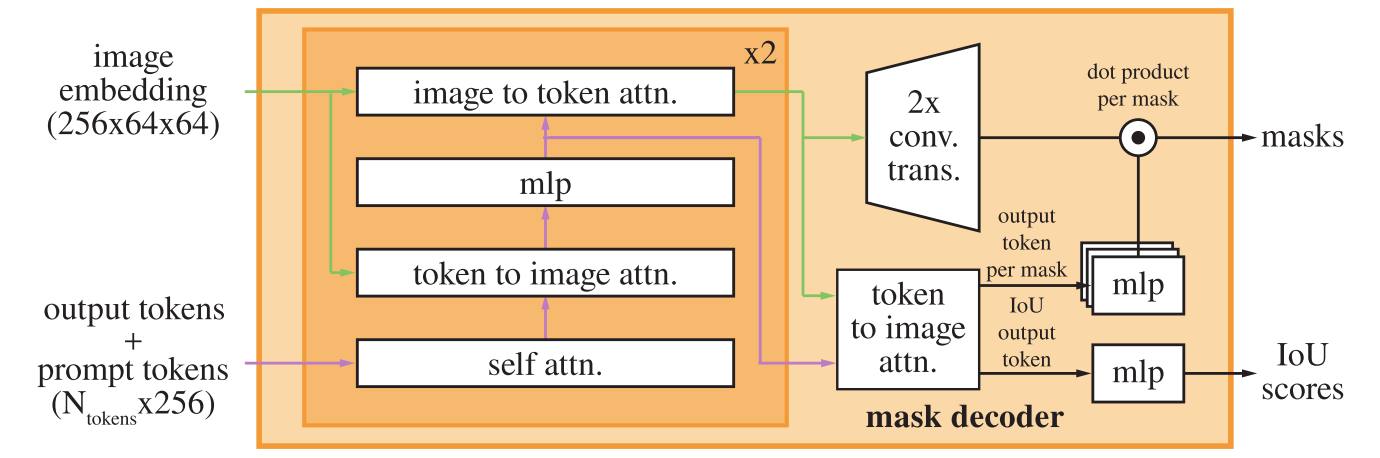
目的:有效地将图像嵌入和一组提示嵌入映射到输出掩码。
过程:在应用解码器之前,首先将学到的 output token 插入到提示嵌入集合中。
每个解码器层执行4个步骤:
- (1)对 token 的自注意力。
- (2)从 token (作为查询) 到 image嵌入 的交叉注意力。
- (3)逐点MLP更新每个token。
- (4)从 image嵌入 (作为查询) 到 token 的交叉注意力。
交叉注意力:在cross-attention中,输入的图像嵌入被视为64×64,256维向量。每个自/交叉注意力和MLP在训练时具有残差连接、层归一化和0.1的dropout。在cross-attention层中,为了提高计算效率,将查询、键和值的通道维度降低了2倍,降至128。所有的注意力层都使用8个头。(多头)
MLP:MLP块的内部维度较大,为2048,但 MLP 仅应用于维度相对较少的提示token(维度很少大于20)。
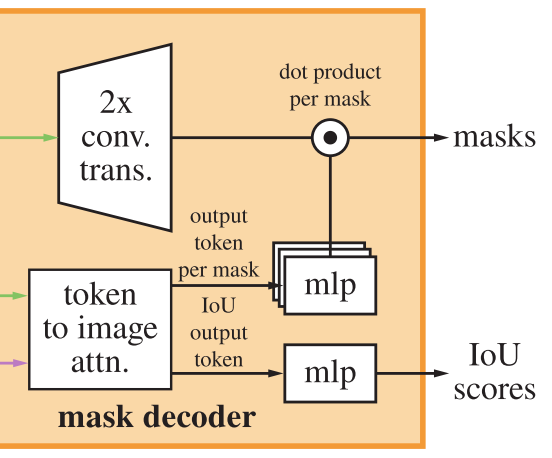
运行解码器之后:用两个转置卷积层将更新后的图像嵌入上采样4倍(现在它相对于输入图像缩小了4倍)。然后,token再次参与图像嵌入,将更新的 output token 嵌入传递给一个小的3层MLP,该MLP输出与升级图像嵌入的通道维度匹配的向量。最后,用放大后的图像嵌入和MLP输出之间的空间点积来预测掩模。
转置卷积层:用于放大输出图像嵌入的转置卷积是2×2,stride 2,输出通道维度分别为64和32,并具有GELU激活。它们被层归一化分开。
代码:
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import torch
from torch import nn
from torch.nn import functional as F
from typing import List, Tuple, Type
from .common import LayerNorm2d
class MaskDecoder(nn.Module):
def __init__(
self,
*,
transformer_dim: int,
transformer: nn.Module,
num_multimask_outputs: int = 3,
activation: Type[nn.Module] = nn.GELU,
iou_head_depth: int = 3,
iou_head_hidden_dim: int = 256,
) -> None:
"""
Predicts masks given an image and prompt embeddings, using a
transformer architecture.
Arguments:
transformer_dim (int): the channel dimension of the transformer
transformer (nn.Module): the transformer used to predict masks
num_multimask_outputs (int): the number of masks to predict
when disambiguating masks
activation (nn.Module): the type of activation to use when
upscaling masks
iou_head_depth (int): the depth of the MLP used to predict
mask quality
iou_head_hidden_dim (int): the hidden dimension of the MLP
used to predict mask quality
"""
super().__init__()
self.transformer_dim = transformer_dim
self.transformer = transformer
self.num_multimask_outputs = num_multimask_outputs
self.iou_token = nn.Embedding(1, transformer_dim)
self.num_mask_tokens = num_multimask_outputs + 1
self.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim)
self.output_upscaling = nn.Sequential(
nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2),
LayerNorm2d(transformer_dim // 4),
activation(),
nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),
activation(),
)
self.output_hypernetworks_mlps = nn.ModuleList(
[
MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)
for i in range(self.num_mask_tokens)
]
)
self.iou_prediction_head = MLP(
transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth
)
def forward(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
multimask_output: bool,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Predict masks given image and prompt embeddings.
Arguments:
image_embeddings (torch.Tensor): the embeddings from the image encoder
image_pe (torch.Tensor): positional encoding with the shape of image_embeddings
sparse_prompt_embeddings (torch.Tensor): the embeddings of the points and boxes
dense_prompt_embeddings (torch.Tensor): the embeddings of the mask inputs
multimask_output (bool): Whether to return multiple masks or a single
mask.
Returns:
torch.Tensor: batched predicted masks
torch.Tensor: batched predictions of mask quality
"""
masks, iou_pred = self.predict_masks(
image_embeddings=image_embeddings,
image_pe=image_pe,
sparse_prompt_embeddings=sparse_prompt_embeddings,
dense_prompt_embeddings=dense_prompt_embeddings,
)
# Select the correct mask or masks for output
if multimask_output:
mask_slice = slice(1, None)
else:
mask_slice = slice(0, 1)
masks = masks[:, mask_slice, :, :]
iou_pred = iou_pred[:, mask_slice]
# Prepare output
return masks, iou_pred
def predict_masks(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""Predicts masks. See 'forward' for more details."""
# Concatenate output tokens
output_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0)
output_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1)
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)
# Expand per-image data in batch direction to be per-mask
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
src = src + dense_prompt_embeddings
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
b, c, h, w = src.shape
# Run the transformer
hs, src = self.transformer(src, pos_src, tokens)
iou_token_out = hs[:, 0, :]
mask_tokens_out = hs[:, 1 : (1 + self.num_mask_tokens), :]
# Upscale mask embeddings and predict masks using the mask tokens
src = src.transpose(1, 2).view(b, c, h, w)
upscaled_embedding = self.output_upscaling(src)
hyper_in_list: List[torch.Tensor] = []
for i in range(self.num_mask_tokens):
hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))
hyper_in = torch.stack(hyper_in_list, dim=1)
b, c, h, w = upscaled_embedding.shape
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
# Generate mask quality predictions
iou_pred = self.iou_prediction_head(iou_token_out)
return masks, iou_pred
# Lightly adapted from
# https://github.com/facebookresearch/MaskFormer/blob/main/mask_former/modeling/transformer/transformer_predictor.py # noqa
class MLP(nn.Module):
def __init__(
self,
input_dim: int,
hidden_dim: int,
output_dim: int,
num_layers: int,
sigmoid_output: bool = False,
) -> None:
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers - 1)
self.layers = nn.ModuleList(
nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim])
)
self.sigmoid_output = sigmoid_output
def forward(self, x):
for i, layer in enumerate(self.layers):
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
if self.sigmoid_output:
x = F.sigmoid(x)
return x4.4 Losses and training(损失和训练)
用 focal loss 和 dice loss 的线性组合来监督掩模预测。使用几何提示的混合来训练可提示的分割任务。通过在每个掩模中随机抽取11轮提示来模拟交互式设置,从而使SAM无缝地集成到我们的数据引擎中。
五、Zero-Shot Transfer Experiments(零样本迁移实验)
在本节中,提出了零射击转移实验与SAM,片段任何模型。考虑了五个任务,其中四个与用于训练SAM的提示分割任务有很大不同。这些实验在训练过程中未接触过的数据集和任务上评估了SAM。这些数据集可能包括新的图像分布。
5.1 Zero-Shot Single Point Valid Mask Evaluation(零样本单点有效掩码评估)
评估指标:mIoU和人工评分(评估从单个前景点分割一个对象,这个任务是病态的,因为一个点可以指向多个对象。因此,采用人工评分补充标准的mIoU度量)
评估对象:由于SAM能够预测多个掩码,因此默认情况下我们只评估模型中分数最高的掩码。(SAM会产出多个分割预测,选择分数最高的输出。)
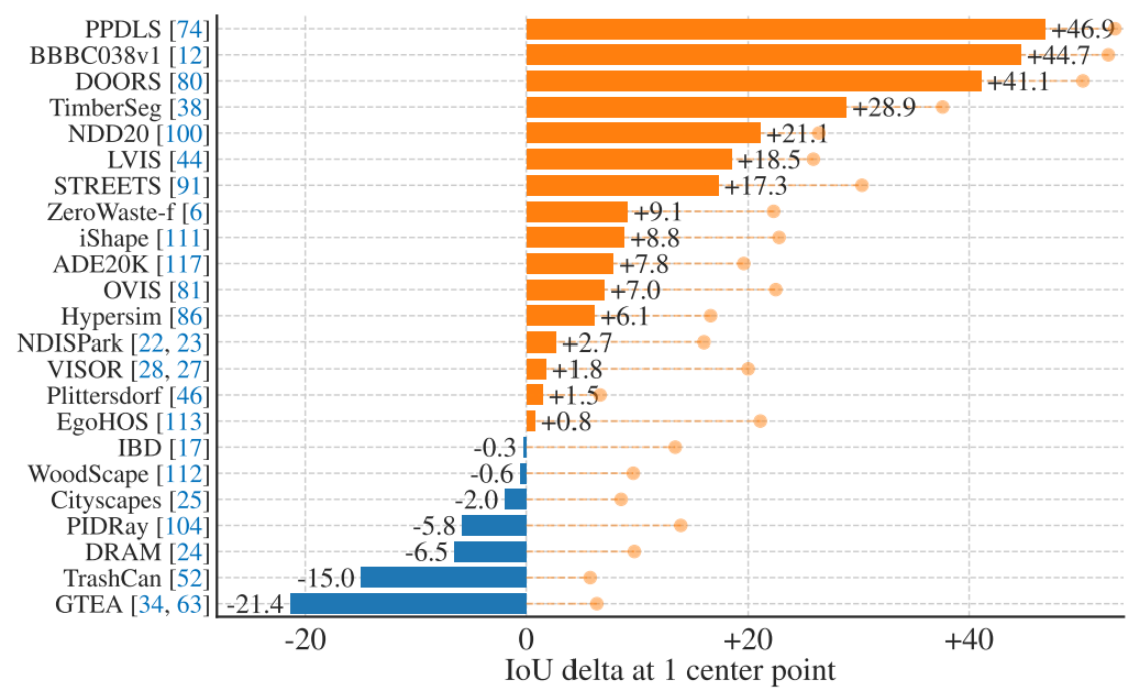
评估结果:与RITM比较,SAM在23个数据集中的16个数据集上产生了更高的结果,IoU分数约高达47。提供了一个“oracle”结果,其中通过将SAM的3个掩码与 ground truth 进行比较来选择最相关的掩码,而不是选择最自信的掩码。这揭示了歧义对自动评估的影响。特别是,使用oracle执行歧义解析,SAM在所有数据集上的性能都优于RITM。
5.2 Zero-Shot Edge Detection(零样本边缘检测)

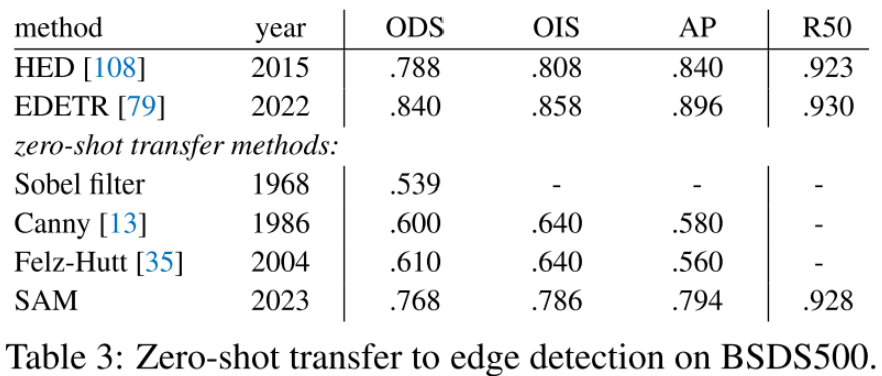
方法:边缘检测任务主要使用BSDS500数据集,属于难度较低的任务。具体的采用了简化版本的自动掩模生成流程,使用一个 16×16 的前景点规则网格做prompt提示,得到了 768 个预测mask(每个点三个,即16×16×3),再通过非极大值抑制做冗余过滤。进一步对剩余mask的未阈值化概率图(unthresholded probability maps)用Sobel 滤波器做过滤。最后对所有预测进行逐像素最大化,线性将结果归一化为 [0,1],用边缘非极大值抑制来稀疏边缘。
结果:定性地说,可以观察到即使SAM没有被训练用于边缘检测,它也能产生合理的边缘图。与ground truth相比,SAM预测了更多的边缘,包括BSDS500中没有注释的敏感边缘。这种偏差在表3中得到了定量的反映:50%精度下的召回率很高,但以精度为代价。SAM自然落后于学习BSDS500偏差的最先进的方法,即哪些边要抑制。尽管如此,与HED等开创性的深度学习方法(也在BSDS500上进行了训练)相比,SAM表现良好,并且明显优于之前的零样本迁移方法。
5.3 Zero-Shot Object Proposals(零样本候选区域识别)
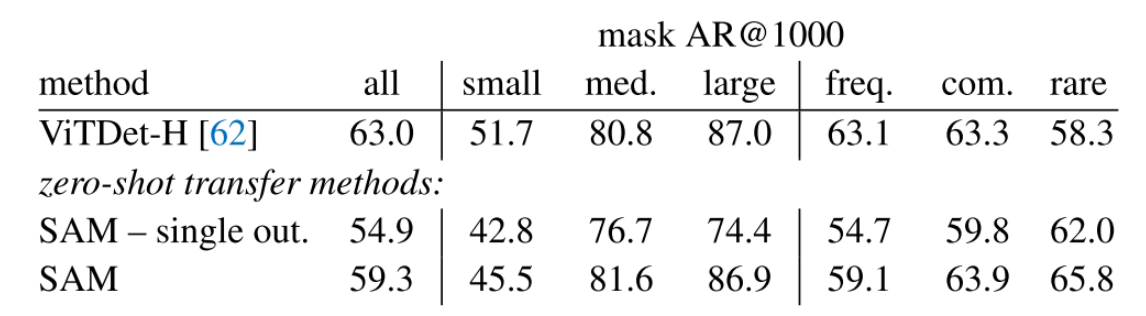
数据集和评价指标:在LVIS v1数据集上计算标准平均召回率(AR)指标。
对比网络:ViTDet检测器实现的强基线(具有级联掩膜R-CNN ViT-H)。
结果:使用来自ViTDet-H的检测作为对象建议(即游戏AR的DMP方法[16])总体上表现最好。然而,SAM在几个指标上做得非常好。值得注意的是,它在大中型物体以及稀有和普通物体上的表现优于ViTDet-H。事实上,SAM只在小对象和频繁对象上的表现不如ViTDet-H,因为它是在LVIS上训练的,所以与SAM不同,ViTDet-H可以很容易地学习到LVIS特定的注释偏差。
7.4 Zero-Shot Instance Segmentation(零样本实例分割)
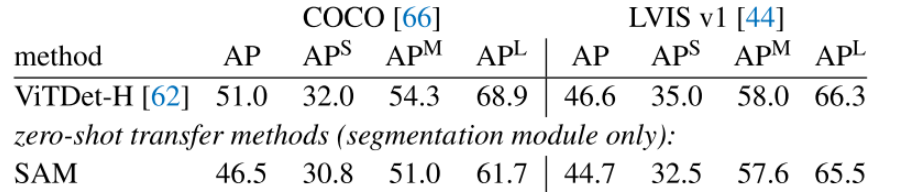
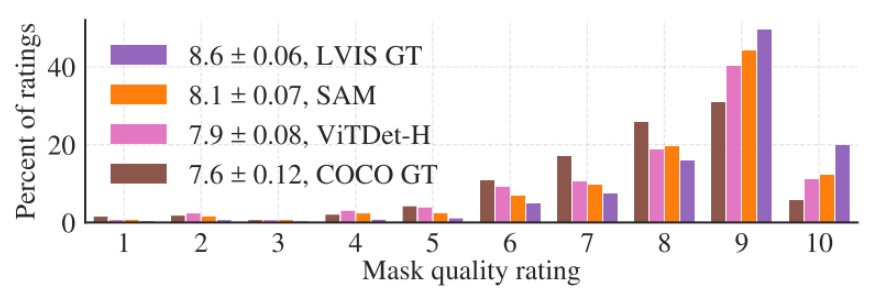
方法:从更高级的角度来看,本文使用SAM作为实例分割器的分割模块。实现很简单:运行一个对象检测器(前面使用的ViTDet)并用它的输出框提示SAM。
结果:通过观察掩模AP指标,观察到两个数据集上的差距,其中SAM相当接近,尽管肯定落后于ViTDet。通过可视化输出,观察到SAM掩模通常在质量上优于ViTDet,具有更清晰的边界。为了调查这一观察结果,进行了一项额外的人工评分,要求注释者按照之前使用的1到10的质量等级对ViTDet Mask和SAM Mask进行评分。如上述结果所示,观察到SAM在人体研究中始终优于ViTDet。
六、结论
1. 目的:Segment Anything 项目是将图像分割提升到基础模型时代的一次尝试。
2. 贡献:主要贡献是一个新的任务(提示分割),模型(SAM)和数据集(SA-1B),使这一飞跃成为可能。
3. 展望:SAM是否达到基础模型的地位还有待观察,因为它在社区中的使用情况如何,但无论我们期望这项工作的前景如何,超过1B个掩模的发布以及我们及时的分割模型将有助于铺平前进的道路。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











